






spring对Jdbc进行了封装,使用jdbcTemplate方便对数据库操作
为什么要用JdbcTemplate?有什么好处?
简化数据库访问:JdbcTemplate是Spring框架提供的一个数据库访问工具,它封装了JDBC的复杂性,提供了简洁的API来执行数据库操作。相比于原生的JDBC,使用JdbcTemplate可以减少很多样板代码,使数据库访问更加简单和可读。
自动资源管理:JdbcTemplate会自动管理数据库连接、执行SQL语句和处理结果集的资源,这包括打开和关闭连接、释放Statement和ResultSet等。这样可以避免手动管理资源时可能出现的错误和资源泄漏。
异常处理:JdbcTemplate会将JDBC抛出的异常转换为Spring的DataAccessException,这使得处理异常更加方便和一致。您可以在代码中专注于业务逻辑,而无需处理低级的JDBC异常。
参数绑定和SQL注入防护:JdbcTemplate提供了参数绑定功能,您可以将参数值安全地绑定到SQL语句中,防止SQL注入攻击。这样可以保护应用程序的安全性。
预定义的操作和便捷的API:JdbcTemplate提供了许多预定义的操作方法,用于执行常见的数据库操作,如查询一个或多个结果、执行更新、批量更新等。同时,JdbcTemplate还提供了简洁易用的API,使得执行数据库操作变得更加方便和灵活。
总之,使用JdbcTemplate可以提高开发效率,简化数据库访问过程,并提供更好的异常处理和安全性。它是一个成熟和广泛使用的数据库访问工具,可以与Spring框架完美结合,为开发人员提供便捷的数据库访问解决方案。
环境搭建
引入依赖
<!-- spring持久化层jar包 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>6.0.9</version>
</dependency>
<!-- MySql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- druid连接池数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.16</version>
</dependency>创建数据库配置文件jbdc.properties
#用户名
jdbc.user = root
#密码
jdbc.password = 123456
#数据库地址
jdbc.url = jdbc:mysql://localhost:3306/springTest
#驱动
jdbc.driver = com.mysql.cj.jdbc.Driver创建beans.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.wal"/>
<!-- 引入外部属性文件,创建数据源对象-->
<context:property-placeholder location="classpath:jdbc.properties"/>
<bean id="druidDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="url" value="${jdbc.url}"/>
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="username" value="${jdbc.user}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<!-- 创建jdbcTemplate-->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="druidDataSource"></property>
</bean>
</beans>我们来详细讲解一下这个xml文件
1、我们在外面创建了jdbc.property外部属性文件,要使用其中编辑的jdbc属性,所以要引入进来
<context:property-placeholder location="classpath:jdbc.properties"/>
context:property-placeholder是一个Spring的命名空间元素,它告诉Spring要解析占位符并将其替换为配置文件中的实际值。
2、然后就要创建其数据源对象,我们有现成的引入的数据库连接池类DruidDataSource,我们只需要使用<property />赋予它属性值,但由于值我们写在了刚才引入的外部文件property中,我们需要使用${ }
${}符号是Spring框架中的占位符语法。它表示该属性的值将从配置文件中获取
使用占位符的好处是可以将属性值从代码中解耦出来,统一放置在配置文件中管理
3、然后,在<bean>元素中,通过使用value属性和${}占位符将具体的属性值注入到Druid连接池的实例中。这些属性值将从jdbc.properties文件中读取,根据配置文件中对应的占位符进行替换。
4、最后我们就可以使用JdbcTemplate了,创建其bean,其中有一个属性dataSource,我们刚才创建的druidDataSource传入可以了
创建数据库
create database springTest;
use springTest;
create table t_emp(
id int(11) not null auto_increment ,
name varchar(20) default null ,
age int(11) default null ,
sex varchar(2) default null,
primary key (id)
) Engine = INNODB DEFAULT CHARSET = utf8mb4;
- Engine = INNODB:表示使用InnoDB存储引擎,它是MySQL中最常用的存储引擎之一。它提供了事务支持和行级锁定等功能,适用于大多数应用场景。
- DEFAULT CHARSET = utf8mb4:指定了表的默认字符集为utf8mb4。utf8mb4是一种字符集,支持存储所有Unicode字符,包括一些不常用的表情符号和特殊符号。使用utf8mb4字符集可以确保数据库存储和处理各种国际化字符的能力。
创建测试类
我们在上一篇文章中已经整合了Junit5,就不再使用ApplicationContext那么繁琐的代码了,直接使用SpringJunitConfig完成自动创建容器
注:这里testUpdate并不是指我们要测试数据修改功能,而是 Template中的update方法
至此,基础环境已经搭建,现在可以使用了
快速入门
我们首先看一下刚才提到的update方法
![]()
第二个参数args用于传递占位符的值,我们要在sql语句中使用占位符
我们直接来举例演示
1、增加
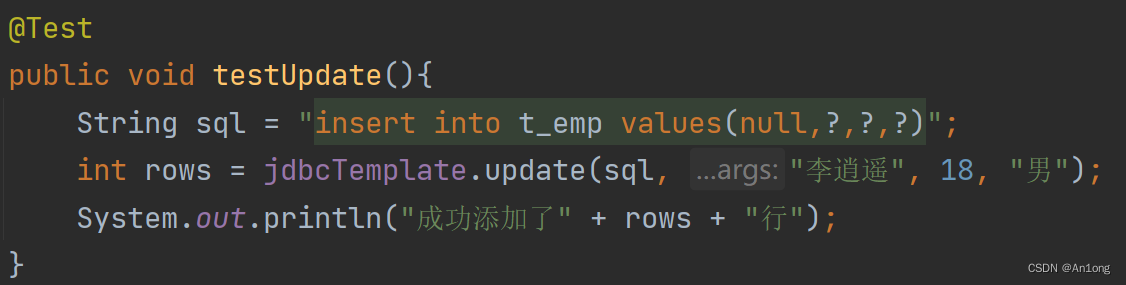 测试
测试

![]()
成功添加
2、修改
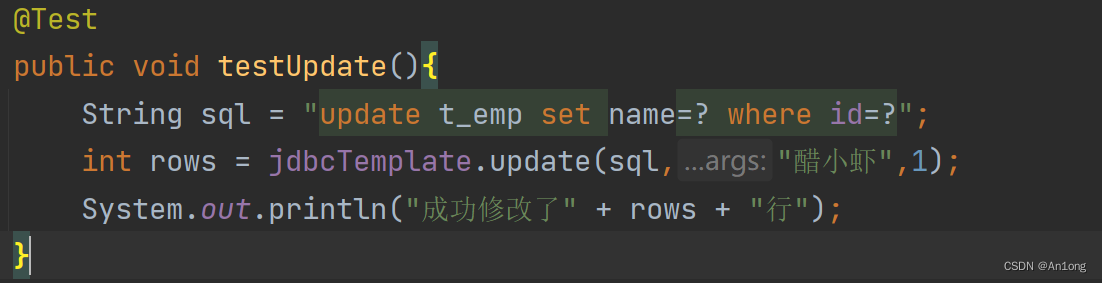

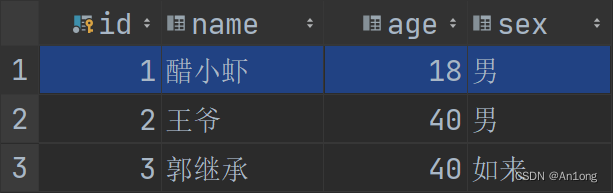
成功将李逍遥改为了醋小虾
3、删除
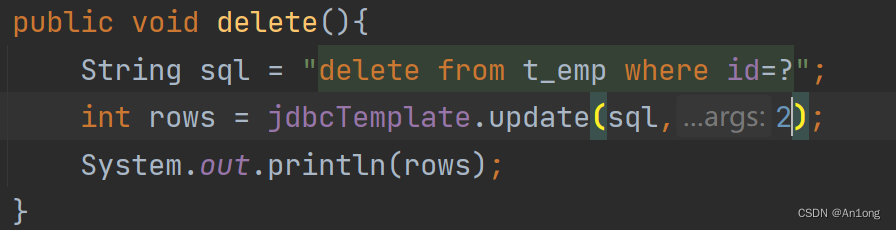
将id为2成功删除
4、查询
<1>、返回对象
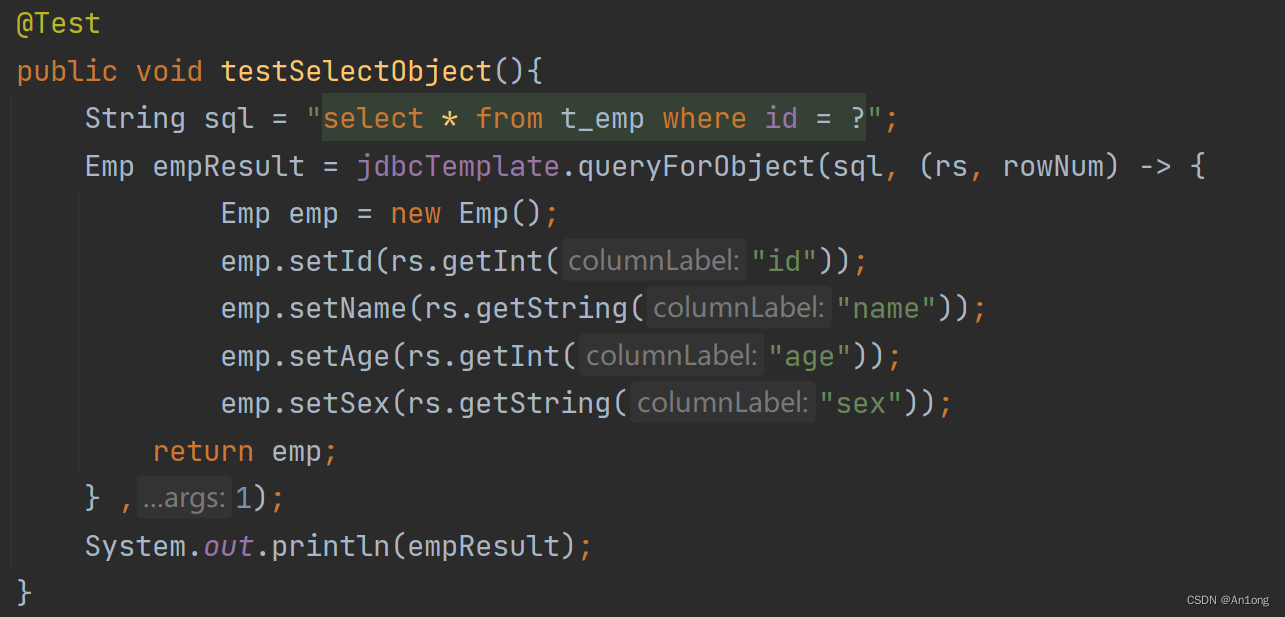
我们做查询操作就不使用update方法了,使用query方法
![]()
RowMapper是一个接口用于数据封装,我们点进源码看
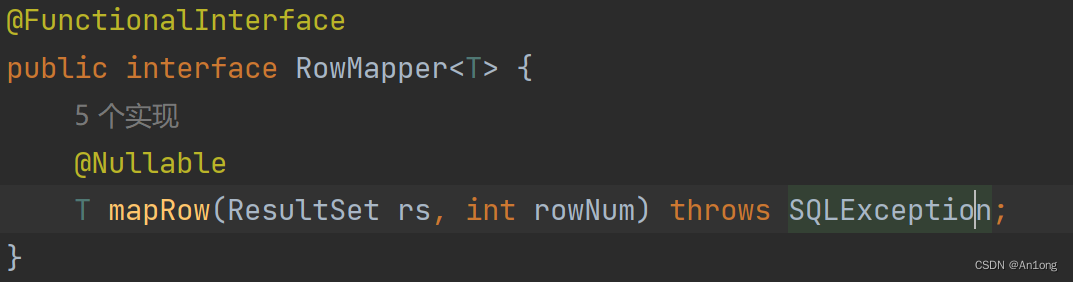
参数一ResultSet(数据集)在JDBC时就出现过,是用于存储从数据库中返回的查询结果的对象。
参数二rowNum是当前的行数,从哪一行开始
这个接口中仅有一个方法,所以我们在使用的时候直接Lambda表达式封装一下即可

但是我们发现这种方式,我们要手动封装有些繁琐,为了偷懒我们使用BeanPropertyRowMapper来帮我们自动封装
我们直接使用匿名内部类进行创建,参数传入你要返回的类型.class
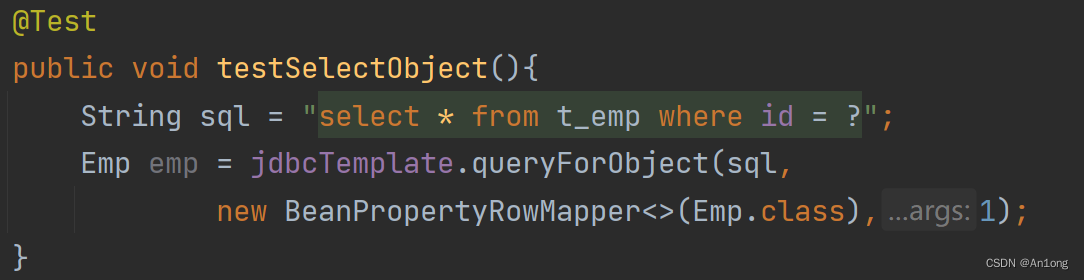
成功运行,其底层逻辑其实是一摸一样的

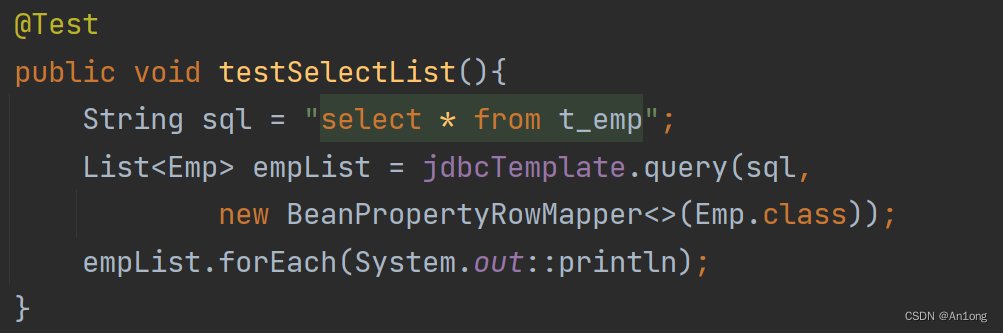
<2>、返回List
这里使用query方法,返回一个集合,也是使用自动封装RowMapper,确实好用

<3>、返回单个信息
查询单个返回的信息,比如查询的年龄,姓名,价格等等
例:
查询count(*)返回的单条数据信息

![]()
















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











