






04-1.3 监督学习与神经网络
如果说深度学习和神经网络背后的基本思想已经存在数十年了,为什么它们最近才风靡起来。在本次视频中,让我来回顾一下,深度学习崛起背后的一些主要驱动力量。因为我认为这能够帮助你更好地在你的工作单位内,发现最佳机会,来运用这些工具。
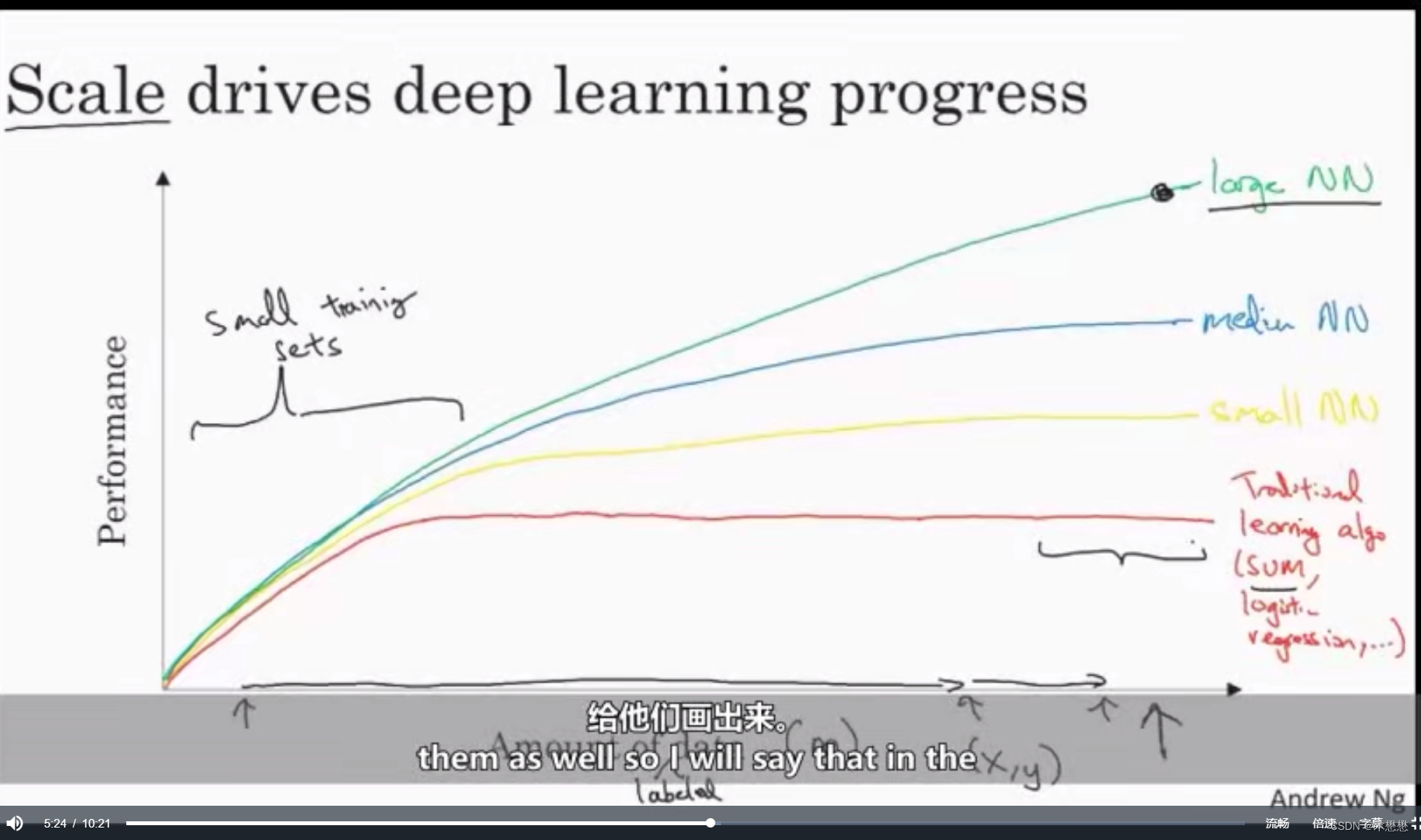
这些年来,很多人问我为什么深度学习突然间这么好使了,当我回答他们这个问题时,通常我会给他们画张图,让我们先来画个坐标图。横坐标表示,在某个任务上我们拥有的数据量。纵坐标表示,学习算法的性能,比如垃圾邮件分类器的准确率或者广告点击预测的准确率,或者对于自动驾驶来说,探测其他车子位置的神经网络的准确率。如果你将传统的学习算法,比如支持向量或者逻辑回归,这些算法的性能来作为数据量的函数,来作图。你或许会得到如图的曲线。这个曲线里面,刚开始性能逐渐上升,但是随着数据增多,过了一段时间,性能逐渐地趋于平坦。这本该是水平的线。我这画得不太好。他们不知道该如何处理大规模数据。但是过去10年,我们社会发生的事情是,对于非常多的问题,我们从只有相对来说少量的数据,到相对大量的数据。这些数据大多都是归功于社会的信息化。非常多的人类行为已经被电子化和信息化,我们在电脑上、网站上、手机APP,花了大量的时间,这些在电子设备上的行为创造了数据。因为手机内置的相机,还有加速计,还有各种物理网中的感应器,这些东西的普及,我们已经收集了越来越多的数据。所以在过去20年,对于很多应用,我们已经积累了非常多的数据,超出了传统的学习算法,所能有效利用的。而如果使用神经网络,你如果训练一个小型的神经网络,那么它的性能也许看起来像这个样子。你如果训练一个稍微大点的神经网络,让我们叫它中型的神经网络,它的性能会稍微好些。你如果训练一个非常大的神经网络,它的性能会越来越好。
所以观察到几个现象。第一,如果你想要达到如此高的性能,你需要2件事。首先,你需要训练足够大的网络,来利用大量的数据。其次,你需要在x轴的这里,你需要非常多的数据,所以我们通常说规模、驱动深度学习进展。所谓规模,我的意思是,不仅仅是神经网络的规模,网络有着很多的隐含单元、很多参数、很多连接,还有数据规模。事实上今天,想要达到高性能,最可靠的方法之一,是要么训练一个大网络,要么放更多的数据。然后这个在一定程度后也会达到瓶颈,因为最终你会用光所有数据,或者最终你的网络实在太大了,训练得花很长时间。但是,光是改善规模就足以帮助我们在深度学习里面前进一大步。为了让这个示意图更加的准确,让我再加点东西,我在x轴上写了数据量,更准确地来说,这是被标记过的数据量。被标记过的意思是,对于训练集,我们同时有输入x和标记y,我来稍微介绍一下这门课,我们将用到的符号,我们将使用m来表示训练集的大小,也就是训练样本的数量。这个小m就是水平坐标。这个图里还有一些细节要说明,在训练集的这个区间里,不同算法的顺序(排名),是不规则的。如果你没有很大的数据集,那么你自己提取出来的特征很大程度上,决定了算法的结果(性能、表现)。所以,很有可能发生这样的事,有人用手工设计好的特征去训练,SVM(支持向量机),而有人在这个很小的训练集上训练一个很大网络,SVM可能会得到更好的结果。所以,在这个图像左边的这个区域里,不同算法的性能的排名,是不固定的。这个性能更多的是由你提取特征的能力,和算法的细节而决定的。只有在这个很大的数据集的区域里,只有在这个m很大的数据集的区域里,我们会经常看到很大的神经网络,超过了其他方法。如果你的朋友问你,神经网络为什么现在才流行起来,我建议你可以把这个图给他们画出来。
在最近这次深度学习崛起的早期,两个不同的关于小脑学习的例子,主要是靠大量的数据,和高效的计算能力,也就是我们训练网络的能力。无论是在CPU还是在GPU上,这个能力(的提升)让我们前进了很多。但是,我们在过去的几年里,也看到了越来越多的算法层面上的创新。所以我也不想忽略这一点。有趣的是,很多在算法层面上的创新,使得神经网络能运行得更快。
举一个例子,神经网络里一个重大的突破,就是从sigmoid函数到ReLU函数的迁移。(左边的是sigmoid,右边是ReLU)。我们在之前的视频里已经讲过,如果你对我说的细节并不是很了解。不要担心,(要知道的是)sigmoid函数在机器学习里有一个问题,那就是在这些剃度几乎为0。区域里,那么学习的进度会变得非常慢。因为当你用剃度下降法的时候,剃度(几乎)为0,那么参数会变得非常慢。而当我们把我们叫做激活函数的这个东西,换成一个叫做ReLU的函数,全名是修正线性单元(rectified linear unit)。对于所有的正输入,剃度都是1,那么剃度就不会慢慢变成0。剃度在左边的时候为0。结果证明,简单地sigmoid函数换成ReLU函数,使得剃度下降算法的速度,提高很多。这个看似比Bayesian,确实大大提高了运算速度,还有很多这样的例子,我们改进了算法,使得我们的代码,可以更快地运行,从而我们可以训练更大的神经网络。当我们有一个很大的网络和很多的数据的时候,我们需要在合理的时间里去训练,快速计算很重要的另一个原因是,你训练一个神经网络的过程,是一个循环。你有一个网络架构的想法,你去用代码实现,实现你的想法,之后让你实验结果告诉你你的网络表现怎么样,这样你可以回过头去修改,网络里面的细节。然后重复这个循环。当你的神经网络需要花费很多时间训练的时候,大量时间就会消耗在在这个循环里。在这个中间,你的效率会受到很大的影响。比如你可以用10分钟或者最多一天尝试你的一个想法,看看它是否可行。也许,你需要1个月去训练你的网络。有的时候确实会发生这样的情况。当你可以在10分钟或者1天之内得到结果的时候,你可以尝试很多想法。这会让你更有可能去发现你的网络是否针对你的应用是可行的。快速计算确实会提高你拿到实践结果的速度,无论是对于追求实践的人还是对于科研人员来说,这都可以加快其深度学习研究速度,促进其想法创新。这些都会促进深度学习领域的大发展。这个领域的前沿有着不可思议的新算法和不断地发展。领域前沿不断更新,不可思议的新算法层出不穷。这些都是使得深度学习不断发展的动力。
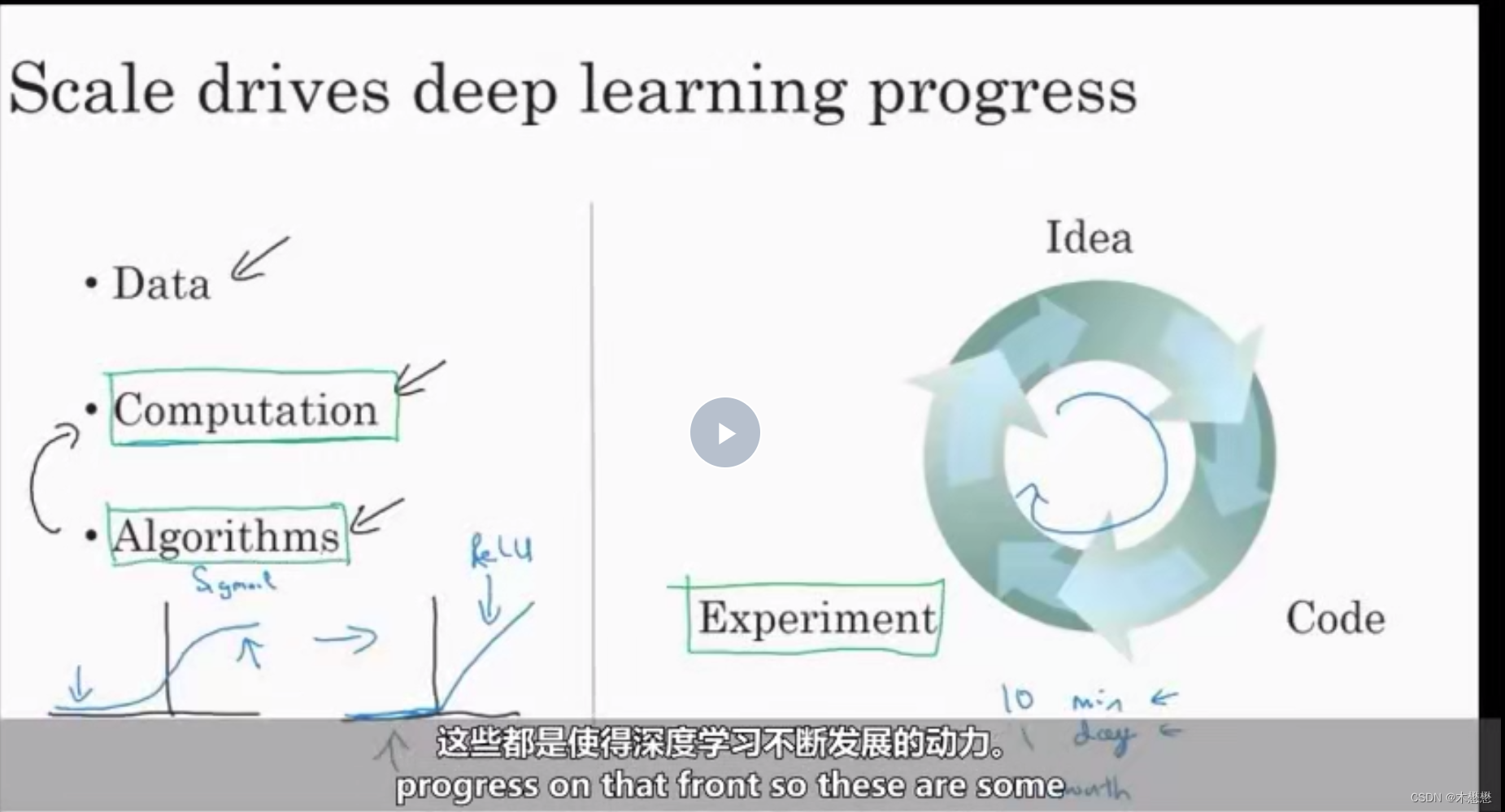
好消息是这些动力如今仍然在推动深度学习更加进步。比如说数据,这个领域产生的数据越来越多。比如说计算(能力),随着针对深度学习的硬件的发展,比如GPU、高速网络、或其他的硬件,我很有信心,我们建造大型神经网络的能力会越来越强大。至于算法,整个深度学习领域一直都在不断创新,正因如此 我认为我们可以很乐观(至少我很乐观),深度学习在未来的几年变得越来越好。那么 让我们继续下一期课程。在下一部分,我们将会讨论你能从课程中学到的知识。















 5962
5962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









