






栈与队列part02(24.01.08)
安排:先独立做题,然后看视频讲解,然后看文章讲解,然后再重新做一遍题,把题目AC,最后整理成今日当天的博客。
- 学习时长:3h
- 学习内容:自己尝试+pdf说明+视频+力扣题解+自己默写
- 学习感悟:坚持!加油!注意力集中!
239. 滑动窗口最大值
题目链接:力扣题目链接
笔记:
1.其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。示意图如下链接:
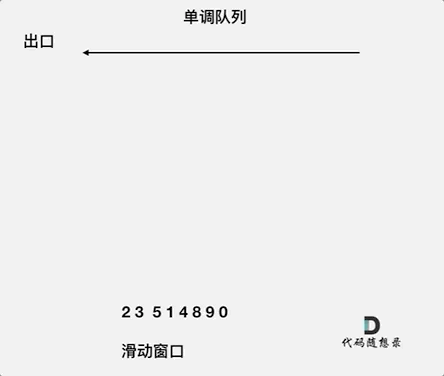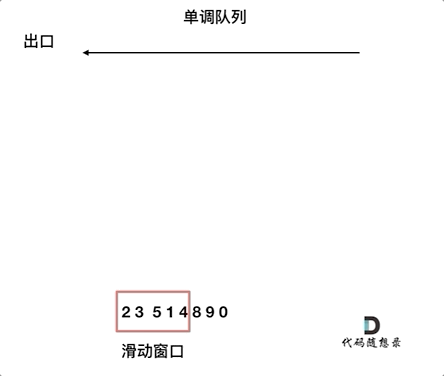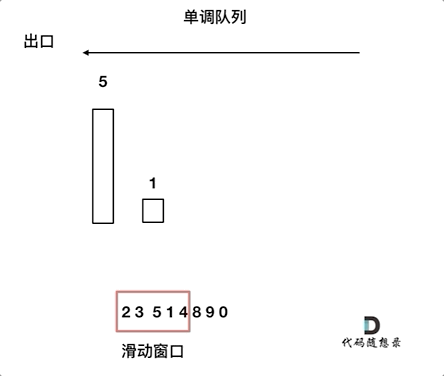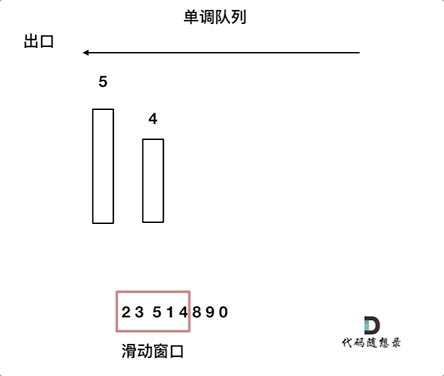
2.设计单调队列的时候,pop和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
3.用什么数据结构来实现这个单调队列呢?
使用deque最为合适,在文章栈与队列:来看看栈和队列不为人知的一面 (opens new window)中,我们就提到了常用的queue在没有指定容器的情况下,deque就是默认底层容器。
提交代码:
from collections import deque
class MyQueue: #单调队列(从大到小
def __init__(self):
self.queue = deque() #这里需要使用deque实现单调队列,直接使用list会超时
#每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
#同时pop之前判断队列当前是否为空。
def pop(self, value):
if self.queue and value == self.queue[0]:
self.queue.popleft()#list.pop()时间复杂度为O(n),这里需要使用collections.deque()
#如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
#这样就保持了队列里的数值是单调从大到小的了。
def push(self, value):
while self.queue and value > self.queue[-1]:
self.queue.pop()
self.queue.append(value)
#查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
def front(self):
return self.queue[0]
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
que = MyQueue()
result = []
for i in range(k): #先将前k的元素放进队列
que.push(nums[i])
result.append(que.front()) #result 记录前k的元素的最大值
for i in range(k, len(nums)):
que.pop(nums[i - k]) #滑动窗口移除最前面元素
que.push(nums[i]) #滑动窗口前加入最后面的元素
result.append(que.front()) #记录对应的最大值
return result过程中报错:myQueue' object has no attribute 'queue':通过修正定义初始init那里(左右各是两个下划线!我错写成一个了,可能就让这块失效了)解决了报错。
疑问:一直感觉比较迷惑的是队列到底哪头是前端哪头是后端,每次做操作的时候默认从哪实施?比如pop()到底从哪弹出?(看代码是感觉定义的deque默认左边出右边进【左边是队头+出口,右边是队尾+入口】pop默认弹出队尾的元素,popleft弹出队头的元素)
347.前 K 个高频元素
题目链接:力扣题目链接
笔记:
1.大顶堆和小顶堆。可以用优先级队列进行实现(其基本逻辑就是堆的逻辑)。
2.统计元素出现的频率,这一类的问题可以使用map来进行统计。对频率进行排序,这里我们可以使用一种容器适配器就是优先级队列(其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列)。
3.堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
4.我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
5.heapq 模块是 Python 中用于堆排序的模块,提供了对堆的支持。在使用 heapq 模块时,你可以创建一个堆(heap)并使用一些函数对其进行操作。map_.get(nums[i], 0) 用于获取字典中键 nums[i] 对应的值。如果键不存在,则返回默认值 0。map_[nums[i]] = map_.get(nums[i], 0) + 1 将字典中键 nums[i] 对应的值增加 1。
提交代码:
#时间复杂度:O(nlogk)
#空间复杂度:O(n)
import heapq
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
#要统计元素出现频率
map_ = {} #nums[i]:对应出现的次数
for i in range(len(nums)):
map_[nums[i]] = map_.get(nums[i], 0) + 1
#对频率排序
#定义一个小顶堆,大小为k
pri_que = [] #小顶堆
#用固定大小为k的小顶堆,扫描所有频率的数值
for key, freq in map_.items():
heapq.heappush(pri_que, (freq, key))
if len(pri_que) > k: #如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
heapq.heappop(pri_que)
#找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
result = [0] * k
for i in range(k-1, -1, -1):
result[i] = heapq.heappop(pri_que)[1]
return result过程中报错:
1.TypeError: 'builtin_function_or_method' object is not iterable for key,freq in map_.items解决办法:在map_.items后面加了一对括号(),解决报错。map_.items() 是字典(map_)的一个方法,用于获取包含字典中所有键值对的视图对象。这个方法返回一个类似于集合的视图,其中包含元组 (key, value)。使用 map_.items() 的典型用法是在循环中迭代字典的键值对。
总结
栈和队列这里代码开始有点复杂了,第一轮学习主要听懂思路即可,可能需要我再学一下数据结构以后再说熟练敲出代码的事情。路漫漫其修远兮。















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}