







 DALLE2是一种利用CLIP模型进行图像生成的两阶段模型,包括先验模型和解码器。它通过学习图像表示来提高多样性和保持真实性。文章介绍了模型的工作原理、训练过程,以及自回归式和扩散模型作为先验模型的选择。预训练模型可用于生成图像,但可能需要调整和优化以获得最佳效果。
DALLE2是一种利用CLIP模型进行图像生成的两阶段模型,包括先验模型和解码器。它通过学习图像表示来提高多样性和保持真实性。文章介绍了模型的工作原理、训练过程,以及自回归式和扩散模型作为先验模型的选择。预训练模型可用于生成图像,但可能需要调整和优化以获得最佳效果。
它主要包括三个部分:CLIP,先验模块prior和img decoder。其中CLIP又包含text encoder和img encoder。(在看DALL·E2之前强烈建议先搞懂CLIP模型的训练和运作机制,之前发过CLIP博客)
论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
代码地址:https://github.com/lucidrains/DALLE2-pytorch
1、简介
DALLE2提出了一个两阶段模型,利用类似CLIP的对比模型学习到的图像表示。第一阶段是一个先验模型,根据文本描述生成CLIP图像嵌入;第二阶段是一个解码器,根据图像嵌入生成相应的图像。我们发现,通过明确生成图像表示,可以提高图像多样性,同时最小程度地损失真实感和描述相似性。我们的解码器在图像表示的条件下,能够产生保留其语义和风格的图像变体,同时变化了图像表示中缺少的非关键细节。此外,CLIP的联合嵌入空间使得可以通过语言引导图像操作,实现零-shot学习。我们采用扩散模型进行解码,并尝试了自回归和扩散模型作为先验模型,结果显示后者在计算上更高效且生成的样本质量更高。
2、模型介绍
DALLE2模型的工作原理很简单,它接受文本描述并通过CLIP将其编码成向量表示,然后通过先验模块生成与文本相关的图像表示,最后,图像解码器将该表示解码成一张具体的图像,实现了根据文本生成对应图像的任务。(在看DALLE2之前强烈建议先搞懂前面引言中的CLIP模型的训练和运作机制)下图中,虚线上方:训练CLIP过程;虚线下方:由文本生成图像过程
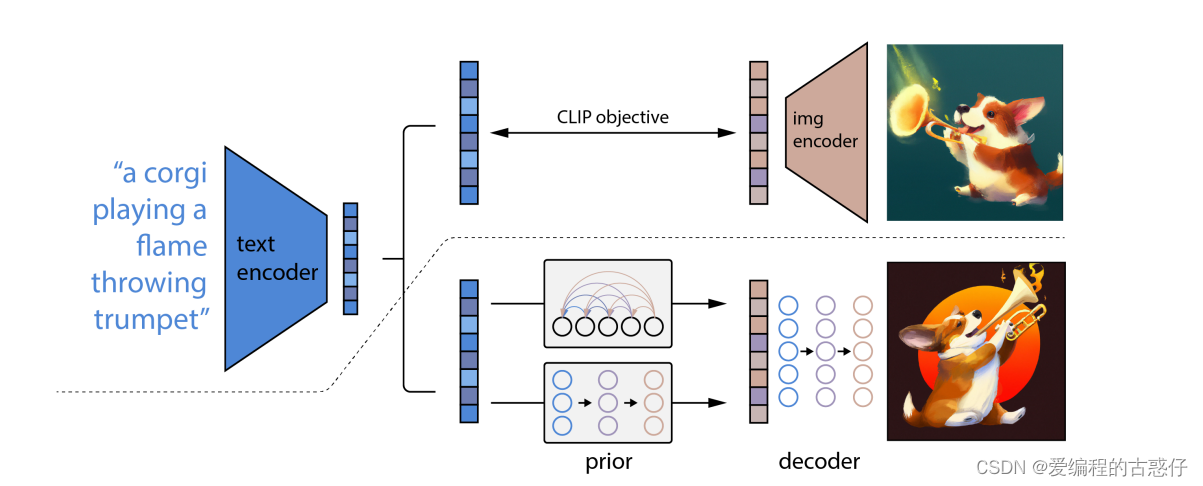
3、训练过程
- 训练CLIP,使其能够编码文本和对应图像
这一步是与CLIP模型的训练方式完全一样的,目的是能够得到训练好的text encoder和img encoder。这么一来,文本和图像都可以被编码到相应的特征空间。对应上图中的虚线以上部分。
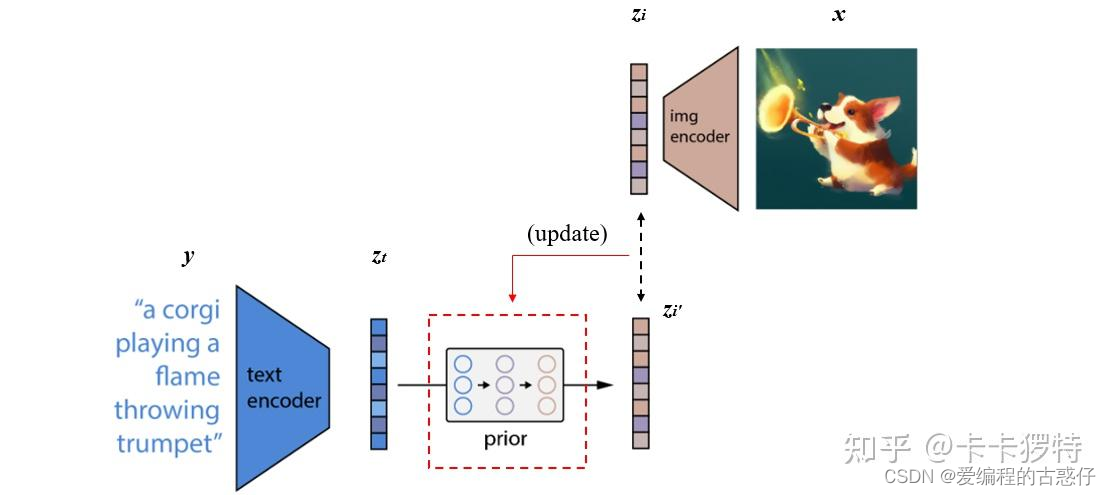
- 训练prior,使文本编码可以转换为图像编码
![]()
将CLIP中训练好的text encoder拿出来,输入文本y,得到文本编码Zt。同样的,将CLIP中训练好的img encoder拿出来,输入图像x得到图像编码Zx。我们希望prior能从Zt获取相对应的Zt。假设Zt经过prior输出的特征为Zi',那么我们自然希望Zi与Zi'越接近越好,这样来更新我们的prior模块。最终训练好的prior,将与CLIP的text encoder串联起来,它们可以根据我们的输入文本y生成对应的图像编码特征Zi了。关于具体如何训练prior,有兴趣的小伙伴可以精读一下论文,作者使用了主成分分析法PCA来提升训练的稳定性。(下图借鉴了一篇知乎的博客的图片)
作者团队尝试了两种先验模型:自回归式Autoregressive (AR) prior 和扩散模型Diffusion prior 。实验效果上发现两种模型的性能相似,而因为扩散模型效率较高,因此最终选择了扩散模型作为prior模块。
小辉问:详细说说自回归式Autoregressive (AR) prior 和扩散模型Diffusion prior
小G答:自回归式(Autoregressive,AR)先验模型和扩散模型(Diffusion Model)是两种不同的先验模型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2908
2908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









