






在日常开发项目的过程中,我们的项目系统由于用户量增加,特别是用户访问量特别大的情况下,用户去请求操作我们的系统资源,往往会导致我们后台系统会在高并发的情况下,发生数据错乱的问题,那这些问题要该如何去解决呢?下面我会根据不同状态下的场景,由浅入深来解决我们实际开发过程中遇到的问题。
通过一个简单的例子来让大家更直观的感受:
用户对库存的操作
不做任何处理
在多线程的环境下,多个线程直接访问我们的系统资源,在我们直接操作库存的那一部分代码中,未作任何处理的情况下由于线程执行的顺序不确定,可能导致资源数量被重复修改或超卖。
使用synchronized做处理
使用synchronized的话,我们会发现数据错乱的问题解决了,synchronized使得多个线程如果要操作某一资源的话需要排队进行,让我们的库存作为一个原子操作执行,避免了线程之间的相互干扰。这时解决了数据错乱的问题。但是由于我们的系统用户量增加,使得对库存操作这一模块所消耗的时间非常长,导致整个系统的性能下降。那又该如何去解决这个问题呢?
对服务进行扩展,并进行负载均衡处理
上面我们了解到使用synchronized方式虽然能够保证我们数据的正确性,但是导致了我们的系统整体性能的下降,我们可以将我们的服务进行水平扩展为若干个服务并使用nignx做负载均衡,减轻了单个服务的压力,提高整个系统的性能。想到这里可能很多人会认为问题已经基本解决,可以正常使用了,其实不然,我们使用的仍然是synchronized的方式去解决并发问题,但是我们却忽略了,synchronized是处于jvm层面的并发处理机制,但是在分布式状态下,各个服务只等锁住单个线程,其他服务的线程无法控制,这时又会导致系统的数据错乱,那这个问题又该如何去解决呢?
使用redis的setNX分布式锁去处理分布式并发问题
我们先来普及一下setnx的功能
SETNX 是 Redis 数据库中的一个原子性操作命令,用于设置一个键的值,仅当该键不存在时才设置成功。SETNX 是 "SET if Not eXists" 的缩写。
命令格式:
SETNX key value
参数:
key:键名value:要设置的值
返回值:
- 当键不存在时,设置成功并返回 1。
- 当键已经存在时,设置失败并返回 0。
SETNX 命令可以用于实现分布式锁的简单机制。通过将某个键作为锁,多个客户端可以使用 SETNX 命令来竞争获取锁。只有一个客户端能够成功设置该键,即获取到锁,而其他客户端则会设置失败。
例如,以下示例展示了如何使用 SETNX 命令实现简单的分布式锁:
SETNX lock_key 1
如果返回值为 1,表示成功获取到锁;如果返回值为 0,表示锁已经被其他客户端获取。在完成任务后,客户端可以使用 DEL 命令来释放锁:
DEL lock_key我们可以利用当该键不存在时才设置成功这一特性可以实现分布式锁,当一个线程进入某一个服务时发现setnx没有设置值,此时可以获取到锁对库存进行操作,需要注意的是setnx所设置的键需要设置过期时间,因为没有设置过期时间的话,假设获取锁的那个服务突然宕机了,此时setnx并没有设置过期时间,并一直不释放锁,导致其他服务无法获取锁,一直处于阻塞状态,只有该服务释放锁其他服务才有机会获取锁。等到所有的问题都解决完了之后,往往又会出现新的问题。如果设置了过期时间,但是我们的业务处理时间大于过期时间,也就是说过期时间到了,业务还没有处理完,锁已经被释放了,这是其他的线程又会获取锁,又会导致数据错乱的问题那又该如何解决呢?
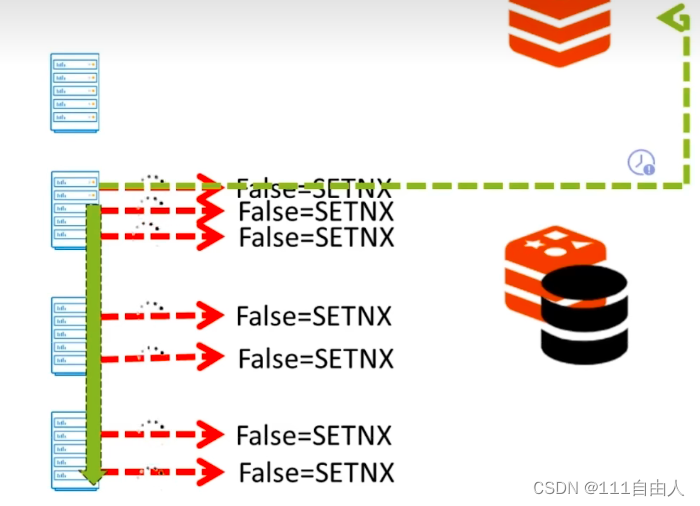
问题产生:
- 业务未处理完,锁已经释放。
- 当业务处理完之释放的是其他服务的锁。
解决思路:
- 使用一个子线程,专门去监控锁是否到了过期时间,每隔几秒就去判断是否过期,如果没有过期的话,就将过期时间重置,相当于延长过期时间,这样就保证了在业务处理完之前不会将锁释放,就解决了第一个问题
- 给锁加上一个唯一的标识,如果不是当前服务的锁,就不会释放。
但是这一系列的操作过于繁琐易出错,此时redis就提出了redisson组件去解决以上问题。
使用redisson实现分布式锁
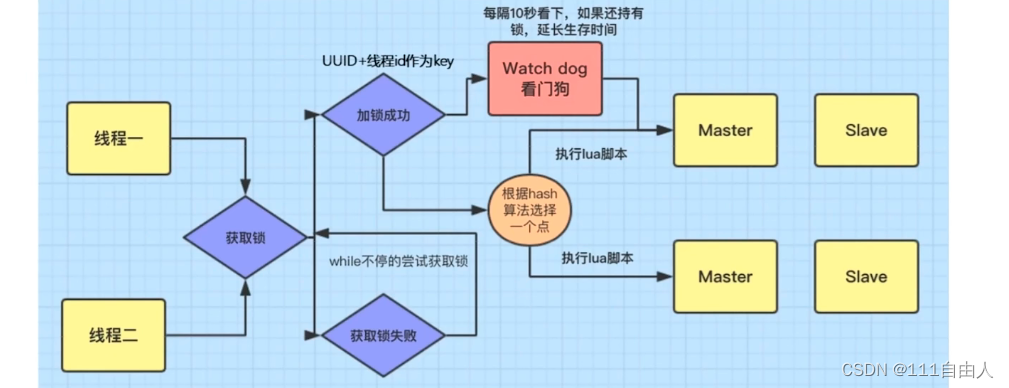
redisson在给线程加锁的过程中会自动给每一个锁附上一个唯一的标识,再使用redisson的看门狗机制给我们锁的过期时间延长 。如果redis是集群状态下使用的主从复制,主节点获取到锁之后会直接返回加锁成功,如果在加锁的过程中主节点宕机了,还未同步到从节点又会出现问题。此时redisson又提供了redlock,它的作用是只有当锁在主节点与从节点同步完成之后再返回加锁状态,这就保证了一致性。
以上就是为什么要引入redisson组件的原因了,当然还有其他处理分布式并发问题的机制,实际代码实践请关注我下一篇文章~~~~















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









