






大家好,从今天开始,笔者将会和大家分享关于自动驾驶中的 3D 目标检测、域自适应等问题,这些内容也将在微信公众号“自动驾驶与雷达感知”一起更新,想了解更多内容,欢迎同时关注!
创作不易,如有纰漏敬请指正,欢迎一起来学习讨论!
这是一篇属于解决模型自适应问题的文章,也是笔者阅读的第一篇关于域自适应的文章,所以相关的背景介绍、概念引入会稍多一点,后续的文章就不会再这么“啰嗦”了。
Part1 Train in Germany, Test in The USA: Making 3D Object Detectors Generalize
原文链接:https://arxiv.org/abs/2005.08139
发表于:CVPR (2020)。
简而言之,自适应问题通常发生在由一个数据集训练出的目标检测器等,应用于另一个数据集的情况下,通常会发生检测器性能下降。这可能是因为不同数据集之间的物体种类分布、大小等存在差异。
Part2 摘要
大多数自动驾驶数据集都是在一个国家内一小部分城市内收集的,通常也是在相似的天气条件下收集的。本文考虑的是让 3D 目标检测器从一个数据集(域)适应到另一个数据集(域)。本文观察并得到的结论是:需要克服的主要适应障碍是不同地理区域的汽车尺寸差异。基于平均汽车尺寸的简单修正就可以对适应差距进行有力的修正。
Part3 引言
自动驾驶汽车需要以 3D 方式准确检测并定位车辆和行人,以确保安全驾驶。但是在 KITTI 上训练的 3D 目标检测算法用于其他域时可能会发生各种偏差:比如模型可能期望道路可见,或者天空是蓝色的,而且模型可能只识别某些品牌的汽车,甚至可能过度适应德国司机和行人的特质。通俗来说,在 KITTI 数据集上训练的模型看 KITTI 数据集的数据更“顺眼”,如果用于其他数据集,则该模型可能会发生性能下降。
因此,本文中的目标是解决两个问题:将 3D 目标检测器部署到安全关键应用中之前了解不同数据之间存在的偏差;找到减轻这些差异的方法。
基于此,本文工作的主要贡献有以下两条:
-
本文对自动驾驶汽车环境之间的差异以及它们如何影响 3D 目标检测器性能进行了广泛的评估。本文的的研究结果认为不同地点的汽车尺寸统计是核心问题。
-
本文提出了一种简单有效的方法来缓解这个问题,通过使用易于获得的汽车尺寸聚合统计数据,并由此提高跨数据集的检测器性能。
Part4 数据集
本文首先回顾了 KITTI 数据集,并介绍了实验中使用的其他四个数据集:Argoverse,Lyft,nuScenes 和 Waymo。本文专注于与 3D 目标检测相关的数据。所有数据集都为多种对象提供真实三维边界框标签。

为了便于本文进行分析,以上数据集都整理为 KITTI 数据集的格式。
Part5 实验
A. 算法和评估指标
本文使用两个基于 LiDAR 的模型 POINTRCNN 和 PIXOR 通过输出周围的 3D 边界框来检测目标。PIXOR 在体素化后通过 3D 张量表示LiDAR点云,而 POINTRCNN 使用 PointNet++ 来提取逐点特征。
评估指标遵循 KITTI,需要评估 3D 和鸟瞰图(BEV)中的目标检测性能。本文专注于汽车这个类别,这是现有工作的焦点。如果预测的 3D 框与真实边界框的 IoU 大于 0.7,则认为正确检测到汽车。
更多具体的参数设置请见原文 4.1 节。
B. 实验结果
(1). 训练、测试均使用同一个数据集
本文首先评估在 KITTI 基准测试中表现较好的现有 3D 目标检测模型是否也可以在新发布的数据集上表现良好。按照 KITTI 数据集官方规定的评估难度划分,实验结果表明,POINTRCNN 在 KITTI,Lyft 和 Waymo 数据集上运行良好,在 Argoverse 上稍微差一点,然后是 nuScenes。本文认为这可能是由于 LiDAR 输入不同:nuScenes 只有32线光束,而 Argoverse 虽然有64线光束,但是其中每两个波束都非常接近。
(2). 训练、测试使用不同的数据集
简单来说,就是使用某个数据集来训练本文所用的 POINTRCNN 算法,然后使用其他的数据集来进行测试。
下表是详细的实验结果,其中对于每一个难度等级,行是用来训练检测器的数据集,列是用于测试检测器的数据集。例如评估难度为 Easy,第三行、第四列的结果就是在 nuScenes 数据集上进行训练、在 Lyft 数据集上进行测试的结果,其中 “89.0” 就是 POINTRCNN 的实验性能。每一列中标红的就是跨数据集的情况下,表现最好的性能,标蓝的则是最差的。对角线上标粗的则是使用同一个数据集进行训练和测试的实验结果。
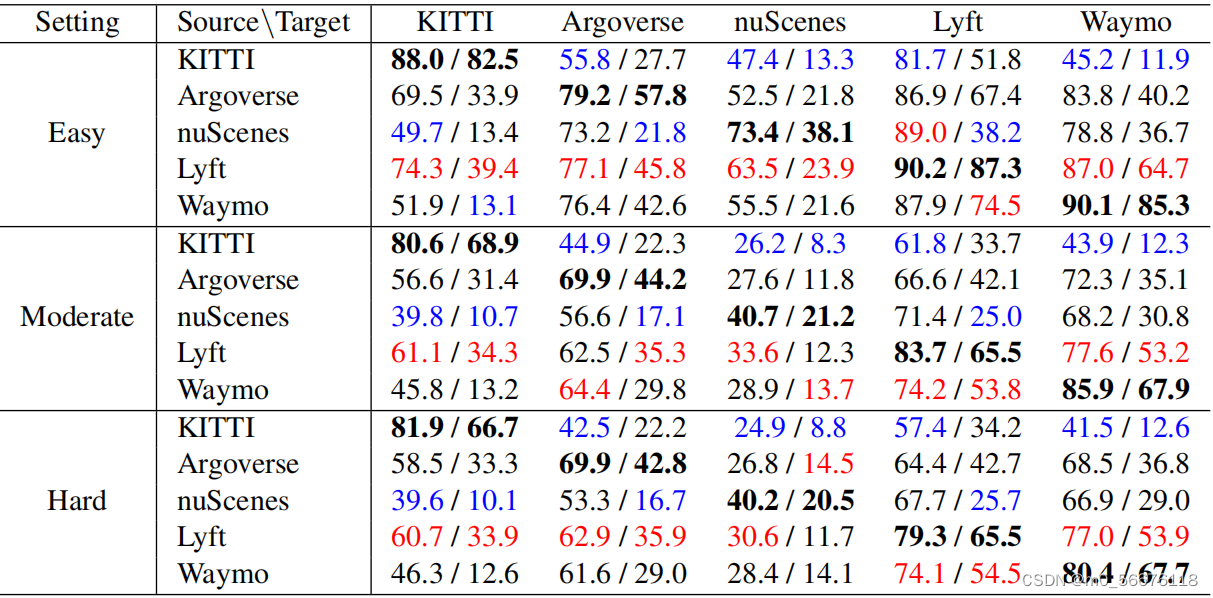
本文中其余类似表格的阅读方法同理。
C. 数据集差异分析
前面 B 的实验结果表明了跨数据集使用 3D 目标检测器会导致其准确度急剧下降。本文认为这是因为每个数据集中都存在显着的特质。特别是这些数据集中的图像和点云存在很大差异,如下图所示:

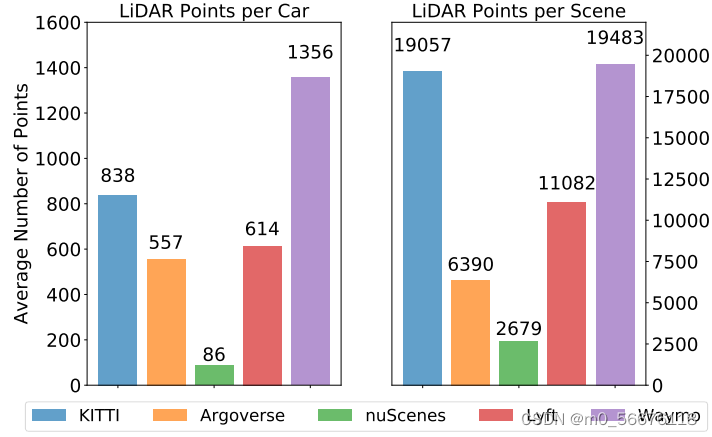
并且每个数据集的硬件设备不同,所以其每帧中的雷达点数、每辆车的 3D 边界框内的雷达点数均不同,如下表所示:
每个数据集中的汽车尺寸也不相同:

D. 泛化性能下降的原因分析
进一步的实验结果表明,检测性能下降更主要的原因是定位不准确。当 IoU 低于 0.4 时,本文观察到 立即增加,性能饱和,并且从其他数据集训练的 POINTRCNN 模型的性能与在 KITTI 上训练的模型相当。换句话说,泛化性能不好的主要原因在于定位。
更进一步的实验结果表明,检测器对汽车定位不准确的主要原因是汽车尺寸的不同。
Part6 解决方法
本文考虑了两种场景:一些带标签的场景(比如带有 3D 边界框注释的点云),或者目标数据集的汽车尺寸是可以获取到的。
对于第一种场景,可以访问来自目标数据集的几个标记场景。本文研究了使用少数镜头示例微调已经训练好的目标检测器。若仅使用目标数据集的 10 个标记场景,当将 KITTI 适应于其他数据集时,可以将 平均提高 20.4% 以上,在将其他数据集适应于 KITTI 时平均提高24.4%。
对于第二中场景,可以获取到目标数据集的汽车的长宽高。本文首先计算目标数据集和源数据集之间的平均汽车尺寸差异:
其中 就是两个数据集间汽车高度、宽度和长度的差值。然后修改源数据集中关于
的点云和标签。对于每个带注释的汽车边界框,本文通过添加
来调整其大小。本文还裁剪原始框中的点,放大或缩小其坐标以相应地适应调整后的边界框大小,然后将它们粘贴回场景的点云。通过这样做,本文生成了新的点云和标签,其汽车尺寸与目标域数据非常相似,如下图所示:
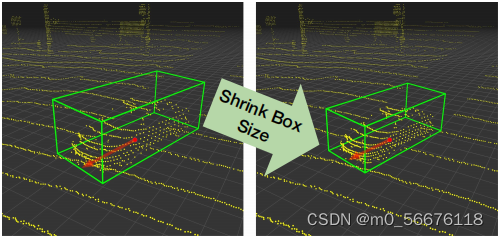
然后,本文使用这些数据在源数据集上微调已经训练好的模型。
还有一种更为简单、直接的方法,可以直接把 添加到预测边界框上。但是这样做实验结果并不好,这是因为当将源检测器应用于目标数据集时,由于输入信号中物体大小的差异,预测的框大小确实会略微偏离源统计信息到目标统计信息。因此,简单地添加
可能会过度纠正偏差。
Part7 总结
这是第一个(据作者所知)提供和研究用于自动驾驶的最广泛使用的 3D 目标检测数据集的标准化形式的公司,并且本文观察到大部分域偏移的主导因素是不同地理区域的汽车尺寸不同,而微调匹配这些区域汽车的平均尺寸就能大大降低这种不确定性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









