






原文链接:《加载自己的图像数据集》
数据集下载链接
1 加载图像数据集
目录结构:
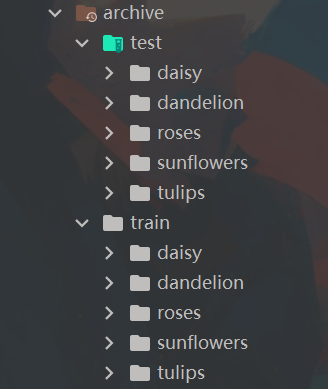
针对这种非常典型的数据集组织方式
我们可以用torchvision.datasets.ImageFolder来加载数据集
import os
import torchvision
data_path = '.\\archive'
train_dataset = torchvision.datasets.ImageFolder(os.path.join(data_path, 'train'))
注意!这并不是把训练集中所有的图像都加载到了内存,那样太耗费内存了,仅仅是把训练集中的图像在磁盘中的存储路径加载了。
train_dataset有几个重要的属性:
# 这个是一个元组列表
# 元组的第一个元素是图像在磁盘中的路径,第二个元素是图像所属的数字标签
# 类似这样('.\\archive\\train\\dandelion\\2503034372_db7867de51_m.jpg', 1)
train_dataset.imgs
# 就是我们要预测的图像所属的数字标签列表
# 顺序和上面的元组列表顺序一样
train_dataset.targets
# 类别的中文名称
# 在这里就是那5个文件夹的名称列表
train_dataset.classes
# ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
# 这是一个字典
# 键为train_dataset.classes
# 值为train_dataset.targets
train_dataset.class_to_idx
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
# 我们可以通过len(train_dataset)查看训练集中一共有多少样本
len(train_dataset) # 3670
我们可以查看一下第一张图像:
from PIL import Image
# 读取图像, train_dataset.imgs[0][0]是第一张图像的路径
img = Image.open(train_dataset.imgs[0][0])
img

2 图像预处理
前面已经看到这些图像现在都是尺寸各异,那么在正式使用这些图像之前,我们首先需要将这些图像的尺寸统一,然后还有一些其他的预处理。常见的预处理顺序是:
-
调整图像尺寸为模型规定的尺寸,比如3x224x224。
-
如果是训练集,那还要做一些数据增强操作,比如随机水平翻转图像。
-
将图像转成张量。自动归一化像素值在0到1之间,这样有助于高效训练CNN。
当然实际的预处理操作可能比这个多,这只是举个例子。
这些操作可以放到管道里依次执行:
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机缩放裁剪出224x224的区域
transforms.RandomHorizontalFlip(), # 在水平方向上随机翻转图像,50%的概率
transforms.ToTensor() # 转成张量,自动归一化到0~1
])
3 再次加载数据集
那么现在加载数据集的正确方式就是:
import os
import torchvision
import torchvision.transforms as transforms
# 如果遇到损坏的图像则跳过
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
data_path = '.\\archive'
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机缩放裁剪出224x224的区域
transforms.RandomHorizontalFlip(), # 在水平方向上随机翻转图像,50%的概率
transforms.ToTensor() # 转成张量,自动归一化到0~1
])
# 测试集的transform仅仅是缩放图像到合适尺寸并在转成张量
test_transform = transforms.Compose([
transforms.Resize(256), # 缩放到256x256的大小,因为后面要裁剪成224x224
transforms.CenterCrop(224), # 从中心裁剪成224x224的大小
transforms.ToTensor()
])
train_dataset = torchvision.datasets.ImageFolder(
os.path.join(data_path, 'train'), transform=transform)
test_dataset = torchvision.datasets.ImageFolder(
os.path.join(data_path, 'test'), transform=transform)
注意!训练集和测试集用了不同的transforms。因为在训练模型时我们需要用到tranforms来帮助我们实现数据增强(Data Augmentation)来减小模型过拟合的可能性。
4 这里还有一个问题,我们没有验证集
利用torch.utils.data.random_split可以帮助我们划分数据集,而且是保持数据集中每个类别的数据量比例不变。
import torch
# 从train_dataset中抽取80%作为训练集
num_train = int(0.8 * len(train_dataset))
# 余下20%作为验证集
num_val = int(0.2 * len(train_dataset))
# torch.manual_seed(0) 为了方便复现设置的随机抽样生成器
train, val = torch.utils.data.random_split(
train_dataset, [num_train, num_val], torch.manual_seed(0))
5 构建DataLoader
有了数据集之后我们还要批量的将数据集真正加载到内存/显存:
from torch.utils.data import DataLoader
train_dl = DataLoader(train, batch_size=128, shuffle=True)
val_dl = DataLoader(val, batch_size=128, shuffle=False)
test_dl = DataLoader(test_dataset, batch_size=128, shuffle=True)
batch_size参数表示一次性加载多少张图像(样本)进入内存。
shuffle表示是否对数据集中的图像(样本)进行混洗。
6 检查是否正确导入数据集
别忘了随机检查几份样本观察一下正确导入了数据集哦,对于图像数据集,那么就是直接画出来看:
import matplotlib.pyplot as plt
imgs, labels = next(iter(train_dl)) # 从train_dl中取出一个批次的数据, iter()是生成器, next()是迭代器
figure = plt.figure(figsize=(10, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
img, label = imgs[i], labels[i] # imgs[i]是第i张图像, labels[i]是第i张图像的标签
figure.add_subplot(rows, cols, i)
plt.title(train_dataset.classes[label])
plt.axis("off")
# img.permute(1, 2, 0)是将张量的维度换位, 使得第0维度在最后, 以便于matplotlib显示,
# 因为matplotlib显示的是RGB图像, 而pytorch的图像是CHW格式, 所以需要将CHW转换为HWC
plt.imshow(img.permute(1, 2, 0))
plt.show()
















 1427
1427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









