








研究动机
- 解决现有数据集的不足:当前数据集提供的图像文本对过于简单,不足以支持模型对图像的深入理解。文章提出了一种自动多层次描述生成方法,通过结合多个先进的系统(如BLIP2、PPOCR、GRIT、SAM和ChatGPT),生成高质量、丰富的描述数据,以弥补现有数据集的不足。
- 提升多模态模型的性能:文章通过引入高分辨率图像和多层次描述生成方法,旨在增强模型对图像细节的理解和描述能力。
主要贡献
- 无需预训练,支持分辨率高达1344×896。
- 上下文关联。我们引入了一种多级描述生成方法,提高了模型掌握多个目标之间关系的能力,并更有效地利用常识来生成文本描述。
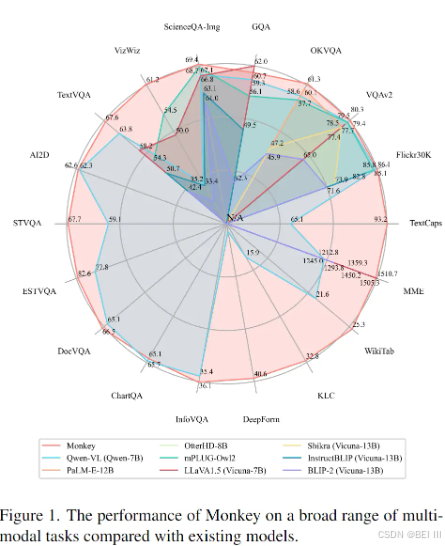
- 在许多评估数据集的性能增强。
主要方法
Monkey的整体架构
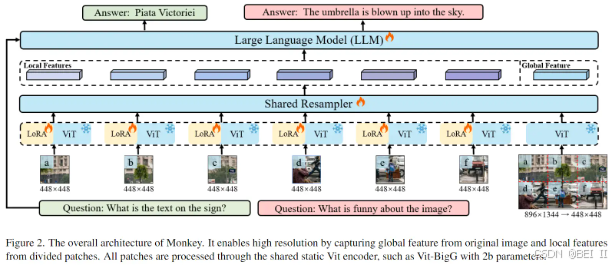
Monkey的整体架构。它通过从原始图像中捕获全局特征和从分割块中捕获局部特征来实现高分辨率。所有补丁均通过共享静态 Vit 编码器进行 处理,例如具有 2b 参数的 Vit-BigG
提高输入分辨率
由于输入分辨率对准确解释文本和图像特征非常重要,但是当前有效的方法,如课程学习对资源要求很高。
- 文章引入了简单有效的方法:滑动窗口技术:

- 将原始图像也调整为
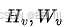 ,维持为全局图像。
,维持为全局图像。 - 在每个share encoder中利用LoRA处理图像不同部分的各种视觉元素(?)。
- 通过视觉编码器和重采样器同时处理局部图片和全局图像
- 重采样器shared Resampler主要功能:

多层次描述生成
为了创建详细且高质量的图像描述数据,本方法结合了多个先进的系统:
- BLIP2:提供图像与文本之间关系的深入理解。
- PPOCR:在光学字符识别方面表现出色。
- GRIT:专注于详细的图像-文本匹配。
- SAM:专注于语义对齐。
- ChatGPT:以其卓越的上下文语言生成能力著称。
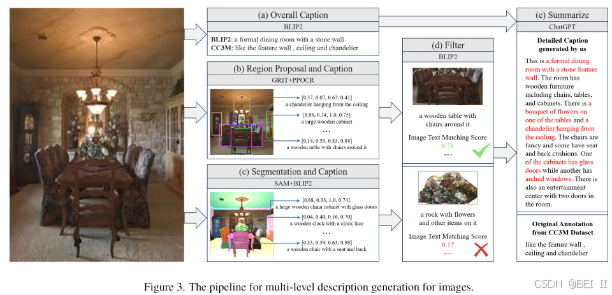
如图 3 所示,
- 图像描述过程从 BLIP2 开始,使用 Q-former 与视觉编码器和 LLM 紧密集成,创建整体字幕,同时保留原始的 CC3M 注释语境。
- GRIT生成特定区域、对象及其特征的详细描述。PPOCR 从图像中提取文本,
- SAM 分段并识别对象及其部分。然后这些对象是由 BLIP2单独描述。
- 然而,为了应对这些工具潜在的不准确性,特别是在零样本设置中,我们发现有必要进一步使用 BLIP2来检查图像区域、对象及其描述之间的一致性,过滤掉低分匹配。
- 最后,所有数据,包括全局标题、本地化描述、文本摘录和带有空间坐标的对象详细信息,都被输入ChatGPT API 进行微调,使 ChatGPT 能够生成准确且上下文丰富的图像描述。
本文使用多级描述生成方法从 CC3M 数据集中重新生成大约 427k 图像文本对,这些数据集先前用于 LLaVA 的预训练阶段。
多任务训练
Task:
- creating image captions
- responding to image-based questions
- activities requiring the model to process both text and images
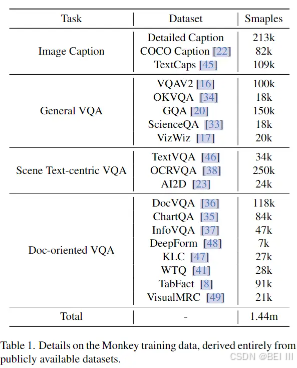
展示了Monkey训练数据的详细信息:
实验
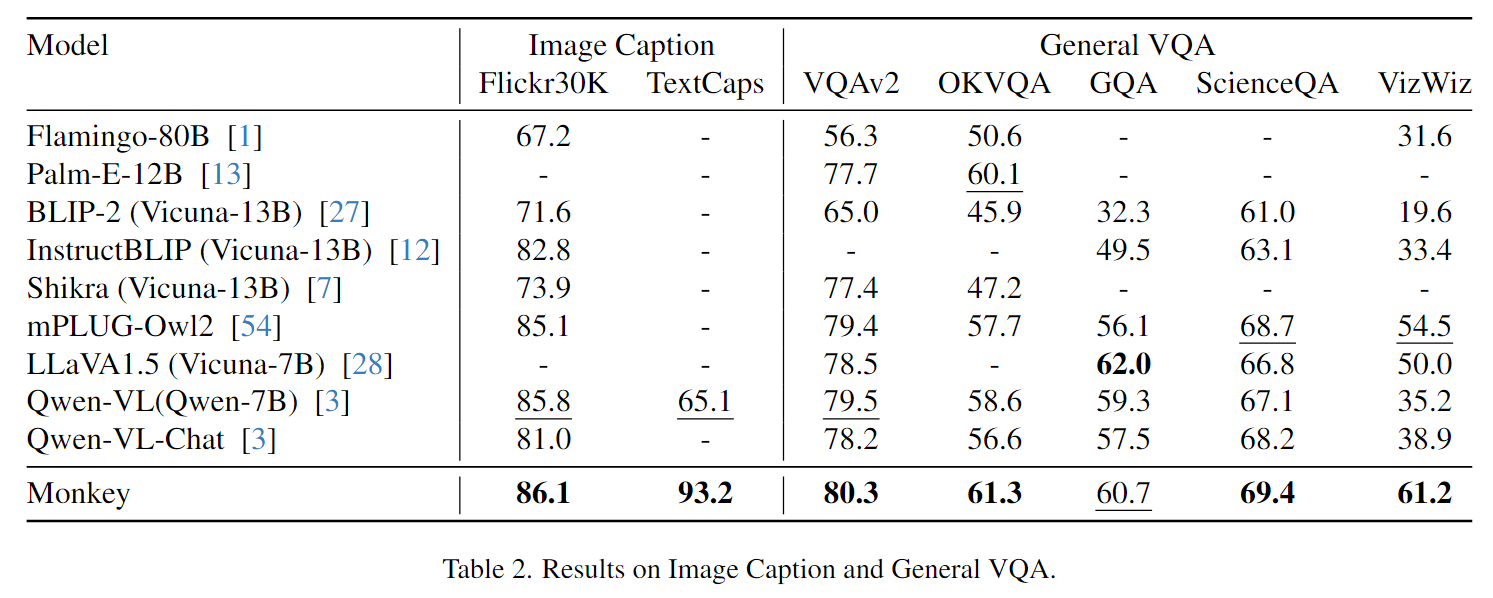
图注和一般VQA
场景VQA
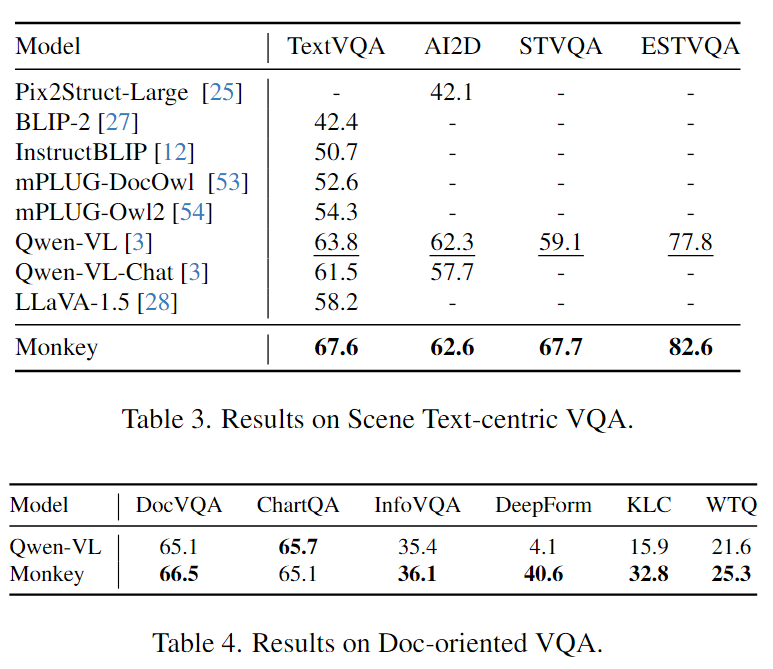
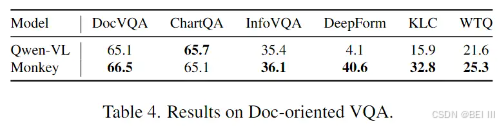
文档VQA
消融实验
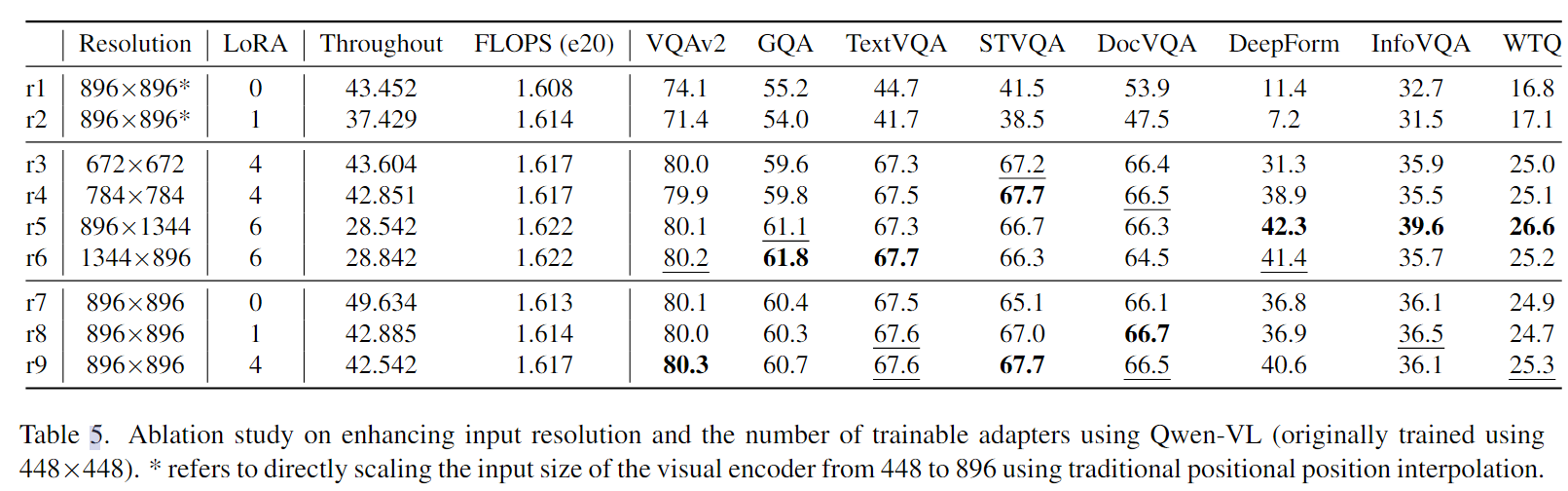
使用 Qwen-VL 增强输入分辨率和可训练适配器数量的消融研究(最初使用 448×448 进行训练)。
* 是指使用传统的位置插值直接将视觉编码器的输入大小从 448 缩放到 896,(r1,r2)。
现象:
- r1,r9:使用传统插值方法和本文方法提高分辨率的对比-本文方法更好
- r1,r2:将LoRA应用于传统方法比不用效果还差
- r3-r9: 随着分辨率的增加,性能会提升,在DeepForm数据集上比较明显
- LoRA的添加没有显著增加FLOPs
本文方法在LLaVA1.5上的有效性
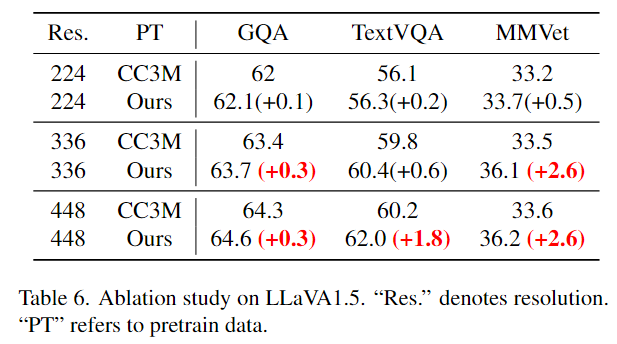
与224分辨率相比, detailed descriptions在336和448分辨率下始终能产生更大的性能增强



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









