







前言
高并发十分考验架构师功底,它也是分布式架构设计中必须考虑的因素之一。要知道,光靠服务器堆是没有出路的。
想看看大牛是怎么面对高并发的?想知道BATJ大厂是怎么设计高可用架构的?这里有可参考的实践案例,干货满满,或许能对你有所启发。
Redis常用的数据类型
Redis的五种常用的数据类型分别是:String、Hash、List、Set和Sorted set
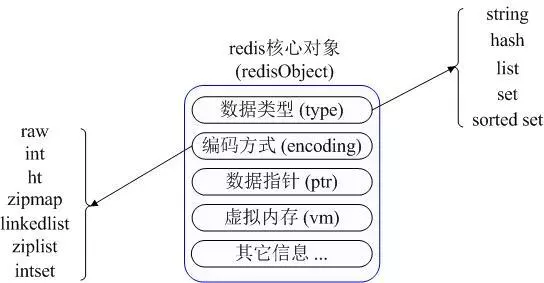
Redis的使用场景
1.Counting(计数)
2.展示最近、最热、点击率最高、活跃度最高等等条件的top list
3.用户最近访问记录也是redis list的很好应用场景
4.通过list的lpop及lpush接口进行队列的写入和消费
5.Redis 的Lua的功能扩展实际给Redis带来了更多的应用场景,你可以编写若干command组合作为一个小型的非阻塞事务或者更新逻辑
6.Redis提供的主从数据同步功能,其实是对cache的一个强有力功能扩展
一、业务场景介绍
先来给大家说一个业务场景,假设咱们现在开发一个电商网站,要实现支付订单的功能,流程如下:
创建一个订单之后,如果用户立刻支付了这个订单,我们需要将订单状态更新为“已支付”
扣减相应的商品库存
通知仓储中心,进行发货
给用户的这次购物增加相应的积分
针对上述流程,我们需要有订单服务、库存服务、仓储服务、积分服务。整个流程的大体思路如下:
用户针对一个订单完成支付之后,就会去找订单服务,更新订单状态
订单服务调用库存服务,完成相应功能
订单服务调用仓储服务,完成相应功能
订单服务调用积分服务,完成相应功能
至此,整个支付订单的业务流程结束
下图这张图,清晰表明了各服务间的调用过程:

好!有了业务场景之后,咱们就一起来看看Spring Cloud微服务架构中,这几个组件如何相互协作,各自发挥的作用以及其背后的原理。
二、Spring Cloud核心组件:Eureka
咱们来考虑第一个问题:订单服务想要调用库存服务、仓储服务,或者是积分服务,怎么调用?
订单服务压根儿就不知道人家库存服务在哪台机器上啊!他就算想要发起一个请求,都不知道发送给谁,有心无力!
这时候,就轮到Spring Cloud Eureka出场了。Eureka是微服务架构中的注册中心,专门负责服务的注册与发现。
咱们来看看下面的这张图,结合图来仔细剖析一下整个流程:

如上图所示,库存服务、仓储服务、积分服务中都有一个Eureka Client组件,这个组件专门负责将这个服务的信息注册到Eureka Server中。说白了,就是告诉Eureka Server,自己在哪台机器上,监听着哪个端口。而Eureka Server是一个注册中心,里面有一个注册表,保存了各服务所在的机器和端口号
订单服务里也有一个Eureka Client组件,这个Eureka Client组件会找Eureka Server问一下:库存服务在哪台机器啊?监听着哪个端口啊?仓储服务呢?积分服务呢?然后就可以把这些相关信息从Eureka Server的注册表中拉取到自己本地缓存起来。
这时如果订单服务想要调用库存服务,不就可以找自己本地的Eureka Client问一下库存服务在哪台机器?监听哪个端口吗?收到响应后,紧接着就可以发送一个请求过去,调用库存服务扣减库存的那个接口!同理,如果订单服务要调用仓储服务、积分服务,也是如法炮制。
总结一下:
Eureka Client:负责将这个服务的信息注册到Eureka Server中
Eureka Server:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
三、Spring Cloud核心组件:Feign
现在订单服务确实知道库存服务、积分服务、仓库服务在哪里了,同时也监听着哪些端口号了。但是新问题又来了:难道订单服务要自己写一大堆代码,跟其他服务建立网络连接,然后构造一个复杂的请求,接着发送请求过去,最后对返回的响应结果再写一大堆代码来处理吗?
这是上述流程翻译的代码片段,咱们一起来看看,体会一下这种绝望而无助的感受!!!
友情提示,前方高能:
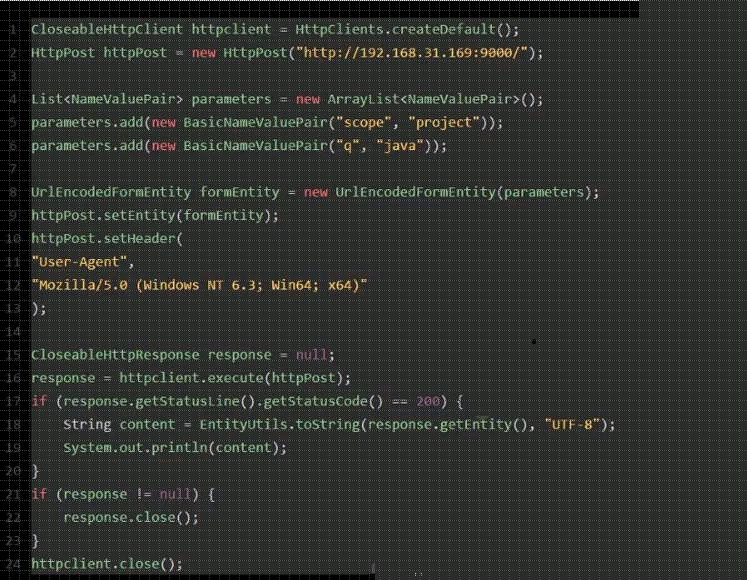
看完上面那一大段代码,有没有感到后背发凉、一身冷汗?实际上你进行服务间调用时,如果每次都手写代码,代码量比上面那段要多至少几倍,所以这个事儿压根儿就不是地球人能干的。
既然如此,那怎么办呢?别急,Feign早已为我们提供好了优雅的解决方案。来看看如果用Feign的话,你的订单服务调用库存服务的代码会变成啥样?

看完上面的代码什么感觉?是不是感觉整个世界都干净了,又找到了活下去的勇气!没有底层的建立连接、构造请求、解析响应的代码,直接就是用注解定义一个 FeignClient接口,然后调用那个接口就可以了。人家Feign Client会在底层根据你的注解,跟你指定的服务建立连接、构造请求、发起靕求、获取响应、解析响应,等等。这一系列脏活累活,人家Feign全给你干了。
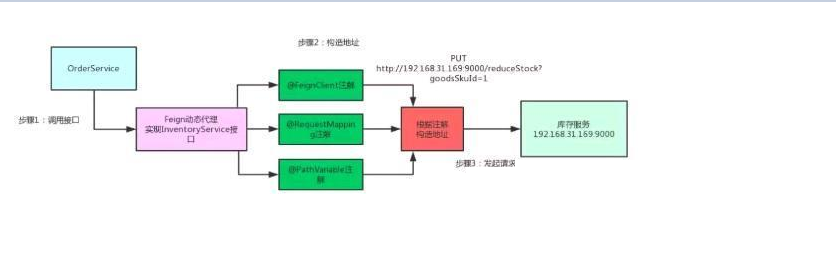
那么问题来了,Feign是如何做到这么神奇的呢?很简单,Feign的一个关键机制就是使用了动态代理。咱们一起来看看下面的图,结合图来分析:
首先,如果你对某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理
接着你要是调用那个接口,本质就是会调用 Feign创建的动态代理,这是核心中的核心
Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址
最后针对这个地址,发起请求、解析响应
四、Spring Cloud核心组件:Ribbon
说完了Feign,还没完。现在新的问题又来了,如果人家库存服务部署在了5台机器上,如下所示:
192.168.169:9000
192.168.170:9000
192.168.171:9000
192.168.172:9000
192.168.173:9000
这下麻烦了!人家Feign怎么知道该请求哪台机器呢?
这时Spring Cloud Ribbon就派上用场了。Ribbon就是专门解决这个问题的。它的作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上
Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法。这是啥?简单来说,就是如果订单服务对库存服务发起10次请求,那就先让你请求第1台机器、然后是第2台机器、第3台机器、第4台机器、第5台机器,接着再来—个循环,第1台机器、第2台机器。。。以此类推。
此外,Ribbon是和Feign以及Eureka紧密协作,完成工作的,具体如下:
首先Ribbon会从 Eureka Client里获取到对应的服务注册表,也就知道了所有的服务都部署在了哪些机器上,在监听哪些端口号。
然后Ribbon就可以使用默认的Round Robin算法,从中选择一台机器
Feign就会针对这台机器,构造并发起请求。
对上述整个过程,再来一张图,帮助大家更深刻的理解:

最后
这份文档从构建一个键值数据库的关键架构入手,不仅带你建立起全局观,还帮你迅速抓住核心主线。除此之外,还会具体讲解数据结构、线程模型、网络框架、持久化、主从同步和切片集群等,帮你搞懂底层原理。相信这对于所有层次的Redis使用者都是一份非常完美的教程了。

快速入手通道:(戳这里,免费下载)诚意满满!!!
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!
703)]
快速入手通道:(戳这里,免费下载)诚意满满!!!
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!















 3175
3175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









