






活字通用大模型简介
活字通用大模型是由哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)开发的一系列中文自然语言处理大模型。其最新版本活字3.0是一个稀疏混合专家模型(SMoE),支持32K上下文,具有丰富的中英文知识和强大的数学推理、代码生成能力。
模型版本与下载
活字大模型目前有以下几个主要版本:
- 活字3.0: 最新版本,基于Chinese-Mixtral-8x7B微调得到
- 活字2.0: 在活字1.0基础上通过RLHF优化
- 活字1.0: 在Bloom模型基础上进行指令微调
各版本模型下载链接:
使用教程
基本使用
活字3.0采用ChatML格式的prompt模板,基本使用示例如下:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "HIT-SCIR/huozi3"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))
高级应用
活字3.0支持以下高级应用:
- 使用vLLM进行推理加速
- 部署为OpenAI API兼容的服务
- 使用GGUF或AWQ格式进行量化推理
详细教程请参考GitHub仓库。
性能评测
活字3.0在多个权威中英文评测数据集上表现出色,包括C-Eval、CMMLU、MMLU、GSM8K等。具体评测结果如下:
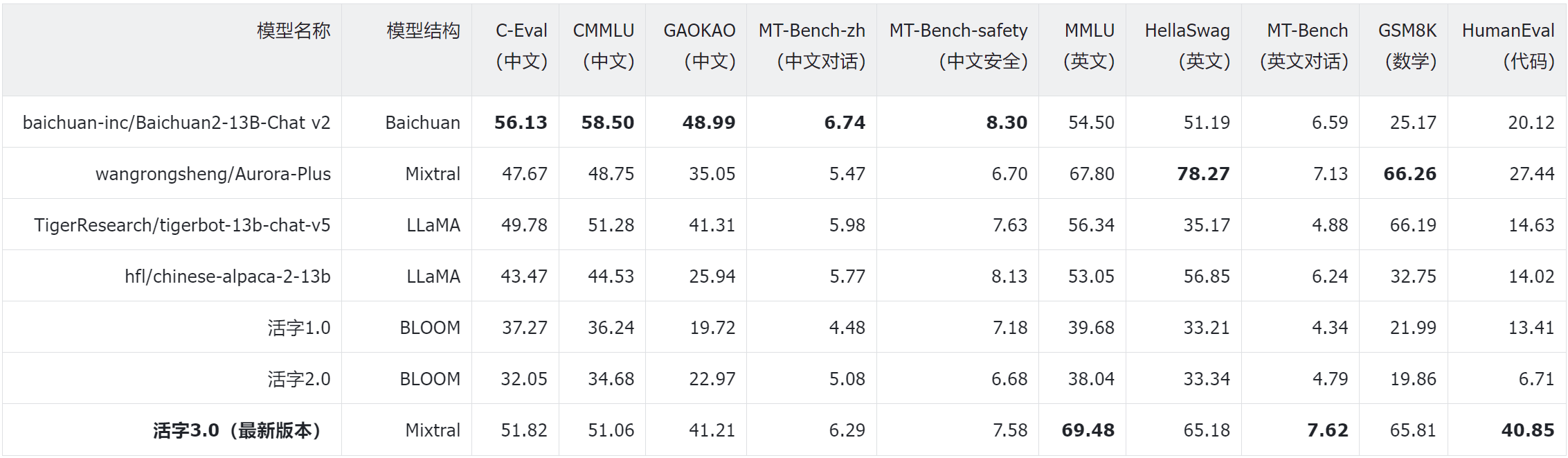
相关资源
活字大模型为中文自然语言处理领域带来了革新性的技术。无论是研究人员还是开发者,都可以通过上述资源深入了解和应用这一先进技术,共同推动中文NLP的发展。
文章连接:www.dongaigc.com/a/generalized-model-learning-resources-nlp
https://www.dongaigc.com/a/generalized-model-learning-resources-nlp
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









