







我们遇到的所有事情本身都是无意义的,所有的意义都是我们根据自己的信念系统,人为给加上去的。因此,如果你想你的世界变得更好,你无须改变外面的世界,你只要改变自己脑海里的世界。

应用程序产生的数据是在内存中的,如果程序退出或者是断电了,则数据就会消失。使用数据库是为了能够永久保存数据
1、SQL是结构化查询语言(Structure Query Language),专门用来操作/访问数据库的通用语言。
2、MySQL数据库现在隶属于Oracle(甲骨文)公司
3、关系型数据库,关系模型指的就是二维表格模型
安装、卸载MySQL
1、查看MySQL服务
1.在win10操作界面中,使用组合键“win+R”运行“services.msc”,进入本地服务窗口;
2.进入本地服务窗口后,在服务列表中,查找到MySQL服务;
3.查找到MySQL服务后,即可查看mysql服务的启动状态,右键可以选择启动或停止MySQL服务;
1、停止服务
此电脑-右键-管理-服务和应用程序-右键-停止mysql服务2.控制面板卸载
控制面板-卸载程序-mysql右键卸载
2、MySQL环境变量
mysql安装目录的bin目录,配置到环境变量path中
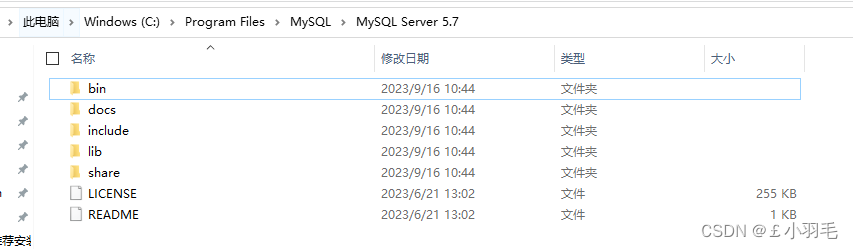
| 环境变量名 | 操作 | 环境变量值 |
|---|---|---|
| MYSQL_HOME | 新建 | C:\Program Files\MySQL\MySQL Server 5.7 |
| path | 编辑 | %MYSQL_HOME%\bin |
3、登录MySQL
-p与密码之间不能有空格,其他参数名与参数值之间可以有空格也可以没有空格
mysql -h localhost -p3306 -uroot -p
-h:host 主机名/IP地址
-P:port端口号
-u:user 用户名
-p:password密码出现下图这样的效果便是好了
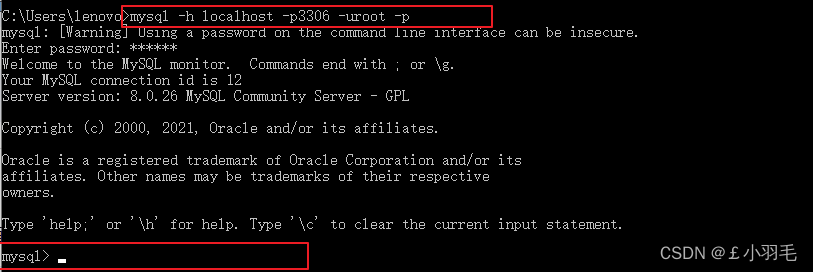
如果是连本机:-h localhost就可以省略,如果端口号没有修改:-P3306也可以省略,最后简写如下:
mysql -u root -p
登录成功后,查看所有的数据库
show databases;
选择数据库,并查看该数据库中的所有表

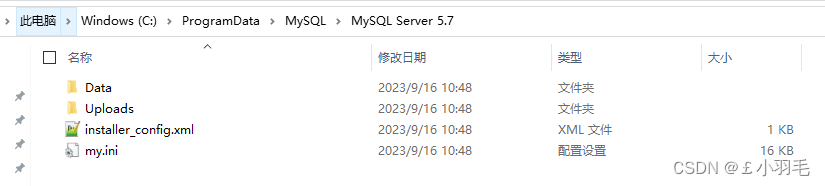
4、my.ini配置内容
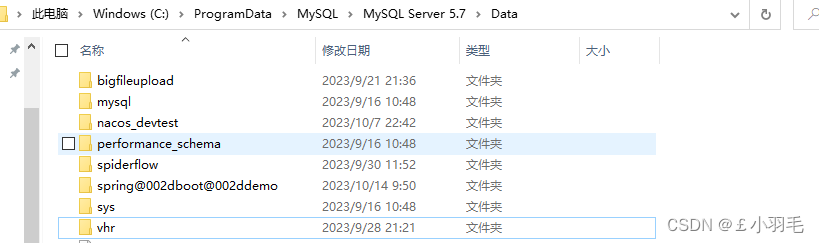
Data目录,是用户创建的数据库所在的目录
my.ini是MySQL数据库中使用的配置文件,其路径默为”C:\ProgramData\MySQL\MySQL Server X.X”,其中X.X表示版本号
大体两部分:MySQL客户端和服务器端的配置。其中,
- client配置项用于指定MySQL客户端的连接参数
- mysqld配置项用于指定MySQL服务器的参数。
服务器端参数:
以下是参数的介绍:
-
port参数也是表示数据库的端口。 -
basedir参数表示MySQL的安装路径。 -
datadir参数表示MySQL数据文件的存储位置,也是数据库表的存放位置。
[client]代表客户端默认设置内容;
[mysql]代表我们使用mysql命令登录mysql数据库时的默认设置;
[mysqld]代表数据库自身的默认设置;
[client]
port=3306
[mysql]
default-character-set=gbk
[mysqld]
port = 3306
socket = /tmp/mysql.sock
# 设置mysql的安装目录
basedir=F:\\Hzq Soft\\MySql Server 51GA
# 设置mysql数据库的数据的存放目录,必须是data,或者是\\xxx-data
datadir=F:\\Hzq Soft\\MySql Server 51GA\\data
#innodb_log_arch_dir 默认datadir
#innodb_log_group_home_dir 默认datadir
# 设置mysql服务器的字符集,默认编码
default-character-set=utf8
#连接数的操作系统监听队列数量,如果经常出现“拒绝连接”错误可适当增加此值
back_log = 50
#不使用接听TCP / IP端口方法,mysqld通过命名管道连接
#skip-networking
# 最大连接数量
max_connections = 90
#打开表的线程数量限定,最大4096,除非用mysqld_safe打开限制
table_open_cache = 2048
#MySql 服务接收针对每个进程最大查询包大小
max_allowed_packet = 16M
#作用于SQL查询单笔处理使用的内存缓存,如果一笔操作的二进制数据超过了限定大小,将会在磁盘上开辟空间处理,一般设为 1-2M即可,默认1M
binlog_cache_size = 2M
#单个内存表的最大值限定
max_heap_table_size = 64M
#为每个线程分配的排序缓冲大小
sort_buffer_size = 8M
#join 连表操作的缓冲大小,根据实际业务来设置,默认8M
join_buffer_size = 32M
#操作多少个离开连接的线程的缓存
thread_cache_size = 8
#并发线程数量,默认为8,可适当增加到2倍以内。如果有多个CPU可以乘 上CPU的数量。双核CPU可以乘 上当前最核数再乘 上70%-85%
thread_concurrency = 16
#专用于具体SQL的缓存,如果提交的查询与几次中的某查询相同,并且在query缓存中存在,则直接返回缓存中的结果。
query_cache_size = 64M
#对应上一条设置,当查询的结果超过下面设置的大小时,将不会趣入到上面设置的缓存区中,避免了一个大的结果占据大量缓存。
query_cache_limit = 2M
#设置加全文检索中的最小单词长度。
#ft_min_word_len = 4
#CREATE TABLE 语句的默认表类型,如果不自己指定类型,则使用下行的类型
default-storage-engine = InnoDB
#线程堆栈大小,mysql说它自己用的堆栈大小不超过64K。这个值可适当设高一点(在RCA的项目中都是共用同一个数据库连接的),默认192K
thread_stack = 800K
#设置事务处理的级别,默认 REPEATABLE-READ,一般用它就即可,以下二行按顺序对应,
#可读写未提交的数据,创建未提交的数据副本读写,未提交之前可读不可写,只允许串行序列招行事务。
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE
transaction_isolation = REPEATABLE-READ
#单一内存临时表在内存中的大小,超过此值自动转换到磁盘操作
tmp_table_size = 64M
#启动二进制日志功能,可通过它实现时间点恢复最新的备份
#log-bin=mysql-bin
#二进制日志格式,对就上一条,-建议混合格式
#binlog_format=mixed
#转换查询为缓慢查询
slow_query_log
#对应上一条,如果一个查询超过了下条设定的时间则执行上一条。
long_query_time = 2
#自定义主机ID识别符,用于主从或多服务器之间识别,为 一个 int 类型
server-id = 1
#一般用来缓存MyISAM表的主键,也用于临时的磁盘表缓存主键,上面多次出现临时磁盘表,所以就算不用MyISAM也最好为其设置一个不小的值,默认32M
key_buffer_size = 56M
#全表扫描MyISAM表时的缓存,每个线程拥有下行的大小。
read_buffer_size = 2M
#排序操作时与磁盘之间的缓存,分到每个线程,默认16M
read_rnd_buffer_size = 16M
#MyISAM使用特殊树形进行批量插入时的缓存,如insert ... values(..)(..)(..)
bulk_insert_buffer_size = 64M
#MyISAM索引文件的最大限定,
myisam_max_sort_file_size = 12G
#如果一个myisam表有一个以上的索引, MyISAM可以使用一个以上线程来排序并行它们。较耗硬件资源,如果你的环境不错,可以增加此值。
myisam_repair_threads = 2
#自动检查和修复无法正确关闭MyISAM表。
myisam_recover
# *** INNODB Specific options ***
#开启下条将会禁用 INNODB
#skip-innodb
#一般不用设置或者说设了也没多大用,InnoDB会自己与操作系统交互管理其附加内存池所使用InnoDB的存储数据的大小
innodb_additional_mem_pool_size = 16M
#innodb整体缓冲池大小,不宜过大,设为本地内存的 50%-75% 比较合适,在本机开发过程中可以设得较小一点如 64M,256M
innodb_buffer_pool_size = 256M
#InnoDB的数据存储在一个或多个数据文件组成的表空间
innodb_data_file_path = ibdata1:10M:autoextend
#用于异步IO操作的线程数量,默认为 4 ,可适当提高
innodb_file_io_threads = 8
#线程数内允许的InnoDB内核,不宜太高
innodb_thread_concurrency = 14
#InnoDB的事务日志快存行为,默认为 1,为0可减轻磁盘I/0操作,还有以为2
innodb_flush_log_at_trx_commit = 1
#InnoDB的用于的缓冲日志数据的大小
innodb_log_buffer_size = 16M
#日志文件,可设置为25%-90%的总体缓存大小,默认 256M. 修改此项要先删除datadir\ib_logfileXXX
innodb_log_file_size = 256M
#日志组数量,默认为3
innodb_log_files_in_group = 3
#InnoDB的日志文件位置。默认是MySQL的datadir
#innodb_log_group_home_dir
#InnoDB最大允许的脏页缓冲池的百分比,默认90
innodb_max_dirty_pages_pct = 90
#事务死锁超时设定
innodb_lock_wait_timeout = 120
[client]
port = 3306
socket = /tmp/mysql.sock
# 设置mysql客户端的字符集
default-character-set=utf8
[mysqldump]
quick
max_allowed_packet = 16M
[mysql]
no-auto-rehash
# Only allow UPDATEs and DELETEs that use keys.
#safe-updates
[WinMySQLAdmin]
# 指定mysql服务启动启动的文件
Server=F:\\myweb\\MySql Server\\bin\\mysqld.exe
5、mysql安装目录
在Windows系统下,MySQL的默认安装目录通常为”C:\Program Files\MySQL\MySQL Server X.X”,其中X.X表示版本号

Data目录:存放数据库
MySQL的安装目录中包含了几个重要的文件夹和文件,分别是:
1. bin
bin文件夹中包含了MySQL的可执行文件,如MySQL客户端、MySQL服务器、mysqldump等。这些程序可以通过命令行或脚本来调用。以下是bin文件夹中一些重要的文件:
– mysql.exe:MySQL客户端
– mysqldump.exe:备份数据使用
– mysqladmin.exe:管理MySQL服务器
– mysqlcheck.exe:检查MySQL表是否损坏
– mysqld.exe:MySQL服务器运行文件
2. data
data文件夹通常用于存放MySQL的存储数据,比如数据库表、索引等。在安装MySQL时,会由用户指定data目录以及该目录的大小。
3. include
include文件夹中包含了MySQL的头文件,用于开发MySQL的应用程序。通常情况下,普通用户不需要使用该文件夹。
4. lib
lib文件夹中包含了MySQL的库文件(即.dll文件),这些文件可以被开发人员引用到。lib文件夹中还包含了与MySQL一同安装的第三方库文件。以下是lib文件夹中一些重要的文件:
– libmysql.dll:MySQL客户端库文件
– libmysqlserver.dll:MySQL服务器库文件
5. share
share文件夹中包含了MySQL的共享文件,如charsets目录、english目录等。这些文件可以被MySQL客户端或服务器使用。
6、mysqld命令启动
windows mysqld启动命令
mysqld --console比如我在排查这个报错的时候就用到了:mysql can not find error-message file errmsg.sys
在命令行初始化MySQL的时候,报错找不到这个errmsg.sys文件,解决方案是在my.ini文件中,使用双斜杠来代替单斜杠
basedir=E:\\rcc\\RCC\\DBSVR
datadir=E:\\rcc\\RCC\\DBSVR\\Data数据库和数据表命令
1.MySQL数据库命令
查看所有的数据库
show databases;创建自己的数据库
#创建数据库 huya CREATE DATABASE huya;删除数据库
#删除数据库 huya DROP DATABASE huya;使用自己的数据库
使用完use语句之后,如果接下来的SQL都是针对一个数据库操作的,那就不用重复use了,如果要针对另一个数据库操作,那么要重新use。
#使用huya数据库 USE huya;
2.MySQL数据表命令
查看某个库的所有表格
#使用huya数据库 USE huya; #要求前面有use语句 SHOW TABLES;或者
#查看数据库bookstore中的所有表格 SHOW TABLES FROM bookstore;
------------------------------------
创建表格
create table 表名称( 字段名 数据类型, 字段名 数据类型 ); #创建学生表 create table student( id int, name varchar(20) #名字最长不超过20个字符 );------------------------------
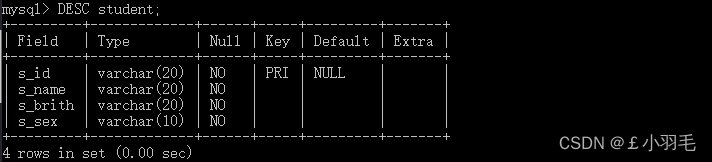
查看定义好的表结构
#desc 表名称 DESC student;
--------------------------------------
删除表
#删除学生表 DROP TABLE student;

除了通过命令行来创建数据库和数据表,还可以借助MySQL图形化工具(如SQLyog和Navicate),而且图形化方式更加简单、方便。
3.FOREIGN_KEY_CHECKS
为MySQL中设置了foreign key关联,造成无法更新或删除数据。可以通过设置FOREIGN_KEY_CHECKS变量来避免这种情况
我们可以禁用外键约束.
SET FOREIGN_KEY_CHECKS=0;之后再用来启动外键约束.
SET FOREIGN_KEY_CHECKS=1;SQL语句分类与规范
SQL:结构化查询语言,(Structure Query Language),专门用来操作/访问数据库的通用语言。
1、SQL语句的分类
DDL语句:数据定义语句(Data Define Language),例如:创建(create),修改(alter),删除(drop)等
DML语句:数据操作语句,例如:增(insert),删(delete),改(update),查(select)
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类,DQL(数据查询语言),DR(获取)L
DCL语句:数据控制语句,例如:grant,commit,rollback等
其他语句:USE语句,SHOW语句,SET语句等。这类的官方文档中一般称为命令。
2、SQL语句的规范
1.SQL语句大小写不敏感 sql规范 :习惯上关键字大写,表名,列名小写
2.关键字不可以分行
3.给列和表起别名注意事项如下:
列的别名有空格时,请加双引号。列的别名中没有空格时,双引号可以加也可以不加。
表的别名不能加双引号,表的别名中间不能包含空格。
as大小写都可以,as也完全可以省略
select 字段名1 as "别名1", 字段名2 as "别名2" from 表名称 as 别名;
4.SQL语句中,只有给列起别名的时候,才用双引号
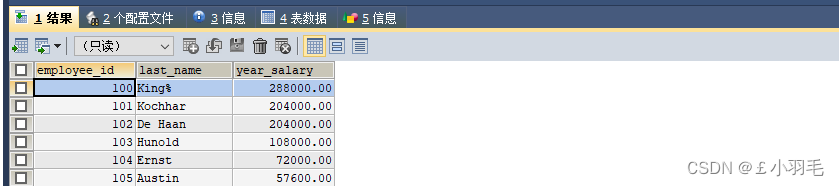
SELECT `employee_id`,`last_name`,`salary`*12*(1+IFNULL(`commission_pct`,0)) year_salary FROM `employees`;
3、引号的用法
单引号:
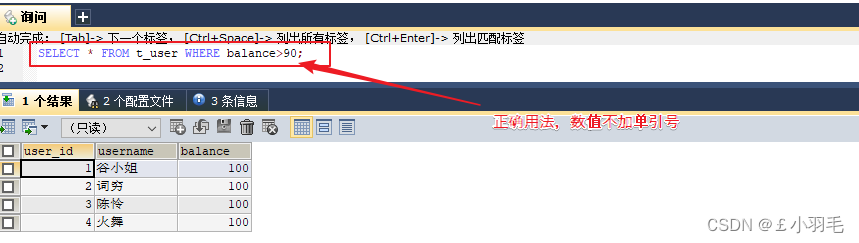
SQL 使用单引号来环绕文本值。字符串和日期类型的数据值使用单引号''引起来
------------------------------
如果是数值,请不要使用引号

反引号的作用和意义:MySQL 中的反引号仅用于表名和列名是保留字时,使用反引号转义保留字。如果表名或列名不是保留字,可以不加反引号。
务必要记住:保留字既不能作为表名,也不能作为字段名,如果非要这么操作,请记住要增加反引号!
双引号:列的别名可以使用双引号""(列别名没有空格则可以不加双引号),给表名取别名不要使用双引号。
MYSQL数据类型
数据类型概述
大体分为数值类型、日期时间类型、字符串类型...

整形类型
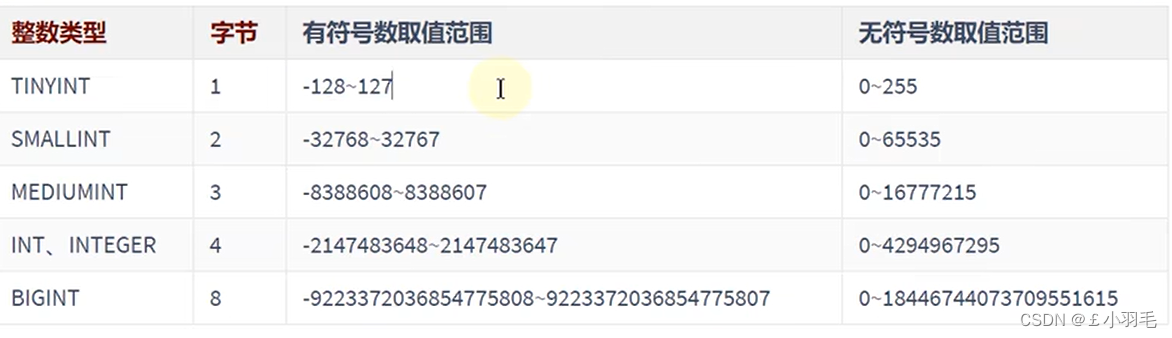
整数类型一共5种,包括TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)、BIGINT
要是插入的数据,超过范围则报错
out of range value for column 'xxx'
整数类型的可选属性
显示宽度INT(M)
显示宽度INT(M)一定要配合ZEROFEILL使用才有效果,举例如下
注意:使用ZEROFEILL时,自动添加UNSIGNED
效果:不足5位是用0填充 ,超过5位该显示啥显示啥
-------------------------------------------------
UNSIGNED




字符串类型
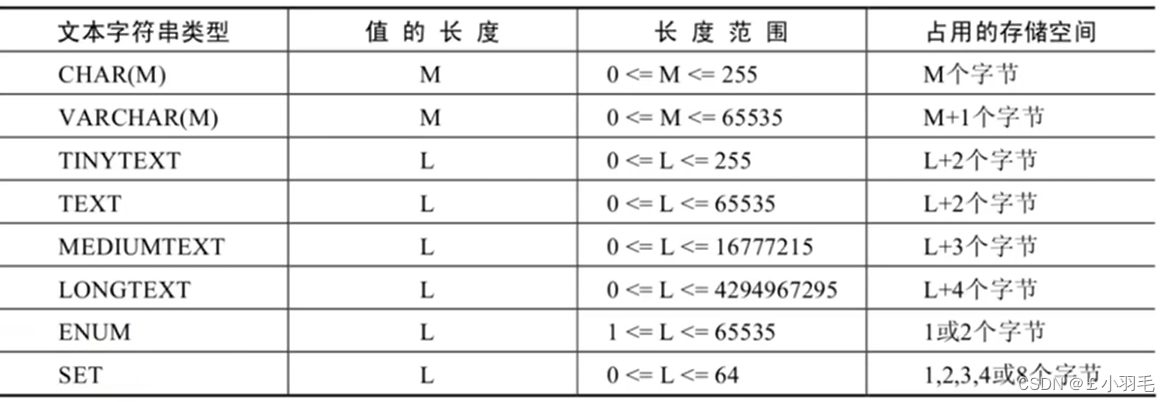
CHAR(M) 和 VARCHAR(M)
这俩用来存储较短的字符串
CHAR(M),如果不指定M,默认1个字符,在定义CHAR类型字段时,声明的字段长度即为CHAR类型字段所占用的存储空间字节数
VARCHAR(M)注意点如下:


开发中怎么选

文本类型
向TEXT类型的字段保存和查询数据时,系统自动按照实际长度存储,不需要预定义长度。
注意:TEXT类型是不能做主键的。


浮点类型
处理小数,整数可以看成是小数的特例,整数可以给浮点类型赋值。
float:单精度浮点数 4字节
double:双精度浮点数 8字节
float和double区别:
float占用字节少,取值范围小,double占用字节数多,取值范围大,精度也更高
为什么浮点数类型的无符号数取值范围,只相当于有符号数取值范围的一半
FLOAT(M,D)或DOUBlE(M,D)
M=整数位+小数位 D<=M<=255 ,M为精度
D=小数位 0<=D<=30 ,D为标度
如定义:FLOAT(5,2),代表整数位3位,小数位2位
范围就是 -999.99~999.99,超过就会报错
FLOAT UNSIGNED(5,2) 0~999.99
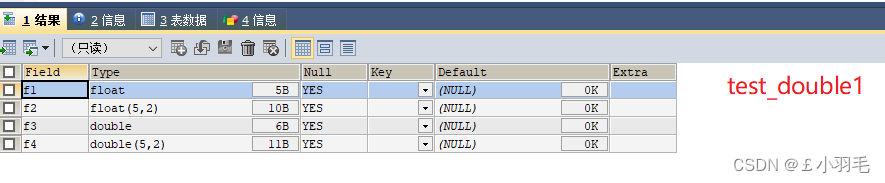
创建表:
CREATE TABLE test_double1(
f1 FLOAT,
f2 FLOAT(5,2),
f3 DOUBLE,
f4 DOUBLE(5,2)
)
测试:插入的数据不超范围
INSERT INTO test_double1(f1,f2)
VALUES (123.45,123.45);
测试:123.456 如果小数位,超出了本身的要求范围,那就4舍5入
INSERT INTO test_double1(f3,f4)
VALUES (123.45,123.456);
测试:1234.456如果整数位,超出了本身的要求范围,那就报错
INSERT INTO test_double1(f3,f4)
VALUES (123.45,1234.456);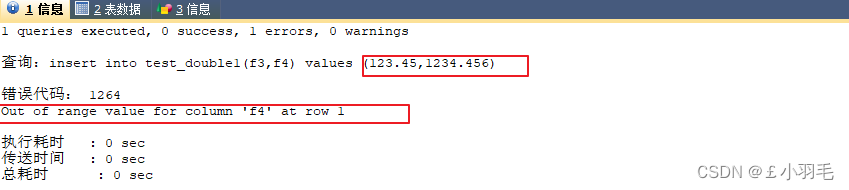
最后临界测试:
INSERT INTO test_double1(f3,f4)
VALUES (123.45,999.995);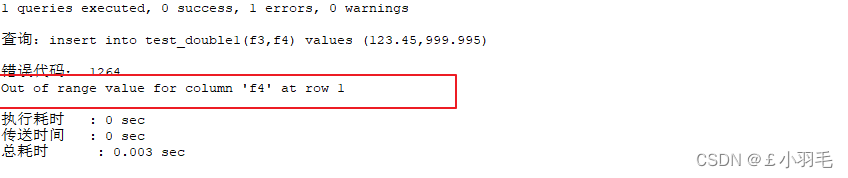
定点类型
DECIMAL(M,D) 字节(M+2)
DECIMAL(5,2)表示的范围-999.99~999.99
为什么精准呢,定点数在mysql中以字符串形式存储当
DECIMAL类型不指定精度和标度时,其默认为DECIMAL(10,0),表示有10个整数位,0个小数位,其范围:-9999999999~9999999999。当数据的精度超出了定点数类型的精度范围时,则MySQL同样会进行四舍五入处理。
CREATE TABLE test_decimal1(
f1 DECIMAL,
f2 DECIMAL(5,2)
);
DESC test_decimal1;日期类型
综述:
表示年月日,可以使用DATE类型,格式为“YYYY-MM-DD”,例如“2022-02-04”
表示时分秒,可以使用TIME类型,格式为“HH:MM:SS”,例如“10:08:08”
如果要表示年月日时分秒的完整日期时间,可以使用DATATIME类型,格式为“YYYY-MM-DD HH:MM:SS”,例如“2022-02-04 10:08:08”
TIMESTAMP类型,格式为“YYYY-MM-DD HH:MM:SS”,例如“2022-02-04 10:08:08”
YEAR类型
CREATE TABLE test_year(
f1 YEAR
);
INSERT INTO test_year VALUES('2021'),(2022);
INSERT INTO test_year(f1) VALUES('2156') 报错,超出范围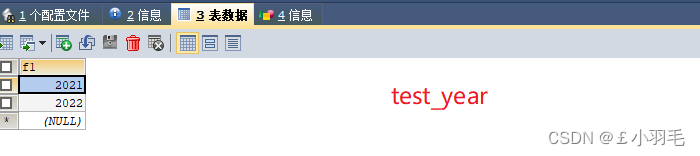
----------------------
DATE类型(3字节),标准格式为“YYYY-MM-DD”,
也可以是“YYYYMMDD”会识别为标准格式。
使用Current_date()或者now()函数,会插入当前系统日期
CREATE TABLE test_date1(
f1 DATE
);
-- 添加指定的年月日
INSERT INTO test_date1 VALUES('2022-06-01'),
('20220601'),(20220601) ;
-- 添加当前的年月日
INSERT INTO test_date1 VALUES(CURRENT_DATE()),(NOW());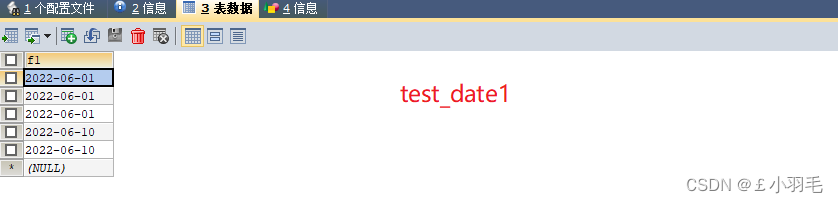
------------------------
TIME (3字节)标准格式为“HH:MM:SS”
'HHMMSS'或HHMMSS
使用Current_TIME()或者now()函数,会插入当前系统时间
CREATE TABLE test_time1(
f1 TIME
);
-- 添加指定的时分秒
INSERT INTO test_time1 VALUES('2 12:35:29'),
('12:35:29'),('120101'),(042122) ;
-- 添加当前的时分秒
INSERT INTO test_time1 VALUES(CURRENT_TIME()),(NOW());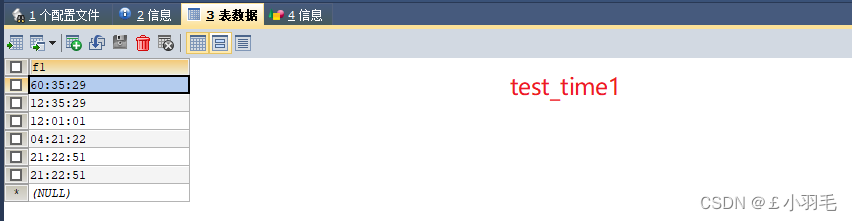
------------------------
DATATIME类型(8字节),标准格式为“YYYY-MM-DD HH:MM:SS”
也可以“YYYYMMDDHHMMSS”会转为标准格式存储
使用Current_TIMESTAMP()或者now()函数,会插入系统的当前日期和时间
CREATE TABLE test_datetime1(
dt DATETIME
);
-- 添加指定的年月日时分秒
INSERT INTO test_datetime1 VALUES('2022-06-06 22:35:29'),('20200101095030');
-- 添加当前的年月日时分秒
INSERT INTO test_datetime1 VALUES(CURRENT_TIMESTAMP()),(NOW());
---------------------------------
TIMESTAMP类型 (4字节)标准格式为“YYYY-MM-DD HH:MM:SS”
UTC 世界标准时间,只能存储1970-2038年
CREATE TABLE test_timestamp1(
ts TIMESTAMP
);
-- 添加指定的年月日时分秒
INSERT INTO test_timestamp1
VALUES('1999-01-01 22:35:29'),('19990101095030');
-- 添加当前的年月日时分秒
INSERT INTO test_timestamp1 VALUES(CURRENT_TIMESTAMP()),(NOW());
SELECT * FROM test_timestamp1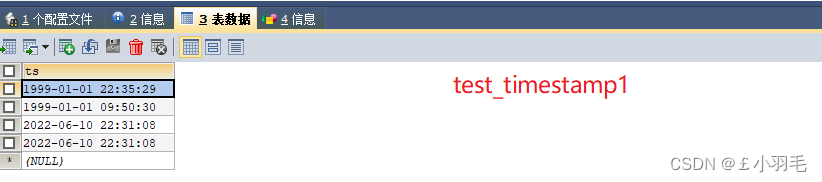
--------------------------------------
比较TIMESTAMP和 DATETIME
存储数据的时候需要对当前时间所在的时区进行转换,查询数据的时候再将时间转换回去当前的时区。因此,使用TIMESTAMP存储的同一个时间值,再不同的时区查询时会显示不同的时间。DATETIME只能反映出插入时当地的时区,其他时区的人查看数据必然会有误差的
区别:
TIMESTAMP底层存储的是毫秒值,距离1970-1-1 0:0:0 0毫秒的毫秒值
俩个日期比较大小和计算,TIMESTAMP会更快一些。
对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,将其又转化为客户端当前时区进行返回。
而对于DATETIME,不做任何改变,基本上是原样输入和输出。
CREATE TABLE temp_time(
d1 DATETIME,
d2 TIMESTAMP
);
INSERT INTO temp_time
VALUES('1999-01-01 22:35:29','1999-01-01 22:35:29');
INSERT INTO temp_time
VALUES(NOW(),NOW());
-- 修改时区
set time_zone='+9:00';
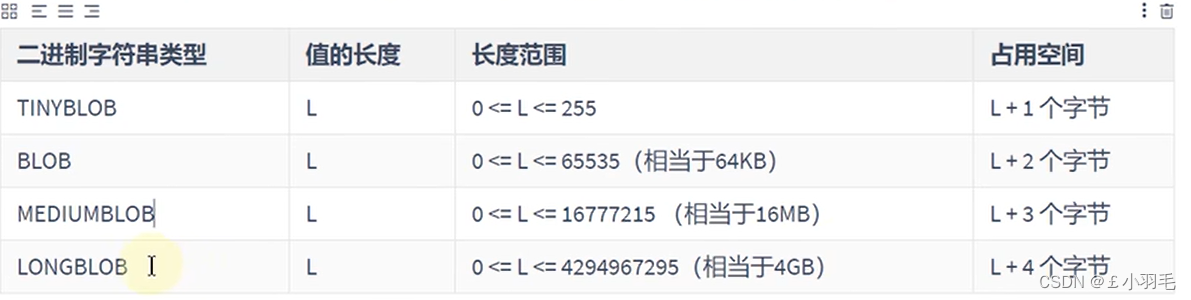
二进制类型
MySQL中的二进制类型主要存储一些二进制数据,如存储图片、音频和视频等二进制数据
支持的二进制类型如下:

BLOB类型

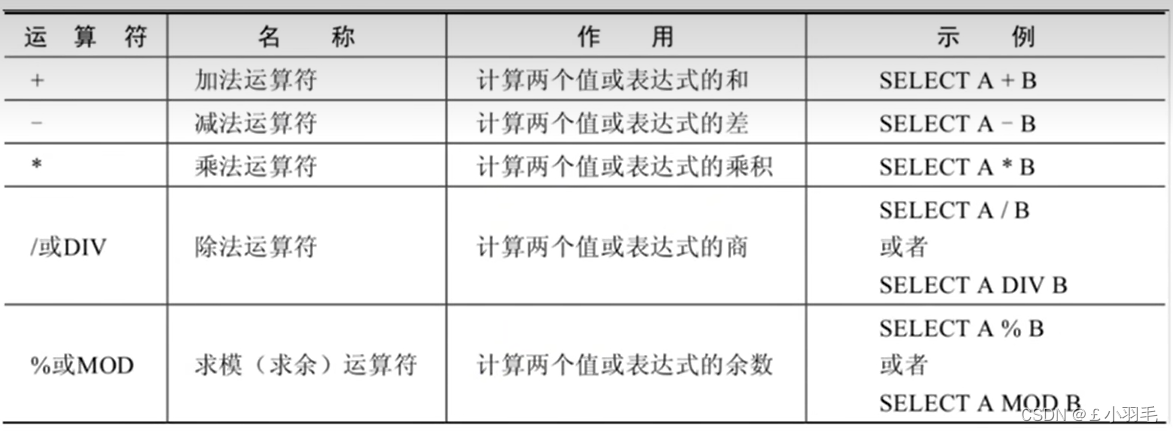
MySQL运算符
算术运算符
在mysql里也存在和oracle里类似的dual虚拟表:官方声明纯粹是为了满足select ... from...这一习惯问题,mysql会忽略对该表的引用。
select 100+1 from dual;
#null值参与运算,结果为null
select 100+null from dual;
#sql中除的结果是小数100.0000
select 100/1 from dual;
#取模结果的正负与被模数相同,下面sql结果是 2 和 0
select 12 % 5,12 % 2;比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,
比较的结果为真则返回1,
比较的结果为假侧则返回O,
其他情况侧返回NULL
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。
1.等号运算符
等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回0。
#结果都为null,只要有null参与判断结果就为null select 1=null,null=null;2.安全等于运算符
安全等于运算符与等于运算符的作用是相以的,唯一的区别是l<=>可以用来对NULL进行判断。在两
个操作家均为NULL时,其返回值为1,而不为NULL:当一个操作数为NULL时,其返回值为O,而不为NULLselect 1<=>null,null<=>null;
3.IS NULL/IS NOT NULL/ISNULL('字段')
ISNULL('字段')是一个函数,和IS NULL是2种写法,作用一样
ifnull(xx,代替值) 当xx是null时,用代替值计算
需求:查询员工的实发工资,实发工资 = 薪资 + 薪资 * 奖金比例
-- 失败,当commission_pct为null,结果都为null SELECT last_name "姓名", salary + salary * commission_pct "实发工资" FROM employees; -- ifnull(xx,代替值) 当xx是null时,用代替值计算 SELECT last_name "姓名", salary + salary *IFNULL(`commission_pct`,0) "实发工资" FROM employees;4.between...and... -- 结果包含俩端边界,范围的查找
not between x and y
5.in (x,x,x) 等于值列表中任意一个,离散值的查找
not in(x,x,x)
#查询籍贯在这几个地方的 select * from employees where native_place in ('北京', '浙江', '江西');6.like 模糊查询
% 表示0个或多个任意字符
_表示一个任意字符
like ‘%e%’ --查询名字包含e的员工信息 -- 查询包含_下划线的名字。用转义字符 like ‘%&_%’ ESCAPE ‘&’ -- 可以声明任意字为转移字符 --查询当前mysql数据库的字符集情况 SHOW VARIABLES LIKE '%character%';7.REGEXP:运算符用来匹配字符串
语法格式为:expr REGEXP 匹配条件。如果expr满足匹配条件,返回1;如果不
满足,则返回)。若expr或匹配条件任意一个为NULL,则结果为NULL。
-- 是否包含gu.gu,这个点可以是任意字符 select 'atguigu' regexp 'gu.gu';



逻辑运算符
在MySQL中,逻辑运算符的返回结果为1、0或者NULL

如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0。
数据库设计规约
1、库名与应用名称尽量一致
2、表名、字段名必须使用小写字母或数字或下划线,禁止出现数字开头,禁止2个下划线之间出现数字
3、表名不使用复数名词
4、表的命名最好是加上“业务名称_表的作用”。如,edu_teacher
5、表必备三字段:id, gmt_create, gmt_modified
说明:
其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。
(如果使用分库分表集群部署,则id类型为verchar,非自增,业务中使用分布式id生成器)
gmt_create, gmt_modified 的类型均为 datetime 类型,前者现在时表示主动创建,后者过去分词表示被 动更新。
6、单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。 说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
7、表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint (1 表示是,0 表示否)。
说明:任何字段如果为非负数,必须是 unsigned。
注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀。数据库表示是与否的值,使用 tinyint 类型,坚持 is_xxx 的 命名方式是为了明确其取值含义与取值范围。
正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。
8、小数类型为 decimal,禁止使用 float 和 double。 说明:float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不 正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。
9、如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
10、varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索 引效率。
11、主键索引 pk_字段名;唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。
说明:pk_ 即primary key; uk_ 即 unique key;idx_ 即 index 的简称
12、不得使用外键与级联,一切外键概念必须在应用层解决。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
各种键
超键:能唯一标识元组的属性集叫做超键。就是包含主键的集合,如 个人编号+姓名
候选键:如果超键不包含多余的属性,那么这个超键就是候选键(如个人编号、身份证号...)
主键:表中任意一个候选键都可以做主键
键可能是由多个属性组成的,针对单个属性,可以用主属性和非主属性区分
主属性:候选键对应的就是主属性
非主属性:与主属性相对
三范式
数据库设计规范化能让我们更好地适应变化,使你能够改变业务规则、需求和数据而不需要重新构造整个系统
第一范式
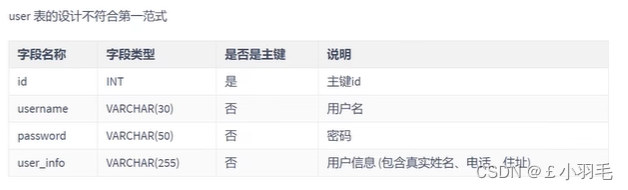
表的列的具有原子性,不可再分解。
- 数据库表每一列都是不可分割的基本数据,同一列中不能有多个值
如下:user_info字段不满足第一范式
-------------------------------------------------------------------------------------------------------------------------------
第二范式
非主键属性均完全依赖于主键
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)
满足第二范式就是说,在表里,只要你告诉我主键的值(或者联合主键的所有值),我就能确定我这个非主键字段自己是什么值。
解决办法:
把不满足第二范式的字段抽出来,单独造表

不满足第二范式,数据冗余会很严重
-------------------------------------------------------------------------------------------------------------------------------
第三范式
- 确保数据表中的每一列数据都和主键直接相关,而不能间接相关
即所有非主属性之间不能有依赖关系,必须相互独立
如员工表里
员工编号 部门编号 部门名称部门名称不满足第三范式
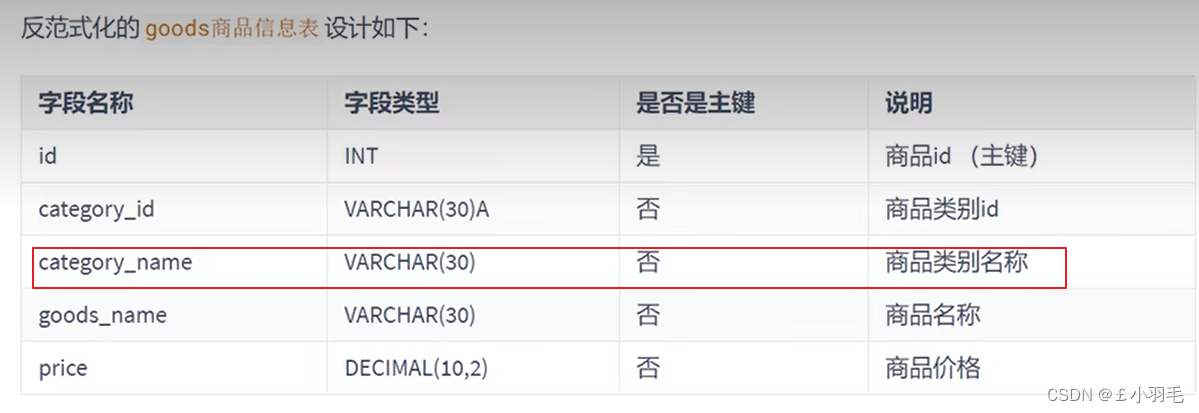
反范式
业务优先:满足业务后,再尽量减少冗余
完全按照三范式设计数据表,读数据会产生大量的关联查询,在一定程度上会影响数据库的读性能。
通过再给定的表中添加额外的字段,以大量减少需要从冲搜索信息所需的时间
ER模型
ER模型3要素
ER模型3要素:实体、属性、关系

可以独立存在的是实体,不可再分的是属性
-------------------------------------------------------------------------------------------------------------------------------
关系的类型
















 7581
7581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









