






Pytorch深度学习实践
Pytorch版本——1.10.0。
需要线性代数和概率论 + Python
深度学习实现步骤
- 准备数据集(Dataset & DataLoader)
- 自定义模型
- 选择Loss与优化器
- Training Cycle
- Test
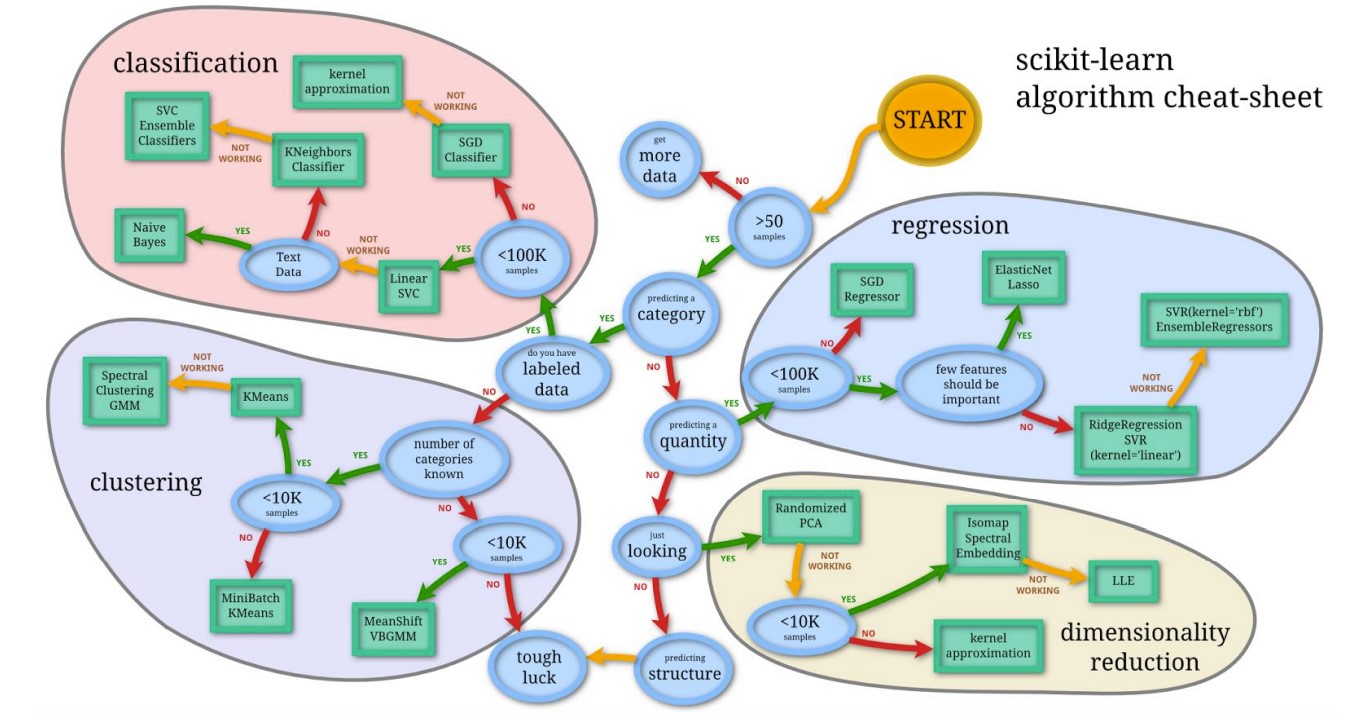
1. Overview
1.1 传统机器学习
输入 -> 手动提取特征 -> 根据特征找到X到Y的映射(Mapping features) -> 输出
1.1.1 表示学习
希望特征提取这个步骤也能通过学习得到。再将提取后的特征向量放入Mapping features中。
1.1.2 维度的诅咒
如果输入每一个数据样本的feature越多,那么学习过程对于样本的需求也越多。
| 采样样本个数 | feature特征(维度) | 所需样本 |
|---|---|---|
| 10 | 1 | 10 |
| 10 | 2 | 100 |
| 10 | 3 | 1000 |
| 10 | n | 10^n |
即需要采样10^n个数据才能认为满足大数定律。
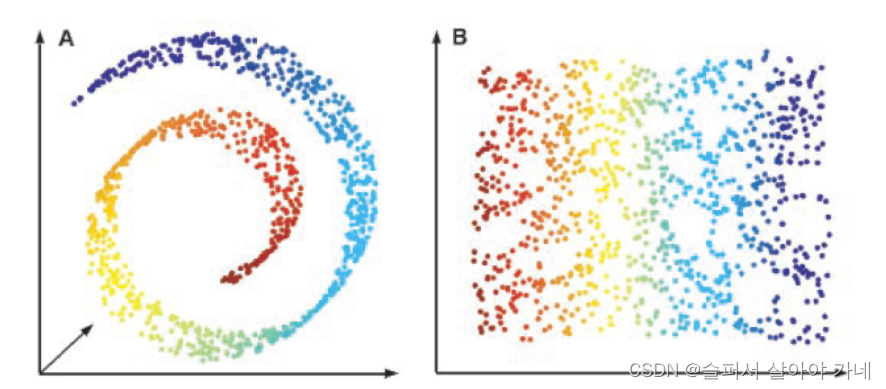
1.1.3 降维
将N维数据映射到M维(N >> M),例如使用线性映射。将N * 1的矩阵映射到M * 1的矩阵只需找到一个合适的M * N矩阵做矩阵乘法,即可得到M*1 = (M*N) * (N*1)。但在向下降维时,我们仍想保留一些高维数据的特征,不能一味的线性降维。极端地,将N维降到1维,数据便丧失了其极大一部分信息。
- 表示学习:找到合适的、从高维降到低维的方法
Manifold(流形):[x, y, z] -> [u, v]。
1.1.4 受到的挑战
- 手动提取特征的限制
- 处理庞大数据比较吃力
- 无结构数据,如图像,文本等需要现做复杂的特征提取器
1.2 深度学习
输入 -> 简单特征(Simple features) -> 深层的特征 -> 特征映射(学习器) -> 输出
1.2.1 深度学习特点
- 传统表示学习:特征提取和特征映射是分开训练的
- 深度学习:合并了特征提取和特征映射学习过程,因此也被称作End2End端对端学习。特征映射学习器一般是神经网络。
1.2.2 深度学习发展介绍
灵感来源于生物神经元(猫的视觉实验)。2012年AlexNet提出,深度学习开始绽放异彩。待到ResNet提出时,深度学习准确率已超过人类。深度学习发展十分迅速,学习深度学习,重点不在于学习各种模型,而是学会如何构建模型,将各基本结构组装起来
1.3 深度学习框架
使用框架的好处
- 不需要从无到有的实现算法
- 可以充分调用GPU的算力,不用直接跟Cuda打交道
- 框架含有神经网络的基本组件
现今Pytorch广泛用于学术界,主打动态图,包含Caffe;TensorFlow广泛用于工业界,包含Keras。
2. 线性模型
获取数据集 -> 模型 -> 训练 -> 新数据推理
2.1 一个简单的例子
已知三个样本,训练出模型后,推理新数据x预测结果
| input | label |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | ? |
上述对于每个输入都有一个输出值的,称作监督学习。注意在学习过程中,测试集是不能动的。
2.2 一般步骤
模型训练时一般先用线性模型y = w * x去拟合。参数w先随机取一个值,评估拟合效果(观察偏移程度)
- 定义一个损失函数: L O S S = 1 N ∑ ( x ∗ w − y ) 2 LOSS = \frac{1}{N} ∑(x * w - y)^{2} LOSS=N1∑(x∗w−y)2 (Mean Square Error, MSE)。通常情况下,LOSS是取不到零的,所以模型训练追求的就是LOSS最小。
2.2.1 二维图像
给定x_data, y_data两个数据集,使用y = w * x拟合并进行可视化
2.2.1.1例子2.1的实现
import numpy as np
import matplotlib.pyplot as plt
# 存储数据集, 相同索引代表同一个样本
x_data = [1.0, 2.1, 2.9]
y_data = [2.0, 4.1, 6.0] # label
# 定义模型,称为前馈 forward
def forward(x):
return x * w
# 定义损失函数
def LOSS(x, y):# MSE
y_pred = forward(x) # 预测值
return (y_pred - y)**2
# 因为训练过程中会得到多个w权重值,所以使用列表保存权重及其MSE值
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.5):
'''
np.arange(start, end, step)
从start开始,以step为步长,逐个生成直到end
[0.0, 0.1, 0.2, ..., 3.9, 4.0]
'''
print("w--", w, end = " ")
LOSS_SUM = 0 # 求MSE用
for x_val, y_val in zip(x_data, y_data):
'''
zip()函数用于可迭代的对象,将对象中的元素打包成一个个元组
然后返回由这些元组构成的列表
Notice:Python3中,返回的是一个对象,得到列表需要进行list解压
'''
y_pred_val = forward(x_val)
loss_val = LOSS(x_val, y_val)
LOSS_SUM += loss_val
print('MSE--', LOSS_SUM / 3)
w_list.append(w)
mse_list.append(LOSS_SUM / 3)
2.2.1.2 模型可视化
- 画图
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
最终得到的图像结果是

在做深度学习时,也要画类似的plt图,但是横坐标不再取LOSS而是轮数。人工观察模型何时收敛可能更加直观。深度学习过程中存盘十分重要,原因是深度学习跑一次模型耗费的资源巨大,如果中途失败而没保存,那么断点以前的劳动都算是白费了。
- 函数
np.meshgrid()是画3D图形的有效工具。
2.2.2 三维图像
画出三维的函数图像,就需要两个参数加一个评价函数。
先给出两个数据集, x_data和y_data,要求使用 y = w * x + b拟合,并可视化
2.2.2.1 例子2.2实现
import numpy as np
# 定义数据集
x_data = [1.0, 3.0,4.5,6.3,9.7]
y_data = [1.1, 5.1, 8.0, 11.6, 18.4]
# 定义参数集
w_list = []
b_list = []
mse_list = []
def forward(x):
return x * w + b
def LOSS(x, y):
return (forward(x) - y)**2
for w in np.arange(0.0, 3.1, 0.1):
for b in np.arange(-2.0, 2.1, 0.1):
w_list.append(w)
b_list.append(b)
LOSS_SUM = 0
# print("w:", w," b:", b, end = " ")
for x_val, y_val in zip(x_data, y_data):
loss_val = LOSS(x_val, y_val)
LOSS_SUM += loss_val
MSE = LOSS_SUM / len(x_data)
# print("MSE: ", MSE)
mse_list.append(MSE)
2.2.2.2 可视化
对于3d图像的生成,使用np.meshgrid()生成坐标矩阵,使用matplotlib绘制
- 生成坐标矩阵
ww, bb = np.meshgrid(w_list, b_list)
mm = np.meshgrid(mse_list)
mm = np.array(mm) # 要生成array类型,否则list报错
- 可视化
# 可视化
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
plt.figure(1, figsize = (20,15))
ax = plt.subplot(1,1,1,projection = "3d")
ax.plot_surface(ww, bb, mm, rstride = 1, cstride = 1, cmap = "rainbow")
plt.show()

3. 梯度下降算法
3.1 为什么要用梯度下降
上一部分线性模型作图时,最开始先随机猜测一个w和b,再使用穷举法绘图,根据目标函数选择最好权重。
假设参数有10个,每个穷举100个数值,那么将取100^10种组合,挨个穷举观察是不可能的,因此代替穷举,对参数要进行搜索。
从“等”到“找”
3.1.1 搜索方法——分治
对于原始数据先进性稀疏的搜索,找到最小值后,再在最小值的附近进行新的一轮稀疏搜索。比如先将原始数据分成四块,然后在最小值附近再
分成四块……如此下来,就能将原始数据划分成很小份,减少了搜索次数。
但是。对于非凸函数,分治法十分容易错过全局最优;且当数据量特别大时,划分空间搜索也是不现实的。
3.2 梯度下降
已知函数在导数的反向下降最快(用微分,化曲为直地理解公式)。沿着目标函数下降最快的方向更新参数,可以迅速找到最优参数。
- 参数更新公式: ω = ω − α ∂ c o s t ∂ ω \omega =\omega -\alpha \frac{\partial cost}{\partial \omega} ω=ω−α∂ω∂cost,其中 α \alpha α为学习率。
梯度下降算法是贪心策略,原则上只能找到局部最优解。但梯度下降算法可用的原因是,神经网络的目标函数中,很少存在局部最优解。但是神经网络存在鞍点,即在一定邻域内梯度恒为零的点。因此,深度学习最主要的难题是鞍点问题
3.3 梯度下降实现
注意梯度下降函数是对参数求导
import numpy as np
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = 1.0 # 初始权重
def forward(x):
return w * x
def cost(xs, ys):
'''
xs, ys是原始数据x_data, y_data
'''
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y-y_pred)**2
return cost / len(xs)
# 求梯度
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2* x * (x*w - y) # cost对w求导
return grad / len(xs)
cost_list = []
ite_list = []
# 训练前预测x=4
print("predict before training: f(4) = ", forward(4))
for ite in range(1000):# 迭代
ite_list.append(ite)
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w = w - 0.01 * grad_val
cost_list.append(cost_val)
# 训练后预测x=4
print("predict after training: f(4) = ", forward(4))
predict before training: f(4) = 4.0
predict after training: f(4) = 7.999999999999996
import matplotlib.pyplot as plt
plt.plot(ite_list, cost_list)
plt.xlabel("iterative")
plt.ylabel("cost")
plt.show()

深度学习的cost函数值可能即使趋于收敛但波动较大,可采用指数加权均值,将cost函数变为更加平滑的曲线。
假设原损失函数值为cost_{0}, cost_{1}, cost_{2}, …
平滑后c o s t 0 ′ = c o s t 0 cost_{0}' = cost_{0} cost0′=cost0
c o s t i ′ = β ∗ c o s t i + ( 1 − β ) ∗ c o s t i − 1 ′ cost_{i}' = \beta * cost_{i} + (1-\beta) * cost_{i-1}' costi′=β∗costi+(1−β)∗costi−1′,其中 β \beta β是权重。
3.3.1 随机梯度下降(SGD)
是一种梯度下降算法的改进版本。不同于原版梯度下降,求梯度时随机梯度不在使用全体样本的损失函数值对参数求导,而是改用从N个样本中随机选取一个,以它的Predicted值LOSS作为参数更新函数。即
- 原始梯度下降更新: ω = ω − α ∂ c o s t ∂ ω \omega = \omega - \alpha \frac{\partial cost}{\partial \omega} ω=ω−α∂ω∂cost; ∂ c o s t ∂ ω = 1 N ∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) \frac{\partial cost}{\partial \omega} = \frac{1}{N} \sum_{n=1}^{N}{2·x_{n}·(x_{n}·\omega-y_{n})} ∂ω∂cost=N1∑n=1N2⋅xn⋅(xn⋅ω−yn)
- 随机梯度下降更新: ω = ω − α ∂ l o s s ∂ ω \omega = \omega - \alpha \frac{\partial loss}{\partial \omega} ω=ω−α∂ω∂loss; ∂ l o s s n ∂ ω = 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) \frac{\partial loss_{n}}{\partial \omega} = 2·x_{n}·(x_{n}·\omega - y_{n}) ∂ω∂lossn=2⋅xn⋅(xn⋅ω−yn)
# 从代码的角度看,gradient( )和迭代过程是不一样的
def gradient(x, y):
return 2*x*(w*x-y)
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y) # 对每一个样本进行更新
w = w - 0.01 * grad
LOSS = Loss(x, y)
假如一共有五组样本迭代10次,梯度下降参数更新次数为10次,随机梯度下降更新次数为50次。
使用随机梯度下降使得存在鞍点的深度学习损失函数有跳出鞍点的可能。
3.3.2 随机梯度下降和原版梯度下降
- 在随机梯度下降过程中,一次迭代内,当前一组样本的参数是经过上一组样本学习优化后的(第i代,每组样本w不同)。
- 但原始梯度下降算法中,一次迭代内,是以上一代参数w计算出每个参数的损失求和(第i代,每组样本w相同)。
因此,样本之间相互不存在依赖的原始梯度下降算法是可以**
并行计算的,时间复杂度要比随机梯度下降算法低;
相反,随机梯度下降可以得到的最终结果普遍要优于原版梯度下降,即性能比原版梯度下降好**
3.3.3 Batch
因为拿所有样本计算梯度下降速度要快(GD),而用单个样本计算效果更好(SGD),所以去一种折中的办法来进行梯度下降,取名为Batch,直观的理解为批量的随机梯度下降。
实际上Batch名为Mini-Batch.
Batch大小是一个超参数,用于定义更新内部模型参数之前要处理的样本数(总结的很到位嗷)。
将批处理视为循环迭代一个或多个样本并进行预测,批处理结束后将预测与预期输出变量比较、计算误差,并改进模型
学习迭代次数:{
一次学习批次数:{
计算该批次的COST
根据得到的COST更新参数w
}
}
一个Batch内部是可以进行并行计算的,但Batch之间不可以
- 当Batch = 1时,为梯度下降
- 当Batch = 样本个数时,为随机梯度下降
- Batch位于两者之间,为小批量梯度下降
4. 反向传播
对于复杂的模型(神经网络), ∂ L O S S ∂ ω \frac{\partial LOSS}{\partial \omega} ∂ω∂LOSS梯度无法直接使用解析式计算,因为参数量太大。所以引入一种方法,将梯度计算的过程变为图的模式,使梯度从输出到输入反向传播,即反向传播算法。
4.1 激活函数!
先假设一个两层的神经网络,假设它不存在激活函数,那么第一层的隐藏状态为
h
1
=
W
1
⋅
X
+
b
1
h_{1} = W_{1} · X + b_{1}
h1=W1⋅X+b1,
h
1
h_{1}
h1作为输出层的输入,在输出层进行第二次运算,即
y
p
r
e
d
i
c
t
=
W
2
(
W
1
⋅
X
+
b
1
)
+
b
2
y_{predict} = W_{2}(W_{1} · X + b_{1}) + b_{2}
ypredict=W2(W1⋅X+b1)+b2。
问题在于,上式经过化简
y
p
r
e
d
i
c
t
=
W
2
(
W
1
⋅
X
+
b
1
)
+
b
2
y_{predict} = W_{2}(W_{1} · X + b_{1}) + b_{2}
ypredict=W2(W1⋅X+b1)+b2
.
.
.
.
.
.
.
.
.
.
=
W
2
⋅
W
1
⋅
X
+
W
2
⋅
b
1
+
b
2
..........= W_{2}·W_{1} · X +W_{2}· b_{1} + b_{2}
..........=W2⋅W1⋅X+W2⋅b1+b2
.
.
.
.
.
.
.
.
.
.
=
W
⋅
X
+
b
..........= W · X + b
..........=W⋅X+b
可以发现,W1,W2可以用一个W代替,b1,b2可以用一个b代替,也就是说,不管进行了多少层运算,多层线性函数的嵌套本质上只有W和b两个矩阵内的参数是有效的,这显然是不可以的。因此,在每个隐藏层后面都需要加入一个非线性的函数,使得每个隐藏层之间非线性连接,这个非线性函数便叫作激活函数
4.2 传播
计算反向传播时,首先画出计算图。第一步进行前馈的计算,第二进行梯度的方向传播。每个结点的梯度等于局部梯度 * 流入梯度
4.3 PyTorch里如何实现
Pytorch里一个基本的数据类型名为Tensor,是用来存数据的。如反向传播时各节点的前馈值和传播值都要存在Tensor中。Tensor支持标量,向量,矩阵和高阶张量。
Tensor是一个类,其重要的两个成员是data和grad,分别保存权重本身和损失函数对权重的导数。
4.3.1 Pytorch实现例2.1
先给出两个数据集, x_data和y_data,要求使用 y = w * x 拟合,并可视化
4.3.2 代码部分
代码下方为注释的总结
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 使用模型为 y = w * x
w = torch.Tensor([1.0]) # 创建参数,w为一阶张量
w.requires_grad = True # 需要计算梯度,默认不需要
torch.Tensor()创建一个Tensor变量,即张量,并将其手动设置为需要计算梯度。否则每次进行一遍反向传播后,它的梯度值亦会被释放
def forward(x):
'''
:return: 因为w是一阶张量,所以返回值也是张量
'''
return x * w
def loss(x, y): # 构建计算图
'''
因为forward()返回值是一个张量,所以loss返回值也是一个张量
:return:
'''
return (forward(x) - y) ** 2
- Pytorch中,Tensor变量拥有极强的感染力,凡经过Tensor变量操作的返回值都是一个Tensor。
mse_list= []
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # 前馈计算,得出计算图
# print(type(l.item()))
# print(type(l.data.item()))
MSE = l.data.item()
# Tensor变量直接调用其库函数backward()反向传播
l.backward() # 传播后释放 —— 动态图
'''
backward函数执行后,计算各点的梯度值,并为 需要保存梯度的变量(line 7) 保存梯度
一旦执行完毕,计算图l(line 24)被释放
'''
# print('grad: ', x, y, w.grad.item())
'''
参数w是一个Tensor变量,包含data和grad两个成员。
注意:Tensor.data和Tensor.grad也是张量,即 Tensor(w) = [Tensor(data), Tensor(grad)]
'''
# 更新权重参数的值
w.data = w.data - 0.01 * w.grad.data # 注意减去的是grad.data而不是grad;因为此处只是进行单纯的数值变换。
# 如果操作对象是grad那么会创建一个新的计算图
'''
Pytorch中,只要使用张量,就计算意味着构建计算图
因此更新权值一定要有.data
'''
w.grad.data.zero_() # 对参数的导数进行清零。如果不清零会导致下一代计算图计算导数时,加上上一次的未清零导数
# mse_list.append(l.data.item())
mse_list.append(MSE)
# print('progress: ', epoch, l.item())
- 经过loss返回的值,直观的理解为计算图。使用
loss.backward( )进行反向传播。 - 反向传播结束后自动释放计算图。此时w声明时的
w.requires_grad = True的作用就体现出来了。其他没有进行保留梯度声明的x, y,loss等梯度都被释放,只有w的梯度被保留下来,用于下一次更新 Tensor.item()用于返回张量中的值,仅限Tensor中只有一个元素时使用。- Tensor是一个类,它的两个主要成员是data 和 grad,它俩也是张量。
- Pytorch只要操作Tensor,就意味着创建计算图。这对于一些只进行数值更改的操作是十分不利的。因此更新权重w时,应当使用
w.data = w.data - 0.01 * w.grad.data而不是w.data = w.data - 0.01 * w.grad。 - 同理,在给
mse_list添加值时,需要append的是loss.data或loss.data.item,而不是mse_list.append(loss) - 此题的参数训练时,我们不希望 上一代的梯度和这一代的梯度有关,因此需要手动对grad清零:
w.grad.data.zero_()
4.3.3 可视化
- 在使用jupyter notebook调用matplotlib时可能会出现内核不断崩溃的情况,此时有两种解决办法
- 在notebook里调用代码
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
可能是直接用代码添加环境变量的意思?不大懂,反正好使。
- 手动添加环境变量
计算机 -> … -> 环境变量 -> 新建 -> 键:“KMP_DUPLICATE_LIB_OK”, 值:“TRUE”
- 可视化代码
import matplotlib.pyplot as plt
import numpy as np
x = np.array(range(100))
# print(mse_list)
plt.plot(x, mse_list)
plt.xlabel("iter")
plt.ylabel("loss")
plt.show()
结果为

4.4 多个变量的反向传播
- 模型选择为: y = w_{1}·X^{2} + w_{2}·X + b;损失函数仍采用MSE
4.4.1 模型训练
import torch
import matplotlib.pyplot as plt
x_data = [1.7,2.4,3.3,4.6,5.6,6.9,7.2,8.2,9.1]
y_data = [4.4,5.3,8.4,10.5,10.7,8.6,6.1,4.1,2.6]
w1 = torch.Tensor([1.0])
w1.requires_grad = True
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
- 声明三个张量,并标记为要保留梯度
def forward(x):
return w1*x*x + w2*x + b
def loss(x, y):
return (forward(x) - y) ** 2
mse_list = []
for epoch in range(10000):
for x, y in zip(x_data, y_data):
# print(x)
l = loss(x, y)
MSE = l.data.item()
# print(MSE)
l.backward()
# print(l)
w1.data = w1.data - 0.00000001 * w1.grad.data
w2.data = w2.data - 0.00000001 * w2.grad.data
b.data = b.data - 0.00000001 * b.grad.data
- 注意更新参数时,学习率的选择要合适,否则会出现梯度爆炸出现inf,nan的情况。原因是过程中出现了计算 l o g ( 0 ) 或 N 0 log(0)或\frac{N}{0} log(0)或0N的式子。
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
mse_list.append(MSE)
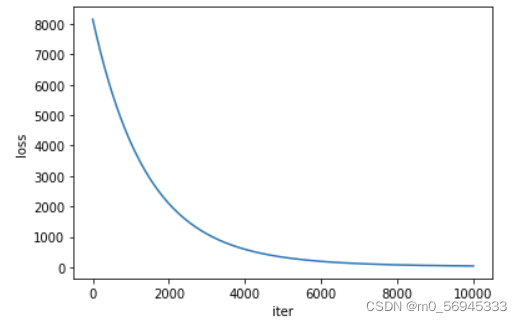
- 最终训练得到的结果为
w1 -- 0.0018304826226085424
w2 -- 0.879086434841156
b -- 0.9854724407196045
4.4.2 可视化
调用matplotlib的环境变量上次已经新建,这次就不需要再重新调用了。
import matplotlib.pyplot as plt
import numpy as np
xl = np.array(range(10000))
yl = np.array(mse_list)
plt.plot(xl, yl)
plt.xlabel("iter")
plt.ylabel("loss")
plt.show()
5. Pytorch线性回归
Linear Regression with PyTorch,用PyTorch接口实现线性回归
- 需要准备的工作
- 构建数据集
- 设计模型
- 构造损失函数和优化器。(使用PyTorch API)
- 确定训练周期(前馈,反馈,更新)
5.1 准备数据集
在之前的例子中,x_data和y_data是两个一维数组;但是在本章将使用mini-batch的方式(一次性将数据都求出来),所以X和Y都要声明成Tensor形式。
[ y p r e d ( 1 ) y p r e d ( 2 ) y p r e d ( 3 ) ] \left[ \begin{matrix} y_{pred}^{(1)} \\ y_{pred}^{(2)} \\ y_{pred}^{(3)} \end{matrix} \right] ⎣⎢⎡ypred(1)ypred(2)ypred(3)⎦⎥⎤ = ω ⋅ [ x ( 1 ) x ( 2 ) x ( 3 ) ] + b \omega·\left[ \begin{matrix} x^{(1)} \\ x^{(2)} \\ x^{(3)} \end{matrix} \right] + b ω⋅⎣⎡x(1)x(2)x(3)⎦⎤+b
- 上式的实现得益于numpy的广播特性:即 ω \omega ω在计算时被numpy自动扩充为 [ ω ω ω ] \left[ \begin{matrix} \omega \\ \omega \\ \omega \end{matrix} \right] ⎣⎡ωωω⎦⎤,b同理
import torch
# 使用mini-batch构建数据
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
5.3.1 数据归一化
在开始进行模型训练之前首先要进行数据预处理,而预处理中比较重要的一环叫做数据归一化。为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理,使得不同指标之间具有可比性。通过梯度下降算法求解的模型都需要进行数据归一化,比如神经网络。
5.3.2 线性函数归一化
经过线性的变换,将数据映射到[0, 1]区间。公式为
X
n
o
r
m
=
X
−
X
m
i
n
X
m
a
x
−
X
m
i
n
X_{norm} = \frac{X - X_{min}}{X_{max} - X_{min}}
Xnorm=Xmax−XminX−Xmin。但是异常值会对数据造成较大的影响。
5.3.3 零均值归一化
首先求出一组变量的均值
μ
=
1
N
∑
i
=
1
N
X
i
\mu = \frac{1}{N}\sum_{i=1}^{N}{X_{i}}
μ=N1∑i=1NXi,在求出标准差
σ
=
1
N
∑
i
=
1
N
(
X
i
−
μ
)
2
\sigma = \sqrt{\frac{1}{N}\sum_{i=1}^{N}{(X_{i}-\mu)^{2}}}
σ=N1∑i=1N(Xi−μ)2。
最后得出
X
n
o
r
m
=
X
−
μ
σ
X_{norm} = \frac{X - \mu}{\sigma}
Xnorm=σX−μ
5.2 设计模型
使用Pytorch进行线性回归时,工作的重心从计算梯度转移到了构造计算图上。Linear_Regression中,称一个仿射模型y = w * x + b为一个线性单元(UNIT)
- 输入x样本(张量
- 线性单元y = w * x + b计算。这个过程需要确定参数W和b的维度。如果 y p r e d y_{pred} ypred是 3x1,样本x是4x1的话,w就要求是3x4的矩阵,b是3x1的矩阵。
- 构造损失函数。这个步骤要求得到的损失函数值一定是个标量值,否则用不了反向传播。
5.3 使用PyTorch构造模板
一个良好的习惯,把要使用的模型声明为一个类,而不是直接使用库。需要掌握此构造模型方式
class LinearModel(torch.nn.Module): # 继承
def __init__(self):
super(LinearModel, self).__init__() # # 调用父类的构造函数
self.linear = torch.nn.Linear(1, 1) # 构造一个Linear对象
def forward(self, x): # 必须起这个名字——Overwrite过程
y_pred = self.linear(x) # 线性模型计算
return y_pred
#实例化
model = LinearModel()
model(X) # _callable !!不是 model.forward(x)
5.3.1 继承自torch.nn.Module
自己编写的LinearModel类是继承在nn.Module下的
Model是为了解决当前问题设计的模型
Module是可以import的模块,即库
5.3.2 构造函数
super(LinearModel, self).__init__()语句是调用父类的构造函数,千万不能忘
self.linear是一个对象, 由torch.nn.Linear这个类实例化。
根据文档,torch.nn.Linear的定义是
class torch.nn.Linear(in_features, out_features, bias = True)
- in_features:输入样本的维度。
维度指特征的个数,题目中为1
- out_features:输出样本的维度
- bias:是否进行偏置,默认为真。
in和out两个参数共同决定了线性回归所需要的两个权重矩阵(W 和 b)的维度。
5.3.3 forward函数
重写forward函数!
nn.Linear类中实现了魔术方法(magic method) __call__(),使得可以像调用函数那样调用类。
在torch.nn.Module这个基类中就定义了这样一个__call__()可调用函数。因此如果我们定义一个线性模型,他就要求我们实现forward()的执行。``这实际上是一个覆盖的过程
看了一下源码,Module里应该是这样定义的:
def __init__(self):
... # 略了
def forward(self, *input): # *input就是*args, 保存未命名的所有输入
# 专门为了报错写的函数
raise NotIMplementedError
def __call__(self, *input, **kwargs):
'''
经过一系列复杂操作最后
:return: self.forward(*input, **kwargs) # 直接调用forward()
'''
...
观察源码发现,基类中的__call__()方法使得用户在实例化对象时便自动执行forward()函数。
但是 它在基类内定义forward()时就指出,如果直接调用它给的forward()函数是会报错的。经过它的这么一番操作,用户就不得不在自定义类时,用新的forward()函数去覆盖那个基类里只用来报错的forward(),以上就是用户为什么必须定义forward()的原因
- 注意:
- 这个包含
forward()的__call__()是定义在nn.Module下的。 - 因为
nn.Linear()也是构造于nn.Module()下的,所以也是可调用的。 - 使用模型时
model(input)体现了LinearModel的可调用,求y_pred时self.linear(x)反映了nn.Linear可调用。
- 这个包含
这也从另一方面反映了使用Pytorch框架时为什么要使用自定义的模型类。
*args:指所有传入的、未被使用的且没有命名的参数,存储形式为n元组
*kwargs:所有传入的、未被使用的且已经命名的参数,存储形式为字典
不需要定义backward()是因为在父类nn.Module中已经实现了。
5.4 构造损失函数
使用MSE计算。
[
L
o
s
s
1
L
o
s
s
2
L
o
s
s
3
]
\left[ \begin{matrix} Loss_{1}\\Loss_{2}\\Loss_{3}\\ \end{matrix} \right]
⎣⎡Loss1Loss2Loss3⎦⎤ =
(
[
y
p
r
e
d
1
y
p
r
e
d
2
y
p
r
e
d
3
]
−
[
y
1
y
2
y
3
]
)
2
(\left[ \begin{matrix} y_{pred}^{1}\\y_{pred}^{2}\\y_{pred}^{3}\\ \end{matrix} \right] - \left[ \begin{matrix} y^{1}\\y^{2}\\y^{3}\\ \end{matrix} \right])^{2}
(⎣⎡ypred1ypred2ypred3⎦⎤−⎣⎡y1y2y3⎦⎤)2
首先会得到一个Loss组成的向量(三个样本各自的Loss),需要处理向量转化为标量。
常用的方法有
L
O
S
S
=
1
N
∑
i
=
1
N
L
o
s
s
i
LOSS = \frac{1}{N} \sum_{i=1}^{N}{Loss_{i}}
LOSS=N1∑i=1NLossi
这个过程是对Tensor进行操作,因此涉及到构建计算图。记住:只要涉及到计算图,就应该继承自Module。
Pytorch自带的MESLoss
PyTorch将MSE计算过程封装成了torch.nn.MSELoss,它也继承自nn.Module。它的定义为
class torch.nn.MSELoss(size_average = True, reduce = True)
- size_average: 是否对 ∑ l o s s i \sum{loss_{i}} ∑lossi求均值,默认为True
- reduce:是否降维至标量,默认为True
调用
criterion = torch.nn.MSELoss(size_average = False),对象criterion在使用时需要的参数为
y
和
y
p
r
e
d
y和y_{pred}
y和ypred
5.5 优化器
- 回顾:使用Pytorch之前的优化器是
def grad(x):
优化器不是继承自nn.Module,不会生成计算图;而是继承自torch.optim,pytorch下的优化器。
- 调用
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
SGD类的定义为
class torch.optim.SGD(params, lr = <object object>, momentum = 0, dampening = 0, weight_decay = 0, newterov = False)
- params:要训练训练权重。赋值时赋了
model.parameters(),其作用是,主动网罗model下所有成员的可训练权重。 - lr:learning rate,学习率。往后可以支持对不同的部分使用不同的学习率。
所以调用后得到的优化器optimizer就知道要训练的所有参数对象和学习率了。
5.6 训练过程 Training Cycle
5.6.1 基本流程
- 先在使用model前馈计算 y p r e d y_{pred} ypred
- criterion求损失,传入原始标签和预测值
- 打印过程中loss并不是一个标量,而是一个对象而是在print时自动调用了
__str__()魔术方法。 - 归零所有权重的梯度。否则权重的梯度会累积
- 根据loss进行反向传播
- 最后使用优化器optimizer进行更新
5.6.2 训练过程代码
前馈 – 反馈 – 更新
mse_list = [ ]
iter_list = [ ]
for epoch in range(100):
y_pred = model(x_data) #Forward
loss = criterion(y_pred, y_data)
print(epoch, loss)
mse_list.append(loss.item())
iter_list.append(epoch)
optimizer.zero_grad()
loss.backward()
optimizer.step() # Update
5.6.3 输出结果
- 输出权重和偏置
# 打印 model下linear模型的权重值
print(‘W= ', model.linear.weight.item()) # weight是一个矩阵[ [ ] ],所以需要取item()
# 同理
print(‘b= ', model.linear.bias.item())
#测试
x_test = torch.Tensor([[4.0]]) # 1*1矩阵
y_test = model(x_test) # 1*1矩阵
print('y_pred = ', y_test.data)
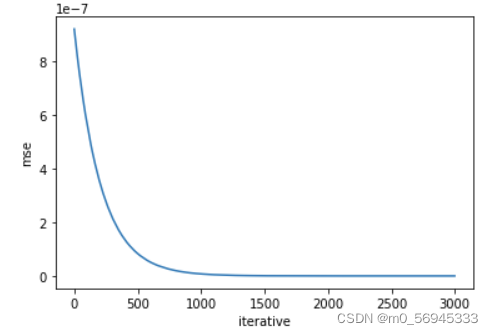
5.6.4 可视化
import matplotlib.pyplot as plt
plt.plot(iter_list, mse_list)
plt.xlabel("iter")
plt.ylabel("mse")
plt.show()
- 运行结果
6. 逻辑回归(Logistic Regression)
名字叫回归但是是分类。
- 分类的一种思路:
一种思路是根据评价函数计算,得出一个分类的值。但是这不是一个很好的办法。比如手写体识别0-9十个数字,得出分类8的评价值和分类0的评价值相差很大,相反7和8的评价值相差很小,因为二者是挨着的(数值大小特征和形状特征)。但是实际上,0和8的相似度要高于7和8的相似度,故根据评价函数设计分类显然是不合理的。
分类问题的解决办法是,模型输出的不是分类,而是属于某一分类的概率,这就涉及到了 分布
一个库——torchvision
安装pytorch时自带的一个库,其中包含一些自带的经典数据集
import torchvision
train_set = torchvision.datasets.MNIST( root = ' ./dataset/MNIST', train = True, download= True)
test_set = torchvision.datasets.MNIST( root = ' ./dataset/MNIST', train = False, download= True)
将MNIST数据集下载到当前目录下的dataset/MNIST文件夹中。另外还有CIFAR-10图片分类的数据集。torchvision.datasets.CIFAR10
6.1 回归与分类
例2.1中,是根据输入x取回归预测分数。逻辑回归分类中,是根据x分类是否通过考试0/1。计算属于0的概率
P
(
y
p
r
e
d
=
0
)
P(y_{pred} = 0)
P(ypred=0)和属于1的概率。
为了将x从实数域映射到[0, 1],采取sigmoid函数
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x) = \frac{1}{1+e^{-x}}
σ(x)=1+e−x1。sigmoid函数两侧是饱和的(梯度趋于0).
- 回归模型: y p r e d = x ∗ w + b y_{pred} = x * w + b ypred=x∗w+b
- 逻辑回归: y p r e d = σ ( x ∗ w + b ) y_{pred} = \sigma(x * w + b) ypred=σ(x∗w+b)
交叉熵
逻辑回归损失函数: l o s s = − ( y l o g ( y p r e d ) + ( 1 − y ) l o g ( 1 − y p r e d ) ) loss = -(ylog(y_{pred})+(1-y)log(1-y_{pred})) loss=−(ylog(ypred)+(1−y)log(1−ypred)),其中 y p r e d = P ( c l a s s = 1 ) y_{pred} = P(class = 1) ypred=P(class=1),计算分布之间的差异,类似熵的计算公式,称作 交叉熵 !
| 真实分类 y | 预测分类 y p r e d y_{pred} ypred | BCE Loss |
|---|---|---|
| 1 | 0.2 | 1.6094 |
| 1 | 0.8 | 0.2231 |
| 0 | 0.3 | 0.3567 |
| 0 | 0.7 | 1.2040 |
可以看出,预测分类的概率越接近真是分类,其损失函数值就越小。
6.2 逻辑回归模型
6.2.1 自定义模型类
import torch
# import torch.nn.functional as F
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
# sigmoid激活函数中没有参数,所以整个模型要训练的参数还是原来的回归部分的W和b
def forward(self, x):
# torch里自带函数模块
y_pred = torch.sigmoid(self.Linear(x))
# y_pred = F.sigmoid(self.linear(x))
return y_pred
torch.nn.functional包,包含了许多需要的函数,如tanh等
pytorch更新后,用torch.sigmoid代替torch.nn.sigmoid;
6.2.2 交叉熵损失函数
criterion = torch.nn.BCELoss(size_average = False)。是否求均值会影响到学习率的设定。若求均值,相应的损失函数值就要小进而梯度也会小,此时学习率若很大,不利于模型的优化。
优化器因为需要调整的参数还是W和b两个一维参数,所以和线性回归一样
# criterion = torch.nn.BCELoss(size_average = False)
criterion = torch.nn.BCELoss(reduction= 'sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
pytorch更新后, 用reduction = 'sum’代替size_average
6.2.3 Training Cycle
训练步骤和回归模型一样
print("before: f(5)", model(torch.Tensor([[5.0]])))
for epoch in range(100):
iter_list.append(epoch)
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
bce_list.append(loss.item())
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("after: f(5)", model(torch.Tensor([[5.0]])))
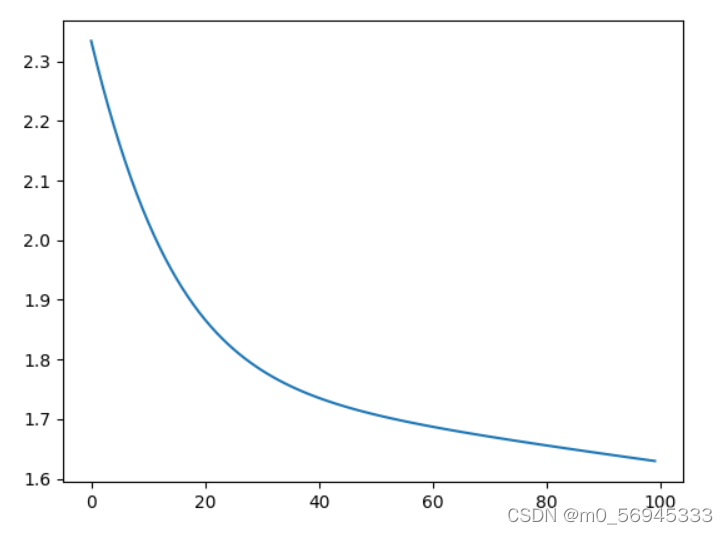
7. 多维特征处理
之前的线性回归和逻辑斯蒂回归所涉及到的都是简单的一维特征,实际问题中遇到的都是高维。
7.1 结构化特征
如图是一个糖尿病的分类样本。每一行是一个样本,数据库中称为record;每一列是一个特征,数据库中称为字段。这样一个二维关系表就可以认为是一个结构化的数据。
一维的逻辑回归前馈函数(第i个1维样本):
y
p
r
e
d
(
i
)
=
σ
(
x
(
i
)
∗
w
+
b
)
y_{pred}^{(i)} = \sigma(x^{(i)} * w + b)
ypred(i)=σ(x(i)∗w+b)
多维的逻辑回归前馈函数(第i个N维样本):
y
p
r
e
d
(
i
)
=
σ
(
∑
n
=
1
N
x
n
(
i
)
∗
w
n
+
b
)
=
σ
(
[
w
1
w
2
.
.
.
w
8
]
∗
[
x
1
(
i
)
x
2
(
i
)
.
.
.
x
8
(
i
)
]
+
b
)
=
σ
(
z
(
i
)
)
y_{pred}^{(i)} = \sigma(\sum_{n=1}^{N}{x^{(i)}_{n} * w_{n} + b}) =\sigma( \left[ \begin{matrix} w_{1} &w_{2}& ...& w_{8} \end{matrix} \right] * \left[ \begin{matrix} x^{(i)}_{1}\\x^{(i)}_{2} \\ ... \\x^{(i)}_{8} \end{matrix} \right] + b ) = \sigma(z^{(i)})
ypred(i)=σ(∑n=1Nxn(i)∗wn+b)=σ([w1w2...w8]∗⎣⎢⎢⎢⎡x1(i)x2(i)...x8(i)⎦⎥⎥⎥⎤+b)=σ(z(i))
7.2 Mini-Batch
- 使用Mini-Batch计算可以提高计算速度。
对于有N个样本的数据集:
z
(
1
)
=
[
w
1
w
2
.
.
.
w
8
]
∗
[
x
1
(
1
)
x
2
(
1
)
.
.
.
x
8
(
1
)
]
+
b
z^{(1)} = \left[ \begin{matrix} w_{1} &w_{2}& ...& w_{8} \end{matrix} \right] * \left[ \begin{matrix} x^{(1)}_{1}\\x^{(1)}_{2} \\ ... \\x^{(1)}_{8} \end{matrix} \right] + b
z(1)=[w1w2...w8]∗⎣⎢⎢⎢⎡x1(1)x2(1)...x8(1)⎦⎥⎥⎥⎤+b
……
z
(
N
)
=
[
w
1
w
2
.
.
.
w
8
]
∗
[
x
1
(
N
)
x
2
(
N
)
.
.
.
x
8
(
N
)
]
+
b
z^{(N)} = \left[ \begin{matrix} w_{1} & w_{2} &...& w_{8} \end{matrix} \right] * \left[ \begin{matrix} x^{(N)}_{1}\\x^{(N)}_{2} \\ ... \\x^{(N)}_{8} \end{matrix} \right] + b
z(N)=[w1w2...w8]∗⎣⎢⎢⎢⎡x1(N)x2(N)...x8(N)⎦⎥⎥⎥⎤+b
注意,在计算这N个样本时它们的W向量是一样的,因为是同一个模型。这样 就可以进一步化简,得到
[
z
(
1
)
.
.
.
z
N
]
=
[
x
1
(
1
)
.
.
.
.
.
.
x
8
(
1
)
.
.
.
.
.
.
x
1
(
N
)
.
.
.
.
.
.
x
8
(
N
)
]
[
w
1
w
2
.
.
.
w
8
]
+
[
b
.
.
.
b
]
\left[ \begin{matrix} z^{(1)} \\ .\\.\\.\\z^{N} \end{matrix} \right] = \left[ \begin{matrix} x^{(1)}_{1} &......&x_{8}^{(1)} \\... & &...\\ x_{1}^{(N)}&......&x_{8}^{(N)} \end{matrix} \right] \left[ \begin{matrix} w_{1}\\w_{2}\\ .\\.\\.\\w_{8} \end{matrix} \right] + \left[ \begin{matrix} b\\.\\.\\.\\b \end{matrix} \right]
⎣⎢⎢⎢⎢⎡z(1)...zN⎦⎥⎥⎥⎥⎤=⎣⎢⎡x1(1)...x1(N)............x8(1)...x8(N)⎦⎥⎤⎣⎢⎢⎢⎢⎢⎢⎡w1w2...w8⎦⎥⎥⎥⎥⎥⎥⎤+⎣⎢⎢⎢⎢⎡b...b⎦⎥⎥⎥⎥⎤
- 一组函数运算合并成一个矩阵运算,这样向量化计算可以利用并行运算能力
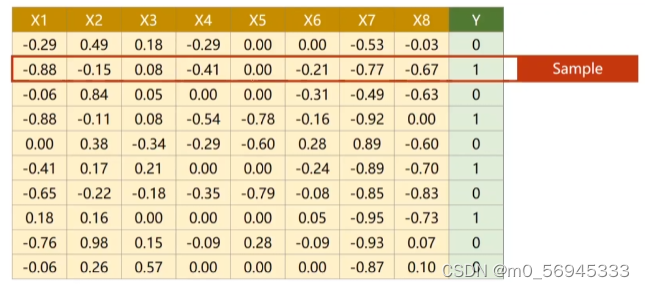
这样的八个特征得到一个标量的运算,其输入维度为8,输出维度为1
self.Linear = torch.nn.Linear(8, 1)
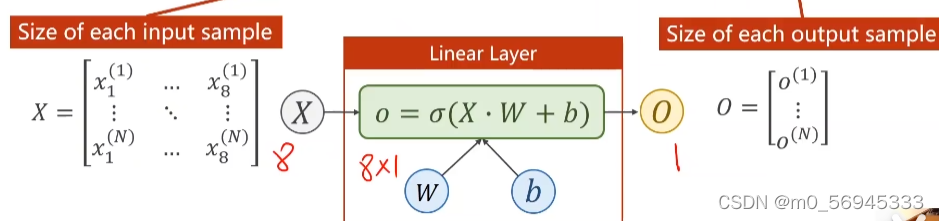
7.3 增加逻辑回归的层数
下图为7.2的运算过程。将八维的X样本,通过一个W矩阵映射到了一个一维的O层。
self.Linear = torch.nn.Linear(8, 1)
- 现在我们让X从八维映射到二维,就需要通过一个 2*8 的W矩阵实现。
self.Linear = torch.nn.Linear(8, 2)
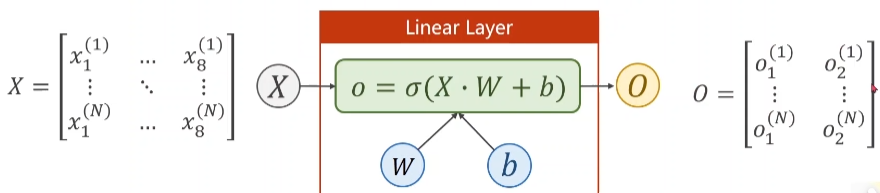
如此再经过一层torch.nn.Linear(2, 1)就又可以从二维降到最终想要得到的一维向量。
神经网络的思想就是通过一层又一层的线性映射加上每层之间的非线性函数,找到一个最优的权重组合,其本质就是寻找一个最优的非线性空间变化函数。通过加了非线性函数的映射,我们只需要调整每一层线性函数就可以达到一个良好的拟合效果。
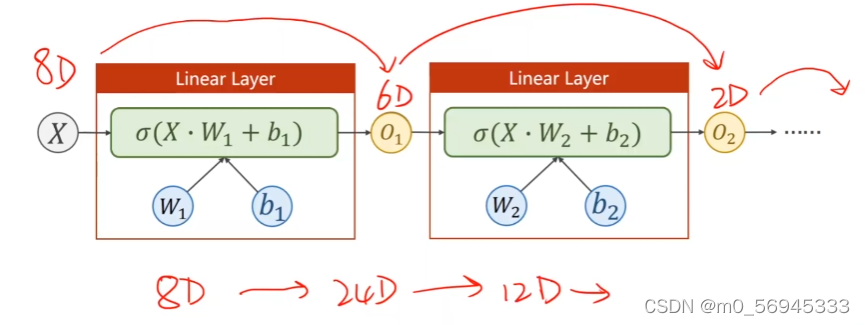
- 图中的 O 1 , O 2 , . . . O_{1}, O_{2}, ... O1,O2,...就称为隐藏层
为什么要使用多层降维:如果从高维直接将到一维,降维跨度太大会丢失许多特征。
7.4 使用神经网络解决多维输入
建立数据集 – 设计模型 – 选择损失和优化器 – 训练周期
7.4.1 导入数据集
本例中使用的数据集是以逗号分隔的csv文件,前八列为特征,最后一列是标签

使用numpy自带的函数numpy.loadtxt()读取
import numpy as np
xy = np.loadtxt('dataset.csv.gz', delimeter = ',', dtype = np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1] ])
loadtxt()需要指明分隔符,例如本例的以逗号分隔的文件就需要指定delimeter = ','- x_data因为有八个特征,读取下来是矩阵。y_data只有一个特征,如果不是
xy[:, [-1] ]而是xy[:, -1]的话,y_data读下来就会是一个列向量,这不是和x_data对应的想要的数据格式。
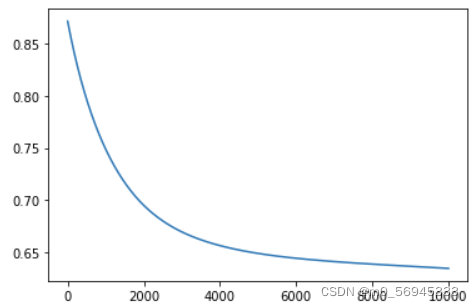
7.4.2 设计多层线性模型
使用多层隐藏层叠加,效果可能要优于单层网络结构
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init()__
self.Linear1 = torch.nn.Linear(8, 6) # 8维到6维
self.Linear2 = torch.nn.Linear(6, 4) # 8维到6维
self.Linear3 = torch.nn.Linear(4, 1) # 8维到6维
self.activate = torch.nn.ReLU6() # 激活函数
def forward(self, x):
x = self.activate(self.Linear1(x))
x = self.activate(self.Linear2(x))
x = torch.sigmoid(self.Linear3(x))
return x
- 对于这种连续的序列问题,通常采用一个变量传递隐藏层,这样不容易出错
torch.nn.Sigmoid()是一个类;torch.sigmoid()是一个函数。前者不能直接传入参数,需要先进行实例化,或者torch.nn.Sigmoid()(x);而后者可以直接传入参数。- 对于为什么ReLU下最后一层要进行sigmoid():因为ReLU的映射范围是【0,∞】,需要sigmoid()映射到[0, 1]。
- 多分类考虑使用
softmax。
- 模型效果
8. 加载数据集
构造Dataset 和 DataLoader。
- Dataset:构造数据集,应该支持使用索引取样本
- DataLoader:取出Mini-Batch一组数据
回顾第7章中,每代训练model(x_data)都一次性的传入了所有的样本。随机梯度下降算法中,可供我们选择的方式包括:
- 只用一个样本:即随机梯度下降。会得到好的结果,有助于克服鞍点问题。[ x1, x2, x3, … ]
- 使用全部样本:最大化利用并行计算的优势 [ [x1], [x2], [x3], …]
- Mini-Batch:均衡性能与效率。
Training Cycle
日后使用mini-batch(下文简称batch)方式时,需要使用循环嵌套的格式
# Training Cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
执行mini-batch
8.1 Batch的三个专用词汇
8.1.1 Epoch
控制最外层循环。当所有样本都完成一次前馈和反馈操作,称为进行了一次***epoch***
8.1.2 Batch-Size
批量大小。在进行一次前馈和反馈操作时,使用的样本个数。
8.1.3 Iterations
控制内层循环。训练完以Batch-Size大小划分的样本所要执行的前馈反馈次数。
比如使用一万个样本。每次训练使用1000个,这样一次epoch就需要执行10次前馈反馈。Batch-Size就等于1000;Iteration就等于10
8.2 DataLoader
为了进行小批量的训练(Batch),需要使用DataLoader类生成一个Batch生成器,每次yield出一个batch_size大小的batch。
两个重要参数
- batch_size:毫无疑问,这是必须指定的参数,决定了每个batch的大小
- shuffle:因为传入的数据集是固定的,所以每次epoch所使用的batch内部是一样的(假如样本一、二第一次迭代在一个batch里,以后每次迭代都会在一个batch里)。这种不随机性可能会影响到模型的效果。因此采用
shuffle = True实现每次创建生成器之前先打乱样本的顺序,让生成器每次迭代提供不一样的batch。
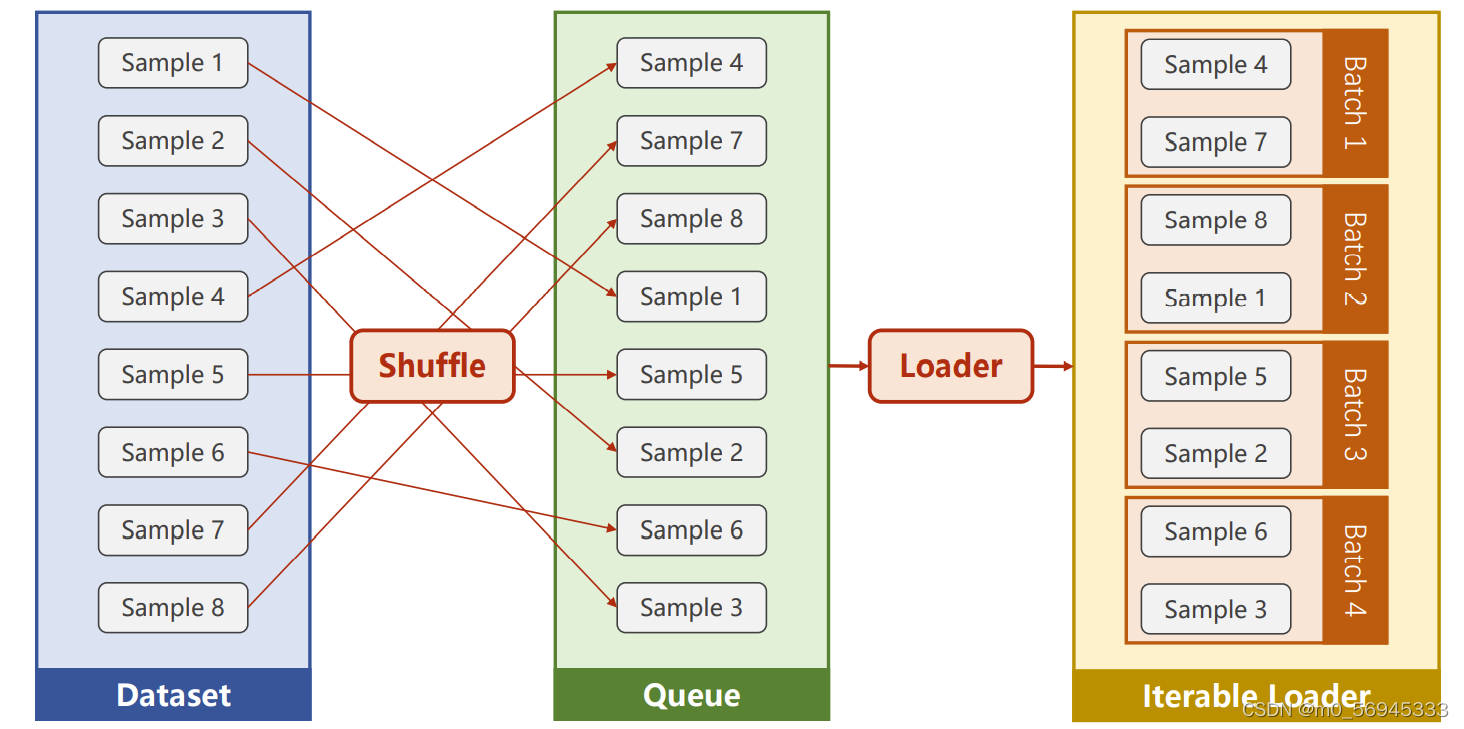
8.3 代码
大部分上面已经都实现过了,下面主要是搭积木的过程了。所以直接把整段代码粘上了,在代码结束时说明一些值得提的问题。
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
# 1. 加载数据集
class DiabetesDataset(Dataset): # 继承抽象类
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, #
batch_size=32, #
shuffle=True, #
num_workers=0 # 并行!!
)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,2)
self.linear4 = torch.nn.Linear(2,1)
self.activate = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x= self.activate(self.linear1(x))
x= self.activate(self.linear2(x))
x= self.activate(self.linear3(x))
x= self.sigmoid(self.linear4(x))
return x
model = Model()
criterion = torch.nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 0.001)
if __name__ == '__main__':
iter_list = []
bce_list = []
print("start from 19:46")
for epoch in range(200):
iter_list.append(epoch)
BCE = 0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
BCE = loss.item()
# print(epoch, BCE)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, BCE)
bce_list.append(BCE)
plt.plot(iter_list, bce_list)
plt.show()
1. Dataset类
从torch.utils.data里导入的Dataset是一个抽象类。抽象类无法实例化,所以需要继承并重新定义。
在自定义Dataset类时需要实现的三个魔法函数
- 初始化函数
__init__():根据要加载的数据集大小的不同,又可以分为两种方式- 第一种:一口气将所有数据读进程序,用内存来临时存储,在
__getitem()__函数中,直接返回第i个元素。这样的操作仅能支持一些较小的数据集,因为它对内存的开销是十分大的。 - 第二种:采取分布式存储。即用列表等方式存储文件的地址而不是元素。在
__getitem()__函数中,返回第i个文件,现读。
- 第一种:一口气将所有数据读进程序,用内存来临时存储,在
- 可根据索引返回值
__getitem()__ - 返回数据集长度
__len()__
2. DataLoader
使用DataLoader构造一个train_loader生成器。设计的参数有dataset,shuffle,batch_size和num_workers。其中num_workers是决定采取多少个CPU核来读数据。这个目前还没有搞懂。
- RuntimeError
在Windows环境下,如果直接调用DataLoader生成的train_loader对象可能会引起报错。这是涉及到这涉及到Linux和Windows多线程的实现的差异,Windows使用spwan而 Linux使用fork(C语言的CPU内核API)。解决办法是将含DataLoader的操作封装(wrap)起来,放到任意一个函数下或者if语句内都可以。常见的一种操作是套用if __name__ == '__main__:'
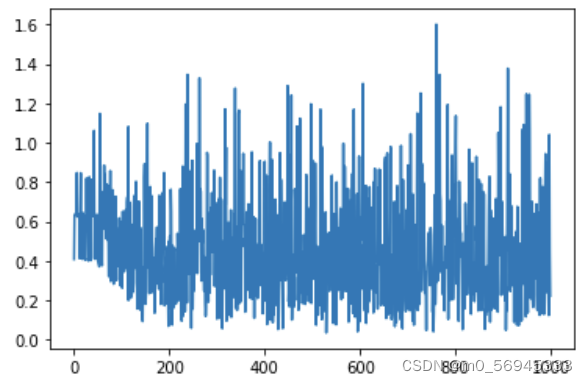
但是使用jupyter lab哪种方式都不行(所以直接注释掉nums_worker
最后附上交叉熵超过1.6的截图,纯纯垃圾模型
9. 多分类问题
多分类的第一种思路:
二分类是最后的输出是P(class = 1),以此来判断属于那个分类。那么对于多分类(比如手写体分为10类),我们可以让输出向量维度为10,以此判断属于哪一个类别。这样的方法使得在分类一个样本时,属于某一分类的概率不会对属于其他分类的概率造成影响,但是我们希望,如果样本在A类上表现的很好(概率很大),表现好的分类可以抑制其它于其他样本的概率。为了实现抑制的效果,我们采取归一化。
原则上,归一化后求N个样本的概率分布只需要计算N-1 个样本的分布,最后一个概率使用 1 − ∑ P 1-\sum{P} 1−∑P就可以了。但是在Pytorch中,为了充分利用它的并行计算能力,最好使得每一个计算步骤是相似的,因此我们仍对N个样本的分布直接计算。
9.1 softmax层
P ( c l a s s = i ) = e Z i ∑ t = 1 N e Z t P(class = i) =\frac{e^{Z_{i}}}{ \sum_{t = 1}^{N}{e^{Z_{t}}}} P(class=i)=∑t=1NeZteZi,借助这样一个函数,可以实现分布的归一化。
- 求损失函数时用到了onehot向量(交叉熵)。
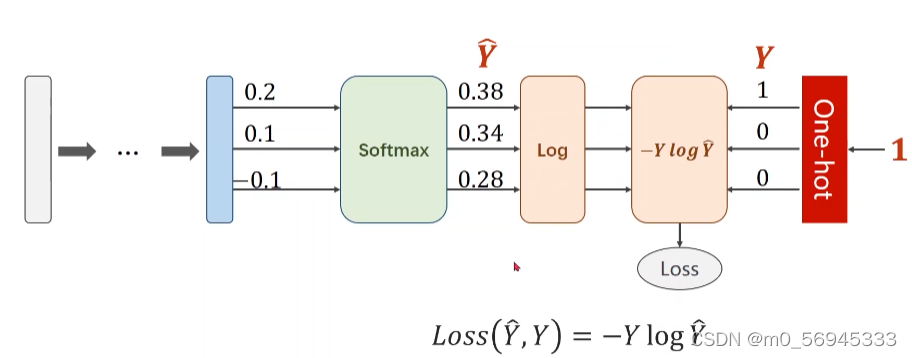
隐藏层中仍沿用sigmoid()作为激活函数,最后的输出层使用Softmax且不能添加sigmoid。
9.2 softmax封装
在求得输出层的输入后,求损失的交叉熵函数(包括Softmax层,Log层和交叉熵层)被Pytorch封装好了,使用时直接调用
import torch
y = torch.LongTensor([0]) #标签要求是LongTensor
z = torch.Tensor([[0.2],[0.1],[-0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(y, z)
- 标签y要求是
LongTensor torch.nn.CrossEntropyLoss()作为损失函数
9.3 MNIST训练
准备数据集 – 定义模型类 – 选择分类器和优化器 – Training Cycle – Test
9.3.1 包s
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as f
import torch.optim as optim
torchvision.transform()主要用于处理图像数据- datasets导入数据
9.3.2 准备数据集
batch_size = 64
transform = transform.Compose([
transform.ToTensor(),
transform.Normalize((0.1307, ), (0.3081, ))
])
transform.ToTensor():图像数据是一个 R w ∗ h ∗ c R^{w * h * c} Rw∗h∗c的格式(宽 * 高 * 通道),而ToTensor()的作用就是转换为 R c ∗ w ∗ h R^{c * w * h} Rc∗w∗h格式,以满足它内部高效计算的实现transform.Normalize():数据标准化。一个是均值,另一个是标准差。0.1307和0.3081是MNIST自己的。transform.Compose(list( )):实现一个Pipeline的操作,其中的ToTensor和Normalize都是可实例化的。传入的文件,先传入ToTensor(),再传入Normalize()。
train_dataset = datasets.MNIST(
root = './dataset/mnist',
train = True,
download = True,
transform = transform
)
train_loader = DataLoader(
train_dataset,
shuffle = True,
batch_size = batch_size
)
# 测试集
test_dataset = datasets.MNIST(
root = './dataset/mnist',
train = False,
download = True,
transform = transform
)
test_loader = DataLoader(
test_dataset,
shuffle = False,
batch_size = batch_size
)
9.3.3 模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10) # 输出维度
def forward(self, x):
x = x.view(-1, 784) # 将1*28*28矩阵转换为张量
x = f.relu(self.l1(x))
x = f.relu(self.l2(x))
x = f.relu(self.l3(x))
x = f.relu(self.l4(x))
return self.l5(x) # 注意最后一部分不需要做激活
model = Net()
view()函数:类似于reshape函数。其作用是重塑Tensor的维度。如tensor.view(m,n)就是将tensor转化为m行n维的张量。当m取-1时,tensor可以根据传入的n自动计算。
在我们定义的模型中,每次的输入样本要求是一个batch_size(个样本) * feature(维度)的矩阵,这就要求将原本图像尺寸为c * w * h的三维矩阵转换为 c·w·h的一维向量。- 最后一层
self.linear5(x)不需要激活,因为下文选择的优化器是CrossEntropyLoss(),它要求输入保持激活前的样子,因为它自带softmax激活。
9.3.4 优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum = 0.5) #动量
带动量(momentum)的SGD算法
目的在于加快收敛速度。
一般不带momentum的更新公式是
x
=
x
−
α
∗
d
x
x= x-\alpha * dx
x=x−α∗dx,即以一定的学习率沿着梯度的反方向减小。
而引入momentum参数后,更新公式就变成了
v
=
β
∗
v
−
α
∗
d
x
v = \beta * v - \alpha * dx
v=β∗v−α∗dx
x
=
x
+
v
x = x + v
x=x+v
其中的
β
\beta
β就是momentum系数。第二种更新公式的理解是,如果上一次的momentum(就是v)与这一次的梯度负向是相同的,则本次下降幅度就会变大,可以做到加速收敛。同时也增大了跳出鞍点的可能。(应该是这样
9.3.5 训练
def train(epoch):
loss_sum = 0.0
for idx, data in enumerate(train_loader):
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
if idx % 300 == 299:
print(epoch+1, idx+1, loss_sum/300) # 看平均损失
loss_sum = 0.0
9.3.6 测试
def test():
correct = 0
total = 0
with torch.no_grad(): # 以下代码就不会计算梯度
for data in test_loader:
images, labels = data
outputs = model(images) # imgages个样本行共10个列的矩阵
_, predicted = torch.max(outputs.data, dim=1) # 返回最大值所在下标 和最大值 dim是第一个维度
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("accuracy on test set: %d %%" % (100 * correct / total))
- with关键字使得在with中进行的语句都不会执行梯度计算
torch.max(input, dim)函数
在计算准确率时比较有用。
- input参数:是***softmax输出的***一个tensor
- dim参数:取值为0/1,0是每列的最大值,1是每行的最大值
- 返回值:返回两个tensor。第一个tensor是每行的最大值,第二个是每行最大值的索引。
# main
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
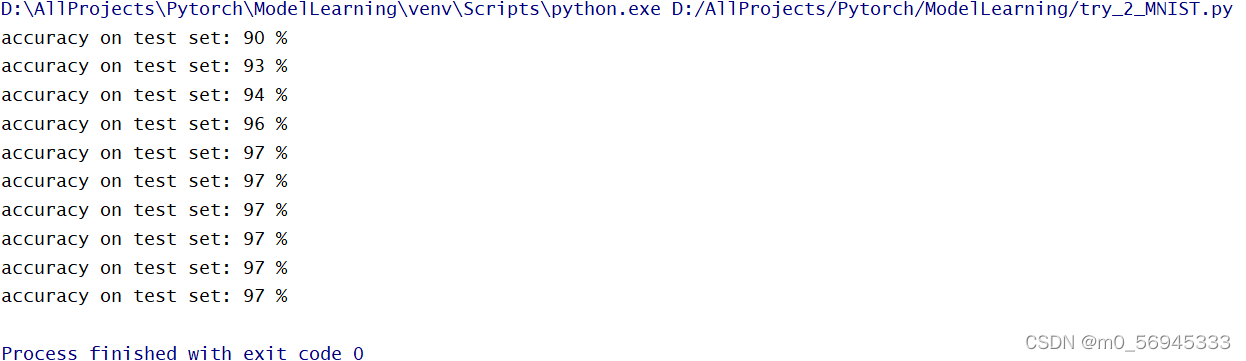
较为不错的训练结果
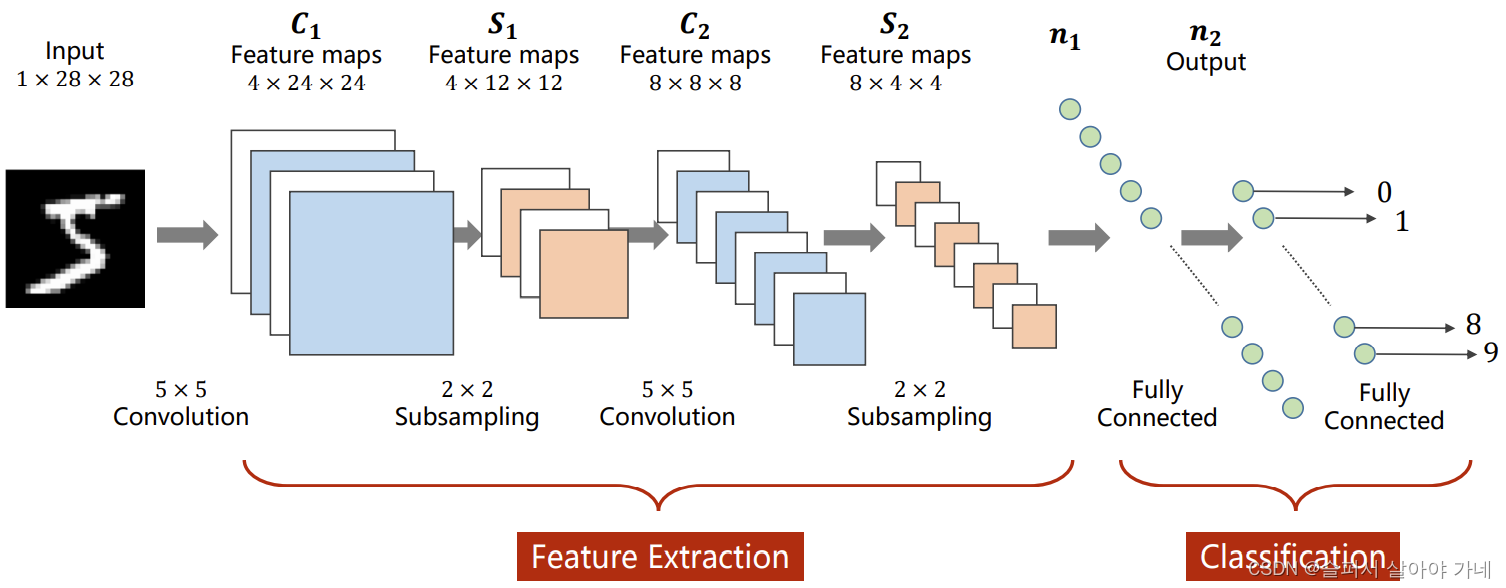
10. 卷积神经网络
卷积神经网络大体可分为特征提取和分类器两个部分。特征提取做的就是不断卷积和池化,并且在最后一层将多通道的特征展开成一个一维的向量。然后分类器借助得到的一维向量进行一层的全连接得到最终的分类结果。
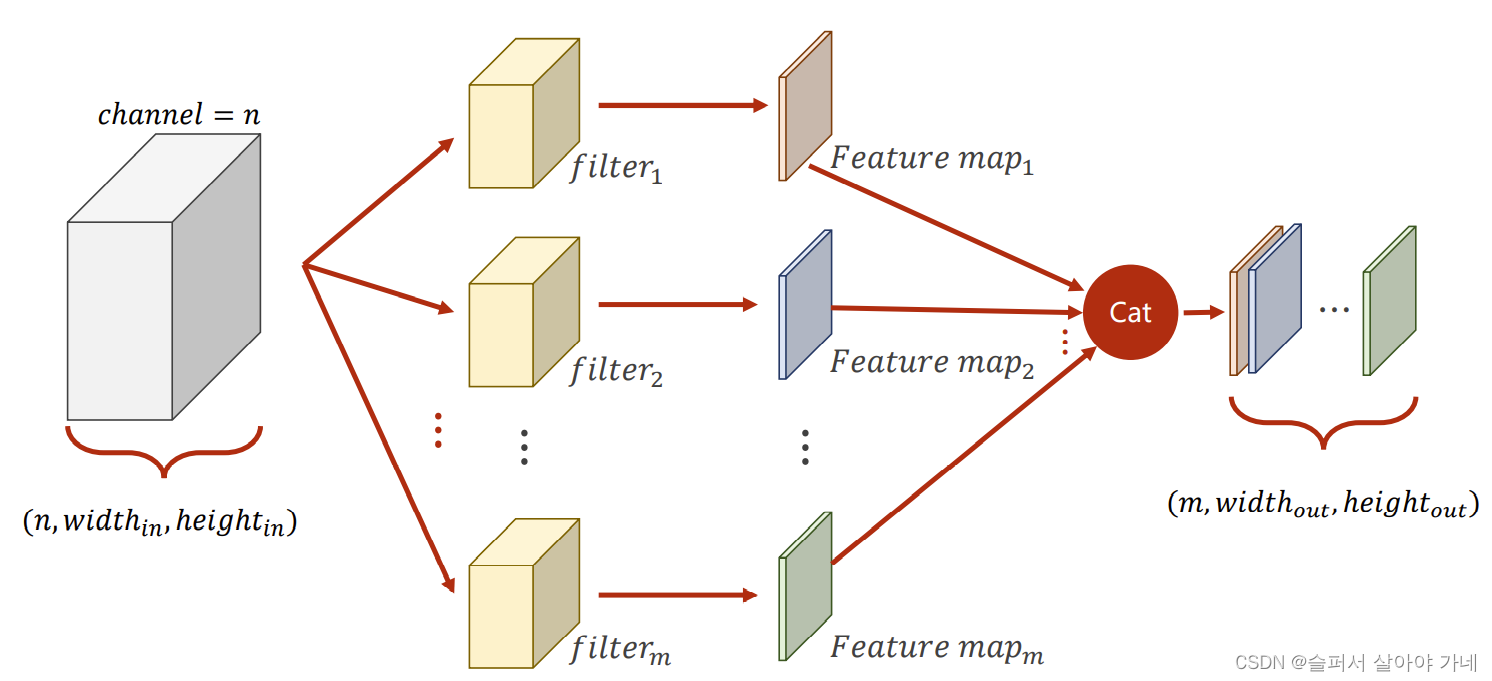
10.1 卷积核
对于一个n通道的输入,1个n通道的w*h的卷积核可以得到一个1通道的feature map。m个卷积核可以得到m个1通道的feature map。
注意:卷积核中的通道不是恒为一的
- 需要注意以下两个等式
- 卷积核的通道数 = 输入样本通道数
- 输出样本通道数 = 卷积核个数
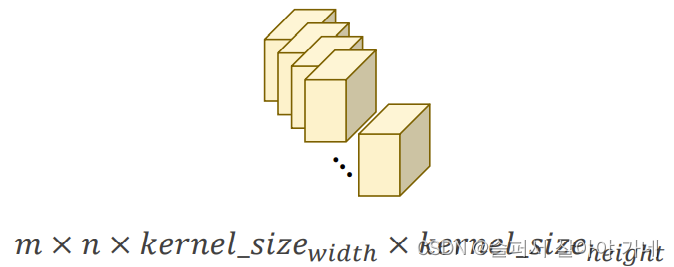
所以一次卷积操作所需要的卷积核是一个四阶张量, R c h i n × k _ s i z e 宽 × k _ s i z e 高 × c h o u t R^{ch_{in} × k\_size_{宽} × k\_size_{高} × ch_{out}} Rchin×k_size宽×k_size高×chout 。其中两个ker_size是自定义的。
10.2 Python计算过程
使用torch.nn.Conv2d()进行一层的卷积操作。
import torch
in_channel, out_channel = 5, 10
width, height = 100, 100 # 图像宽高
kernel_size = 3 # 卷积核大小
batch_size = 1
input = torch.randn( # 随即赋值
batch_size,
in_channels,
width,
height
)
conv_layer = torch.nn.Conv2d( # 必须的三个参数:输入通道,输出通道,卷积核大小
in_channels,
out_channels,
kernel_size = kernel_size # 想用长方形的卷积核 就传入元组(长, 宽)0
)
out = conv_layer(input) # 一次卷积
prnit(input.shape) # [batch, 通道, 长, 宽]
print(conv_layer.weight.shape) # [输出通道, 输入通道, 卷积宽, 卷积高]
10.3 初始化常见参数
10.3.1 padding
补零。padding = 1, 填充一圈0。
import torch
input = [3,4,6,5,2,
2,3,6,3,2,
2,5,6,2,6,
5,2,3,6,2,
4,5,9,8,1
]
input = torch.Tensor(input).view(1, 1, 5, 5) # 分别是 batch, channel, width 和 height
conv_layer = torch.nn.Conv2d(1, 1, kernel_size = 3, padding = 1, bias = False)
kernel = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8 ,9]).view(1, 1, 3, 3) # 手动为kernel赋值
conv_layer.weight.data = kernel.data # conv_layer.weight才是真正的kernel
10.3.2 stride
步长。上边代码改动:
conv_layer = torch.nn.Conv2d(1, 1, kernel_size = 3, stride = 2, bias = False)
10.3.3 Pooling
maxpooling_layer = torch.nn.MaxPool2d(kernel_size = 2) # 使得pooling的stride也变为2
10.4 简单卷积操作MNIST
- 需要确定最后输出层的输入维度。即最有一层pooling的参数个数


















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









