






Mapreduce词频统计
初始化Maven项目
修改pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hdfs_upload</artifactId>
<version>1.0-SNAPSHOT</version>
<name>hdfs_upload</name>
<!-- FIXME change it to the project's website -->
<url>http:///maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<!-- hadoop基础库 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- hadoop客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- hadoop hdfs -->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
<scope>test</scope>
</dependency>
<!-- hadoop-mapreduce -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<!-- 控制⽇志信息输出 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
本地编写java代码
对word.txt文件进行每个单词出现次数的统计
word.txt文件内容:
zqk zqk
mfh mfh
zhangqiongke zhangqiongke
在项目目录下src/main/java下创建com.example文件夹
在项目目录下src/main/java/com.example下创建
- WordCountMain
- WordCountMapper
- WordCountReducer
WordCountMapper
package com.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
Text k = new Text();
IntWritable v = new IntWritable(1);
// 将Text类型⽂本转换为String类型
String text = value.toString();
// 分词,存储到String数组
String[] words = text.split(" ");
// 输出
for (String word : words) {
// k.set(word):将word装载到k中
k.set(word);
// 将map()函数输出的键值对写⼊到MapReduce上下⽂环境
context.write(k, v);
}
}
}
WordCountReducer
package com.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws
IOException, InterruptedException {
int sum=0;
IntWritable v = new IntWritable();
for (IntWritable count : values) {
// count.get():获取 count 值
sum += count.get();
}
// 将sum值装载到v中
v.set(sum);
// 将reduce()函数输出的键值对写⼊到MapReduce上下⽂环境
context.write(key,v);
}
}
WordCountMain
package com.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception{
// 创建hadoop集群配置对象
Configuration conf = new Configuration();
// 创建⼀个 job 实例
Job job = Job.getInstance(conf,"word count");
// 设置主类
job.setJarByClass(WordCountMain.class);
// 设置 job 的 mapper 类
job.setMapperClass(WordCountMapper.class);
// 设置 Mapper 的输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置 Mapper 的输出值类型
job.setMapOutputValueClass(IntWritable.class);
// 设置 job 的 reducer 类
job.setReducerClass(WordCountReducer.class);
// 设置 Reducer 的输出键类型
job.setOutputKeyClass(Text.class);
// 设置 Reducer 的输出值类型
job.setOutputValueClass(IntWritable.class);
// 指定 job 的输⼊⽂件路径
FileInputFormat.setInputPaths(job, new Path("C:\\Users\\11150\\Desktop\\word.txt"));
// 指定 job 的输出⽂件路径
FileOutputFormat.setOutputPath(job, new Path("C:\\Users\\11150\\Desktop\\newword.txt"));
Path path = new Path("C:\\Users\\11150\\Desktop\\newword.txt");
FileSystem fs = FileSystem.get(conf);
// 判断⽬录是否存在,如果存在,删除该⽬录
if (fs.exists(path)) {
fs.delete(path,true);
}
// 等待任务结束
System.exit(job.waitForCompletion(true)?0:1);
}
}
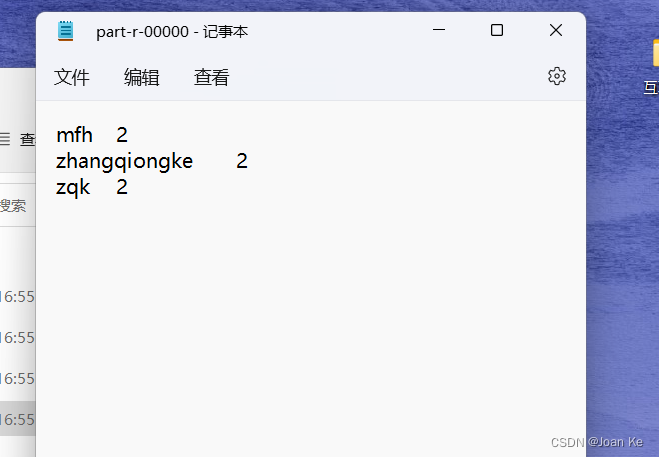
运行结果















 3367
3367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









