







垃圾回收器
(1)GC分类和GC性能指标
分类:
| 按线程数分 | 串行GC(只有一个cpu执行GC)、并行GC |
|---|---|
| 按工作模式分 | 并行式GC(与应用程序线程交替工作)、独占式GC(暂停应用程序线程) |
| 碎片处理 | 压缩式GC(回收碎片)、非压缩式GC(不回收GC) |
| 工作内存 | 年轻代GC、老年代GC |
性能指标:
主要是在意这三个性能指标
-
吞吐量:运行用户线程/总时间
-
暂停时间:用户线程暂停时间
-
垃圾收集开销:垃圾GC时间/总时间
-
内存占用:Java堆区所在的内存大小
(2)GC发展史
串行Serial GC--------->Parallel GC 和Concurrent Mark Sweep GC(CMS)------>G1-JDK11--->Epsilion GC 和ZGC
Serial Old GC Parallel Old GC
-
1999年随JDK1.3.1一起来的是串行方式的serialGc,它是第一款GC。ParNew垃圾收集器是Serial收集器的多线程版本
-
2002年2月26日,Parallel GC和Concurrent Mark Sweep GC跟随JDK1.4.2一起发布·
-
Parallel GC在JDK6之后成为HotSpot默认GC。
-
2012年,在JDK1.7u4版本中,G1可用。
-
2017年,JDK9中G1变成默认的垃圾收集器,以替代CMS。
-
2018年3月,JDK10中G1垃圾回收器的并行完整垃圾回收,实现并行性来改善最坏情况下的延迟。
-
2018年9月,JDK11发布。引入Epsilon 垃圾回收器,又被称为 "No-Op(无操作)“ 回收器。同时,引入ZGC:可伸缩的低延迟垃圾回收器(Experimental)
-
2019年3月,JDK12发布。增强G1,自动返回未用堆内存给操作系统。同时,引入Shenandoah GC:低停顿时间的GC(Experimental)。·2019年9月,JDK13发布。增强zGC,自动返回未用堆内存给操作系统。
-
2020年3月,JDK14发布。删除cMs垃圾回收器。扩展zGC在macos和Windows上的应用
7种经典GC:
-
串行回收器:Serial、Serial old
-
并行回收器:ParNew、Parallel Scavenge、Parallel old
-
并发回收器:CMS、G1
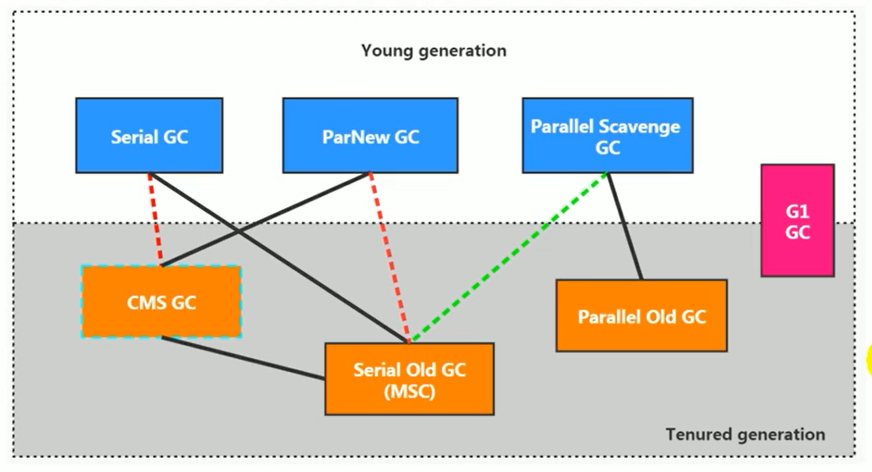
-
两个收集器间有连线,表明它们可以搭配使用:Serial/Serial old、Serial/CMS、ParNew/Serial old、ParNew/CMS、Parallel Scavenge/Serial 0ld、Parallel Scavenge/Parallel 01d、G1;
-
其中Serial o1d作为CMs出现"Concurrent Mode Failure"失败的后备预案。
-
(红色虚线)由于维护和兼容性测试的成本,在JDK 8时将Serial+CMS、ParNew+Serial old这两个组合声明为废弃(JEP173),并在JDK9中完全取消了这些组合的支持(JEP214),即:移除。
-
(绿色虚线)JDK14中:弃用Paralle1 Scavenge和Serialold GC组合(JEP366)
-
(青色虚线)JDK14中:删除CMs垃圾回收器(JEP363)
两个小问题:
-
为什么Parallel Scanvenge GC 不能和CMS GC一起合作:
PS GC底层实现的框架不同
-
为什么存在多个GC
没有在任何情况下都适用的GC,选择的只是对具体应用最合适的GC
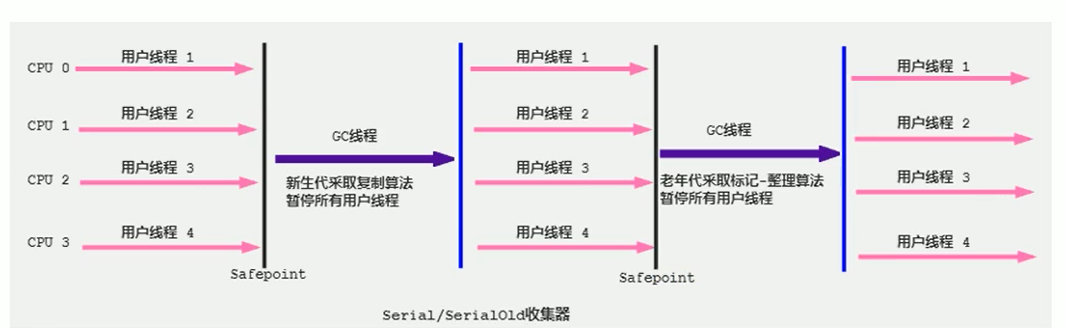
(3)Serial GC
Serial GC:
串行收集器(只有一个cpu进行GC)、进行年轻代的垃圾收集、采用Copying垃圾清除算法、串行进行垃圾回收、存在STW
Serial Old GC:
串行收集器、进行老年代的垃圾收集、Mark-Compact垃圾清除算法、串行进行垃圾回收、存在STW
-
client:默认的老年代GC
-
Server模式下:与新生代Parallel Scavenge配合 作为CMS的后备GC收集
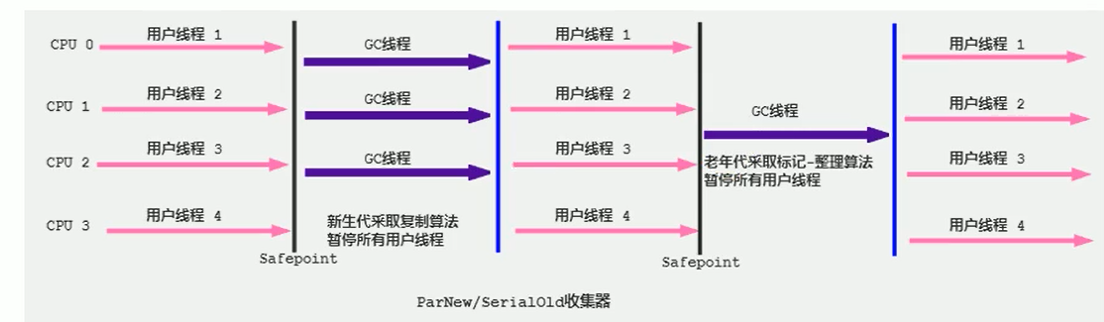
(4)ParNew GC
parallel的缩写,并行回收(其他与Serial GC没有区别)
ParNew和Serial Old配合使用:
-
新生代:回收频繁、用并行比较高效
-
老年代:回收少、用串行节省资源
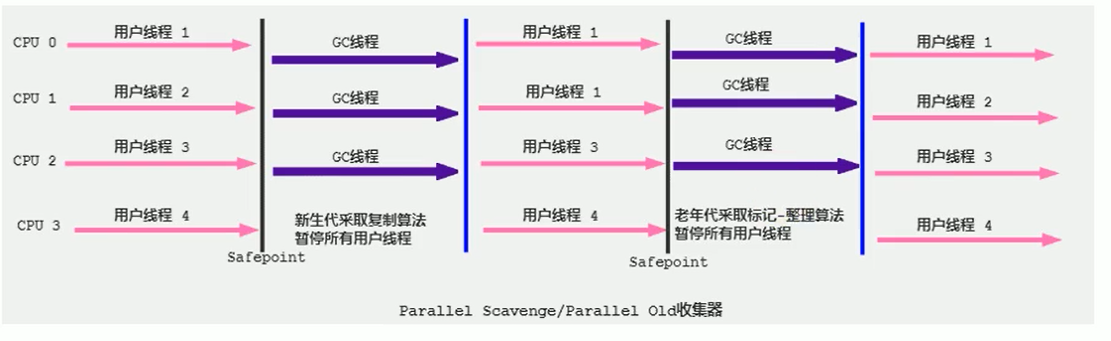
(5)Parallel 回收器
吞吐量优先
Parallel Scavenge:
并行收集器、进行年轻代的垃圾收集、Copying垃圾清除算法、STW
与ParNew不同:
-
Parallel Scavenge是为了达到一个可控制的吞吐量
-
自适应调节策略(可以动态调整内存)
Parallel Old GC:
并行收集器、进行老年代的垃圾收集、Mark-Compact、STW
JDK8中默认GC:Parallel+Parallel Old
(6) CMS回收器
基本信息:
concurrent Mark Sweep GC 主打低延迟(尽可能缩短GC的停顿时间)
并发收集器(让垃圾收集线程和用户线程同时工作)、Mark-Sweep垃圾清除算法、进行老年代的垃圾收集、STW
只能和Serial GC 和ParNew GC配合使用,不能和Parallel Scavenge GC配合

收集过程:
-
初始标记:只标记与GC Roots直接关联的对象,STW
-
并发标记:标记所有存活对象(并发标记)、因为有用户线程存在所以不能再内存填满了再进行回收(当堆空间内存使用率达到一定的阈值就开始进行回收)
要是CMS运行期间预留的内存无法满足程序需要,就会出现一次“Concurrent Mode Failure” 失败,这时虚拟机将启动后备预案:临时启用Serial old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。
-
重新标记:由于上一步并行,所以可能存在新的未被标记的对象。(STW)
-
并发清除:清除已死亡对象、释放空间,但是存在内存碎片(并行)
CMS为什么不使用标记整理算法?
因为当并发清除的时候,用Compact整理内存的话,原来的用户线程使用的内存还怎么用呢?要保证用户线程能继续执行,前提的它运行的资源不受影响嘛。Mark Compact更适合“stop the world” 这种场景下使用
优缺点:
-
优点:低延迟+并发收集
-
缺点:产生内存碎片+对cpu资源敏感(在并发阶段,它虽然不会导致用户停顿,但是会因为占用了一部分线程而导致应用程序变慢,总吞吐量会降低)+无法处理浮动垃圾(在并发标记阶段产生新的垃圾对象,CMS将无法对这些垃圾对象进行标记,最终会导致这些新产生的垃圾对象没有被及时回收,从而只能在下一次执行GC时释放这些之前未被回收的内存空间。)
GC选择:
-
如果你想要最小化地使用内存和并行开销,请选Serial GC;
-
如果你想要最大化应用程序的吞吐量,请选Parallel GC;
-
如果你想要最小化GC的中断或停顿时间,请选CMs GC
JDK后续版本中CMS的变化
-
JDK9新特性:CMS被标记为deprecate了
-
JDK14新特性:删除CMS
(7) G1回收器
基本信息:
在延迟可控的情况下获得尽可能高的吞吐量
即可以收集新生代的垃圾也可以收集老年代垃圾,并行回收器、分区收集算法(分Region)
主要是适应不断扩大的内存和不断增加的处理器数量(引入G1原因)
G1跟踪各个Region里面的垃圾堆积的价值大小,优先回收价值最大的Region(侧重点在于回收垃圾最大量的region,所以叫做garbage first 垃圾优先)
G1优劣势:
优势:
-
兼具并行和并发:
-
并行:多个GC同时工作
-
并发:GC和应用程序交替工作
-
-
分区收集
-
空间整合:Region支架的清除是Copying算法,但是整体上的清除算法是Mark-Compact,没有产生碎片
-
可预测的停顿时间模型 soft real-time:能够指定在一个长度为M毫秒的时间片段内消耗在GC的时间不能超过N毫秒
缺点:
G1在为了GC产生的内存占用、程序运行时的额外执行负载都比CMS高。从经验上来说,在小内存应用上CMS的表现大概率会优于G1,而G1在大内存应用上则发挥其优势。平衡点在6-8GB之间。
G1参数设置
-
-XX:+UseG1GC:手动指定使用G1垃圾收集器执行内存回收任务
-
-XX:G1HeapRegionSize设置每个Region的大小。值是2的幂,范围是1MB到32MB之间,目标是根据最小的Java堆大小划分出约2048个区域。默认是堆内存的1/2000。
-
-XX:MaxGCPauseMillis 设置期望达到的最大Gc停顿时间指标(JVM会尽力实现,但不保证达到)。默认值是200ms
-
-XX:+ParallelGcThread 设置STW工作线程数的值。最多设置为8
-
-XX:ConcGCThreads 设置并发标记的线程数。将n设置为并行垃圾回收线程数(ParallelGcThreads)的1/4左右。
-
-XX:InitiatingHeapoccupancyPercent 设置触发并发Gc周期的Java堆占用率阈值。超过此值,就触发GC。默认值是45。
G1适用场景:
-
服务端应用 大内存 多处理器
-
低GC延迟
-
G1可能比CMS好的情况:
-
超过50%的Java堆被活动数据占用
-
GC停顿时间过长
-
对象分配频率变化很大
-
Region:
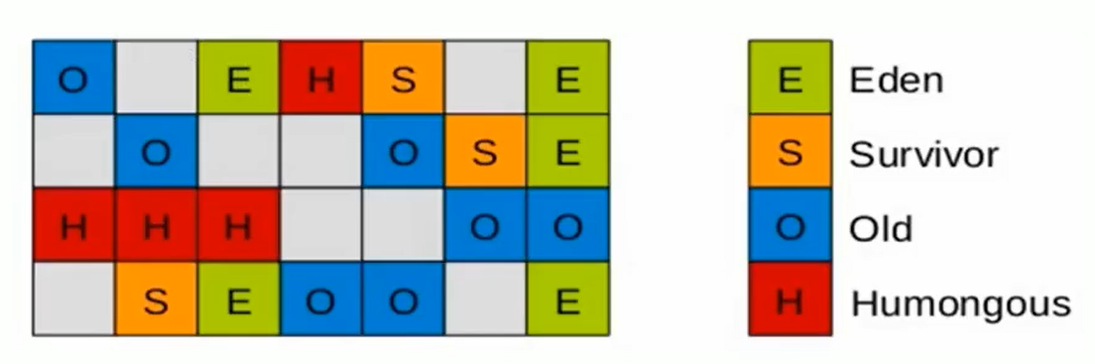
使用G1收集器时,将整个Java堆划分成约2048个大小相同的独立Region块,每个Region块大小根据堆空间的实际大小而定,整体被控制在1MB到32MB之间,且为2的N次幂,即1MB,2MB,4MB,8MB,16MB,32MB。可以通过XX:G1HeapRegionsize设定。所有的Region大小相同,且在JVM生命周期内不会被改变。
主要是E、S、O、H(H区主要是用于放置大对象)
H区存在的必要性:之前分配大对象是直接分配到老年代、但是如果是一个短期存在的大对象就会对GC有负面影响,所以开辟出一个H区放置大对象,如果一个H区装不下,就会寻找连续的H区存储
G1回收过程:
Remembered Set:
出现原因:一个对象可能会被不同区域引用,即一个Region中的对象可能会被任意Region中的对象引用,那判断这个对象是否存活,就需要进行全局扫描进行确定(那记忆集就是用来解决这个全局扫描的问题)
解决:给每个Region都分配一个Rset,每个Rset记录了当前Region中的对象的引用情况(每次就直接扫描Rset就可)
G1回收主要是三个环节:
-
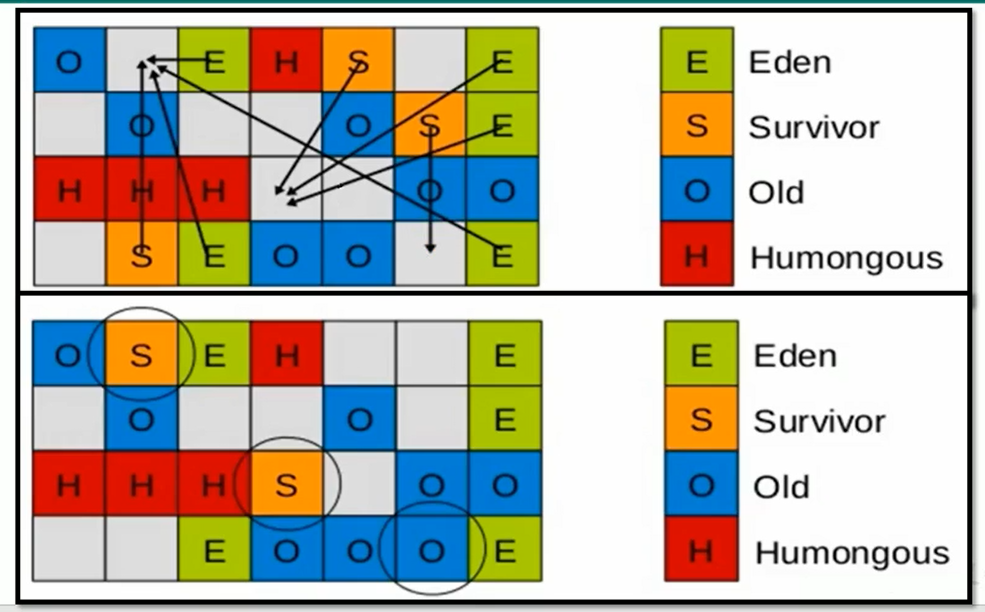
年轻代GC:
并行,STW,当Eden区用尽时开启YoungGC,主要是将E区的存活对象移至S区,S区的对象符合要求的移至老年代
-
老年代并发标记过程:
当堆内存使用达到一定值时(默认是45%),触发老年代 concurrent marking
1.初始标记阶段:标记从根节点直接可达的对象。这个阶段是STW的,并且会触发一次年轻代GC。
2.根区域扫描(Root Region Scanning):G1 Gc扫描survivor区直接可达的老年代区域对象,并标记被引用的对象。这一过程必须在youngGC之前完成。
3.并发标记(Concurrent Marking):在整个堆中进行并发标记(和应用程序并发执行),此过程可能被youngGC中断。在并发标记阶段,若发现区域对象中的所有对象都是垃圾,那这个区域会被立即回收。同时,并发标记过程中,会计算每个区域的对象活性(区域中存活对象的比例)。
4.再次标记(Remark):由于应用程序持续进行,需要修正上一次的标记结果。是STW的。G1中采用了比CMS更快的初始快照算法:snapshot-at-the-beginning(SATB)。
5.独占清理(cleanup,STW):计算各个区域的存活对象和GC回收比例,并进行排序,识别可以混合回收的区域。为下阶段做铺垫。是sTw的。这个阶段并不会实际上去做垃圾的收集
6.并发清理阶段:识别并清理完全空闲的区域。
-
混合回收:
越来越多的对象进入老年代后,为了避免堆内存被耗尽,触发一个混合的垃圾收集器,即Mixed GC,该算法并不是一个old GC,除了回收整个Young Region,还会回收一部分的old Region。这里需要注意:是一部分老年代,而不是全部老年代。可以选择哪些o1d Region进行收集,从而可以对垃圾回收的耗时时间进行控制。也要注意的是Mixed GC并不是Full GC。
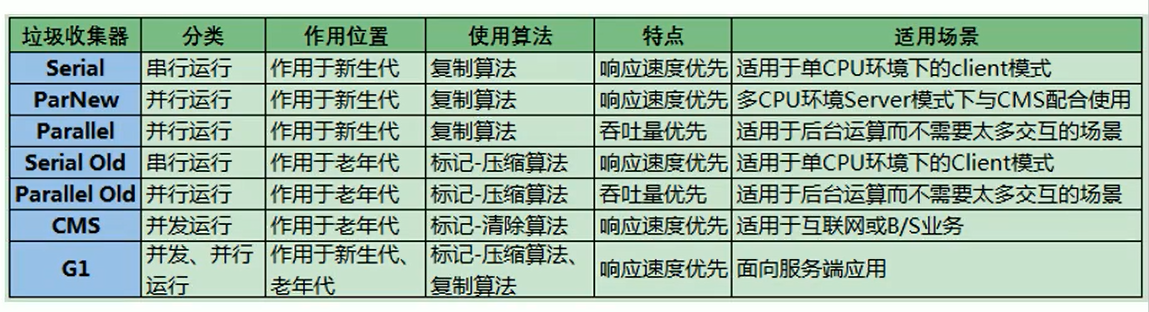
(8)垃圾回收器总结
新生代都是复制Copying算法;老年代除了CMS都是Mark-Compact















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









