






spark
Spark 运行模式
本章介绍在各种运行模式如何运行 Spark 应用.
首先需要下载 Spark
1.官网地址 http://spark.apache.org/
2.文档查看地址 https://spark.apache.org/docs/2.1.1/
3.下载地址 https://archive.apache.org/dist/spark/
目前最新版本为 2.4.4, 考虑到国内企业使用情况我们仍然选择 2.1.1 来学习. 不过2.x.x 的版本差别都不大.
Local 模式
Local 模式就是指的只在一台计算机上来运行 Spark.
通常用于测试的目的来使用 Local 模式, 实际的生产环境中不会使用 Local 模式.
解压 Spark 安装包
把安装包上传到/opt/software/下, 并解压到/opt/module/目录下
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module
然后复制刚刚解压得到的目录, 并命名为spark-local:
cp -r spark-2.1.1-bin-hadoop2.7 spark-local
运行官方求PI的案例
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
注意:
•如果你的shell是使用的zsh, 则需要把local[2]加上引号:‘local[2]’
说明:
•使用spark-submit来发布应用程序.
•语法:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
––master 指定 master 的地址,默认为local. 表示在本机运行.
––class 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
•–deploy-mode 是否发布你的驱动到 worker节点(cluster 模式) 或者作为一个本地客户端 (client 模式) (default: client)
•–conf: 任意的 Spark 配置属性, 格式key=value. 如果值包含空格,可以加引号"key=value"
•application-jar: 打包好的应用 jar,包含依赖. 这个 URL 在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar
•application-arguments: 传给main()方法的参数
•–executor-memory 1G 指定每个executor可用内存为1G
•–total-executor-cores 6 指定所有executor使用的cpu核数为6个
•–executor-cores 表示每个executor使用的 cpu 的核数
•关于 Master URL 的说明

备注: 也可以使用run-examples来运行
bin/run-example SparkPi 100
使用 Spark-shell
Spark-shell 是 Spark 给我们提供的交互式命令窗口(类似于 Scala 的 REPL)
本案例在 Spark-shell 中使用 Spark 来统计文件中各个单词的数量.
步骤1: 创建 2 个文本文件
mkdir input
cd input
touch 1.txt
touch 2.txt
分别在 1.txt 和 2.txt 内输入一些单词.
步骤2: 打开 Spark-shell
bin/spark-shell
步骤3: 查看进程和通过 web 查看应用程序运行情况
步骤4: 运行 wordcount 程序
sc.textFile("input/").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect
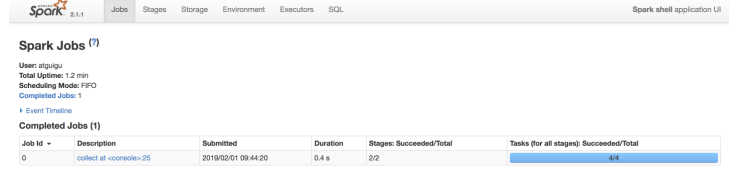
步骤5: 登录hadoop201:4040查看程序运行
提交流程
Spark 通用运行简易流程
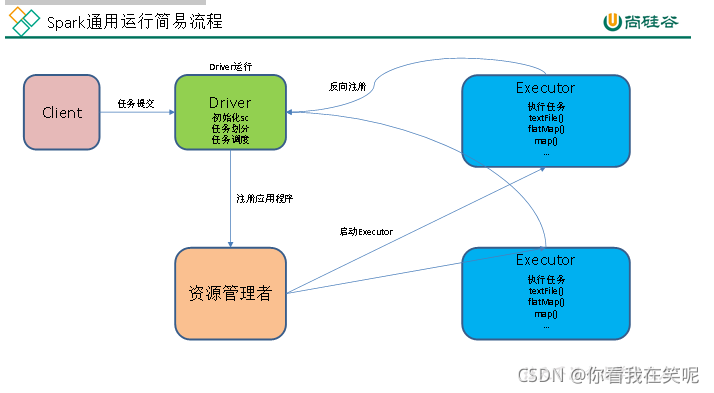
wordcount 数据流程分析:
 1.textFile(“input”):读取本地文件input文件夹数据;
1.textFile(“input”):读取本地文件input文件夹数据;
2.flatMap(.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
3.map((,1)):对每一个元素操作,将单词映射为元组;
4.reduceByKey(+):按照key将值进行聚合,相加;
5.collect:将数据收集到Driver端展示。
Spark 核心概念介绍
Master
Spark 特有资源调度系统的 Leader。掌管着整个集群的资源信息,类似于 Yarn 框架中的 ResourceManager,主要功能:
1.监听 Worker,看 Worker 是否正常工作;
2.Master 对 Worker、Application 等的管理(接收 Worker 的注册并管理所有的Worker,接收 Client 提交的 Application,调度等待的 Application 并向Worker 提交)。
Worker
Spark 特有资源调度系统的 Slave,有多个。每个 Slave 掌管着所在节点的资源信息,类似于 Yarn 框架中的 NodeManager,主要功能:
1.通过 RegisterWorker 注册到 Master;
2.定时发送心跳给 Master;
3.根据 Master 发送的 Application 配置进程环境,并启动 ExecutorBackend(执行 Task 所需的临时进程)
driver program(驱动程序)
每个 Spark 应用程序都包含一个驱动程序, 驱动程序负责把并行操作发布到集群上.
驱动程序包含 Spark 应用程序中的主函数, 定义了分布式数据集以应用在集群中.
在前面的wordcount案例集中, spark-shell 就是我们的驱动程序, 所以我们可以在其中键入我们任何想要的操作, 然后由他负责发布.
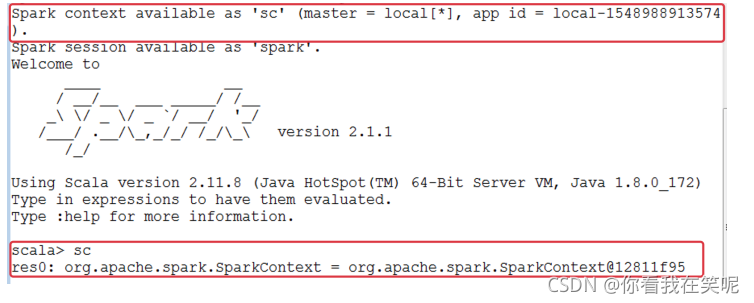
驱动程序通过SparkContext对象来访问 Spark, SparkContext对象相当于一个到 Spark 集群的连接.
在 spark-shell 中, 会自动创建一个SparkContext对象, 并把这个对象命名为sc.
executor(执行器)
SparkContext对象一旦成功连接到集群管理器, 就可以获取到集群中每个节点上的执行器(executor).
执行器是一个进程(进程名: ExecutorBackend, 运行在 Worker 节点上), 用来执行计算和为应用程序存储数据.
然后, Spark 会发送应用程序代码(比如:jar包)到每个执行器. 最后, SparkContext对象发送任务到执行器开始执行程序.

RDDs(Resilient Distributed Dataset) 弹性分布式数据集
一旦拥有了SparkContext对象, 就可以使用它来创建 RDD 了. 在前面的例子中, 我们调用sc.textFile(…)来创建了一个 RDD, 表示文件中的每一行文本. 我们可以对这些文本行运行各种各样的操作.
在第二部分的SparkCore中, 我们重点就是学习 RDD.
cluster managers(集群管理器)
为了在一个 Spark 集群上运行计算, SparkContext对象可以连接到几种集群管理器(Spark’s own standalone cluster manager, Mesos or YARN).
集群管理器负责跨应用程序分配资源.
专业术语列表


Standalone 模式
构建一个由 Master + Slave 构成的 Spark 集群,Spark 运行在集群中。
这个要和 Hadoop 中的 Standalone 区别开来. 这里的 Standalone 是指只用 Spark 来搭建一个集群, 不需要借助其他的框架.是相对于 Yarn 和 Mesos 来说的.
配置 Standalone 模式
步骤1: 复制 spark, 并命名为spark-standalone
cp -r spark-2.1.1-bin-hadoop2.7 spark-standalone
步骤2: 进入配置文件目录conf, 配置spark-evn.sh
cd conf/
cp spark-env.sh.template spark-env.sh
在spark-env.sh文件中配置如下内容:
SPARK_MASTER_HOST=hadoop201
SPARK_MASTER_PORT=7077 # 默认端口就是7077, 可以省略不配
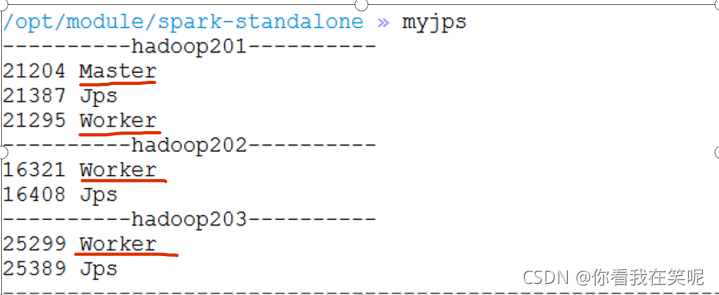
步骤3: 修改 slaves 文件, 添加 worker 节点
cp slaves.template slaves
在slaves文件中配置如下内容:
hadoop201
hadoop202
hadoop203
步骤4: 分发spark-standalone
步骤5: 启动 Spark 集群
sbin/start-all.sh
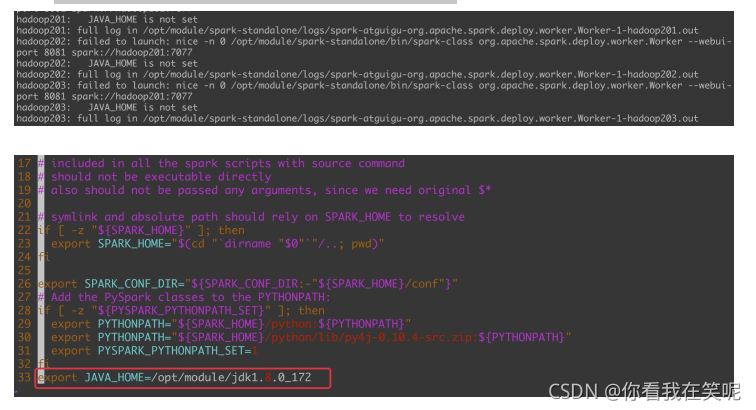
可能碰到的问题
•如果启动的时候报:JAVA_HOME is not set, 则在sbin/spark-config.sh中添加入JAVA_HOME变量即可. 不要忘记分发修改的文件
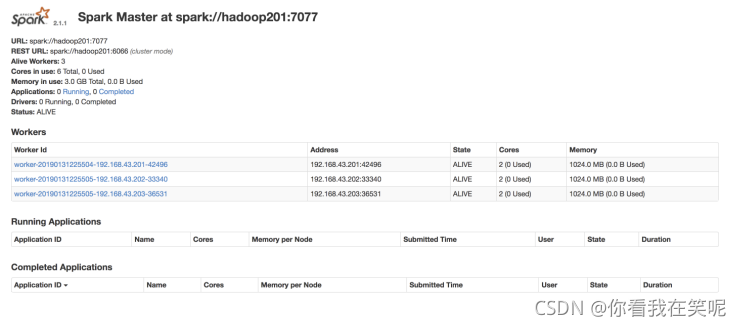
步骤6: 在网页中查看 Spark 集群情况
地址: http://hadoop201:8080
 ### 使用 Standalone 模式运行计算 PI 的程序
### 使用 Standalone 模式运行计算 PI 的程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop201:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
--executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









