






1.显著性检验的意义:
基本解释:
如果某两个样本平均数之间的差异达到了一定的限度,即达到了显著性水平,就可以认为这两个样本来自不同的总体,或者说,这两个样本各自所代表的总体之间有真正的差异;如果两个样本平均数之间的差异不显著,则可以认为,这两个样本平均数之间的差异是由抽样误差造成的,它们所来自的总体的平均数相等或就来自同一个总体。
2.计算检验工具:
使用前提:存在两个样本(n1,n2)均来自正态总体,且两总体方差已知。当n=n1+n2>30时使用z检验,n<30时,使用t检验。
1.z检验:
1)定义解释:‘’Z检验(Z Test)又叫U检验。由于实际问题中大多数随机变量服从或近似服从正态分布,U作为检验统计量与X的均值是等价的,且计算U的分位数或查相应的分布表比较方便。通过比较由样本观测值得到的U的观测值,可以判断数学期望的显著性,我们把这种利用服从标准正态分布统计量的检验方法称为U检验(U-test)‘’摘自百度百科。此处附百科对应链接有需要自行查看。
2)公式:
2.t检验:
1)定义解释:‘’t检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。 [1] t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。它与f检验、卡方检验并列。t检验是戈斯特为了观测酿酒质量而发明的,并于1908年在Biometrika上公布 [2] 。’摘自百度百科。此处附链接有需要自行查看。
2)公式:
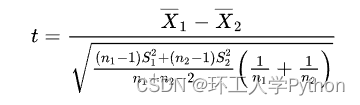
自由度n=n1+n2-2
3.例题及代码展示:
2-2:某地区对土壤砷含量背景值进行调查,120个样本分析结果如下表所示。
(1) 试求其算数均值、中位教、众数、极差、标准差、标准差变异系数、偏度和峰度系数:通过比较算术均值、位数和众数的关系,判断分布偏态:
(2) 编制频数分布表,通过频数分布表计算算术均值和中位数(3)绘制频数分布直方图,并添加拟合正态曲线。
1.09 0.57 1.57 1.79 2.24 0.82 2.30 1.22 1.90 1.02 2.02 1.64 0.99 1.89 1.20 0.61 2.36 0.82 2.06 0.93
0.87 1.42 2.36 1.95 1.40 1.25 0.77 2.20 2.10 1.72 0.73 1.20 2.37 0.68 1.19 0.61 0.82 0.77 1.00 0.54
1.71 1.74 1.15 2.13 1.93 0.83 0.78 2.08 0.76 2.12 2.33 2.12 0.89 1.75 0.86 1.01 1.43 2.22 1.28 2.42
2.27 2.16 1.47 0.96 2.20 0.59 2.36 1.00 2.03 0.74 0.82 0.94 2.06 0.84 1.59 1.41 0.50 0.69 1.37 1.60
1.46 0.50 0.70 1.07 2.24 2.09 2.20 1.17 1.33 2.38 1.26 0.86 1.31 0.51 2.31 0.91 1.35 0.68 1.01 2.23
1.34 0.91 0.77 1.94 1.62 1.35 0.50 1.10 2.28 1.45 0.50 1.19 1.78 2.08 1.30 1.26 2.03 1.64 2.20 1.94
1):
思路分析:
该题数据量较大,可采用r语言,或者python中的numpy库处理数据,依据公式计算,即可。
代码展示:
可横向滑动
import numpy as np
import pandas as pd
from scipy import stats
x = '1.09 0.57 1.57 1.79 2.24 0.82 2.30 1.22 1.90 1.02 2.02 1.64 0.99 1.89 1.20 0.61 2.36 0.82 2.06 0.93 0.87 1.42 2.36 ' \
'1.95 1.40 1.25 0.77 2.20 2.10 1.72 0.73 1.20 2.37 0.68 1.19 0.61 0.82 0.77 1.00 0.54 1.71 1.74 1.15 2.13 1.93 0.83 ' \
'0.78 2.08 0.76 2.12 2.33 2.12 0.89 1.75 0.86 1.01 1.43 2.22 1.28 2.42 2.27 2.16 1.47 0.96 2.20 0.59 2.36 1.00 2.03 ' \
'0.74 0.82 0.94 2.06 0.84 1.59 1.41 0.50 0.69 1.37 1.60 1.46 0.50 0.70 1.07 2.24 2.09 2.20 1.17 1.33 2.38 1.26 0.86 ' \
'1.31 0.51 2.31 0.91 1.35 0.68 1.01 2.23 1.34 0.91 0.77 1.94 1.62 1.35 0.50 1.10 2.28 1.45 0.50 1.19 1.78 2.08 1.30 ' \
'1.26 2.03 1.64 2.20 1.94 '.split()
d = np.array(x).astype(np.float64)#使用np录入数据
x1 = d.mean()#求平均值
s1 = np.sqrt(sum((d - d.mean()) ** 2) / (len(d) - 1))#np库计算的标准差与公式计算标准差有差异
s11 = d.std()#np库计算标准差的函数
n1 = len(d)样本数量
ss1 = s1 * s1#方差
print('该组数据的平均数为', d.mean(), '标准差为:', d.std(), '自由度为:', len(d) - 1, '样本量为:', len(d))
p = pd.Series(d).skew() # 求偏态 pandas库中有直接的计算函数
k = pd.Series(d).kurt() # 求峰度注意事项:
1.np库计算的标准差的函数与公式计算标准差有差异 原因未知 2.numpy,pandas,为非官方库,如需使用请百度python如何安装库,或者直接win+r打开cmd使用代码:pip install i ,i为库名
结果展示:
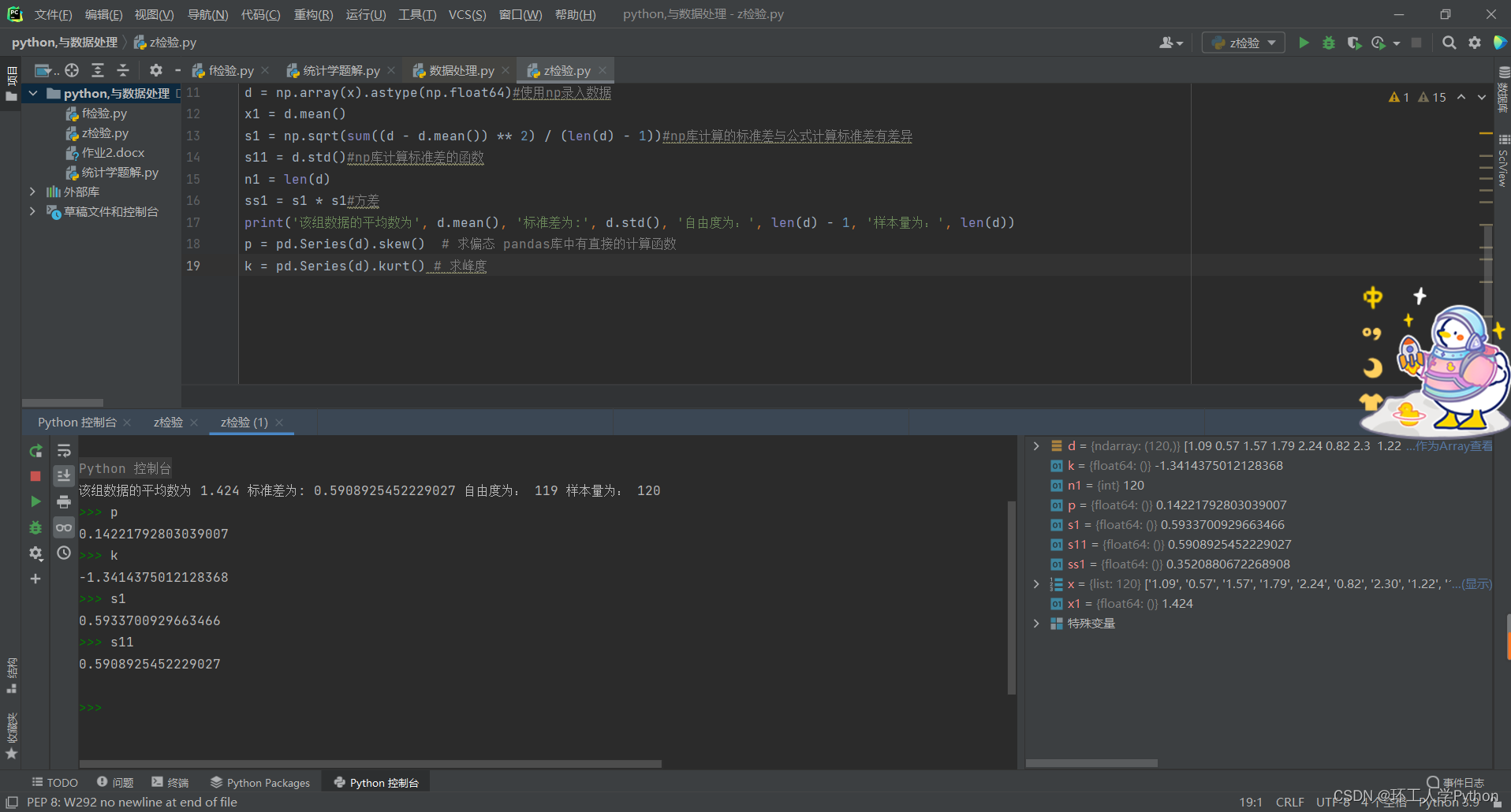
该组数据的平均数为 1.424 标准差为: 0.5908925452229027 自由度为: 119 样本量为: 120
p
0.14221792803039007
k
-1.3414375012128368
s1
0.5933700929663466
s11
0.5908925452229027
第一问依据相关数据进行解答即可。
2)
思路分析:
据我所知目前没有库中有代码可以直接展示相关数据的频率直方图,故我们根据频率直方图的基本定义和元素确定方法使用matplotlib库进行画图操作。
频率直方图:‘’频率直方图(frequency histogram)亦称频率分布直方图。统计学中表示频率分布的图形。在直角坐标系中,用横轴表示随机变量的取值,横轴上的每个小区间对应一个组的组距,作为小矩形的底边;纵轴表示频率与组距的比值,并用它作小矩形的高,以这种小矩形构成的一组图称为频率直方图。‘’摘自百度百科。
具体步骤:
1.求极差:
极差=最大值-最小值
该题中极差=1.92
2.定组段数:
一般取8-15个为合适,多数情况下取10个:组段数太多,计算繁琐,过少则误差较大。
该题我们取10个
3.定组距:
相邻两段下限值之差为组距。各组段组距可相等,也可不相等。
定组距时:组距等于极差/组段数
该题此值取0.192,也可选择合适的数据
4.定组段:
即定各组数据的上下限。离散型变量值可以一列举,因此相邻组的上下限可以不同,这种分组称为异限分组:连续型变量不能还列举, 此时用同一值表示相邻组的上下限,这种分组称为同限分组。同限分组时,与组的下限相同的值,规定划归该组,称之为“上限不在内"原则。
该题我们在中位数左右两侧各取5个组段:0--0.385,0.385--0.577,......,2.113,--2.305,2.305--无穷大,共十个组段
代码展示:
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
os.chdir("D:\\桌面\\python学习资料\\图表输出") # 指定图表存储位置括号内写对应路径即可。
plt.rcParams['font.sans-serif'] = ['SimHei'] # 修改数据使matplotlib对中文更加兼容。
plt.rcParams['axes.unicode_minus'] = False # 同上。
x = '1.09 0.57 1.57 1.79 2.24 0.82 2.30 1.22 1.90 1.02 2.02 1.64 0.99 1.89 1.20 0.61 2.36 0.82 2.06 0.93 0.87 1.42 2.36 ' \
'1.95 1.40 1.25 0.77 2.20 2.10 1.72 0.73 1.20 2.37 0.68 1.19 0.61 0.82 0.77 1.00 0.54 1.71 1.74 1.15 2.13 1.93 0.83 ' \
'0.78 2.08 0.76 2.12 2.33 2.12 0.89 1.75 0.86 1.01 1.43 2.22 1.28 2.42 2.27 2.16 1.47 0.96 2.20 0.59 2.36 1.00 2.03 ' \
'0.74 0.82 0.94 2.06 0.84 1.59 1.41 0.50 0.69 1.37 1.60 1.46 0.50 0.70 1.07 2.24 2.09 2.20 1.17 1.33 2.38 1.26 0.86 ' \
'1.31 0.51 2.31 0.91 1.35 0.68 1.01 2.23 1.34 0.91 0.77 1.94 1.62 1.35 0.50 1.10 2.28 1.45 0.50 1.19 1.78 2.08 1.30 ' \
'1.26 2.03 1.64 2.20 1.94 '.split()
A = np.array(x).astype(np.float64) # 使用np录入数据
n = pd.cut(A, bins=[0.385 + 0.192 * x for x in range(13) ])
print(n.value_counts()) # 找到不同区间的分布频数数据
X = n.value_counts().values
labels = []
for i in range(13):
t = 0.385 + 0.192 * i
te = format(t, '.3f')
if i < 1:
s = (str(i) + '-' + str(te))
pass
elif i >= 1:
s = format((0.385 + 0.192 * (i - 1)), '.3f') + '-' + te
labels.append(s)
fig = plt.figure()
df = pd.DataFrame(X, index=labels)
df.plot(kind='bar', legend=False)
plt.xticks(rotation=0)
plt.ylabel('频数')
plt.xlabel('区间')
plt.show()
fig.savefig("结果.png")
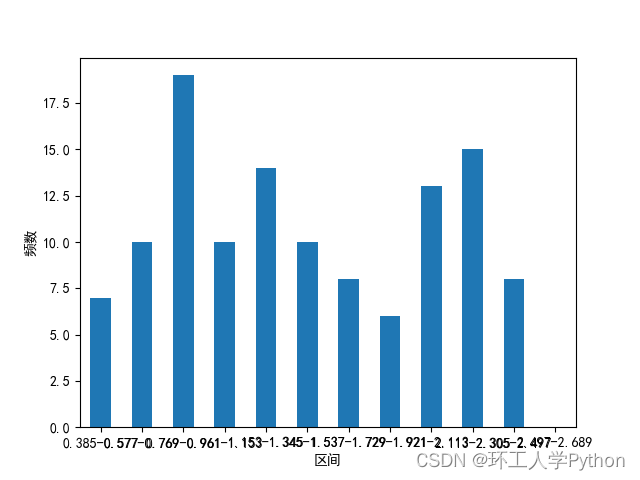
(0.385, 0.577] 7
(0.577, 0.769] 10
(0.769, 0.961] 19
(0.961, 1.153] 10
(1.153, 1.345] 14
(1.345, 1.537] 10
(1.537, 1.729] 8
(1.729, 1.921] 6
(1.921, 2.113] 13
(2.113, 2.305] 15
(2.305, 2.497] 8
(2.497, 2.689] 0余下还有其他部分和细节后续有空会重新编辑和详细说明,但今日时间有限暂时不更















 4241
4241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









