






目录
1.f检验是什么:
‘F检验(F-test),最常用的别名叫做联合假设检验(英语:joint hypotheses test),此外也称方差比率检验、方差齐性检验。它是一种在零假设(null hypothesis, H0)之下,统计值服从F-分布的检验。其通常是用来分析用了超过一个参数的统计模型,以判断该模型中的全部或一部分参数是否适合用来估计母体。
F检验这名称是由美国数学家兼统计学家George W. Snedecor命名,为了纪念英国统计学家兼生物学家罗纳德·费雪(Ronald Aylmer Fisher)。Fisher在1920年代发明了这个检验和F分配,最初叫做方差比率(Variance Ratio)。’摘自百度百科
2.f检验用来做什么?
通常的F检验例子包括:
-
假设一个回归模型很好地符合其数据集要求,检验多元线性回归模型中被解释变量与解释变量之间线性关系在总体上是否显著。
3.f检验的计算公式:
f检验又称方差比率检验,故需要用到的统计量是方差:将两组或两组以上的方差进行求比如:
方差为样本标准偏差的平方,即:
两组数据就能得到两个值
F1=
然后计算的F值与查表得到的F表值比较,如果
F < F表 表明两组数据没有显著差异;
F ≥ F表 表明两组数据存在显著差异。
4.相关例题及代码展示:
例题:
2.8:某环境监测站对某地水稻田、小麦田和莱园田土壤中氰含量(mg/kg) 进行测定,结果如下表所示。试比较三种土壤含氰量有无显著差异(先方差分析,如有差异显著性,则进行多重比较)。
| 水稻田 | 小麦田 | 菜园田 |
| 对应数据: | ||
| 0.815 0.642 0.743 0.513 0.521 0.241 0.658 0.648 0.368 | 0.975 0.549 0.639 0.570 0.456 0.599 0.916 0.508 0.781 | 0.825 0.464 0.544 0.533 0.553 0.527 0.806 0.633 0.726 |
思路分析:
n1=n2=n3=9,总实验次数为27次
有两个变量:氰含量和田的种类。
f检验中自由度公式:n=n1+n2-2-1
使用f检验或者多次t检验解答
解答过程:
(1):代码展示
import numpy as np
from scipy import stats
import statsmodels.stats.weightstats as sw
A = '0.815 0.642 0.743 0.513 0.521 0.241 0.658 0.648 0.368'.split()
B = '0.957 0.549 0.639 0.570 0.456 0.599 0.916 0.508 0.781'.split()
C = '0.825 0.464 0.544 0.553 0.553 0.527 0.806 0.633 0.726'.split()
e = np.array(B).astype(np.float64)
x2 = e.mean()#求平均值
s2 = np.sqrt(sum((e - e.mean()) ** 2) / (len(e) - 1))#手动求标准差
ss2 = s2 * s2#方差
n2 = len(e)#数据数量
d = np.array(A).astype(np.float64)
x1 = d.mean()
s1 = np.sqrt(sum((d - d.mean()) ** 2) / (len(d) - 1))
n1 = len(d)
ss1 = s1 * s1
g = np.array(C).astype(np.float64)
x3 = g.mean()
s3 = np.sqrt(sum((g - g.mean()) ** 2) / (len(g) - 1))
n3 = len(g)
ss3 = s3 ** 2
F1=ss1/ss2#求f值
F2=ss2/ss3
F3=ss1/ss3使用的pycharm科学模式,在输入端口输入变量名称就得到计算值
如图: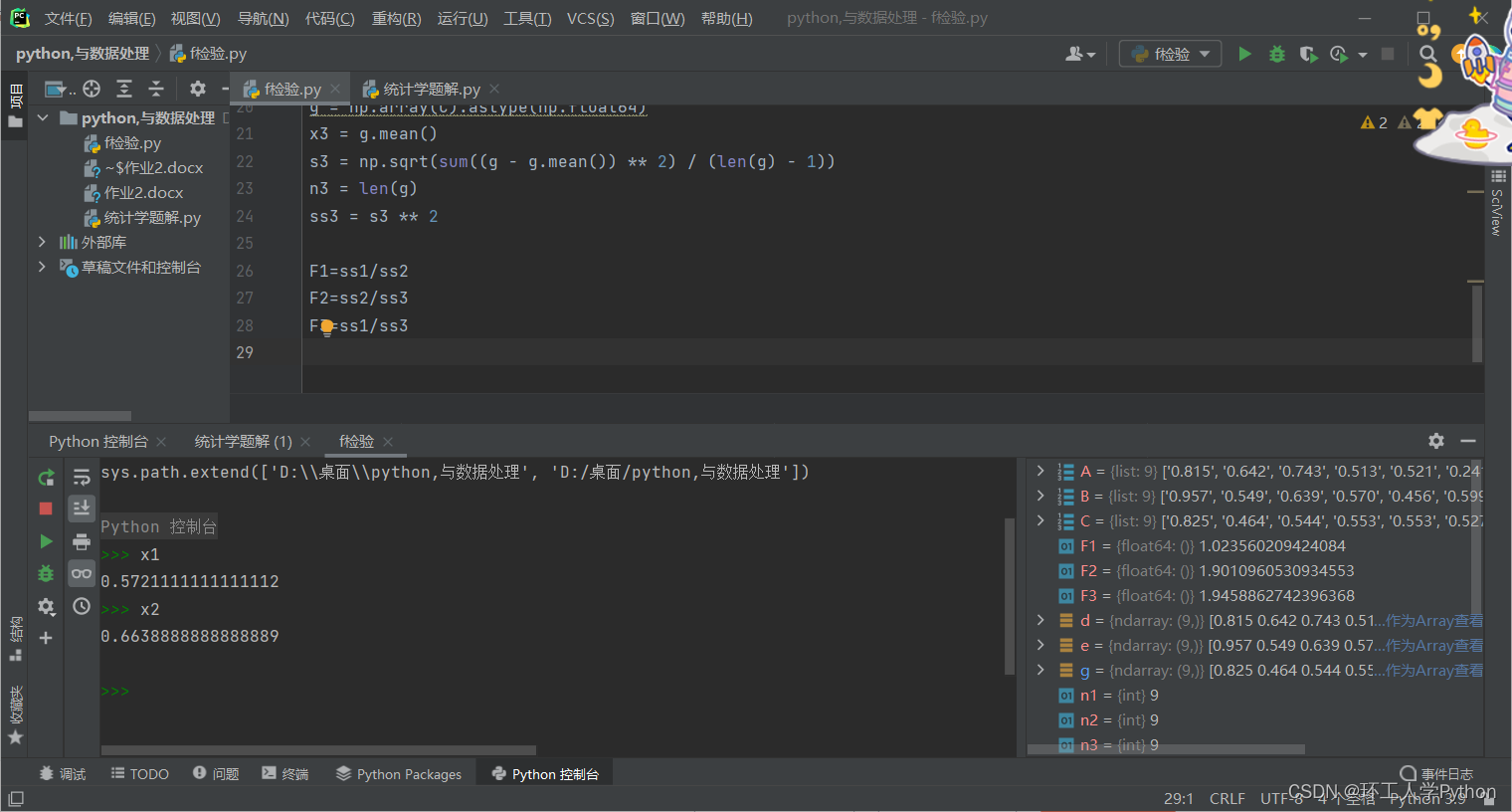
(2)解题过程:
1.计算对应的统计量
每块田数据对应的方差
2.建立假设
H0:u1=u2=u3(u1,u2,u3为对应平均值)该假设的意思为三种田的氰含量无显著性差异。
H1:u1=!u2!u3(=!为不等号)(备择假设)有显著性差异。
3.确定标准值查f分布表(文尾附):
我们在进行比较时:是两两比较,故自由度为n:n1+n2-2-1=15,自变量为2
查f分布表f(15,2)有,F=3.682
4.将计算f值与标准值比较:
F1<F F2<F F3<F
该结果表示三组数据无显著差异,所以拒绝假设H1,接受H0,对本题予以解答。
最后附图: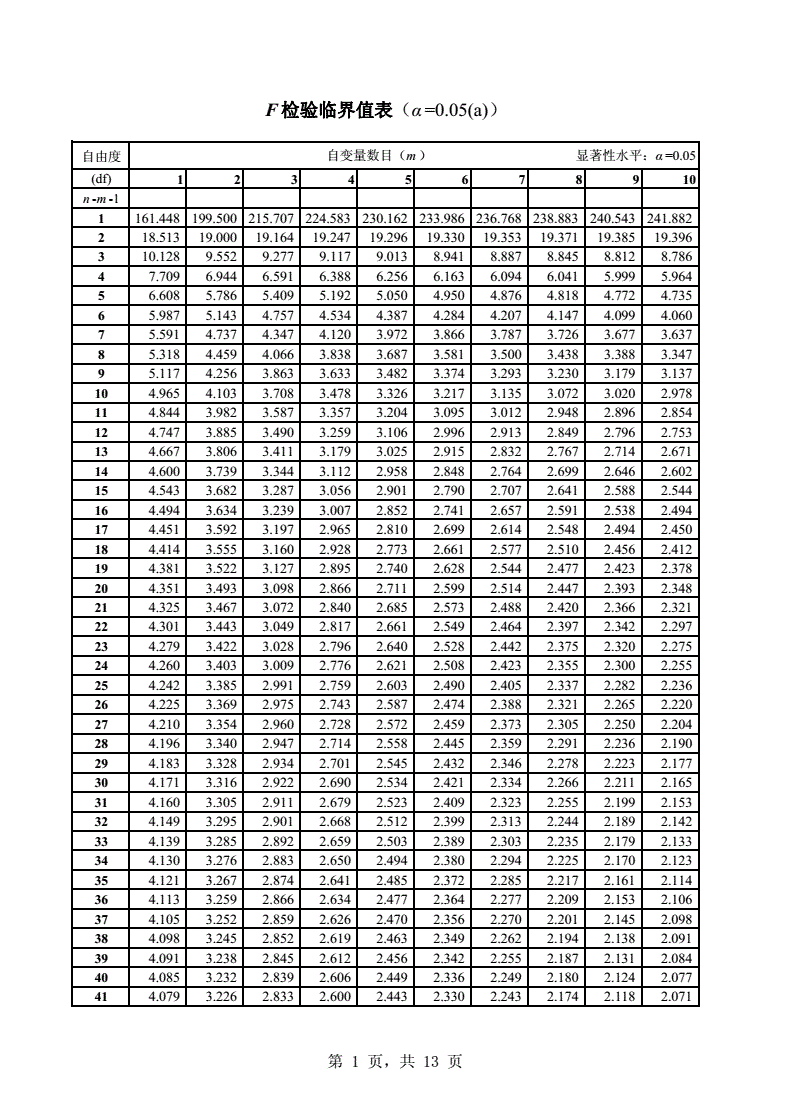















 4168
4168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









