






示例表:
① 员工表
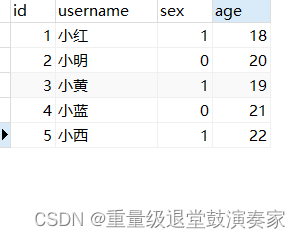
②部门表

1.建表语句
create table table_name(
id int auto_increment primary key,
name vachar(20),
...
);
2.修改表结构语句
修改表中一列的属性:alart table table_name modify column_name char;
3.左外连接
select t1.c1, t1.c2, t1.c3, t2.c1
from t1 left join t2
on t1.c1 = t2.c1;
如果左表t1的行基于条件与表t2匹配时,将该行包含在结果中
如果不匹配时,则仍将t1中的行与右表中的"假行"组合,对于select中的对应列设置为null
select t1.username, t1.sex, t1.age, t2.deptname from test1 t1 left join test2 t2 on t1.username = t2.username

4.count、sum函数
count、sum函数作为一列的返回值,仅返回一条记录,若返回列数不仅函数统计时,取其它列数的第一条作为返回值。多配合group by一起使用
5. group by
先来看下表1,表名为test: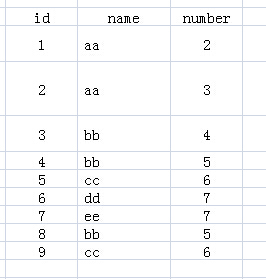
执行如下SQL语句:
SELECT name FROM test GROUP BY name
你应该很容易知道运行的结果,没错,就是下表2:
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面,如下图所示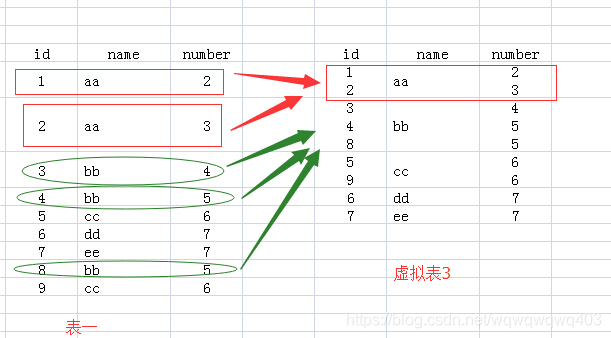
3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,那么id跟number会返回各自单元格中的排序第一个值。id列会返回1,3,5
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如count(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下:
5)group by 多个字段该怎么理解呢:如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组,如下图所示:
6)接下来就可以配合select和聚合函数进行操作了。如执行select name,sum(id) from test group by name,number,结果如下图: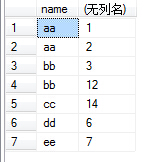















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









