







写在前面的话
了解我的朋友应该都知道,我之前一直负责的是云原生网络相关的工作,对容器化,k8s 基本上属于有一定的知识储备。所以本系列的文章主要是一个云原生从业人员的角度去切入到机器学习和大数据方面,对应有一定k8s知识储备的朋友来说可能比较友好,但是对于一些炼丹师朋友来说可能是一个全新的角度,如果需要一些云原生的基础知识的话,也可以看我云原生基础的专栏。
本文只是一个基础的概况和本专栏的介绍,后续专栏内容会从启动自己的一个简单的机器学习任务开始,到k8s如何支持,在超大规模机器学习集群中如何加速,如何在超大规模的计算集群中提高GPU 的利用率等等。
什么是机器学习
机器学习是AI 的一种应用领域,讲人话就是通过算法和统计模型让计算机从大量的数据中学习,关键思想是利用数据来训练模型,,让模型能够自动发现数据中的模式并作出预测或决策。
tensorflow
经常炼丹的炼丹师们肯定很了解了,谷歌开源的一个机器学习框架,可以构建各种机器学习的模型,还支持分布式训练
PyTorch
facebook 开源的机器学习框架,对于学习者来说更加友好灵活,py代码可读性更强,同时也支持分布式训练
机器学习的大模型训练
从chatgpt开始,大模型训练就开始风就开始吹遍整个炼丹圈,在大家还在讨论未来AI 会给我们生活带来什么样的变化的时候各个大厂已经开始布局自己的大模型训练
和小模型训练相比,大模型对大规模的分布式并行训练有更强的需求
首先是模型本身非常之大,以至于单机单卡甚至单机多卡无法满足,我们不得不把单个模型拆分到多个GPU上存储
其次大模型训练的计算量更大,数据源更大,对算力要求更高我们除了上更高算力的GPU 之外也需要为大模型训练搭建大规模的训练集群
而因为一些政治原因,导致一些高端GPU (比如阉割过算力的A800和H800)国内无法买到,不但没有让国内大模型训练降温,反而催化一批国产GPU的发展,身为炼丹师的我们在现在或者未来都会有明显的接触。
分布式训练策略
分布式训练有多种,我在这里只列出一些常用的三种
-
数据并行,在数据并行中每个GPU 都要相同的模型副本,数据集拆分到多份给不同GPU进行训练。每一轮迭代训练完成之后,各个GPU 需要把各自计算梯度进行全局同步,然后各个GPU计算出下一轮迭代用到的参数。在数据并行中,网络上对各个GPU 上的梯度做一次Allreduce ,通信数据量和模型参数规模成正比,对网络要求比较高。
-
流水线并行 神经网络模型通常都是多层神经元的组合,包括大模型底层的 Transformer 模型也是这样。我们可以把模型按照神经元的层次进行拆分,不同层放到不同的 GPU 上去。这种并行策略需要不同 GPU 之间做层间点到点数据传递,传输的内容包括正向计算里的激活值和反向计算里的梯度值。这种通信在一个迭代里至少会发生几十次,但通信量一般不大,对网络的性能要求相对较低。
-
第三种并行策略就是张量并行,也就是联合多个 GPU 同时做一个张量计算,(比如我们大学学到的线性代数,对两个大矩阵的乘法,可以拆分成多个小矩阵进行相乘,在张量并行策略中,我们可以把很大的矩阵拆分成若干小矩阵放到多个GPU中进行计算)。但是这种并行策略中很明显需要频繁的多个GPU 之间做Allreduce,对网络带宽要求是最大的
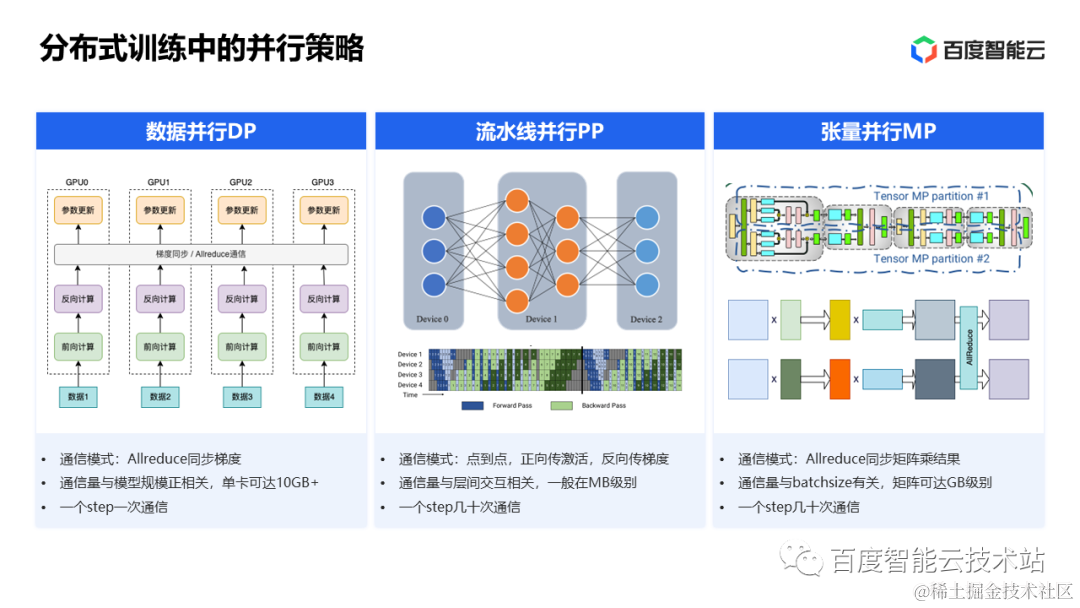
三种策略各有特色,在实际的大规模训练集群中其实是三种策略同时存在的
在单机多卡的机器中我们可以采用张量并行,充分使用NVlink(nvlink 可以理解成是一个高速的PCIe总线,对比PCIe 总线而言nvlink 在各个卡间做通信速度更快带宽更大)的高带宽
当模型过大,单机放不下我们可以采用流水线并行
为了加速我在使用多路数据并行
每路内部都是张量并行和流水线并行

k8s 解决分布式训练
k8s 之于大模型分布式训练,可以说有着天然的承接优势,多机多卡的训练集群完全可以通过K8S 搭建和维护,训练任务可以使用job 进行分发,多种调度策略让有限的GPU 资源可以更高效的利用。kubernetes 自带的服务发现可以简化分布式训练过程中的配置问题
kubeflow
Kubeflow是在k8s平台之上针对机器学习的开发、训练、优化、部署、管理的工具集合,内部集成的方式融合机器学习中的很多领域的开源项目,比如Jupyter、tfserving、Katib、Fairing、Argo等。可以针对机器学习的不同阶段:数据预处理、模型训练、模型预测、服务管理等进行管理。只要安装了k8s,可以在本地、机房、云环境中部署。
volcano
Volcano是CNCF 下首个也是唯一的基于Kubernetes的容器批量计算平台,主要用于高性能计算场景。它提供了Kubernetes目前缺 少的一套机制,这些机制通常是机器学习大数据应用、科学计算、特效渲染等多种高性能工作负载所需的。作为一个通用批处理平台,Volcano与几乎所有的主流计算框 架无缝对接,如Spark 、TensorFlow 、PyTorch 、 Flink 、Argo 、MindSpore 、 PaddlePaddle 等。它还提供了包括基于各种主流架构的CPU、GPU在内的异构设备混合调度能力。Volcano的设计 理念建立在15年来多种系统和平台大规模运行各种高性能工作负载的使用经验之上,并结合来自开源社区的最佳思想和实践。
后续介绍
本文作为前言介绍部分,不会对内容进行更深入的分析,后面会推出如下内容,或者大家有想要了解的内容欢迎向我分享
炼丹师的优雅内功一:tensorflow on kubernetes
炼丹师的优雅内功二:PyTorch on kubernetes
炼丹师的优雅内功三:kubeflow 如何承接机器学习任务
炼丹师的优雅内功四:volcano 批量处理容器计算业务
炼丹师的优雅内功五:大规模计算集群的秘密RDMA网络,IB网络和RoCe的纠葛















 2150
2150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









