







文章目录
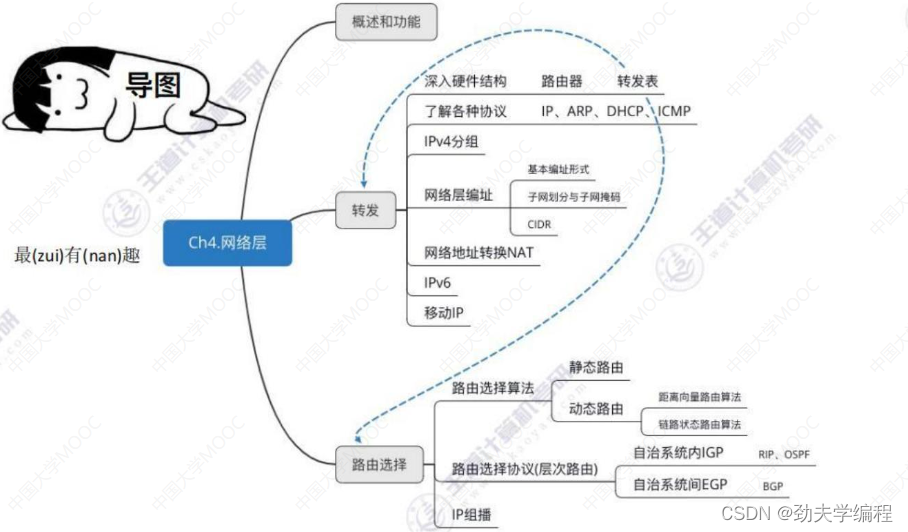
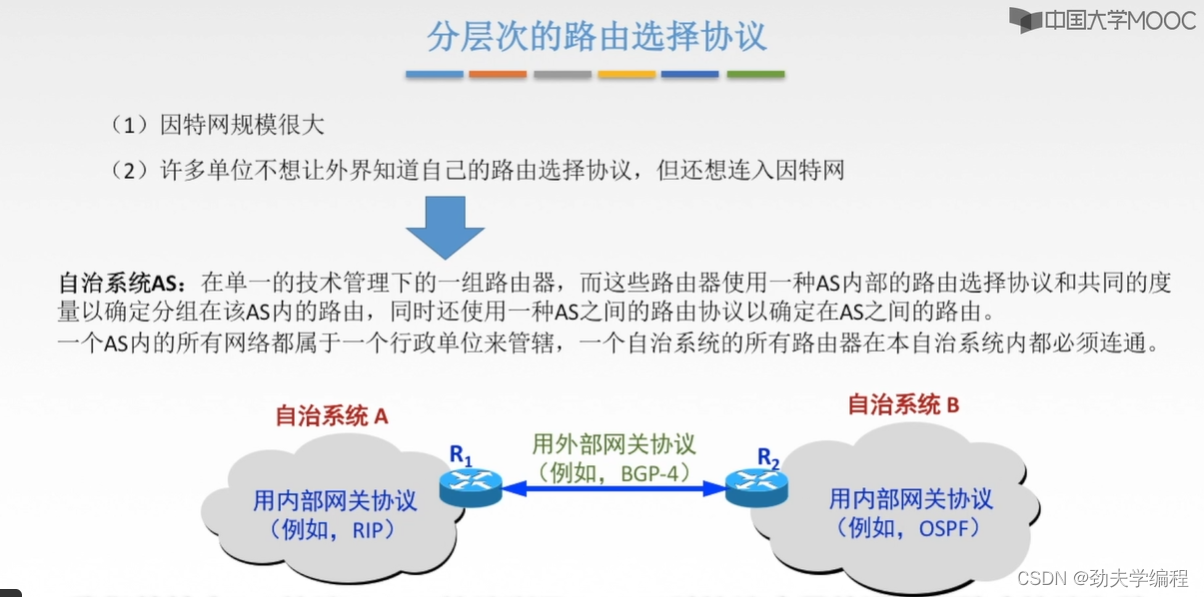
一、网络功能概述
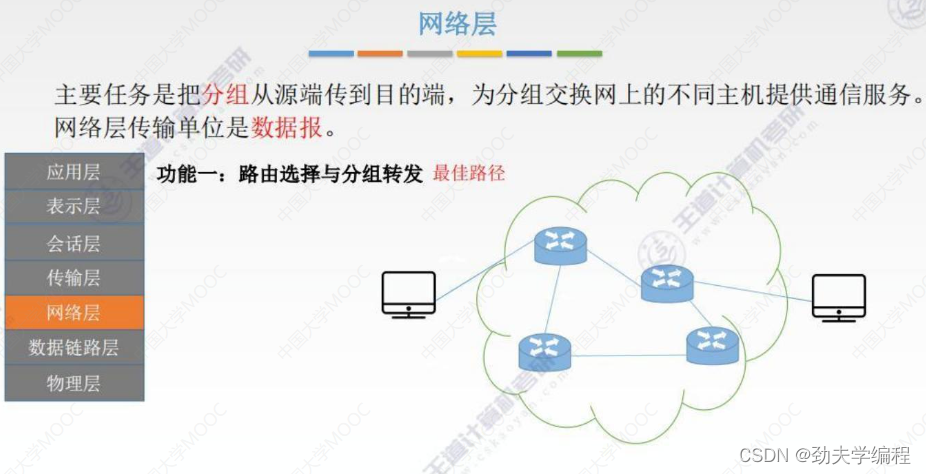
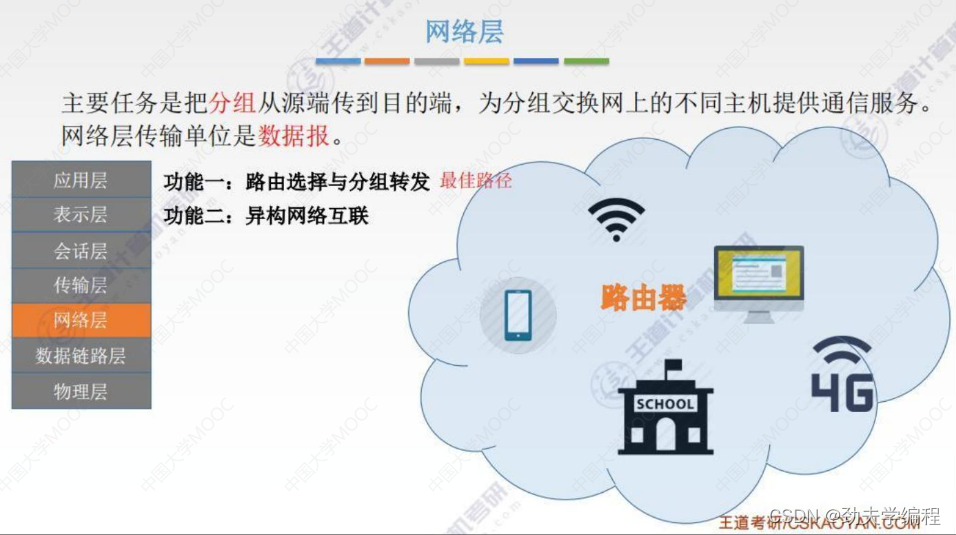

二、SDN基本概念
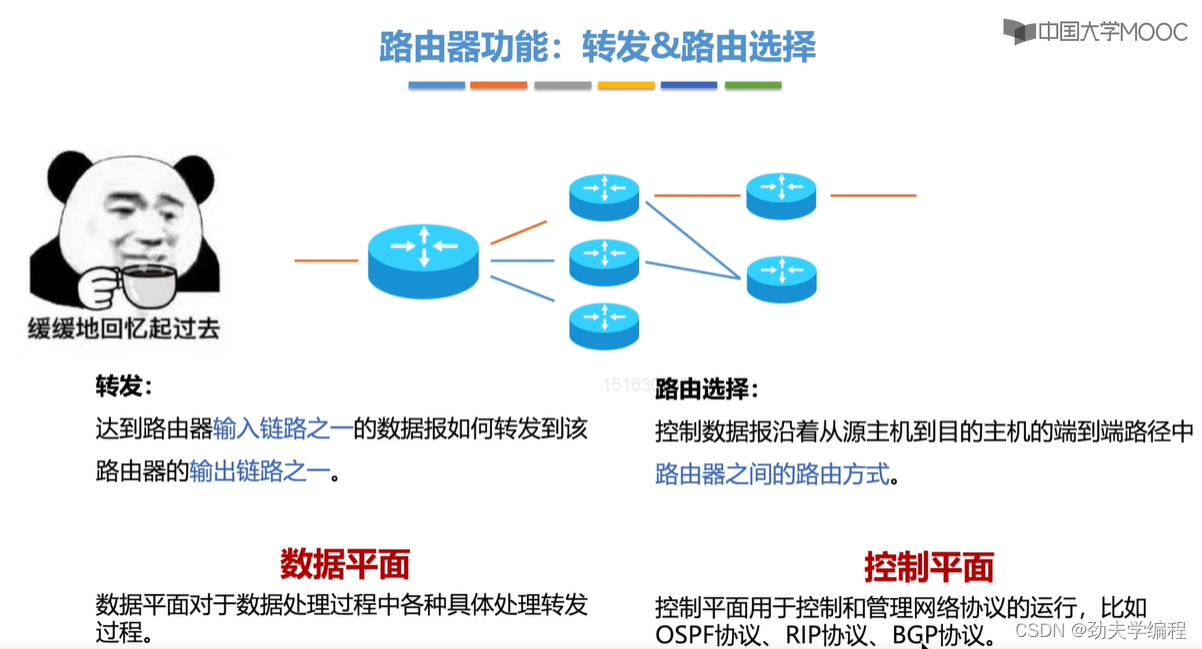




三、路由算法与路由协议概述



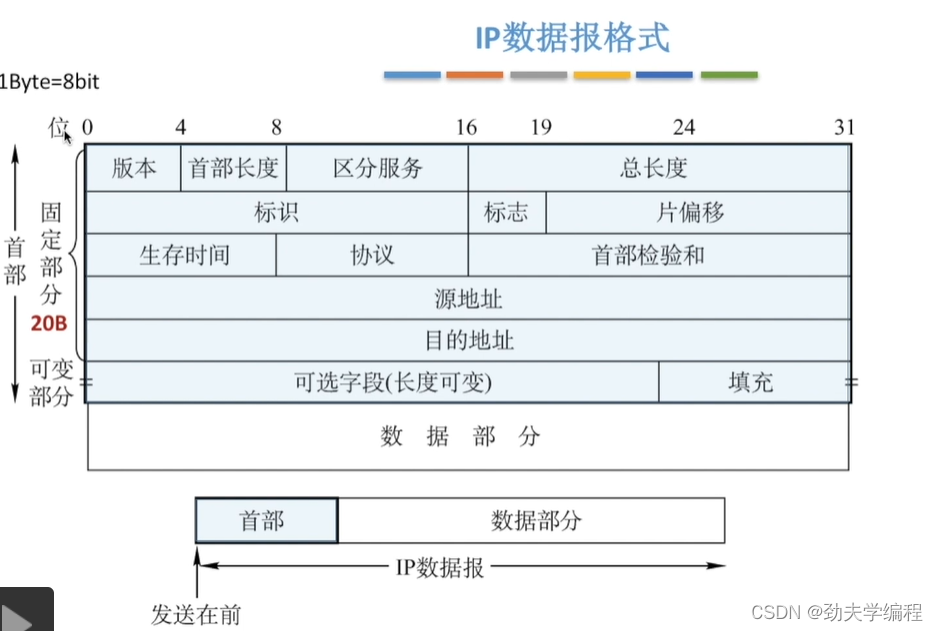
四、IP数据报格式
对于IP数据报,分成了两部分,一个是首部和数据部分。
数据部分就是运输层的传送单元,有TCP段也有UDP段。这个首部也可以称之为IP数据报的头部,需要注意的是,在网络层这一章的IP数据报和分组不用做太细的区分。但我们要清楚它们仍有一定的区别,对于一个IP数据报如果过大,我们会给它进行一个分片,分片下来的小单位就是网络层的传输单元“分组”
我们发送数据的时候是从首部开始,然后逐个比特再去发送。这个首部我们又给它细分成了两个部分,第一部分是固定部分,第二部分叫可变部分。固定部分必须要有,可变部分不一定需要。

下面我们看一下具体的首部有哪些字段。
固定部分长度固定是20字节,1字节=8比特(1比特就是1位),所以我们这里用位来对首部进行划分。
版本:
版本字段是0-4,也就是版本字段占4位。它是指使用ip协议版本的是ipv4还是ipv6。
首部长度:
首部长度占4位,也就是0000-1111,可以表示16个数,而首部长度的单位是4字节,也就是说如果首部长度的数据是1111,那么就是15*4=60字节的首部长度。
首部长度可以是0000吗?这个是不行的,因为固定部分是20字节,我们用20字节除4字节单位长度,20/4=5,所以首部长度的数据最少要是5开始,对应二进制是0101
填充:
而当我们ip分组的首部长度不是4字节的整数倍时,就没办法用首部长度表示了,所以我们会有这样一个填充字段。
填充字段的意义就是把整个首部填充成4字节的整数倍,这样首部长度才能对应的表示出来
这样,后面的数据部分就会从4字节的整数倍开始。
我们常用的首部是20字节,也就是只有固定部分,没有可变部分,首部长度的比特序列也就是0101,也就是5
区分服务:
区分服务是只期望获得哪种类型的服务,比如我现在手里有一个数据报,想把它优先发出去,那我们就可以用区分服务来强调优先级。实际应用中很少用区分服务。
总长度:
是指首部长度+数据部分,也就是整个ip数据报的长度。这里需要和首部长度做一个区分。
首部长度的单位是1B
总长度占16位,也就是可以用16位二进制数表示,那么总长度最大值216-1,也就是65535,再乘以1字节(一个单位),也就是65535B,这是ip数据报长度的上限。但是实际生活中是不会达到这个上限的,因为如果长度过大我们还需要对它进行分片来满足这个数据链路层的一个MTU(最大数据传输单元的要求)
标识、标志、片偏移
后面讲ip数据报分片着重讲,这里先跳过
生存时间
生存时间(TTL),time to live,它表示ip分组的保质期,也就是ip分组在网络中的一个寿命,它每经过一个路由器,它的生存时间就会减一。如果最后这个生存时间变成0了,这个数据报就会丢弃掉。
至于为什么要设置生存时间,是为了防止无法交付的数据报无限制的在网络中兜圈子。
举个例子:
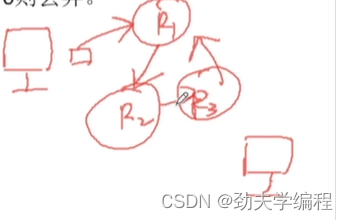
我们某个主机要发送一个分组,而发送过程要经过大大小小的网络再到达目的主机。
假设现在3个路由器R1 R2 R3
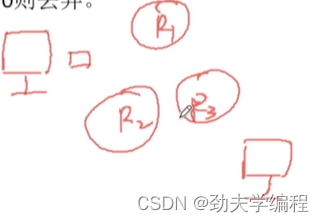
分组首先从R1转发到R2,再到R3,后面可能又到R1了,这样其实就很消耗网络资源了。
协议:
协议是指数据部分所用的协议,也就是我们运输层传下来的报文段是什么样的协议。
具体来说有如下协议,它们分别对应一定的字段值。我们着重记忆TCP和UDP两协议

我们简单记忆一下:
TCP是面向连接的,所以它非常”6“
UDP是不面向连接的,对于不面向连接的传输,数据比较容易被遗弃。因为如果不建立连接,那么这个链路是不可靠的。因此这个数据经常会发生丢包的现象,也就是被遗弃掉了。遗弃就是”17“。
首部检验和:
它占的位数是16位,顾名思义就是检验首部的字段,为什么用”和“呢,这个是因为检验首部使用的方法是二进制求和。
需要注意,首部检验和只检验首部,它不检验数据部分。之所以要有首部检验和,是因为我们在数据传输过程中,数据报每经过一个路由器,路由器都需要重新计算一下首部检验和。因为一些字段,比如生存时间、标志、片偏移都可能发生变化。所以我们要通过检验和来检验一些发生变化后数据报有没有出错。如果出错就把数据报丢弃掉,如果没错就继续传输。
源地址、目的地址:
它们的长度都是32位,也就是我们现在常用的ipv4,ipv4对应的ip地址长度就是32位。
可选字段:
可选字段长度是可变的,它的范围是0-40B,是用来支持排错、测量的。
填充字段:
这个是为了实现补全的功能,是为了让ip数据报长度是4字节的整数倍。
五、IP数据报分片
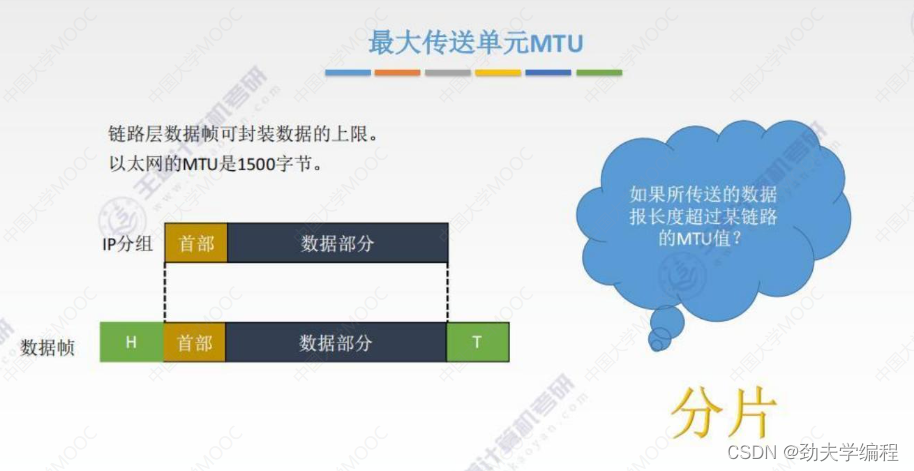
在链路层上,每一个数据帧都有一个可封装数据的上限,这个上限就叫做最大传送单元mtu
对于以太网来说,mtu就是1500字节。
ip分组(也称之为ip数据报),它分为首部和数据部分

ip数据报经过封装成为链路层的数据帧,封装过程就是在分组前面加头,分组后面加尾

中间部分是ip分组,这个数据部分有一个最大要求,这个最大要求就是mtu不能超过这个上限值,以太网中数据帧的数据部分最大就是1500字节。
如果我们要传送的数据报长度超过了链路的mtu怎么办?
我们的解决办法就是分片(这种分片的解决办法前提是这个ip分组同意)
有些ip分组不愿意分片,但是不分片就无法往下传递了,于是就会返回一个icmp的差错报文,这个icmp后面再详细讲。
我们下面来学一下分片的方法。
分片就需要结合ip数据报首部中的”标识、标志、片偏移“来理解。
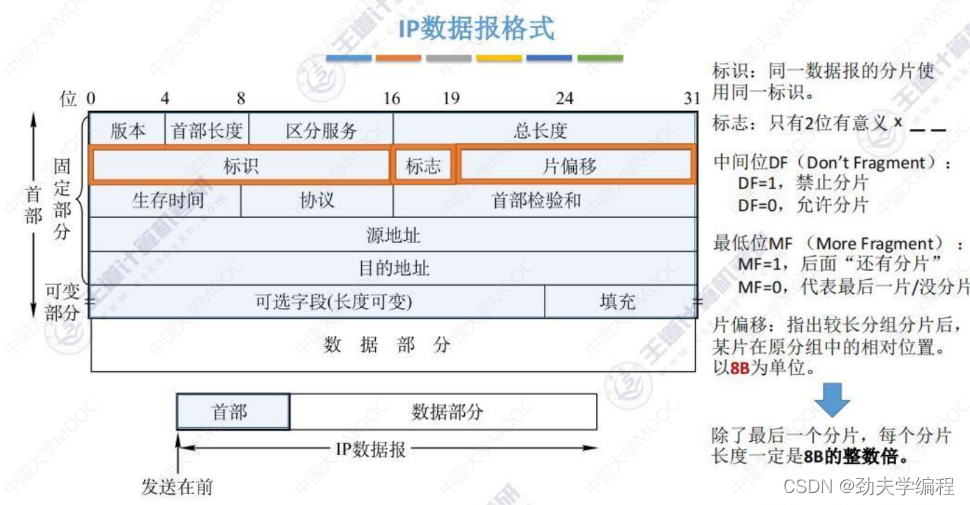
标识:
标识是指同一数据报的分片,只要是同一数据报的分片,它都会使用相同的标识,也就是说一个原始的数据报,如果它的长度超过了mtu,那么它就需要进行分片,每分的一小片它都和原来的数据报使用同一个标识。
标志:
标志字段占3位,但是只有2位是有意义的,
中间的位DF=1表示不允许分片,DF=0表示允许分片
最后一位MF=1表示后面还有分片,MF=0表示后面没有分片了。

片偏移:
这个字段是告诉我们这个分片是在原先分组哪个位置上。
这个字段共占13位,以8B为单位。
如果一个分片的片偏移数据为1,那么这个分组在原先分组中相对位置就是1*8B
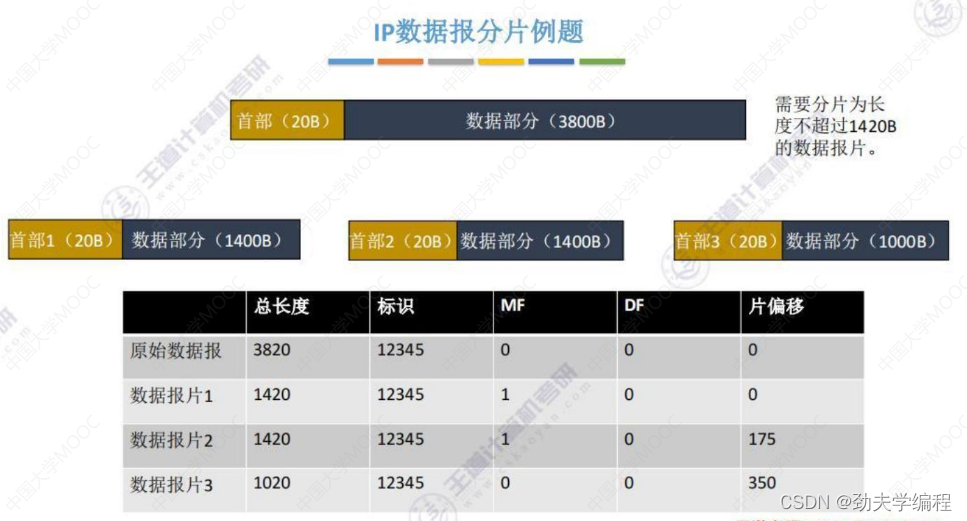
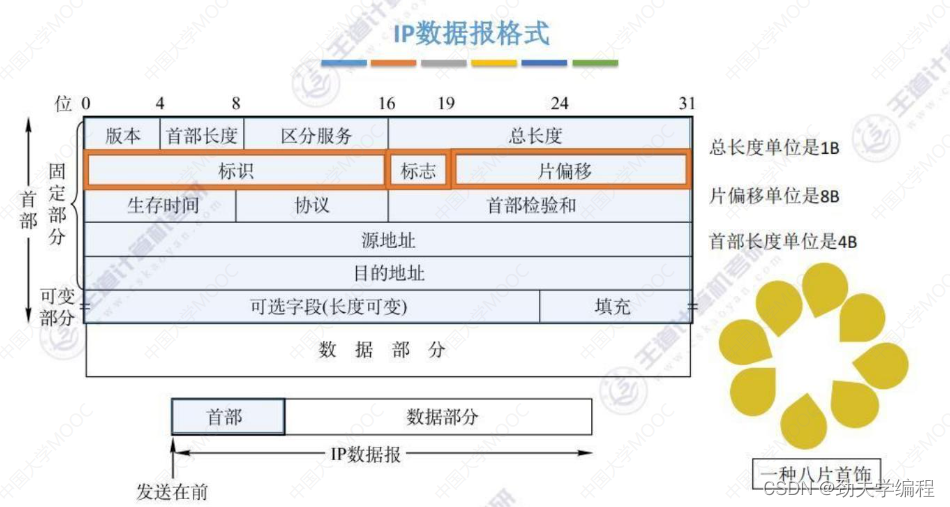
简单记忆单位:1总8片首4
六、IPv4地址
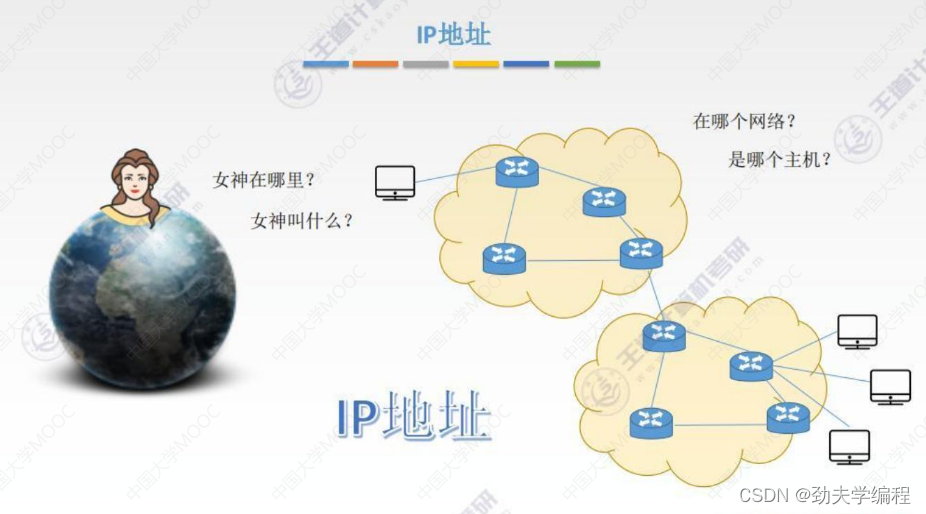
整个大的互联网,也就是因特网是非常单一的网络。ip地址其实就是在给这个网络中的每一台主机或者每一个主机的接口,以及路由器的接口都赋予一个标识符,使之能够标识这个主机的接口以及路由器的接口。这样我我们根据ip地址就可以很容易的在因特网中进行寻址了。
而由于世界上的设备非常的多,如果每一个设备都有一个属于自己的ip地址,我们怎么分配呢?

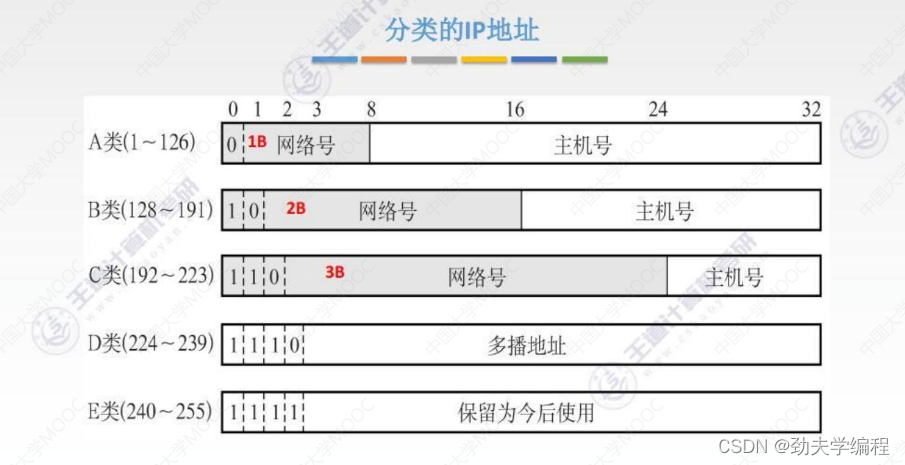
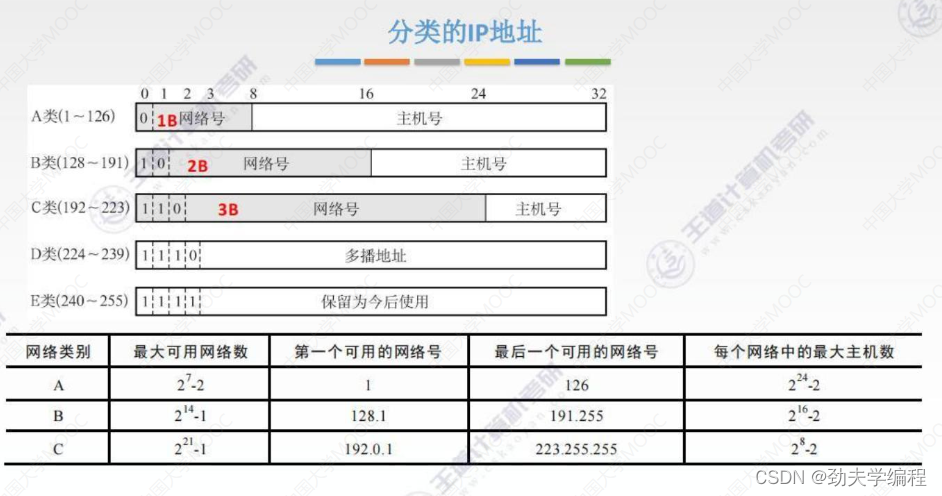
分类的IP地址:
第一阶段:分类的ip地址就是把一个很大的ip地址空间进行一个划分,分成几类。
子网的划分:
第二阶段:随着时代的发展,我们所需分配的地址变多了,这个分类的ip地址其实已经不太能满足人们的应用了,所以对于ip地址的改进就出现了子网的划分。
构成超网:
第三阶段:就是构成超网,也就是CIDR技术,这是目前比较新的技术,是一种无分类的编址方法。
子网划分和构成超网我们后面会详细解释,这里先学习分类的ip地址

身份证可以唯一标识一个人,ip地址也可以唯一标识一个主机或者路由器。
IP地址前8位是网络号,后24位是主机号,这种32位机器是可以识别的。
但是为了方便人们操作,我们写成了点分十进制,我们把每一个字节(8位)写成十进制数,中间用点分割开就可以了。我们做题中也是用的点分十进制。
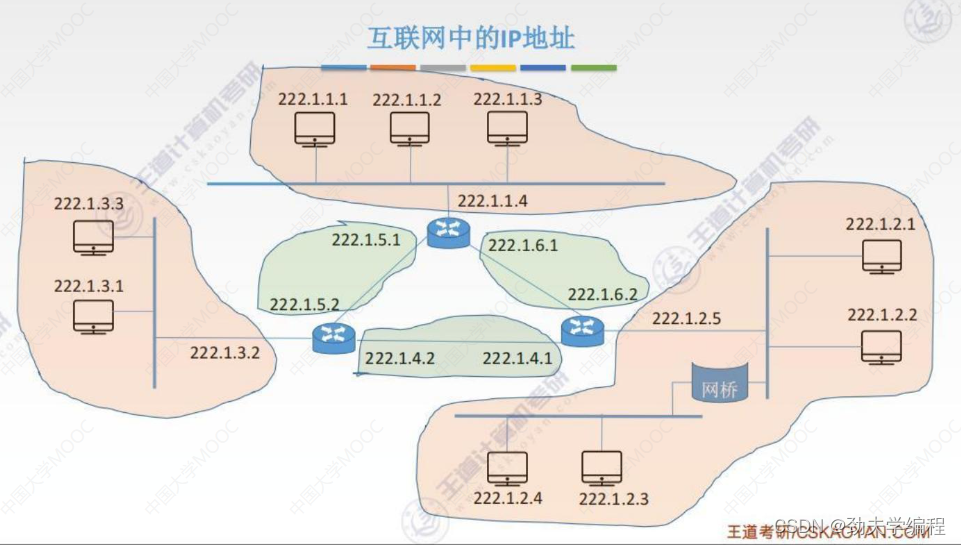
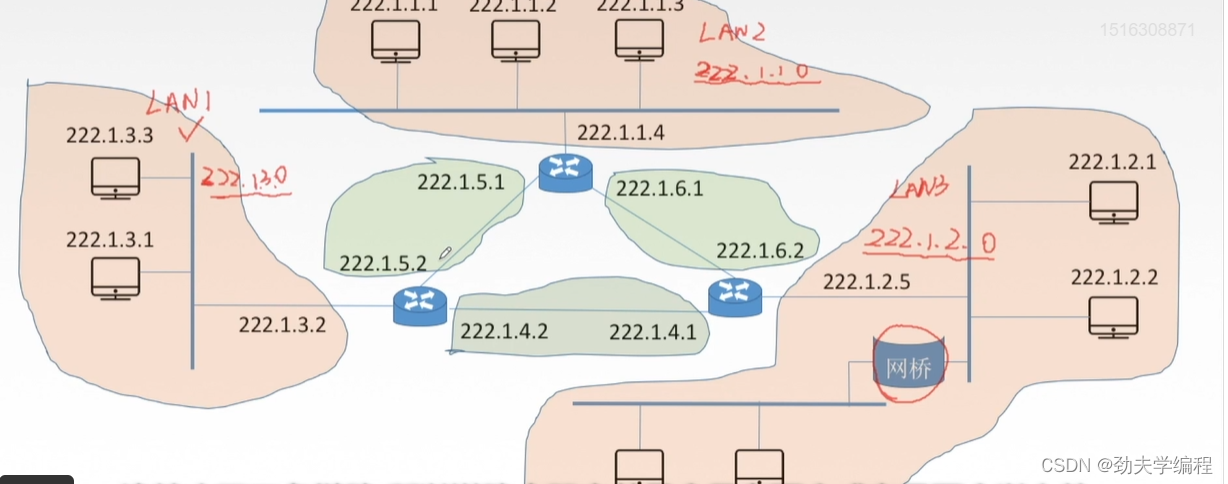
上图中总共有6个网络,但只有2种类型的网络。
上图粉色部分是一种网络,它们都是路由器的一个接口连接的主机以及链路层设备(网桥)所构成的局域网,所以都叫做一个网络。
比如最左边的一个网络,我们可以用222.1.3.0表示,主机号全0,剩下网络号不变这就标识着这样一整个局域网。,我们这里称之为LAN1。
最右边一个网络,它有一个网桥,网桥是不能够分割广播域的,所以用网桥(链路层设备)连接起来的网段仍然是一个局域网,而且也只能有一个网络号,所以这个LAN3所对应的网络号就是222.1.2.0,只要是属于LAN3范围的主机和设备,它们的ip地址网络号都是222.1.2,剩下的主机号位置各部相同。
再来看剩下的几个路由器,每个路由器都有三个端口(看路由器出去几条线)
七、网络地址转换NAT
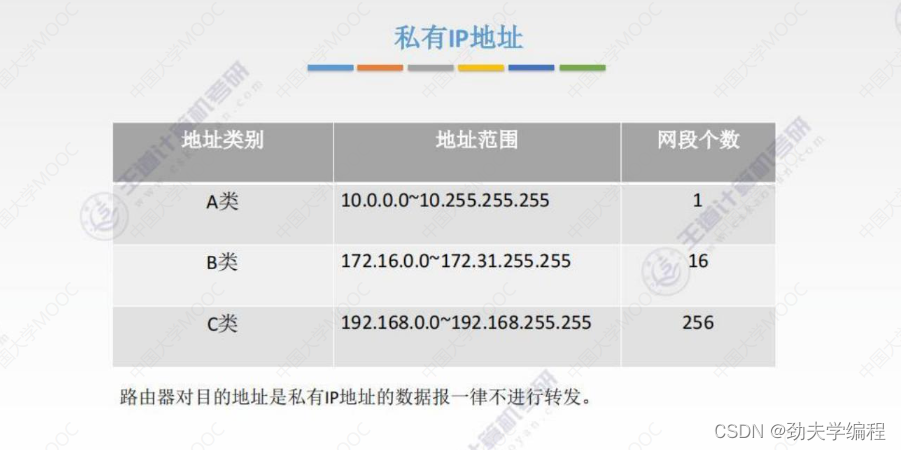
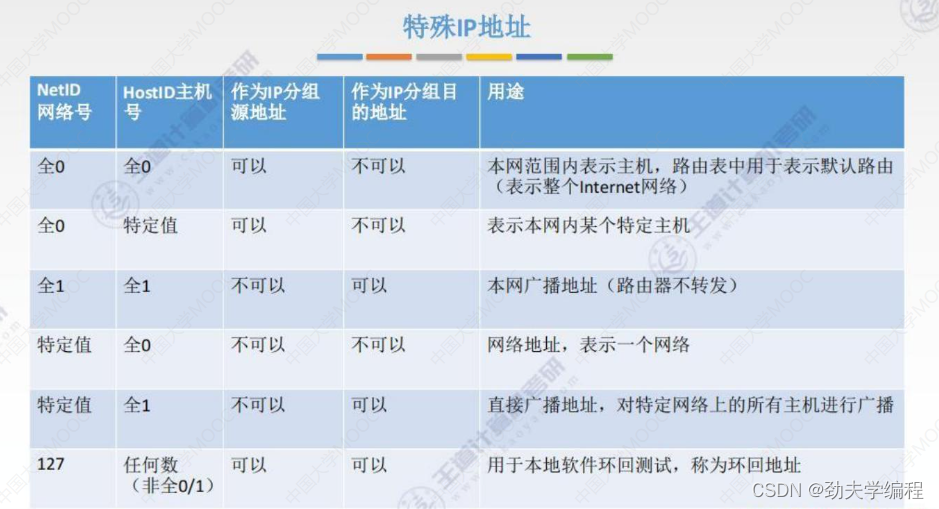
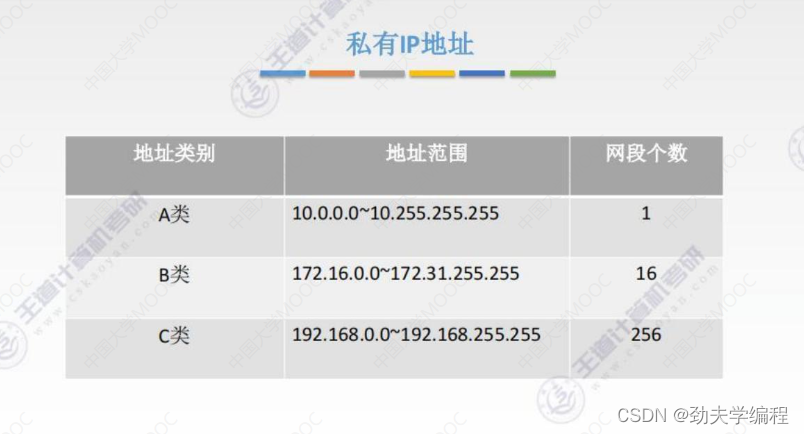
路由器对私有IP地址不会进行转发,也就是说私有IP地址在外网/因特网中是无效的。
那这种私有IP地址能否和外网中的主机进行通信呢?这个是可以的,也就是我们本节要讲的网络地址转换NAT技术。
NAT技术也很简单,只需要在专用网和因特网之间的路由器上装一个NAT的软
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











