






相信在座的所有同学都用过搜索引擎。那么,你知道它的大概工作原理吗?
当你精心制作了一个网页、或写了一篇博客、或者上传一组照片到互联网上,来自世界各地的无数“蜘蛛”便会蜂拥而至。所谓蜘蛛就是搜索引擎公司服务器上的软件,它如同蜘蛛一样把互联网当成了蜘蛛网,没日没夜的访问互联网上的各种信息。
它抓取并复制你的网页,且通过你网页上的链接爬上更多的页面,将所有信息纳入到搜索引擎网站的索引数据库。服务器拆解你网页上的文字内容、标记关键词的位置、字体、颜色,以及相关图片、音频、视频的位置等信息,并生成庞大的索引记录,如下图所示。
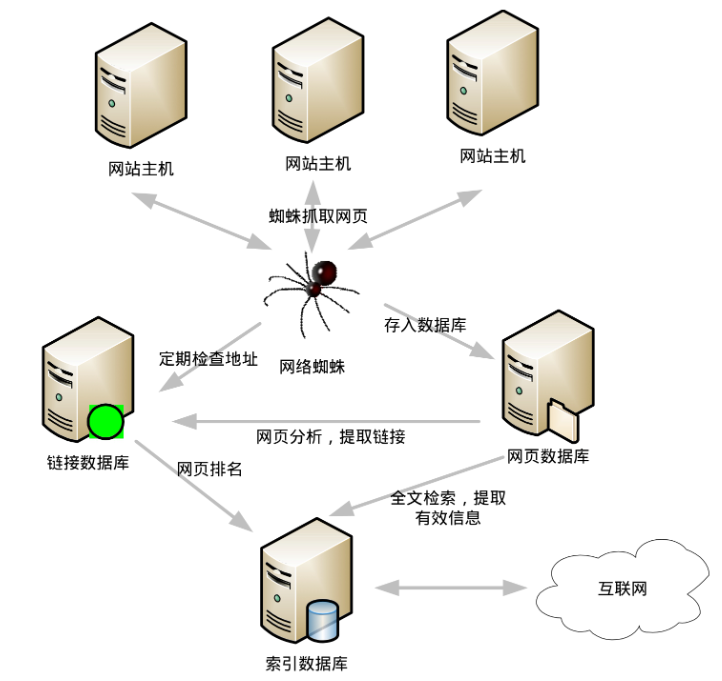
当你在搜索引擎上输入一个单词,点击“搜索”按钮时,它会在不到1秒的时间,带着单词奔向索引数据库的每个“神经末梢”,检索到所有包含搜索词的网页,依据它们的浏览次数与关联性等一系列算法确定网页级别,排列出顺序,最终按你期望的格式呈现在网页上。
这就是一个“关键词”的云端之旅。在过去的10多年里,成就了本世纪最早期的创新明星Google,还有Yandex、Navar和百度等来自全球各地的搜索引擎,搜索引擎已经成为人们最依赖的互联网工具。
作为学习编程的人,面对查找或者叫做搜索(Search)这种最为频繁的操作,理解它的原理并学习应用它是非常必要的事情,让我们开始对“Search”的探索之旅吧。
1 查找概论
只要你打开电脑,就会涉及到查找技术。如炒股软件中查股票信息、硬盘文件中找照片、在光盘中搜DVD,甚至玩游戏时在内存中查找攻击力、魅力值等数据修改用来作弊等,都要涉及到查找。当然,在互联网上查找信息就更加是家常便饭。所有这些需要被查的数据所在的集合,我们给它一个统称叫查找表。
查找表(Search Table)是由同一类型的数据元素(或记录)构成的集合。例如下图就是一个查找表。
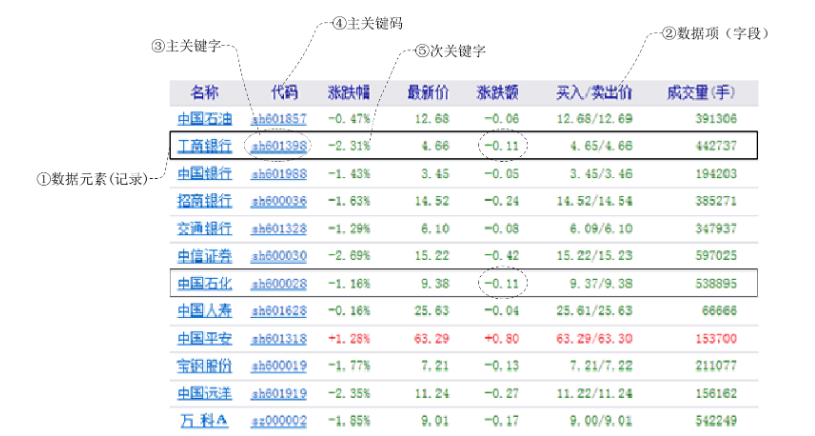
关键字(Key)是数据元素中某个数据项的值,又称为键值,用它可以标识一个数据元素。也可以标识一个记录的某个数据项(字段),我们称为关键码,如上图中①和②所示。
若此关键字可以唯一地标识一个记录,则称此关键字为主关键字(Primary Key)。注意这也就意味着,对不同的记录,其主关键字均不相同。主关键字所在的数据项称为主关键码,如上图中③和④所示。
那么对于那些可以识别多个数据元素(或记录)的关键字,我们称为次关键字(Secondary Key),如上图中⑤所示。次关键字也可以理解为是不以唯一标识一个数据元素(或记录)的关键字,它对应的数据项就是次关键码。
查找(Searching)就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。
若表中存在这样的一个记录,则称查找是成功的,此时查找的结果给出整个记录的信息,或指示该记录在查找表中的位置。比如上图所示,如果我们查找主关键码“代码”的主关键字为“sh601398”的记录时,就可以得到第2条唯一记录。如果我们查找次关键码“涨跌额”为“-0.11”的记录时,就可以得到两条记录。
若表中不存在关键字等于给定值的记录,则称查找不成功,此时查找的结果可给出一个“空”记录或“空”指针。
查找表按照操作方式来分有两大种:静态查找表和动态查找表。
1.1 静态查找表
静态查找表(Static Search Table):只作查找操作的查找表。它的主要操作有:
(1)查询某个“特定的”数据元素是否在查找表中。
(2)检索某个“特定的”数据元素和各种属性。
按照我们大多数人的理解,查找,当然是在已经有的数据中找到我们需要的。静态查找就是在干这样的事情,不过,现实中还有存在这样的应用:查找的目的不仅仅只是查找。
比如网络时代的新名词,如反应年轻人生活的“蜗居”、“蚁族”、“孩奴”、“啃老”等,以及“X客”系列如博客、播客、闪客、黑客、威客等,如果需要将它们收录到汉语词典中,显然收录时就需要查找它们是否存在,以及找到如果不存在时应该收录的位置。再比如,如果你需要对某网站上亿的注册用户进行清理工作,注销一些非法用户,你就需查找到它们后进行删除,删除后其实整个查找表也会发生变化。对于这样的应用,我们就引入了动态查找表。
1.2 动态查找表
动态查找表(Dynamic Search Table):在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。显然动态查找表的操作就是两个:
(1)查找时插入数据元素。
(2)查找时删除数据元素。
为了提高查找的效率,我们需要专门为查找操作设置数据结构,这种面向查找操作的数据结构称为查找结构。
从逻辑上来说,查找所基于的数据结构是集合,集合中的记录之间没有本质关系。可是要想获得较高的查找性能,我们就不能不改变数据元素之间的关系,在存储时可以将查找集合组织成表、树等结构。
例如,对于静态查找表来说,我们不妨应用线性表结构来组织数据,这样可以使用顺序查找算法,如果再对主关键字排序,则可以应用折半查找等技术进行高效的查找。
如果是需要动态查找,则会复杂一些,可以考虑二叉排序树的查找技术。
另外,还可以用散列表结构来解决一些查找问题,这些技术都将在后面的讲解中说明。
2. 顺序表查找
试想一下,要在散落的一大堆书中找到你需要的那本有多么麻烦。碰到这种情况的人大都会考虑做一件事,那就是把这些书排列整齐,比如竖起来放置在书架上,这样根据书名,就很容易查找到需要的图书,如下图所示。

散落的图书可以理解为一个集合,而将它们排列整齐,就如同是将此集合构造成一个线性表。我们要针对这一线性表进行查找操作,因此它就是静态查找表。
此时图书尽管已经排列整齐,但还没有分类,因此我们要找书只能从头到尾或从尾到头一本一本查看,直到找到或全部查找完为止。这就是我们现在要讲的顺序查找。
顺序查找(Sequential Search)又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功。
2.1 顺序表查找算法
顺序查找的算法实现如下。

2.2 顺序表查找优化
到这里并非足够完美,因为每次循环时都需要对i是否越界,即是否小于等于n作判断。事实上,还可以有更好一点的办法,设置一个哨兵,可以解决不需要每次让i与n作比较。看下面的改进后的顺序查找算法代码。

此时代码是从尾部开始查找,由于a[0]=key,也就是说,如果在a[i]中有key则返回i值,查找成功。否则一定在最终的a[0]处等于key,此时返回的是0,即说明a[1]~a[n]中没有关键字key,查找失败。
这种在查找方向的尽头放置“哨兵”免去了在查找过程中每一次比较后都要判断查找位置是否越界的小技巧,看似与原先差别不大,但在总数据较多时,效率提高很大,是非常好的编码技巧。当然,“哨兵”也不一定就一定要在数组开始,也可以在末端。
对于这种顺序查找算法来说,查找成功最好的情况就是在第一个位置就找到了,算法时间复杂度为O(1),最坏的情况是在最后一位置才找到,需要n次比较,时间复杂度为O(n),当查找不成功时,需要n+1次比较,时间复杂度为O(n)。我们之前推导过,关键字在任何一位置的概率是相同的,所以平均查找次数为(n+1)/2,所以最终时间复杂度还是O(n)。
很显然,顺序查找技术是有很大缺点的,n很大时,查找效率极为低下,不过优点也是有的,这个算法非常简单,对静态查找表的记录没有任何要求,在一些小型数据的查找时,是可以适用的。
另外,也正由于查找概率的不同,我们完全可以将容易查找到的记录放在前面,而不常用的记录放置在后面,效率就可以有大幅提高。
3. 有序表查找
我们如果仅仅是把书整理在书架上,要找到一本书还是比较困难的,也就是刚才讲的需要逐个顺序查找。但如果我们在整理书架时,将图书按照书名的拼音排序放置,那么要找到某一本书就相对容易了。说白了,就是对图书做了有序排列,一个线性表有序时,对于查找总是很有帮助的。
3.1 折半查找
我们在讲树结构的二叉树定义时,曾经提到过一个小游戏,我在纸上已经写好了一个100以内的正整数数字请你猜,问几次可以猜出来,当时已经介绍了如何最快猜出这个数字。我们把这种每次取中间记录查找的方法叫做折半查找,如下图所示。
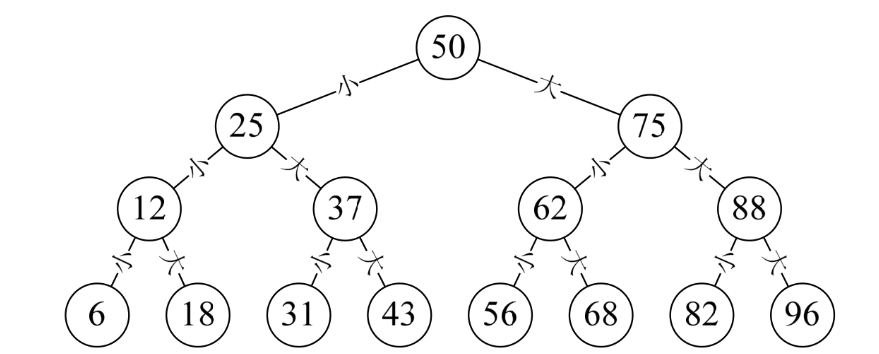
折半查找(Binary Search)技术,又称为二分查找。它的前提是线性表中的记录必须是关键码有序(通常从小到大有序),线性表必须采用顺序存储。折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
假设我们现在有这样一个有序表数组{0,1,16,24,35,47,59,62,73,88,99} ,除0下标外共10个数字。对它进行查找是否存在62这个数。我们来看折半查找的算法是如何工作的。

该算法还是比较容易理解的,同时我们也能感觉到它的效率非常高。但到底高多少?关键在于此算法的时间复杂度分析。
首先,我们将这个数组的查找过程绘制成一棵二叉树,如下图所示,从图上就可以理解,如果查找的关键字不是中间记录47的话,折半查找等于是把静态有序查找表分成了两棵子树,即查找结果只需要找其中的一半数据记录即可,等于工作量少了一半,然后继续折半查找,效率当然是非常高了。
我们之前讲的二叉树的性质,有过对“具有n个结点的完全二叉树的深度为⌊log2n⌋+1。”性质的推导过程。在这里尽管折半查找判定二叉树并不是完全二叉树,但同样相同的推导可以得出,最坏情况是查找到关键字或查找失败的次数为⌊log2n⌋+1。
有人还在问最好的情况?那还用说吗,当然是1次了。
因此最终我们折半算法的时间复杂度为O(logn),它显然远远好于顺序查找的O(n)时间复杂度了。
不过由于折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,这样的算法已经比较好了。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。
3.2 插值查找
现在我们的新问题是,为什么一定要折半,而不是折四分之一或者折更多呢?
打个比方,在英文词典里查“apple”,你下意识里翻开词典是翻前面的书页还是后面的书页呢?如果再让你查“zoo”,你又怎么查?很显然,这里你绝对不会是从中间开始查起,而是有一定目的的往前或往后翻。
同样的,比如要在取值范围0~10000之间100个元素从小到大均匀分布的数组中查找5,我们自然会考虑从数组下标较小的开始查找。
看来,我们的折半查找,还是有改进空间的。
折半查找代码的第8句,我们略微等式变换后得到:
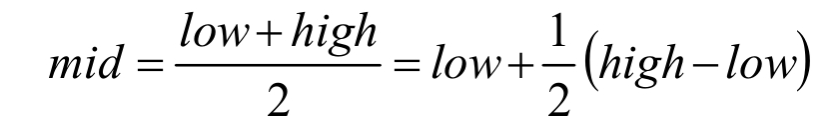
也就是mid等于最低下标low加上最高下标high与low的差的一半。算法科学家们考虑的就是将这个1/2进行改进,改进为下面的计算方案:
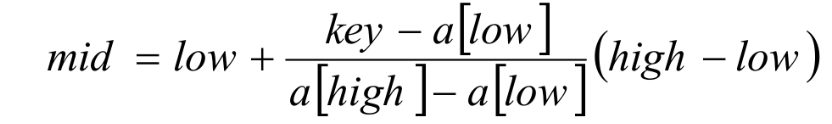
将1/2改成这样有什么道理呢?假设a[11]={0,1,16,24,35,47,59,62,73,88,99},low=1,high=10,则a[low]=1,a[high]=99,如果我们要找的是key=16时,按原来折半的做法,我们需要四次才可以得到结果,但如果用新办法,(16-1)/(99-1)≈0.153,即mid≈1+0.153×(10-1)=2.377取整得到mid=2,我们只需要二次就查找到结果了,显然大大提高了查找的效率。
换句话说,我们只需要在折半查找算法的代码中更改一下第8行代码如下:

就得到了另一种有序表查找算法,插值查找法。插值查找(Interpolation Search)是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式.
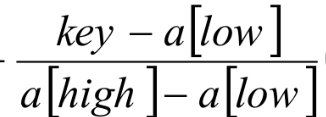
应该说,从时间复杂度来看,它也是O(logn),但对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好得多。反之,数组中如果分布类似{0,1,2,2000,2001,……, 999998,999999}这种极端不均匀的数据,用插值查找未必是很合适的选择。
3.3 斐波那契查找
还有没有其他办法?我们折半查找是从中间分,也就是说,每一次查找总是一分为二,无论数据偏大还是偏小,很多时候这都未必就是最合理的做法。除了插值查找,我们再介绍一种有序查找,斐波那契查找(Fibonacci Search),它是利用了黄金分割原理来实现的。
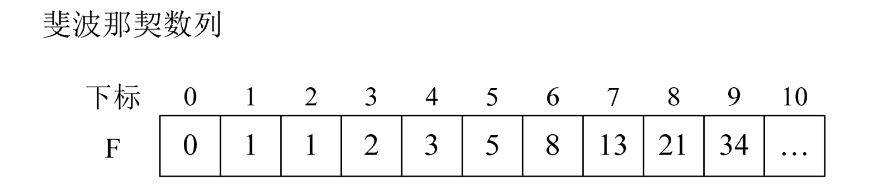
斐波那契数列我们在前面讲递归时,也详细地介绍了它。如何利用这个数列来作为分割呢?
为了能够介绍清楚这个查找算法,我们先需要有一个斐波那契数列的数组,如下图所示。
下面我们根据代码来看程序是如何运行的。

1.程序开始运行,参数a={0,1,16,24,35,47,59,62,73,88,99},n=10,要查找的关键字key=59。注意此时我们已经有了事先计算好的全局变量数组F的具体数据,它是斐波那契数列,F={0,1,1,2,3,5,8,13,21,……}。
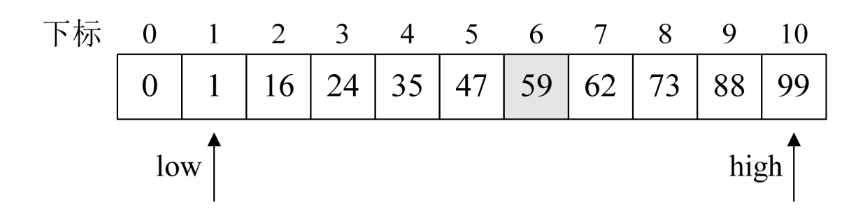
2.第6~8行是计算当前的n处于斐波那契数列的位置。现在n=10,F[6]<n<F[7],所以计算得出k=7。
3.第9~10行,由于k=7,计算时是以F[7]=13为基础,而a中最大的仅是a[10],后面的a[11],a[12]均未赋值,这不能构成有序数列,因此将它们都赋值为最大的数组值,所以此时a[11]=a[12]=a[10]=99(此段代码作用后面还有解释)。
4.第11~31行查找正式开始。
5.第13行,mid=1+F[7-1]-1=8,也就是说,我们第一个要对比的数值是从下标为8开始的。
6.由于此时key=59而a[8]=73,因此执行第16~17行,得到high=7,k=6。
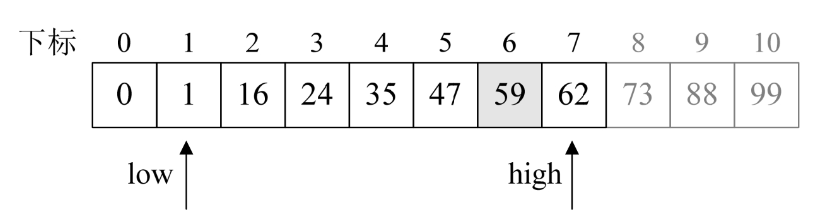
7.再次循环,mid=1+F[6-1]-1=5。此时a[5]=47<key,因此执行第21~22行,得到low=6,k=6-2=4。注意此时k下调2个单位。
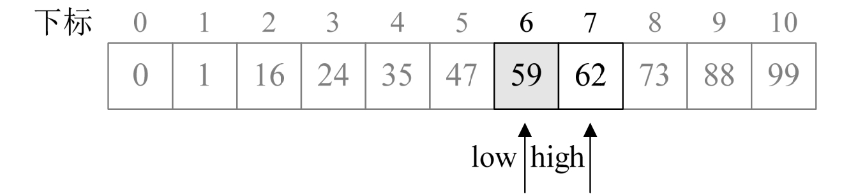
8.再次循环,mid=6+F[4-1]-1=7。此时a[7]=62>key,因此执行第16~17行,得到high=6,k=4-1=3。
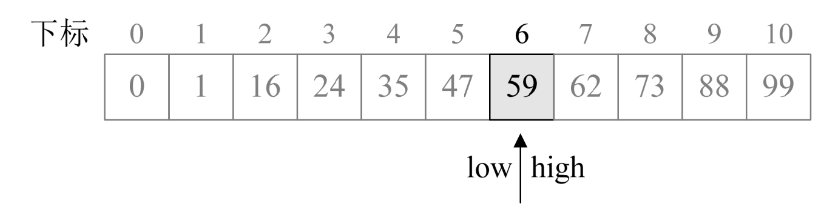
9.再次循环,mid=6+F[3-1]-1=6。此时a[6]=59=key,因此执行第26~27行,得到返回值为6。程序运行结束。
如果key=99,此时查找循环第一次时,mid=8与上例是相同的,第二次循环时,mid=11,如果a[11]没有值就会使得与key的比较失败,为了避免这样的情况出现,第9~10行的代码就起到这样的作用。
斐波那契查找算法的核心在于:
1)当key=a[mid]时,查找就成功;
2)当key<a[mid]时,新范围是第low个到第mid-1个,此时范围个数为F[k-1] -1个;
3)当key>a[mid]时,新范围是第m+1个到第high个,此时范围个数为F[k-2] -1个。
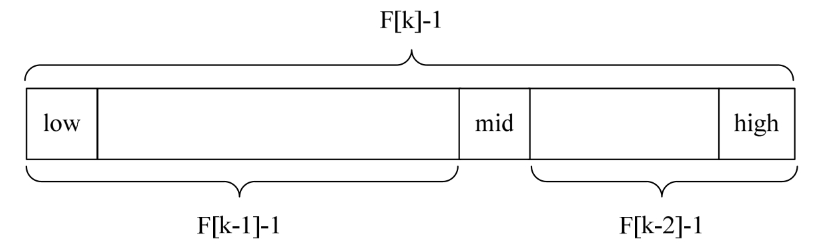
也就是说,如果要查找的记录在右侧,则左侧的数据都不用再判断了,不断反复进行下去,对处于当中的大部分数据,其工作效率要高一些。所以尽管斐波那契查找的时间复杂也为O(logn),但就平均性能来说,斐波那契查找要优于折半查找。可惜如果是最坏情况,比如这里key=1,那么始终都处于左侧长半区在查找,则查找效率要低于折半查找。
还有比较关键的一点,折半查找是进行加法与除法运算(mid=(low+high)/2),插值查找进行复杂的四则运算(mid=low+(high-low)*(key-a[low])/(a[high]-a[low])),而斐波那契查找只是最简单加减法运算(mid=low+F[k-1]-1),在海量数据的查找过程中,这种细微的差别可能会影响最终的查找效率。
应该说,三种有序表的查找本质上是分隔点的选择不同,各有优劣,实际开发时可根据数据的特点综合考虑再做出选择。
4. 线性索引查找
我们前面讲的几种比较高效的查找方法都是基于有序的基础之上的,但事实上,很多数据集可能增长非常快,例如,某些微博网站或大型论坛的帖子和回复总数每天都是成百万上千万条,如图8-5-1所示,或者一些服务器的日志信息记录也可能是海量数据,要保证记录全部是按照当中的某个关键字有序,其时间代价是非常高昂的,所以这种数据通常都是按先后顺序存储。
那么对于这样的查找表,我们如何能够快速查找到需要的数据呢?办法就是——索引。
数据结构的最终目的是提高数据的处理速度,索引是为了加快查找速度而设计的一种数据结构。索引就是把一个关键字与它对应的记录相关联的过程,一个索引由若干个索引项构成,每个索引项至少应包含关键字和其对应的记录在存储器中的位置等信息。索引技术是组织大型数据库以及磁盘文件的一种重要技术。
索引按照结构可以分为线性索引、树形索引和多级索引。我们这里就只介绍线性索引技术。所谓线性索引就是将索引项集合组织为线性结构,也称为索引表。我们重点介绍三种线性索引:稠密索引、分块索引和倒排索引。
4.1 稠密索引
我母亲年纪大了,记忆力不好,经常在家里找不到东西,于是她想到了一个办法。她用一小本子记录了家里所有小东西放置的位置.总之,她老人家把这些小物品的放置位置都记录在了小本子上,并且每隔一段时间还按照本子整理一遍家中的物品,用完都放回原处,这样她就几乎再没有找不到东西。
记得有一次我申请职称时,单位一定要我的大学毕业证,我在家里找了很长时间未果,急得要死。和老妈一说,她的神奇小本子马上发挥作用,一下子就找到了,原来被她整理后放到了衣橱里的抽屉里。
从这件事就可以看出,家中的物品尽管是无序的,但是如果有一个小本子记录,寻找起来也是非常容易,而这小本子就是索引。
稠密索引是指在线性索引中,将数据集中的每个记录对应一个索引项,如下图所示。
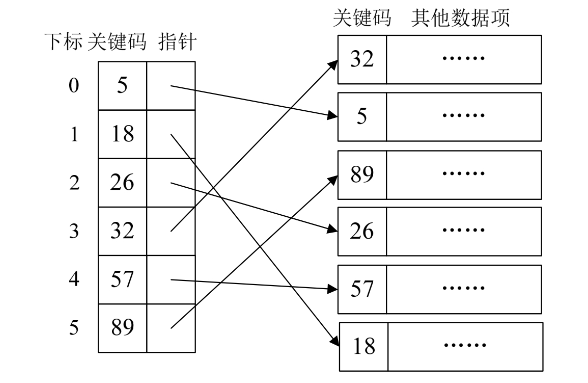
刚才的小例子和稠密索引还是略有不同,家里的东西毕竟少,小本子再多也就几十页,全部翻看完就几分钟时间,而稠密索引要应对的可能是成千上万的数据,因此对于稠密索引这个索引表来说,索引项一定是按照关键码有序的排列。
索引项有序也就意味着,我们要查找关键字时,可以用到折半、插值、斐波那契等有序查找算法,大大提高了效率。比如上图中,我要查找关键字是18的记录,如果直接从右侧的数据表中查找,那只能顺序查找,需要查找6次才可以查到结果。而如果是从左侧的索引表中查找,只需两次折半查找就可以得到18对应的指针,最终查找到结果。
这显然是稠密索引优点,但是如果数据集非常大,比如上亿,那也就意味着索引也得同样的数据集长度规模,对于内存有限的计算机来说,可能就需要反复去访问磁盘,查找性能反而大大下降了。
4.2 分块索引
回想一下图书馆是如何藏书的。显然它不会是顺序摆放后,给我们一个稠密索引表去查,然后再找到书给你。图书馆的图书分类摆放是一门非常完整的科学体系,而它最重要的一个特点就是分块。

稠密索引因为索引项与数据集的记录个数相同,所以空间代价很大。为了减少索引项的个数,我们可以对数据集进行分块,使其分块有序,然后再对每一块建立一个索引项,从而减少索引项的个数。
分块有序,是把数据集的记录分成了若干块,并且这些块需要满足两个条件:
■ 块内无序,即每一块内的记录不要求有序。当然,块内有序对查找来说更理想,不过这就要付出大量时间和空间的代价,因此通常我们不要求块内有序。
■ 块间有序,例如,要求第二块所有记录的关键字均要大于第一块中所有记录的关键字,第三块的所有记录的关键字均要大于第二块的所有记录关键字……因为只有块间有序,才有可能在查找时带来效率。
对于分块有序的数据集,将每块对应一个索引项,这种索引方法叫做分块索引。如下图所示,我们定义的分块索引的索引项结构分三个数据项:
■ 最大关键码,它存储每一块中的最大关键字,这样的好处就是可以使得在它之后的下一块中的最小关键字也能比这一块最大的关键字要大;
■ 存储了块中的记录个数,以便于循环时使用;
■ 用于指向块首数据元素的指针,便于开始对这一块中记录进行遍历。

在分块索引表中查找,就是分两步进行:
1.在分块索引表中查找要查关键字所在的块。由于分块索引表是块间有序的,因此很容易利用折半、插值等算法得到结果。例如,在上图的数据集中查找62,我们可以很快可以从左上角的索引表中由57<62<96得到62在第三个块中。
2.根据块首指针找到相应的块,并在块中顺序查找关键码。因为块中可以是无序的,因此只能顺序查找。
应该说,分块索引的思想是很容易理解的,我们通常在整理书架时,都会考虑不同的层板放置不同类别的图书。例如,我家里就是最上层放不太常翻阅的小说书,中间层放经常用到的如菜谱、字典等生活和工具用书,最下层放大开本比较重的计算机书。这就是分块的概念,并且让它们块间有序了。至于上层中《红楼梦》是应该放在《三国演义》的左边还是右边,并不是很重要。毕竟要找小说《三国演义》,只需要对这一层的图书用眼睛扫过一遍就能很容易查找到。
我们再来分析一下分块索引的平均查找长度。设n个记录的数据集被平均分成m块,每个块中有t条记录,显然n=m×t,或者说m=n/t。再假设Lb为查找索引表的平均查找长度,因最好与最差的等概率原则,所以Lb的平均长度为(m+1)/2。Lw为块中查找记录的平均查找长度,同理可知它的平均查找长度(t+1)/2。
这样分块索引查找的平均查找长度为:
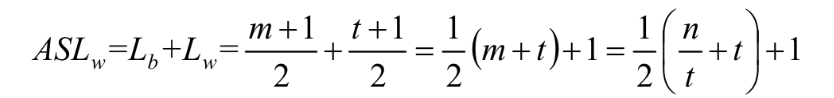
注意上面这个式子的推导是为了让整个分块索引查找长度依赖n和t两个变量。从这里了我们也就得到,平均长度不仅仅取决于数据集的总记录数n,还和每一个块的记录个数t相关。最佳的情况就是分的块数m与块中的记录数t相同,此时意味着n=m×t=t^2,即
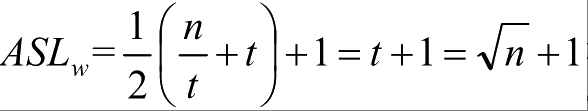
可见,分块索引的效率比之顺序查找的O(n)是高了不少,不过显然它与折半查找的O(logn)相比还有不小的差距。因此在确定所在块的过程中,由于块间有序,所以可以应用折半、插值等手段来提高效率。
总的来说,分块索引在兼顾了对细分块不需要有序的情况下,大大增加了整体查找的速度,所以普遍被用于数据库表查找等技术的应用当中。
4.3 倒排索引
我不知道大家有没有对搜索引擎好奇过,无论你查找什么样的信息,它都可以在极短的时间内给你一些结果,如下图所示。是什么算法技术达到这样的高效查找呢?
我们在这里介绍最简单的,也算是最基础的搜索技术——倒排索引。
我们来看样例,现在有两篇极短的英文“文章”——其实只能算是句子,我们暂认为它是文章,编号分别是1和2。
1.Books and friends should be few but good.(读书如交友,应求少而精。)
2.A good book is a good friend.(好书如挚友。)
假设我们忽略掉如“books”、“friends”中的复数“s”以及如“A”这样的大小写差异。我们可以整理出这样一张单词表,如下表所示,并将单词做了排序,也就是表格显示了每个不同的单词分别出现在哪篇文章中,比如“good”它在两篇文章中都有出现,而“is”只是在文章2中才有。
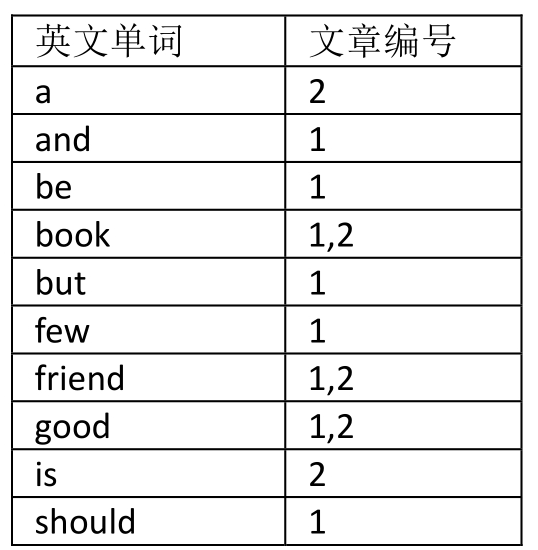
有了这样一张单词表,我们要搜索文章,就非常方便了。如果你在搜索框中填写“book”关键字。系统就先在这张单词表中有序查找“book”,找到后将它对应的文章编号1和2的文章地址(通常在搜索引擎中就是网页的标题和链接)返回,并告诉你,查找到两条记录,用时0.0001秒。由于单词表是有序的,查找效率很高,返回的又只是文章的编号,所以整体速度都非常快。
在这里这张单词表就是索引表,索引项的通用结构是:
■ 次关键码,例如上面的“英文单词”;
■ 记录号表,例如上面的“文章编号”。
其中记录号表存储具有相同次关键字的所有记录的记录号(可以是指向记录的指针或者是该记录的主关键字)。这样的索引方法就是倒排索引(inverted index)。倒排索引源于实际应用中需要根据属性(或字段、次关键码)的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引。
倒排索引的优点显然就是查找记录非常快,基本等于生成索引表后,查找时都不用去读取记录,就可以得到结果。但它的缺点是这个记录号不定长,比如上例有7个单词的文章编号只有一个,而“book”、“friend”、“good”有两个文章编号,若是对多篇文章所有单词建立倒排索引,那每个单词都将对应相当多的文章编号,维护比较困难,插入和删除操作都需要作相应的处理。
5. 二叉排序树
假设查找的数据集是普通的顺序存储,那么插入操作就是将记录放在表的末端,给表记录数加一即可,删除操作可以是删除后,后面的记录向前移,也可以是要删除的元素与最后一个元素互换,表记录数减一,反正整个数据集也没有什么顺序,这样的效率也不错。应该说,插入和删除对于顺序存储结构来说,效率是可以接受的,但这样的表由于无序造成查找的效率很低,前面我们有讲解,这就不在啰嗦。
如果查找的数据集是有序线性表,并且是顺序存储的,查找可以用折半、插值、斐波那契等查找算法来实现,可惜,因为有序,在插入和删除操作上,就需要耗费大量的时间。
有没有一种即可以使得插入和删除效率不错,又可以比较高效率地实现查找的算法呢?还真有。
我们在之前把这种需要在查找时插入或删除的查找表称为动态查找表。我们现在就来看看什么样的结构可以实现动态查找表的高效率。
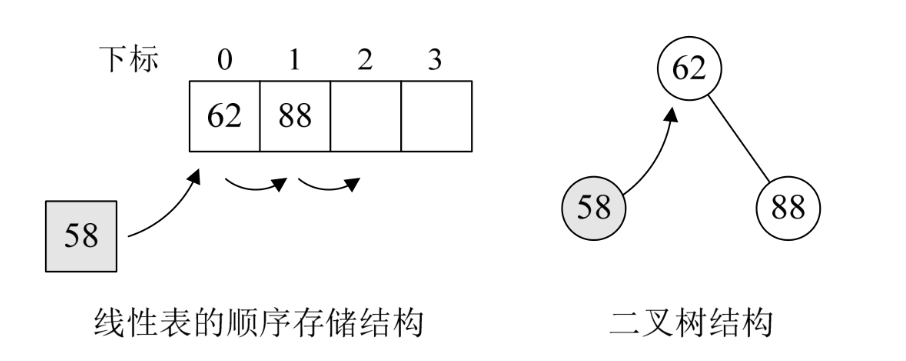
如果在复杂的问题面前,我们束手无策的话,不妨先从最最简单的情况入手。现在我们的目标是插入和查找同样高效。假设我们的数据集开始只有一个数{62},然后现在需要将88插入数据集,于是数据集成了{62,88},还保持着从小到大有序。再查找有没有58,没有则插入,可此时要想在线性表的顺序存储中有序,就得移动62和88的位置,如下图左图,可不可以不移动呢?嗯,当然是可以,那就是二叉树结构。当我们用二叉树的方式时,首先我们将第一个数62定为根结点,88因为比62大,因此让它做62的右子树,58因比62小,所以成为它的左子树。此时58的插入并没有影响到62与88的关系,如下图右图所示。
也就是说,若我们现在需要对集合{62,88,58,47,35,73,51,99,37,93}做查找,在我们打算创建此集合时就考虑用二叉树结构,而且是排好序的二叉树来创建。如下图所示,62、88、58创建好后,下一个数47因比58小,是它的左子树(见③),35是47的左子树(见④),73比62大,但却比88小,是88的左子树(见⑤),51比62小、比58小、比47大,是47的右子树(见⑥),99比62、88都大,是88的右子树(见⑦),37比62、58、47都小,但却比35大,是35的右子树(见⑧),93则因比62、88大是99的左子树(见⑨)。
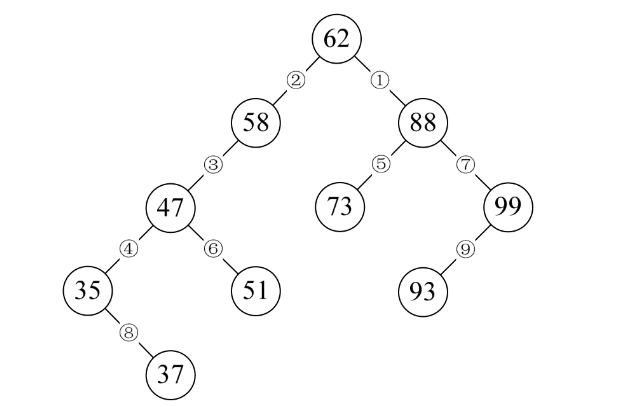
这样我们就得到了一棵二叉树,并且当我们对它进行中序遍历时,就可以得到一个有序的序列{35,37,47,51,58,62,73,88,93,99},所以我们通常称它为二叉排序树。
二叉排序树(Binary Sort Tree),又称为二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树。
■ 若它的左子树不空,则左子树上所有结点的值均小于它的根结构的值;
■ 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
■ 它的左、右子树也分别为二叉排序树。
从二叉排序树的定义也可以知道,它前提是二叉树,然后它采用了递归的定义方法,再者,它的结点间满足一定的次序关系,左子树结点一定比其双亲结点小,右子树结点一定比其双亲结点大。
构造一棵二叉排序树的目的,其实并不是为了排序,而是为了提高查找和插入删除关键字的速度。不管怎么说,在一个有序数据集上的查找,速度总是要快于无序的数据集的,而二叉排序树这种非线性的结构,也有利于插入和删除的实现。
5.1 二叉排序树查找操作
首先我们提供一个二叉树的结构。
 然后我们来看看二叉排序树的查找是如何实现的。
然后我们来看看二叉排序树的查找是如何实现的。

1.SearchBST函数是一个可递归运行的函数,函数调用时的语句为SearchBST(T,93,NULL,p),参数T是一个二叉链表,其中数据如图8-6-3所示,key代表要查找的关键字,目前我们打算查找93,二叉树f指向T的双亲,当T指向根结点时,f的初值就为NULL,它在递归时有用,最后的参数p是为了查找成功后可以得到查找到的结点位置。
2.第3~7行,是用来判断当前二叉树是否到叶子结点,显然当T指向根结点62的位置,T不为空,第5~6行不执行。
3.第8~12行是查找到相匹配的关键字时执行语句,显然93≠62,第10~11行不执行。
4.第13~14行是当要查找关键字小于当前结点值时执行语句,由于93>62,第14行不执行。
5.第15~16行是当要查找关键字大于当前结点值时执行语句,由于93>62,所以递归调用SearchBST(T->rchild, key, T, p)。此时T指向了62的右孩子88,如下图所示。
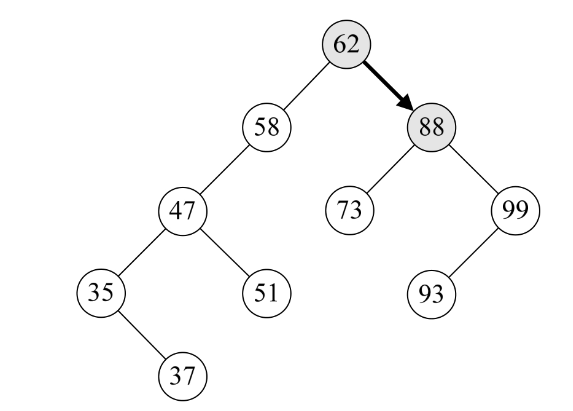
6.此时第二层SearchBST,因93比88大,所以执行第16行,再次递归调用SearchBST(T->rchild, key, T, p)。此时T指向了88的右孩子99,如下图所示。
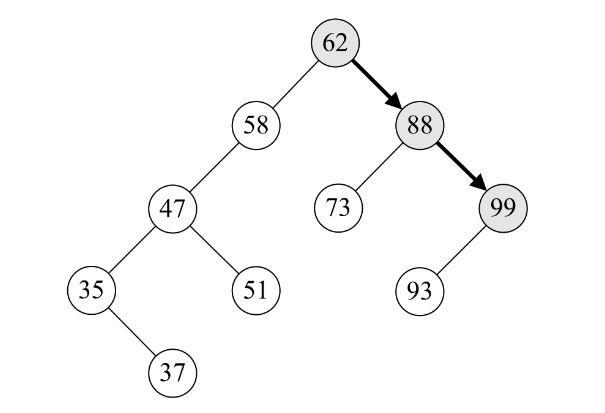
7.第三层的SearchBST,因93比99小,所以执行第14行,递归调用SearchBST(T->lchild, key, T, p)。此时T指向了99的左孩子93,如下图所示。
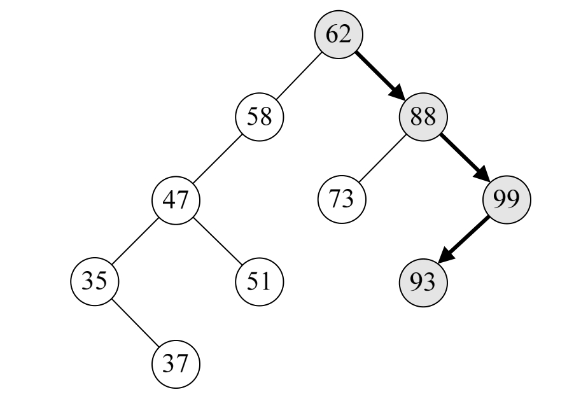
8.第四层SearchBST,因key等于T->data,所以执行第10~11行,此时指针p指向93所在的结点,并返回True到第三层、第二层、第一层,最终函数返回True。
5.2 二叉排序树插入操作
有了二叉排序树的查找函数,那么所谓的二叉排序树的插入,其实也就是将关键字放到树中的合适位置而已,来看代码。

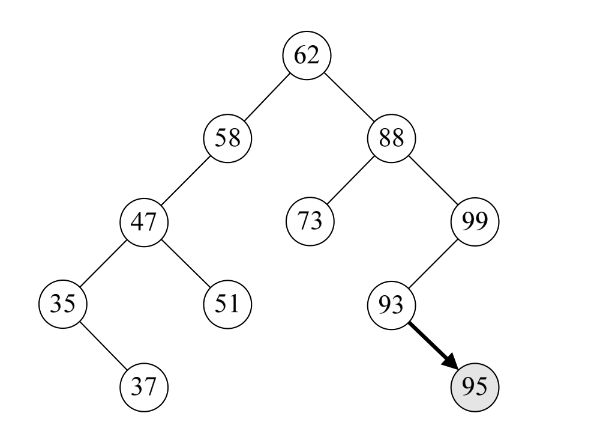
这段代码非常简单。如果你调用函数是“InsertBST(T,93);”,那么结果就是FALSE,如果是“InsertBST(T,95);”,那么一定就是在93的结点增加一个右孩子95,并且返回True。如下图所示。
有了二叉排序树的插入代码,我们要实现二叉排序树的构建就非常容易了。下面的代码就可以创建一棵这样的树。
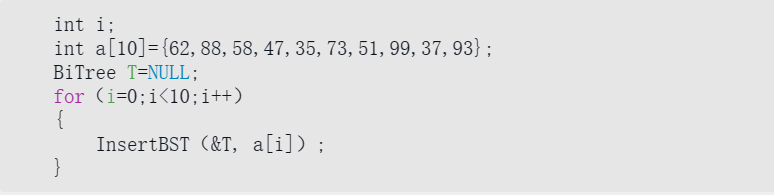
在你的大脑里,是否已经有一幅随着循环语句的运行逐步生成这棵二叉排序树的动画图案呢?如果不能,那只能说明你还没真理解它的原理哦。
5.3 二叉排序树删除操作
俗话说“请神容易送神难”,我们已经介绍了二叉排序树的查找与插入算法,但是对于二叉排序树的删除,就不是那么容易,我们不能因为删除了结点,而让这棵树变得不满足二叉排序树的特性,所以删除需要考虑多种情况。
如果需要查找并删除如37、51、73、93这些在二叉排序树中是叶子的结点,那是很容易的,毕竟删除它们对整棵树来说,其他结点的结构并未受到影响,如下图所示。
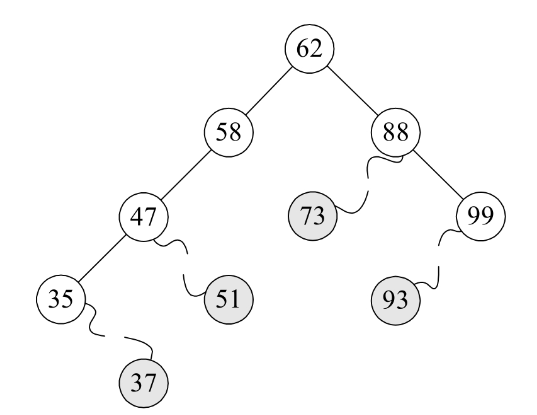
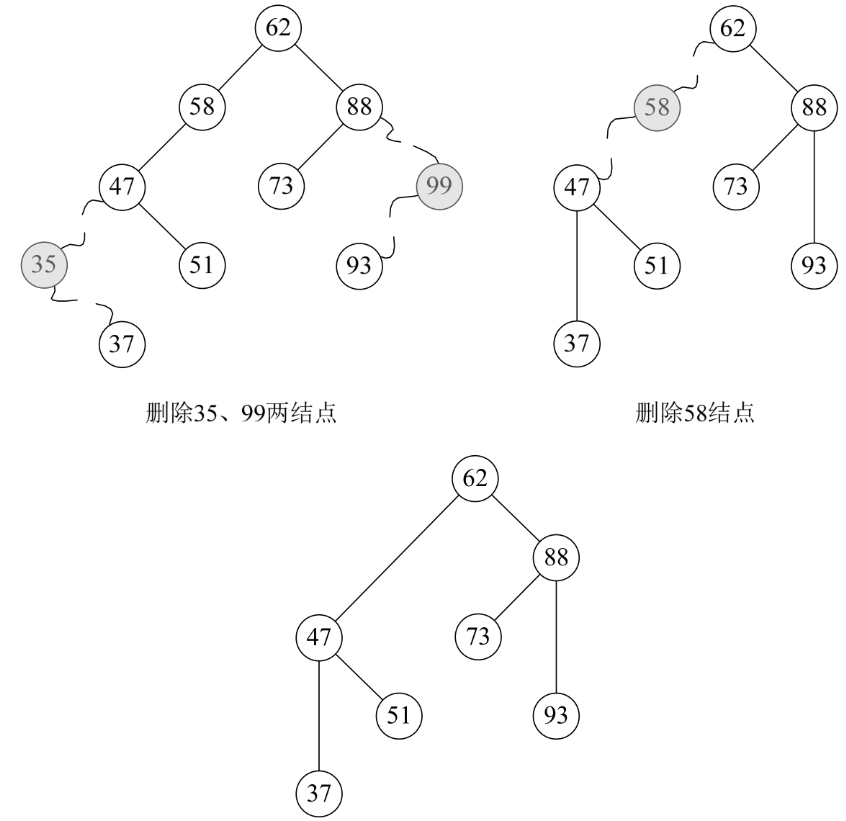
对于要删除的结点只有左子树或只有右子树的情况,相对也比较好解决。那就是结点删除后,将它的左子树或右子树整个移动到删除结点的位置即可,可以理解为独子继承父业。比如下图,就是先删除35和99结点,再删除58结点的变化图,最终,整个结构还是一个二叉排序树。
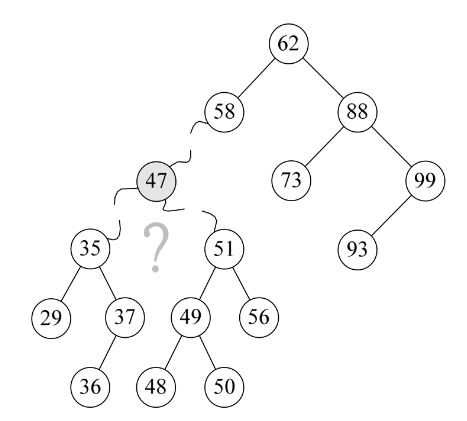
但是对于要删除的结点既有左子树又有右子树的情况怎么办呢?比如下图中的47结点若要删除了,它的两儿子以及子孙们怎么办呢?
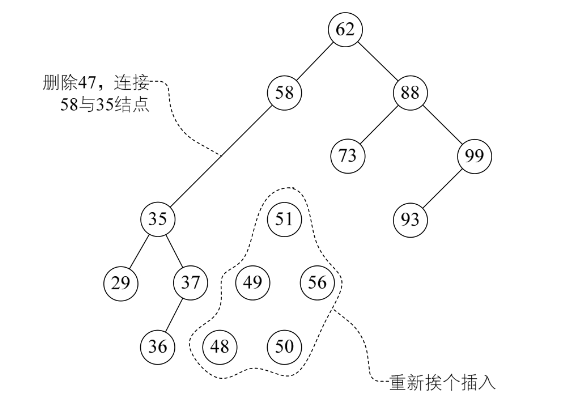
起初的想法,我们让47结点只有一个左子树,那么做法和一个左子树的操作一样,让35及它之下的结点成为58的左子树,然后再对47的右子树所有结点进行插入操作,如图8-6-11所示。这是比较简单的想法,可是47的右子树有子孙共5个结点,这么做效率不高且不说,还会导致整个二叉排序树结构发生很大的变化,有可能会增加树的高度。增加高度可不是个好事,这我们待会再说,总之这个想法不太好。
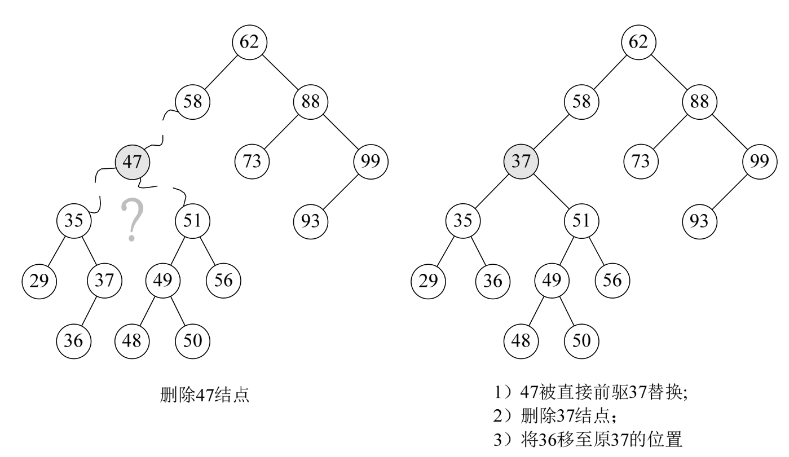
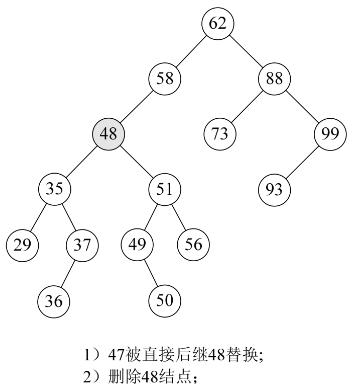
我们仔细观察一下,47的两个子树中能否找出一个结点可以代替47呢?果然有,37或者48都可以代替47,此时在删除47后,整个二叉排序树并没有发生什么本质的改变。
为什么是37和48?对的,它们正好是二叉排序树中比它小或比它大的最接近47的两个数。也就是说,如果我们对这棵二叉排序树进行中序遍历,得到的序列{29,35,36,37,47,48,49,50,51, 56,58,62,73,88,93,99},它们正好是47的前驱和后继。
因此,比较好的办法就是,找到需要删除的结点p的直接前驱(或直接后继)s,用s来替换结点p,然后再删除此结点s,如下图所示。
根据我们对删除结点三种情况的分析:
■ 叶子结点;
■ 仅有左或右子树的结点;
■ 左右子树都有的结点,我们来看代码,下面这个算法是递归方式对二叉排序树T查找key,查找到时删除。

这段代码和前面的二叉排序树查找几乎完全相同,唯一的区别就在于第8行,此时执行的是Delete方法,对当前结点进行删除操作。我们来看Delete的代码。

1.程序开始执行,代码第4~7行目的是为了删除没有右子树只有左子树的结点。此时只需将此结点的左孩子替换它自己,然后释放此结点内存,就等于删除了。
2.代码第8~11行是同样的道理处理只有右子树没有左子树的结点删除问题。
3.第12~25行处理复杂的左右子树均存在的问题。
4.第14行,将要删除的结点p赋值给临时的变量q,再将p的左孩子p->lchild赋值给临时的变量s。此时q指向47结点,s指向35结点,如下图所示。
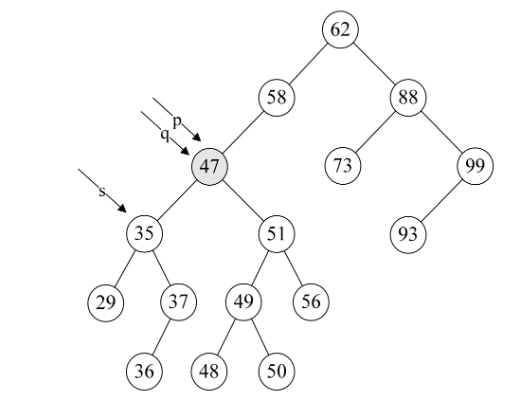
5.第15~18行,循环找到左子树的右结点,直到右侧尽头。就当前例子来说就是让q指向35,而s指向了37这个再没有右子树的结点,如下图所示。
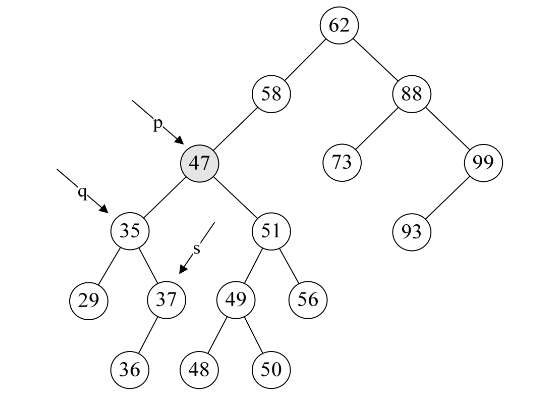
6.第19行,此时让要删除的结点p的位置的数据被赋值为s->data,即让p->data=37,如下图所示。
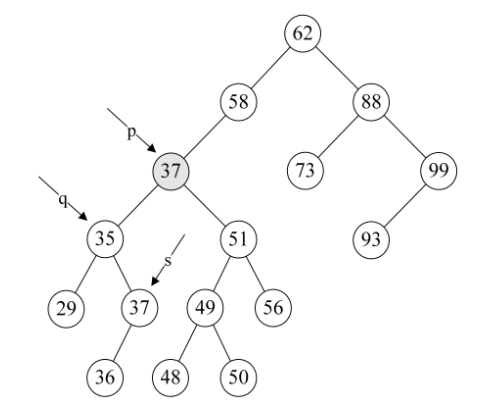
7.第20~23行,如果p和q指向不同,则将s->lchild赋值给q->rchild,否则就是将s->lchild赋值给q->lchild。显然这个例子p不等于q,将s->lchild指向的36赋值给q->rchild,也就是让q->rchild指向36结点,如下图所示。
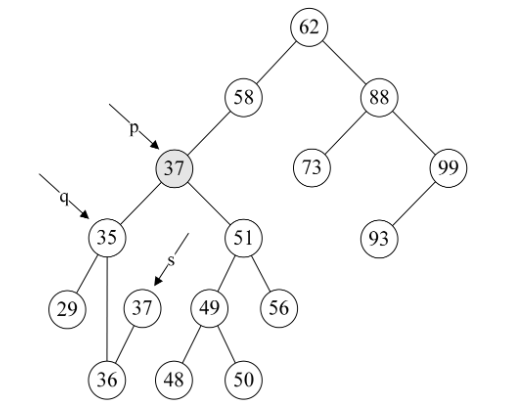
8.第24行,free(s),就非常好理解了,将37结点删除,如下图所示。
从这段代码也可以看出,我们其实是在找删除结点的前驱结点替换的方法,对于用后继结点来替换,方法上是一样的。
从这段代码也可以看出,我们其实是在找删除结点的前驱结点替换的方法,对于用后继结点来替换,方法上是一样的。
5.4 二叉排序树总结
总之,二叉排序树是以链接的方式存储,保持了链接存储结构在执行插入或删除操作时不用移动元素的优点,只要找到合适的插入和删除位置后,仅需修改链接指针即可。插入删除的时间性能比较好。而对于二叉排序树的查找,走的就是从根结点到要查找的结点的路径,其比较次数等于给定值的结点在二叉排序树的层数。极端情况,最少为1次,即根结点就是要找的结点,最多也不会超过树的深度。也就是说,二叉排序树的查找性能取决于二叉排序树的形状。可问题就在于,二叉排序树的形状是不确定的。
例如{62,88,58,47,35,73,51,99,37,93}这样的数组,我们可以构建如下图左图的二叉排序树。但如果数组元素的次序是从小到大有序,如{35,37,47,51,58,62,73,88,93,99},则二叉排序树就成了极端的右斜树,注意它依然是一棵二叉排序树,如下图的右图。此时,同样是查找结点99,左图只需要两次比较,而右图就需要10次比较才可以得到结果,二者差异很大。
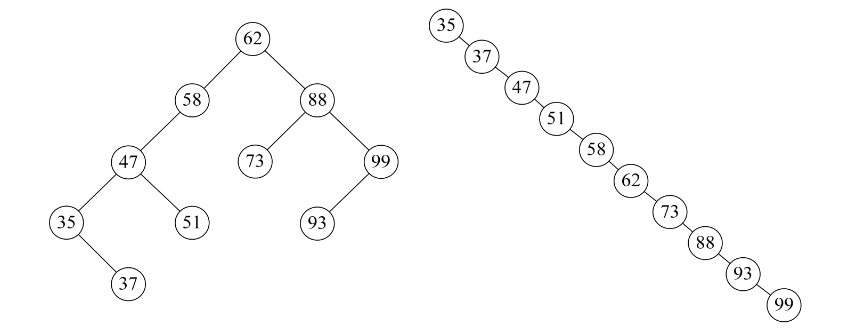
也就是说,我们希望二叉排序树是比较平衡的,即其深度与完全二叉树相同,均为⌊log2n⌋+1,那么查找的时间复杂也就为O(logn),近似于折半查找,事实上,下图的左图也不够平衡,明显的左重右轻。
不平衡的最坏情况就是像下图右图的斜树,查找时间复杂度为O(n),这等同于顺序查找。
因此,如果我们希望对一个集合按二叉排序树查找,最好是把它构建成一棵平衡的二叉排序树。这样我们就引申出另一个问题,如何让二叉排序树平衡的问题。


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









