






目录
习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果
习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果
附加题 6-1P 什么时候应该用GRU? 什么时候用LSTM?
习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
原因
公式:,此时可能存在
,则在计算梯度时有:
为
在第
时刻的输入,则在
时,有:
因此:时,
,故梯度此刻可能爆炸了。
解决方法
- 使用基于门控的循环神经网络;
- 使用更小的U和f(⋅)缓解,尽量让
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果
第t时刻的输入向量:
权重参数:
偏置:
:sigmoid函数
前向传播

反向传播
隐藏状态和
的梯度为:
,
损失函数:
最后时刻时:
从第t+1时刻反向传播到第t时刻:
又有:
因此有:
于是:
LSTM遗忘门值可以选择在[0,1]之间,让LSTM来改善梯度消失的情况。也可以选择接近1,让遗忘门饱和,此时远距离信息梯度不消失。也可以选择接近0,此时模型是故意阻断梯度流,遗忘之前信息。
习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果
GRU将三门变两门:更新门,重置门
,单元状态
与输出
合并为一个状态
前向传播

反向传播
参考:人人都能看懂的LSTM介绍及反向传播算法推导(非常详细) - 知乎

t时刻其它节点的梯度:
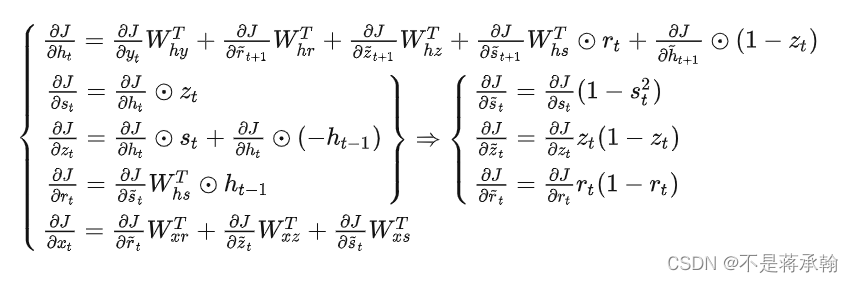
对参数的梯度:

GRU它引⼊了重置⻔(reset gate)和更新⻔(update gate) 的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。
附加题 6-1P 什么时候应该用GRU? 什么时候用LSTM?
LSTM与GRU二者结构十分相似,不同在于:
新的记忆都是根据之前状态及输入进行计算,但是GRU中有一个重置门控制之前状态的进入量,而在LSTM里没有类似门;
产生新的状态方式不同,LSTM有两个不同的门,分别是遗忘门(forget gate)和输入门(input gate),而GRU只有一种更新门(update gate);
LSTM对新产生的状态可以通过输出门(output gate)进行调节,而GRU对输出无任何调节。
GRU的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。
LSTM更加强大和灵活,因为它有三个门而不是两个。
心得体会
因为自己的数学功底比较差,这次作业的推导感觉很迷茫很吃力,同时也借鉴了很多其他人的文章,再结合上次BPTT的作业才勉强完成了这次的作业。但是期末考试在下学期,还有很长时间去复习,不必感到着急。















 1632
1632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









