







 前言紧接前文我们学习了Redis中Hash结构。在里面我们梳理了字典这个重要的内部结构并分析了hash结构rehash的流程从而解释了为什么redis单线程还是那么快本章节我们将视角下推,继续学习Redis五大天王中的zset数据结构 ; zset是有序不重复集合其内部元素唯一且是有序的,他的排序标准是根据其内部score维度进行排序的。zset结构基本单元关于zset结构很简单,一个是我们之前学习的字典结构(简单理解成Hash结构),另外一个是跳跃表结构 ; 关于字典我们上一章节已经详细
前言紧接前文我们学习了Redis中Hash结构。在里面我们梳理了字典这个重要的内部结构并分析了hash结构rehash的流程从而解释了为什么redis单线程还是那么快本章节我们将视角下推,继续学习Redis五大天王中的zset数据结构 ; zset是有序不重复集合其内部元素唯一且是有序的,他的排序标准是根据其内部score维度进行排序的。zset结构基本单元关于zset结构很简单,一个是我们之前学习的字典结构(简单理解成Hash结构),另外一个是跳跃表结构 ; 关于字典我们上一章节已经详细
前言
- 紧接前文我们学习了
Redis中Hash结构。在里面我们梳理了字典这个重要的内部结构并分析了hash结构rehash的流程从而解释了为什么redis单线程还是那么快 - 本章节我们将视角下推,继续学习
Redis五大天王中的zset数据结构 ;zset是有序不重复集合其内部元素唯一且是有序的,他的排序标准是根据其内部score维度进行排序的。
zset结构
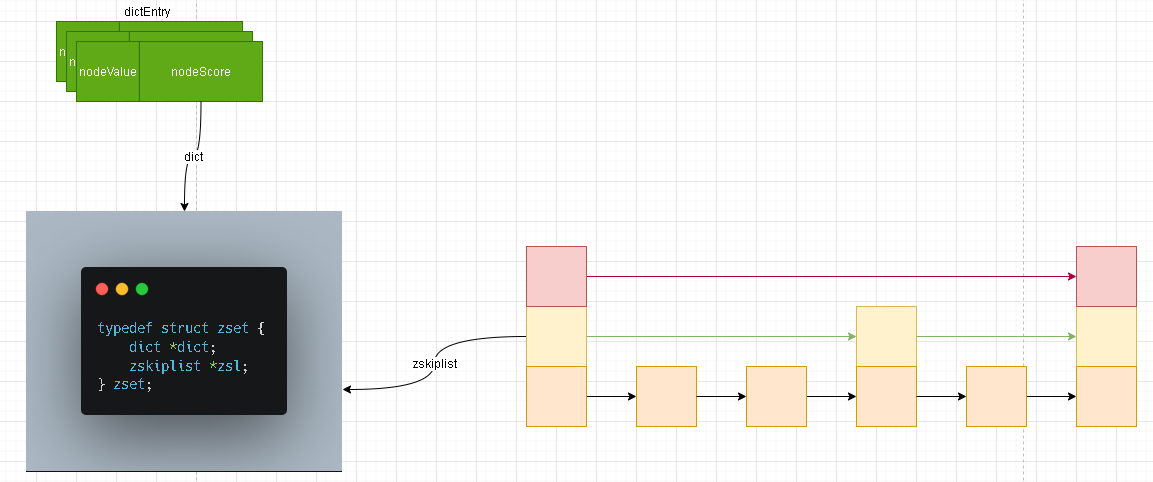
基本单元
- 关于zset结构很简单,一个是我们之前学习的字典结构(简单理解成Hash结构),另外一个是跳跃表结构 ; 关于字典我们上一章节已经详细解说了其内部的构造及其如何进行数据扩容等操作!剩下的且符合今天我们学习主旨的自然就是这个熟悉又陌生的
zskiplist。 - 我们根据上面zset的结构图也能够看出来,zskiplist实际上就是一个链表。
zskiplist

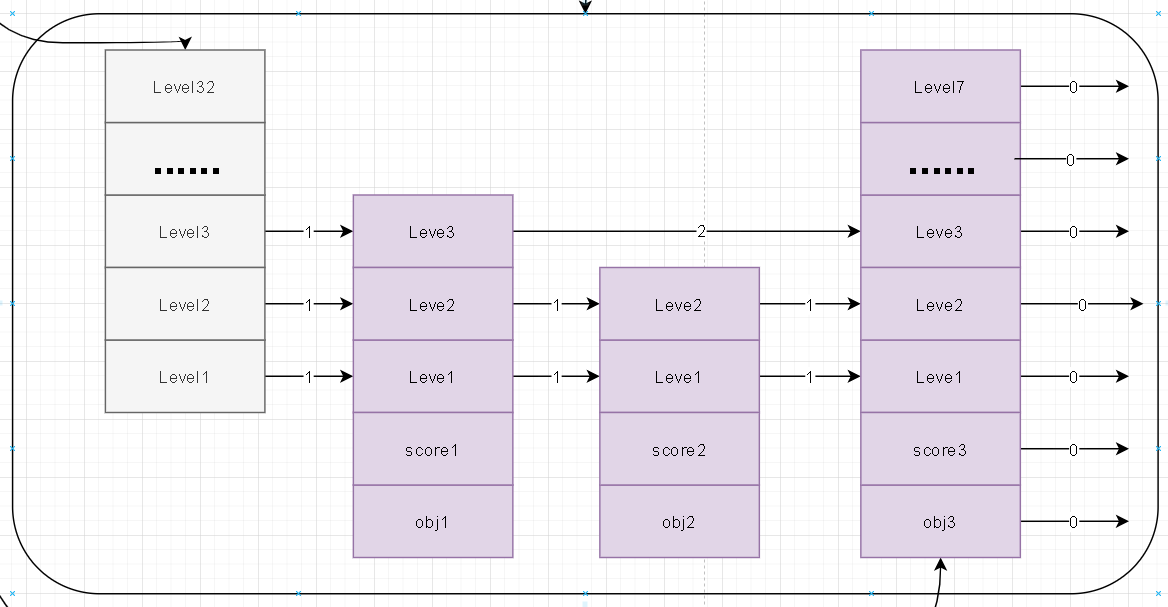
- 我们查看源码不难看出其内部结构是对zset中链表的一个抽象描述。zskiplist首先会对这个链表记录其头结点、尾结点方便通过zskiplist进行遍历操作。剩下的length自然就是对内部的这个链表数量的统计。比较抽象的是这个level的理解。在上面我们也看到了zskiplist那个链表实际上会有分层的概念。笔者这里通过不同的颜色进行表述不同层级的概念。
- 笔者这里针对上述描述的跳跃表内部的zskiplist绘画了一张内部数据图
- 在对zskiplist结构描述和数据描述中我将他们拆开理解,觉得这样更容易理解结构关系。下面是整个图示
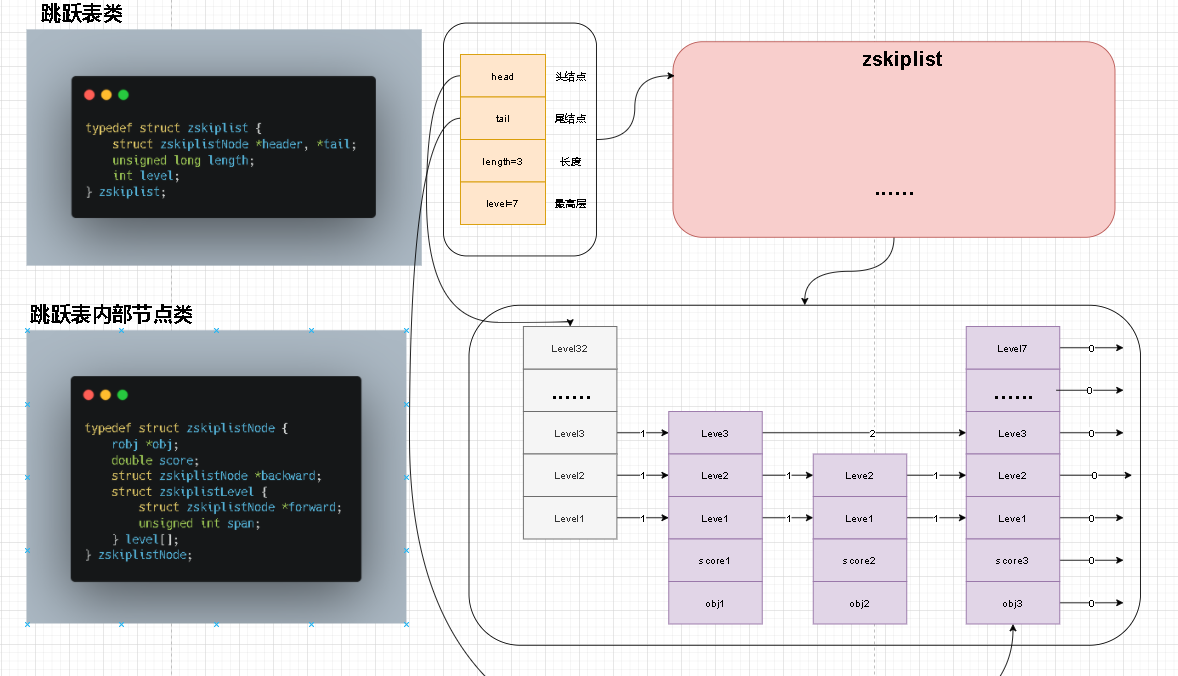
- 细心的读者应该能够发现,我好想漏掉了链表重要组成部分
zskiplistNode这个重要的节点说明。实际上他就是我们右侧那个链表中节点。换句话说链表中每个点就是zskiplistNode 。
level
- 跳跃表的重要特性类型与树结构可以避免逐个遍历的苦恼。那么他是如何实现这种跳跃性质的访问的呢?还有一点为什么redis会这么设计。首先我们先回答下为什么这么设计。在链表中插入、删除等操作是很快速的只需要改变指针指向就可以完成。但是对于查询来说他需要遍历整个链表才能完成操作。针对链表的这个弊端redis设计了跳表的数据结构。
- 下面就是针对如何实现来简单梳理下。上述zskiplistNode节点对象结构中我们也可以看到有个level属性。redis就是通过这个属性来实现跳跃的特性。在每个节点生成的时候回随机生成这个level值。他就表示这个节点所在层的范围。
- 关于这个level为什么说是随机。这有牵涉到其内部的幂等性算法。这个算法保证数字越大生成的概览越小。在redis内部level最大值32.
- 比如说level随机生成5 。 表示当前节点node在level1~level5这五层中。上面的图示中所示的三个节点生成的level值分别是level3、level2、level7。注意在实际存储中level索引时从0开始。
forward
- 在level中还有两个属性分别是前进指针、跨越长度。根据字面意思我们能够理解前进指针是想链表后端方向推进的指针。其跨度就是表示当前节点距离前进指针处节点的距离。这个距离的是参考最底层的距离的。
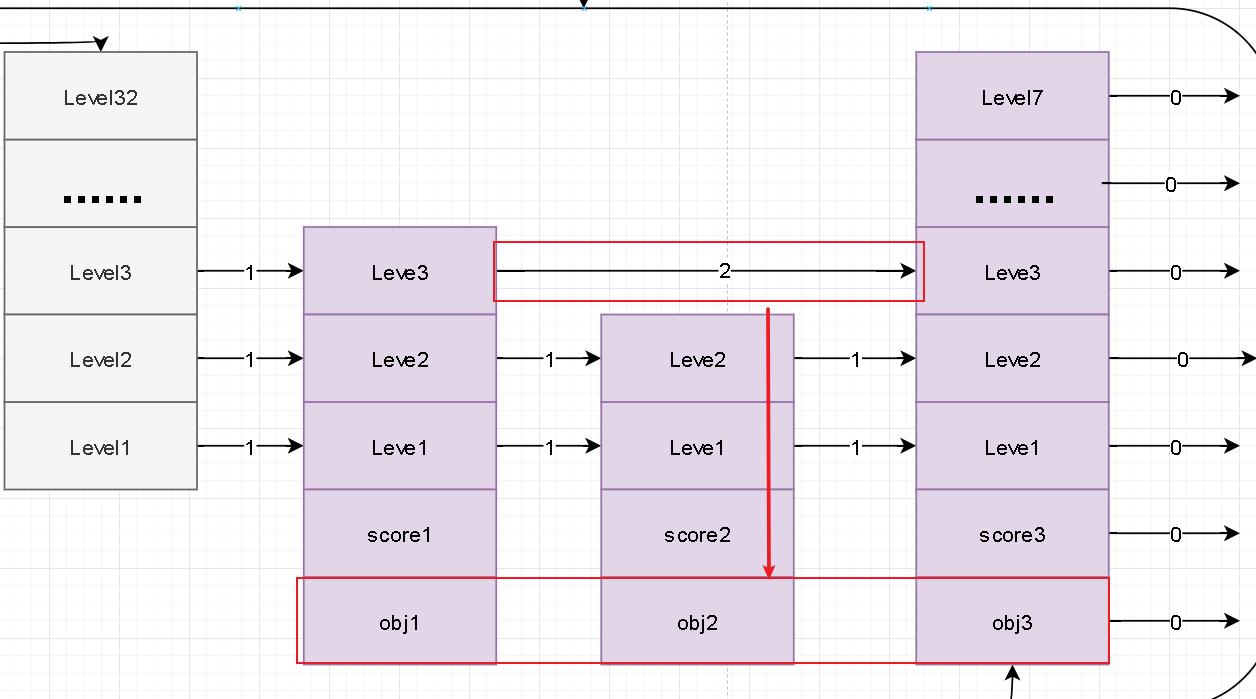
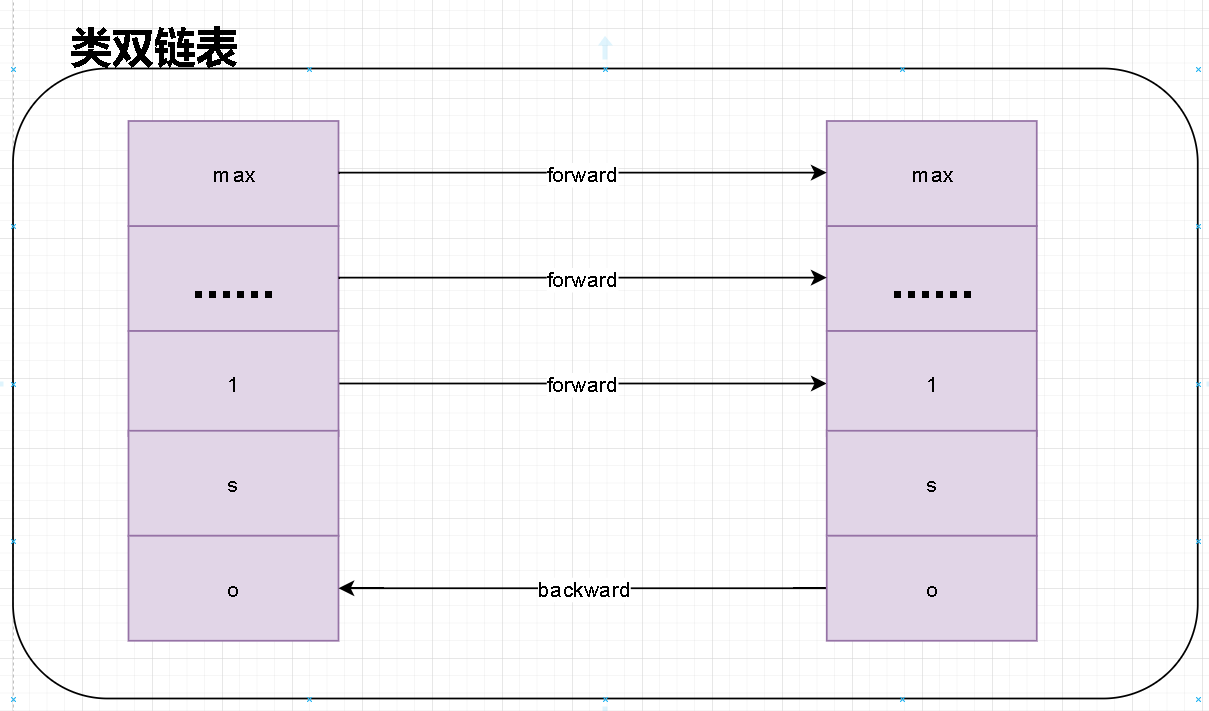
双链表
- 在zskiplist中每一层都是一个单向链表。在level中通过forwar指针指向我们表尾。那么为什么我说是双链表呢?这里的双链表不是严格意义的双链表。但是我们可以借助这些层级的单链表实现我们双向自由路由。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









