




 本文是关于Python机器学习的详细笔记,涵盖了机器学习的基本概念,包括人工智能、深度学习的关系,机器学习算法分类,特征工程的各个环节,如数据集划分、特征抽取、预处理和降维,以及分类算法如KNN、朴素贝叶斯、决策树和随机森林。此外,还讨论了回归和聚类算法,如线性回归、岭回归、逻辑回归、K-means等,以及模型评估和调优的方法。
本文是关于Python机器学习的详细笔记,涵盖了机器学习的基本概念,包括人工智能、深度学习的关系,机器学习算法分类,特征工程的各个环节,如数据集划分、特征抽取、预处理和降维,以及分类算法如KNN、朴素贝叶斯、决策树和随机森林。此外,还讨论了回归和聚类算法,如线性回归、岭回归、逻辑回归、K-means等,以及模型评估和调优的方法。
Python机器学习笔记
一 机器学习概述
1.1 人工智能概述
1.1.1 机器学习与人工智能、深度学习关系
-
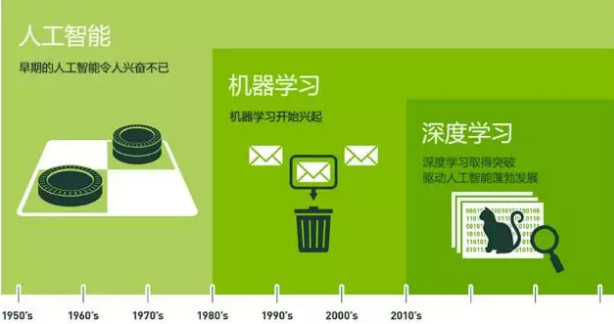
机器学习和人工智能、深度学习的关系
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
-
达特茅斯会议(Dartmouth Conferences)- 人工智能的起点
1956年,几个计算机科学家相聚在达特茅斯会议(Dartmouth Conferences),提出了“人工智能”的概念。
1.1.2 机器学习、深度学习能够做什么
机器学习应用场景非常多,可以说渗透到各行各业。医疗、航空、教育、物流、电商等等领域的各种场景。
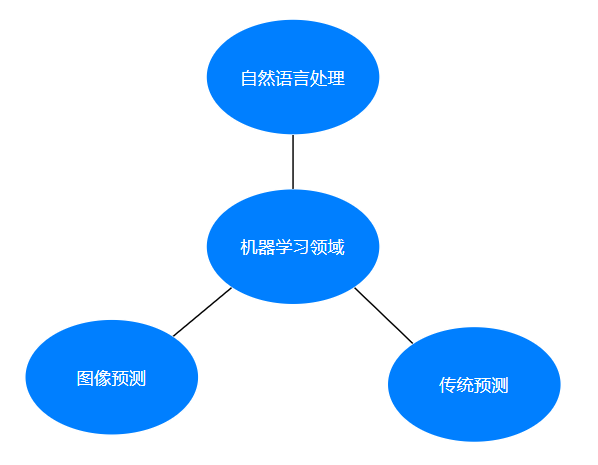
- 用在挖掘、预测领域:
- 应用场景:店铺销量预测、量化投资、广告推荐、企业用户分类…
- 用在图像领域:
- 应用场景:街道交通标志检测、人脸识别等等
- 用在自热语言处理领域:
- 应用场景:文本分类、情感分析、自动聊天、文本检测等等。
当前重要的是掌握一些机器学习算法等技巧,从某个行业切入解决问题。
1.2 什么是机器学习
1.2.1 定义
机器学习:是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
1.2.2 数据集构成
- 结构:特征值+目标值
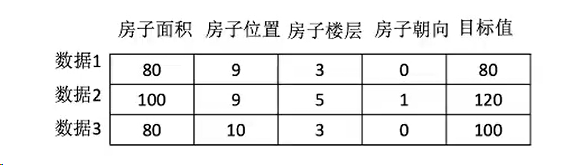
注释:
- 对于每一行数据我们称为样本。
- 有些数据可以没有目标值:

1.3 机器学习算法分类
1.3.1 监督学习
-
分类问题:有目标值,判断类别

-
回归问题:有目标值,连续型的数据

1.3.2 无监督学习
- 无监督学习:无目标值
1.4 机器学习开发流程
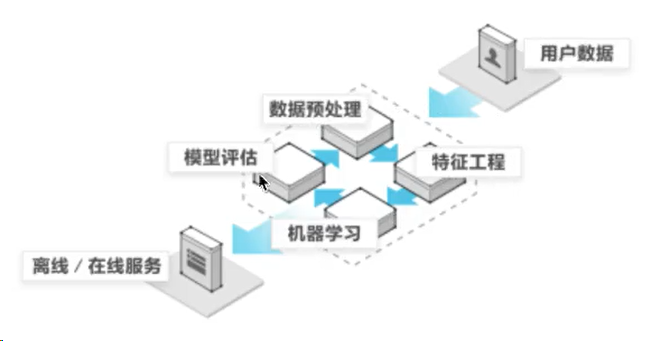
机器学习开发流程:
- 获取数据
- 数据处理
- 特征工程
- 机器学习算法训练 — 模型
- 模型评估
- 应用
1.5 学习框架和资料介绍
明确几点:
- 算法是核心,数据和计算是基础
- 找准定位
大部分的算法都有专有的算法工程师在做,而我们只要:
- 分析很多的数据
- 分析具体的业务
- 应用常见的算法
- 特征工程、调参数、优化
机器学习库和框架:

二 特征工程
2.1 数据集
- 目标:
- 知道数据集分为训练集和测试集
- 会使用sklearn的数据集
- 应用:
- 无
2.1.1 可用数据集
1、Scikit-learn工具介绍

- Python语言的机器学习工具
- Scikit-learn包括了许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 最新稳定版本0.24
2、安装
conda install -c conda-forge scikit-learn
3、Scikit-learn包含的内容
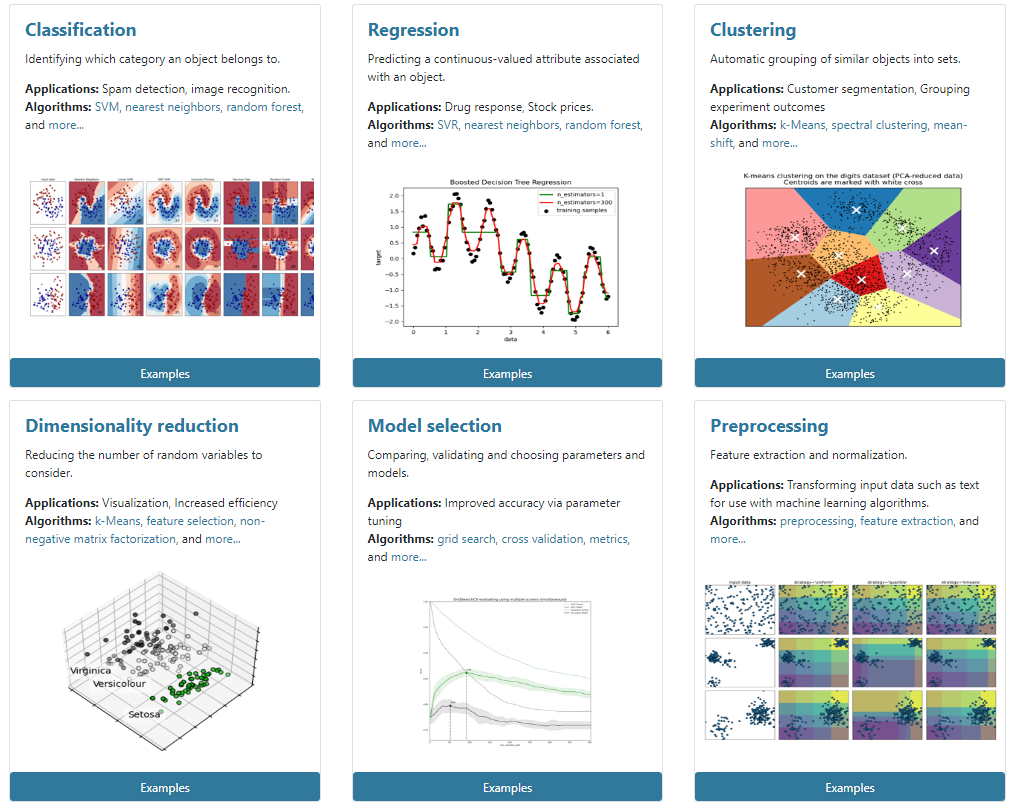
2.1.2 sklearn数据集
1、scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行的数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录。
2、sklearn数据集返回
- load和fetch返回的数据类型datasets.base.Bunch(字典格式)
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
# 获取数据
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值:\n", iris.data, iris.data.shape)
return None
2.1.3 数据集划分
机器学习一般的数据集会划分为两部分:【数据集结构:特征值和目标值】
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验的时候使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 90%
- 测试集:30% 20% 10%
数据集划分api
- sklearn.model_selection.train_test_split(arrys,*options)
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
# 获取数据
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值:\n", iris.data, iris.data.shape)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
2.2 特征工程介绍
学习目标:
- 了解特征工程在机器学习中的重要性
- 知道特征工程的分类
2.2.1 为什么需要特征工程(Feature Engineering)
业界广泛流传:数据和特征决定了机器学习的上线,而模型和算法只是逼近这个上线而已。
2.2.2 什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:直接影响机器学习的效果
2.2.3 特征工程的位置与数据处理的比较

- pandas:一个读取数据方便和基本处理数据格式的工具
- sklearn:对于特征处理提供了强大的接口
2.3 特征抽取
目标:
- 应用DictVectorizer实现对类别特征进行数值化、离散化
- 应用CountVectorizer实现对文本特征进行数值化
- 应用TfidfVectorizer实现对文本特征进行数值化
- 区分两种文本特征提取的区别
2.3.1 特征提取
1、将任意数据(如文本或图像)转换成可用于机器学习的数字特征
注:特征值化是为了计算机更好的理解数据
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取
2、特征提取API
sklearn.feature_extraction
2.3.2 字典特征提取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorizer(…)
事例:
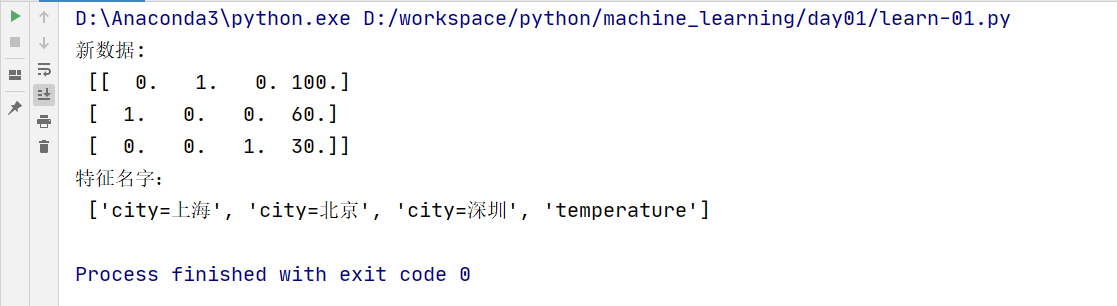
def dict_demo():
"""
字典特征抽取
:return:
"""
data = [{'city': "北京", 'temperature': 100}, {'city': "上海", 'temperature': 60}, {'city': "深圳", 'temperature': 30}]
# 1.实例化一个转换器
# sparse 表示稀疏矩阵:只返回有值的位置,不返回0值
transfer = DictVectorizer(sparse=False)
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
print("新数据:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None
执行结果:
2.3.3 文本特征提取
1、作用:对文本数据做特征值化
- sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回词频矩阵
- CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代的对象,返回值sparse矩阵
- CountVectorizer.inverse_transform(X) X:array数组或sparse矩阵 返回值:转换前的数据格式
- CountVectorizer.get_feature_names() 返回单词列表
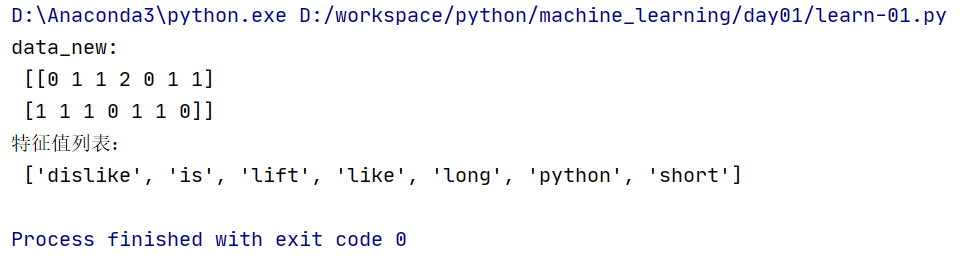
def count_demo():
"""
文本特征提取
:return:
"""
data = ["lift is short,i like like python", "lift is long,i dislike python"]
# 1.实例化一个转换器
transfer = CountVectorizer()
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征值列表:\n", transfer.get_feature_names())
return None
2、运行结果
3、中文提取事例,注:因为中文词语之间没有空格分割,程序不能识别单个词,需要使用空格分割,之后会使用分词器,这里先手动分割验证。
def count_chinese_demo():
"""
中文文本特征提取
:return:
"""
data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]
# 1.实例化一个转换器
transfer = CountVectorizer()
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征值列表:\n", transfer.get_feature_names())
return None
4、中文提取:使用jieba分词器自动分词
def count_chinese_demo2():
"""
中文文本特征提取,自动分词
:return:
"""
data = ["所谓的培训讲师,实则为一名感染新冠的个体营销职业人员。就是他,一个人传染了102个人,其中年龄最大的出生于1933年。",
"发布会上,吉林省市场监管部门相关负责人表示,目前两地相关部门已经开展了联合调查,如有违法违规行为将进行严厉处罚。",
"疫情防控大局当下,医护工作者仍然紧裹厚重的防护服,在前线与病毒奋勇厮杀,社区志愿者依旧冒寒风瑟瑟立于居民楼下“站岗守家”,可是竟有人在这个时候,举办“养生培训活动”推销产品,将老年人置于新冠病毒感染的“风口”,虽然打着关爱老年人健康的旗号,却无异于图财致命!"]
# 分词
data_new = []
for item in data:
data_new.append(" ".join(list(jieba.cut(item))))
# 1.实例化一个转换器
transfer = CountVectorizer(stop_words=["102", "1933", "一个"])
# 2.调用fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征值列表:\n", transfer.get_feature_names())
return None
运行结果:

引出问
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









