







知识点回顾:
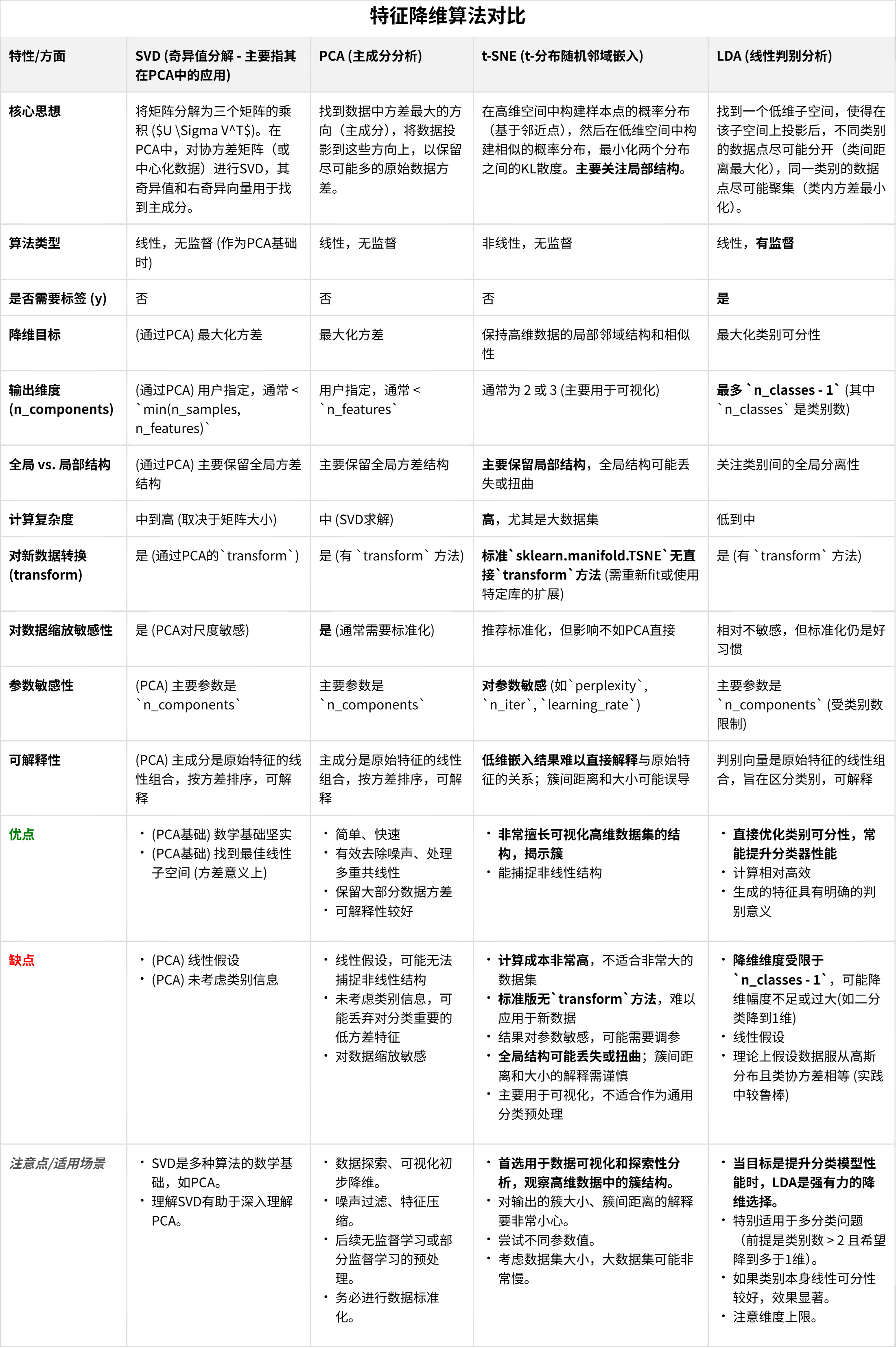
1.LDA线性判别
2.PCA主成分分析
3.t-sne降维
还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说
作业:
自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可视化的区别。
LDA线性判别
PCA主成分分析
t-sne降维
降维技术的应用场景与主要用途
降维技术广泛应用于多个领域,尤其是在数据分析、机器学习和数据可视化中扮演着重要角色。通过减少数据的维度,不仅可以降低计算复杂度,还能帮助揭示隐藏在高维数据中的结构和模式1。
应用场景
数据预处理:在构建机器学习模型之前,降维可以去除冗余特征并提高模型性能。
数据压缩:通过保留最重要的信息来减小存储需求和传输成本。
噪声过滤:某些降维方法可以帮助消除无关变量带来的干扰。
可视化:将高维数据投影到二维或三维空间以便于人类理解。
t-SNE 和 PCA 的可视化效果对比
尽管两者都属于降维工具,但它们的设计目标和技术特点差异显著:
主要区别
PCA(Principal Component Analysis, 主成分分析)
基于线性变换,寻找方差最大的方向以最大化信息量保持率3。
更适合捕捉全局几何特性,在低噪音环境下表现出色。
t-SNE(t-Distributed Stochastic Neighbor Embedding, t分布随机邻域嵌入)
使用非线性的概率分布建模相似性,专注于局部结构而非整体形状2。
能够更好地反映样本间的簇状关系,尤其擅长处理复杂的非线性边界。
可视化表现
对于像 MNIST 手写数字这样的典型例子,PCA 往往倾向于展示较为模糊的整体趋势;而 t-SNE 则能清晰地区分各个类别形成紧凑且分离良好的群组3。然而需要注意的是,由于 t-SNE 过程引入了一定程度的随机性和敏感参数调整依赖性强等问题,可能导致重复运行结果不完全一致。
import numpy as np
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
digits = load_digits()
X, y = digits.data, digits.target
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='tab10')
plt.title('PCA Visualization')
plt.subplot(1, 2, 2)
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='tab10')
plt.title('t-SNE Visualization')
plt.show()@浙大疏锦行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









