







 Hadoop MapReduce是一种分布式计算框架,通过Map和Reduce函数处理大规模数据。它将数据集拆分成小任务并行计算,然后通过Reduce阶段汇总结果,简化了大数据处理过程。MapReduce具有易编程、良好扩展性和高容错性,适用于离线数据处理,但不适用于实时或流式计算。在MapReduce程序中,数据以
Hadoop MapReduce是一种分布式计算框架,通过Map和Reduce函数处理大规模数据。它将数据集拆分成小任务并行计算,然后通过Reduce阶段汇总结果,简化了大数据处理过程。MapReduce具有易编程、良好扩展性和高容错性,适用于离线数据处理,但不适用于实时或流式计算。在MapReduce程序中,数据以Hadoop MapReduce是一种用于处理大数据的编程模型。它将数据集切分成多个小任务,每一个小任务都可以通过独立的计算来完成,最终的结果可以通过合并或更新数据来进行聚合。Hadoop MapReduce极大地简化了处理大数据的过程,因为它可以同时进行多个计算任务,并且可以快速地进行计算结果的合并和更新。
1. MapReduce的思想很好理解,关键在于如何基于这 个思想设计出一款分布式计算程序?
2. 下面看看Hadoop团队针对MapReduce的设计构思是怎样的?这决定了你将如何使用MapReduce?
(1)如何对付大数据处理场景
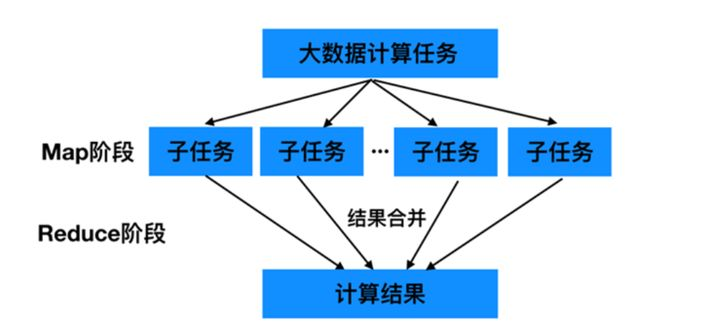
⚫ 对相互间不具有计算依赖关系的大数据计算任务,实现并行最自然的办法就是采取MapReduce分而治之的策略。
⚫ 首先Map阶段进行拆分,把大数据拆分成若干份小数据,多个程序同时并行计算产生中间结果;然后是Reduce聚合阶段,通过程序对并行的结果进行最终的汇总计算,得出最终的结果。
⚫ 不可拆分的计算任务或相互间有依赖关系的数据无法进行并行计算!
(2)构建抽象编程模型
⚫ MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
map: 对一组数据元素进行某种重复式的处理;
reduce: 对Map的中间结果进行某种进一步的结果整理。

⚫ MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → (k2; v2)
reduce: (k2; [v2]) → (k3; v3)
⚫ 通过以上两个编程接口,大家可以看出MapReduce处理的数据类型是<key,value>键值对。
(3)统一架构、隐藏底层细节
⚫ 如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
⚫ MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to
do)分开了,为程序员提供一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 466
466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









