







hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Hive是一个翻译器:SQL ---> Hive引擎 ---> MapReduce程序
Hive工作原理

- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL优化,再转换为物理的计划(MapReduce)。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给ResourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。
Hive一些基本操作
1.须知命令
(1)在hive中输入! pwd;可查看当前所在位置,! ls;可以查看所在位置的文件列表。
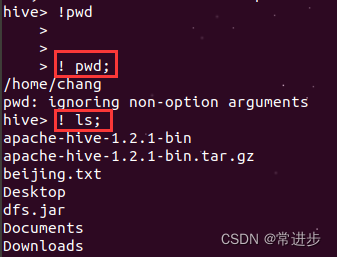
(2) 也可以实现hdfs的操作,不用在前面加hdfs.
dfs -ls /;
dfs -cat /salary.txt2.一些查看命令
#1.查看或显示数据库
show databases;
#2.创建数据库(也可以先判断,不存在则创建)
create database t1;
create database if not exists t2;
#3.查看某数据库的表
show tables;
#4.创建一个表(方法1)
create table emp(id int,name string,job string,
birth string,salary int,dep int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
#5.查看表结构
desc emp;
#6.查看表信息,包括创表语段
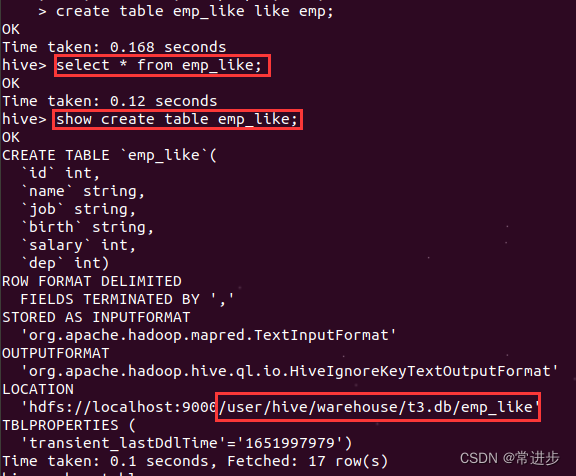
show create table emp;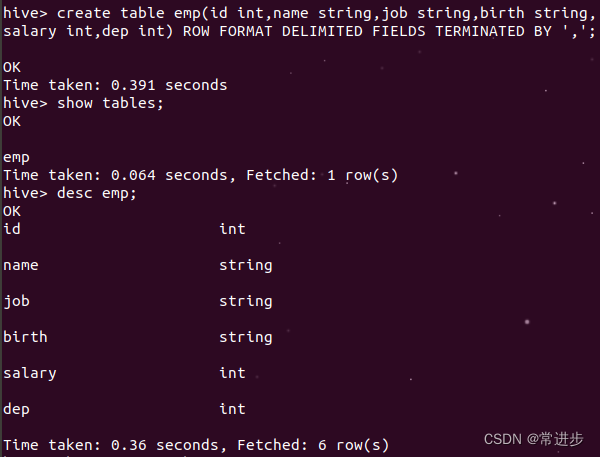

由上图,我们可以知道emp这个表存放的位置,可以通过dfs -ls /user/hive/warehouse/t3.db;
进行查看。
3.加载数据
可通过select * from emp;查看数据内容
#加载数据,若要加载的数据是在本地路径,则需要加LOCAL,INPATH后面需要加上数据的路径
#OVERWRITE表示覆盖,若表emp里面有数据,则会进行覆盖,不加OVERWRITE表示追加;
#没有数据的话加不加OVERWRITE都不影响。
LOAD DATA [LOCAL] INPATH '/home/hadoop/salary.txt' [OVERWRITE] INTO TABLE emp;4.创建表的其他形式
#通过like实现,在原有表的基础上创建表
create table emp_like like emp;
select * from emp_like;
show create table emp_like;(1)通过like创建表,可以发现表的内容为空,但是表结构是一样的,并且都放在同一个数据库下。
(2)通过as创建表,与like相比,在查看创表语段时,发现没有DELIMITED来进行符号分隔,
并且和emp都在同一个数据库下,用dfs -ls /user/hive/warehouse/t3.db/emp_as;查看可知数据内容在emp_as再往下一个文件里,并且中间没有明确符号进行分割。
#用as创建表,也是在原有表的基础上进行选择指定创建的内容
create table emp_as as select id,name,job from emp;
select * from emp_as;
show create table emp_as;
dfs -ls /user/hive/warehouse/t3.db/emp_as;
dfs -cat /user/hive/warehouse/t3.db/emp_as/000000_0;
5.在空表中插入数据
可以一行一行插,也可以插入其他表的全部数据。
#在表emp_like里插入一条数据,必须列数对应
insert into emp_like values(001,'aaa','bbb','2002/10/10',1230,10);
#插入表emp的全部数据
insert into emp_like select * from emp;
6.筛选操作
注意:select语句总体执行顺序:
1.from语句----2.where语句----3.group by语句((开始使用select中的别名,后面的语句中都可以使用))----4.having语句----5.select语句----6.order by语句
#1.从表emp_like中选择薪资大于2000的,属性并全部输出
select * from emp_like where salary>2000;
#2.从表emp_like中对部门进行分组,并输出部门和每个部门各自的薪资总和
select dep,sum(salary) from emp_like group by dep;
#3.从表emp_like中对部门进行分组,使用having字句,对分组后的结果进行筛选
#筛选出每个部门各自的薪资总和大于3775的,并输出符合条件的部门和每个部门各自的薪资总和
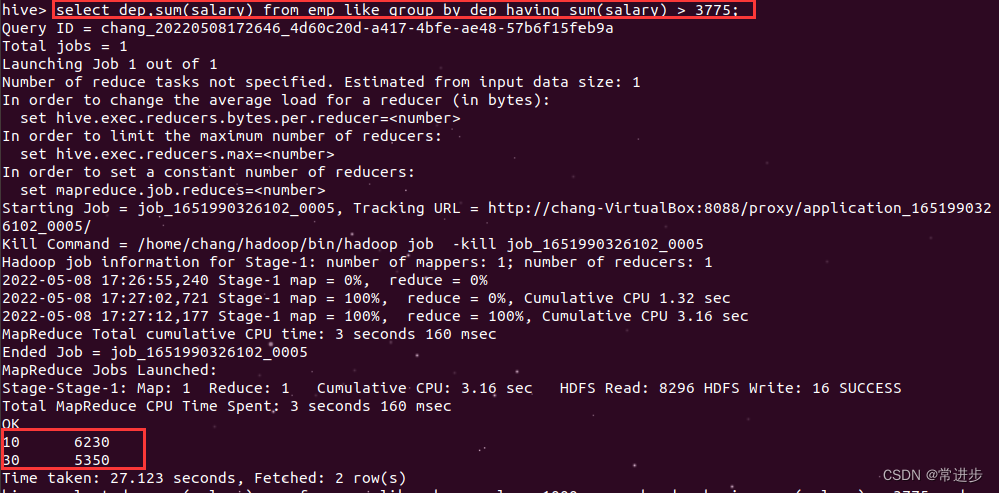
select dep,sum(salary) from emp_like group by dep having sum(salary) > 3775;
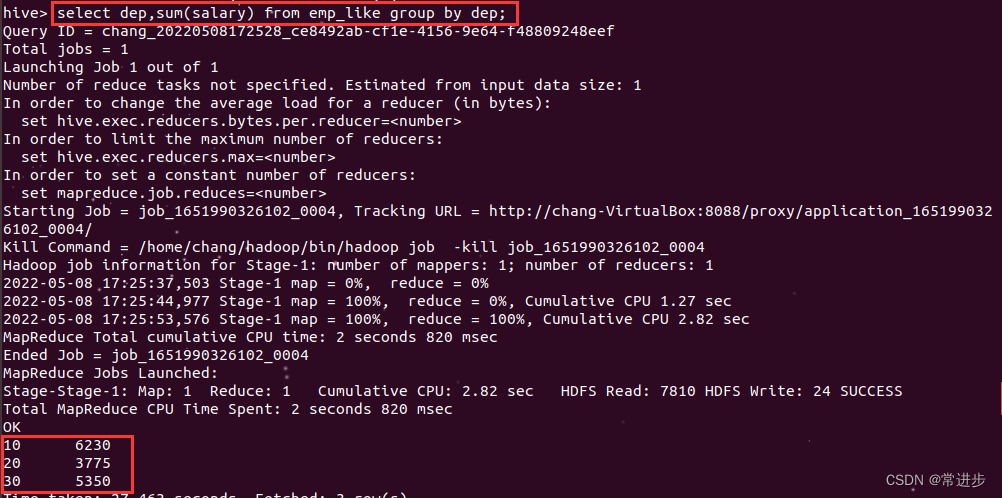
#4.从表emp_like中选出薪资大于1000的,通过部门进行分组,筛选出分组后每个部门薪资总和大于3775的,
并选择输出dep和每个部门薪资和,此时可以将输出结果重命名,最后用该重命名进行升序输出。
select dep,sum(salary) sum from emp_like where salary>1000 group by dep
having sum(salary) > 3775 order by sum limit 2;结果如下面展示:


















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











