







目录
RedisObject
Redis中任意数据类型的key和value都会被封装成一个RedisObject对象。其源码如下:
//server.h
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;redisObject的成员变量的含义如下图所示:

为什么要对底层的数据结构进行一层包装?
通过封装, 可以根据对象的类型动态地选择存储结构和可以使用的命令, 实现节省空间和优化查询速度。
Redis的编码方式
根据存储的数据类型的不同,Redis会选择不同的编码方式,共包含11中不同类型。
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */ //raw编码动态字符串
#define OBJ_ENCODING_INT 1 /* Encoded as integer */ //long类型的整数
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */ //hash表(字典dict)
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ //编码为zipmap,已废弃
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ //双端链表,在数据量少使用,这是旧版的编码方式
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ //压缩列表
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ //整数集合
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ //跳表
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ //embstr的动态字符串
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ //快速列表
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */ //stream流对外可见的5种数据结构
结构体redisObject中的变量type就是对外可见的数据类型,有string,hash,list,set和zset 5种。
Redis中会根据存储的数据类型不同,会选择不同的编码方式。用string来举个例子。

同样是存储string,其编码方式就会有不同。下图是每种结构类型会使用到的编码方式。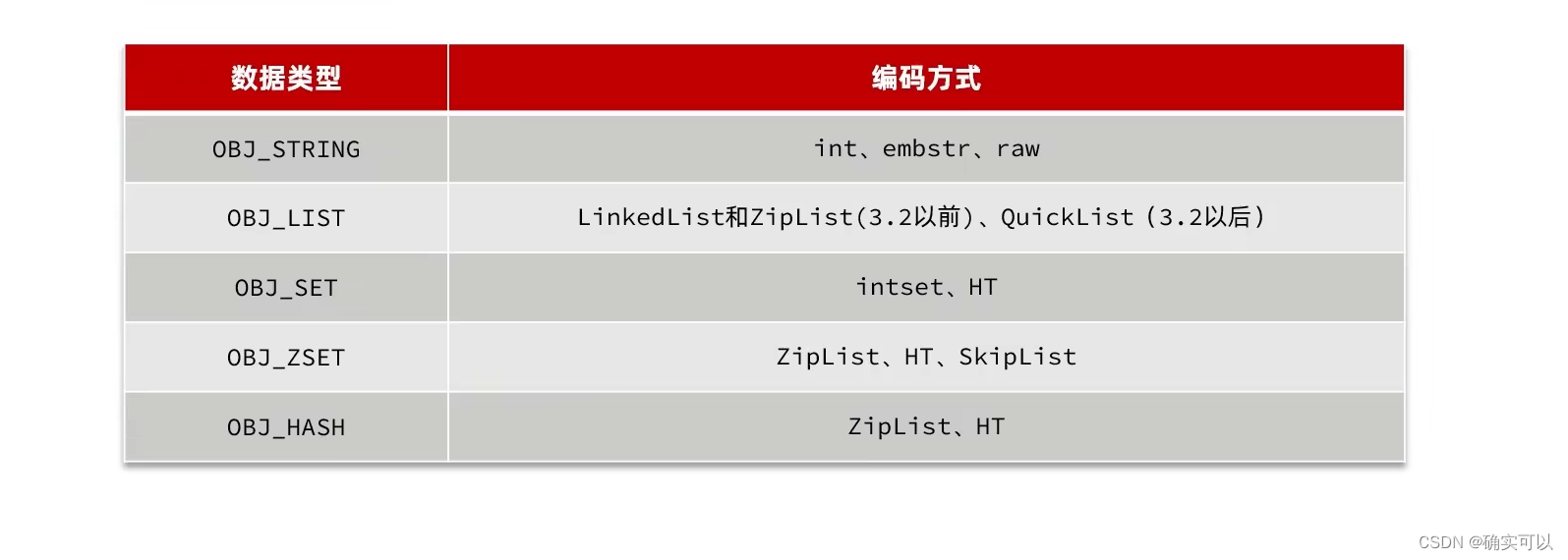
1.string
Redis中key和字符串类型的value最大限制均为512mb,key均是string类型。
string是Redis中最常见的数据存储类型:
- 其基本编码方式是raw,这是基于简单动态字符串(SDS)实现的。
- 若存储的SDS长度小于44字节,则会采用embstr编码,此时的object head与SDS是一段连续空间。
- 存储的字符串是整数值,并且大小在LONG_MAX范围捏,则会采用int编码,直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS。
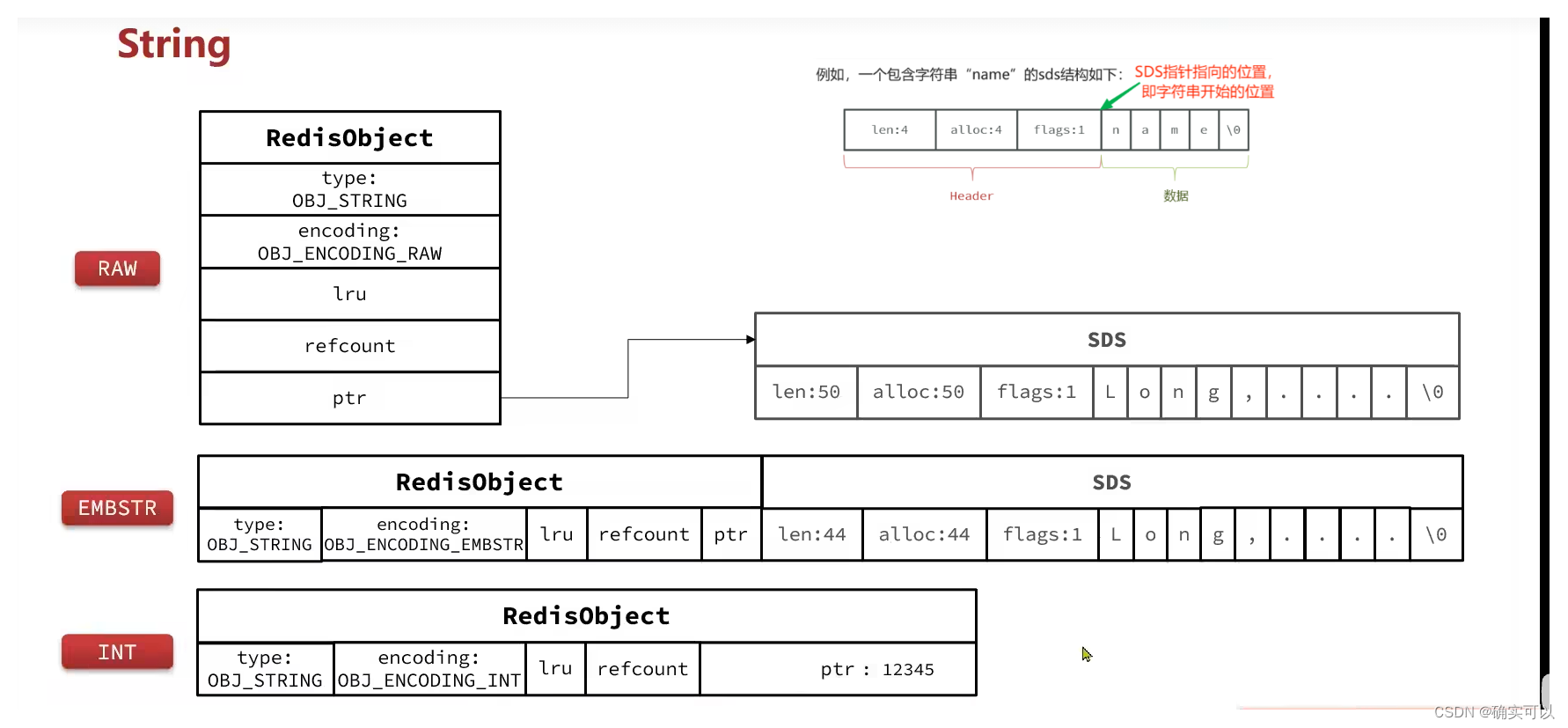
string结构的源码
从string结构插入元素的代码入手:
/* SET key value [NX] [XX] [KEEPTTL] [GET] [EX <seconds>] [PX <milliseconds>]
* [EXAT <seconds-timestamp>][PXAT <milliseconds-timestamp>] */
//结构体client的变量argv是个数组,元素是robj*。所以客户端输入的数据是已经封装成redisObject结构体的了
//比如输入 set name jack,那name,jack都会封装成redisobject结构,name的赋值给c->argv[1],jack的会赋值给c->argv[2]
void setCommand(client *c) {
robj *expire = NULL;
int unit = UNIT_SECONDS;
...............................
//尝试对字符串对象进行编码以节省空间,若字符串是整数的话,就进行编码转换
c->argv[2] = tryObjectEncoding(c->argv[2]);
...........................
}
//object.c
/* Try to encode a string object in order to save space */
//该函数编码是embstr时候,为什么要释放整个redisObject对象?
//因为embstr编码的只申请一次内存空间,这是一个整块,之后是存储整数,就不需要那么大空间,就可释放该对象,再新创redisObject
//而raw编码的,是两次申请内存空间,是两块不连续的内存空间,所以释放ptr部分即可。
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
.................................................
len = sdslen(s);
if (len <= 20 && string2l(s,len,&value)) {//函数string21,表明字符串s中存储的是整数
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
.....................................
} else {
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o); //释放o
return createStringObjectFromLongLongForValue(value);//创建编码为OBJ_ENCODING_INT的redisObject对象
}
}
}
.................................
return o; /* Return the original object. */
}创建string的源码:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len); //小于44字节的,就使用embstr编码
else
return createRawStringObject(ptr,len);
}
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
//给结构体redisObject的变量赋值
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
//给结构体sdshdr的属性赋值
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
/* Create a string object with encoding OBJ_ENCODING_RAW, that is a plain
* string object where o->ptr points to a proper sds string. */
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
..................省略部分
return o;
}为什么是小于44字节会采用embstr编码?
- 因为Redis底层的内存分配是统一管理的(用c语言的内存分配器jemalloc、tcmalloc),而分配的内存大小为
,即是2,4,8等。
- Redis认为一次分配的内存大于64字节是个得不偿失的行为,大内存的申请会消耗更长的时间等。所以在Redis中,超过64字节的内存分配,就会多次进行的。
- 前面我们学习的结构体RedisObject的大小是4bit+4bit+24bit+4字节+8字节=16字节。
- 而字符串为空的SDS,其至少占用1(len)+1(alloc)+1(flags)+1('\0')=4字节。再加上对象头16字节,那一共是20字节。那剩余给字符串的就是64-20=44字节。所以实际字符串超过44字节则为长字符串,会转换为raw格式存储。
embstr和raw区别
embstr与raw都使用redisObject和sds保存数据。
- embstr的使用只分配一次内存空间,因此其redisObject和sds是连续的;而raw需要分配两次内存空间,分别为其redisObject和sds分配空间。
- 因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
- 而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
2.list
Redis的list结构类似一个双端链表,可以从首/尾操作列表中的元素:
- 在3.2版本前,Redis采用ziplist和linkedlist来实现list。当元素数量小于512并且元素的大小小于64字节时采用ziplist编码,超过则采用linkedlist编码。
- 在3.2版本后,Redis统一采用quicklist来实现list。quicklist是个双端链表,每个节点是ziplist。(Redis7.0后,listpack已完全替换ziplist)

list结构的源码
从 list结构插入元素的源码入手:
/* LPUSH <key> <element> [<element> ...] */
void lpushCommand(client *c) {
pushGenericCommand(c,LIST_HEAD,0);
}
/* Implements LPUSH/RPUSH/LPUSHX/RPUSHX.
* 'xx': push if key exists. */
void pushGenericCommand(client *c, int where, int xx) {
int j;
//判断每个插入的元素的长度
for (j = 2; j < c->argc; j++) {
if (sdslen(c->argv[j]->ptr) > LIST_MAX_ITEM_SIZE) {
addReplyError(c, "Element too large");
return;
}
}
//尝试找到key对应的list
robj *lobj = lookupKeyWrite(c->db, c->argv[1]);
if (checkType(c,lobj,OBJ_LIST)) return; //检查类型是否正确
//检查是否为空
if (!lobj) {
if (xx) {
addReply(c, shared.czero);
return;
}
//为空,就创建新的quikclist
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
..............................................
}
//创建list结构
robj *createQuicklistObject(void) {
quicklist *l = quicklistCreate(); //创建快速列表
robj *o = createObject(OBJ_LIST,l);
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
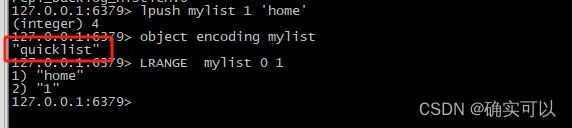
}
3.set
set是Redis中的集合,不保证元素有序的,其元素唯一,查询效率高。
- 为了查询效率高,那可以使用Dict;而唯一性,就可以先从Dict中查询,若没有查到就插入,否则不插入。这个就是HT编码(Dict),Dict中的key可以用来存储元素,value统一为null。
- 当存储的所有数据都是整数,并且元素数量不超过参数set-max-intset-entries时,set会采用intset编码以节省内存。

set结构的源码
从set插入元素部分代码开始:
//t_set.c
//sadd key value1 value2
void saddCommand(client *c) {
robj *set;
int j, added = 0;
//尝试找到对应key的set,可以简单认为c->argv[1]就是key,c->argv[2]就是value1
set = lookupKeyWrite(c->db,c->argv[1]);
//检查类型是否正确
if (checkType(c,set,OBJ_SET)) return;
//如果为空
if (set == NULL) {
set = setTypeCreate(c->argv[2]->ptr); //创建set
dbAdd(c->db,c->argv[1],set);
}
....................
}
robj *setTypeCreate(sds value) {
//判断value是不是整数类型
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
return createIntsetObject(); //若是,则采用intset编码
return createSetObject(); //否则采用默认编码,即是HT
}
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL); //创建dict
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;
return o;
}
robj *createIntsetObject(void) {
intset *is = intsetNew(); //创建intset
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
4.zset
zset也就是sortedSet,其中每个元素都需要指定一个score值和member值。其特性:
- 可以根据score值排序
- memeber值必须唯一
- 可以根据member查询score
因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个要求。
那可以使用什么结构来表示zset呢?
- 可以排序的,并且同时存储score和member值,那可以使用跳表skiplist。
- 根据key快速找到value,可以使用dict。key保存member值,value保存score。
- 这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,不会造成内存的浪费
确实是使用这两个结构体。源码中有这个结构体zset,源码如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;那zset可以不使用dict吗?从性能上来说不妥。
因为zset需要可以通过member得到其score。而skiplist是通过score得到member(score有序),复杂度是O(logN),而通过member查找score,复杂度O(n),从头到尾遍历。
当元素数量不多时,dict和skiplist的优势不明显,而且会更耗内存。所以,zset还会采用ziplist结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_ziplist_entries,默认值是128
- 每个元素的长度都小于zset_max_ziplist_value字节,默认值是64
zset结构的源码
从zset插入元素的代码入手:
//t_zset.c
void zaddCommand(client *c) {
zaddGenericCommand(c,ZADD_IN_NONE);
}
/* This generic command implements both ZADD and ZINCRBY. */
//zadd key score1 member1 score2 memeber2 .......
void zaddGenericCommand(client *c, int flags) {
robj *key = c->argv[1];
robj *zobj;
...................................
//查找key对应的zset
zobj = lookupKeyWrite(c->db,key);
//若没有,就创建
if (zobj == NULL) {
if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
}
//插入元素部分
for (j = 0; j < elements; j++) {
double newscore;
score = scores[j];
int retflags = 0;
ele = c->argv[scoreidx+1+j*2]->ptr;
//zsetadd插入元素,如果最初是ziplist,但随着元素数量的增加,就可能需要进行编码转换,即是用其他结构来保存
int retval = zsetAdd(zobj, score, ele, flags, &retflags, &newscore);
}
..............................
}
//创建zset
robj *createZsetObject(void) {
zset *zs = zmalloc(sizeof(*zs));
robj *o;
zs->dict = dictCreate(&zsetDictType,NULL); //创建dict
zs->zsl = zslCreate(); //创建skiplist
o = createObject(OBJ_ZSET,zs); //给redisObject的type赋值为obj_zset
o->encoding = OBJ_ENCODING_SKIPLIST; //zset的编码是skiplist
return o;
}
robj *createZsetZiplistObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_ZSET,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}zset结构的编码转换是在插入时候进行判断的,在函数zsetAdd中。
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) {
.................................
//判断编码方式,若是ziplist编码,就可能需要进行编码转换
/* Update the sorted set according to its encoding. */
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *eptr;
//判断当前元素是否存在,已存在则更新score即可
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
...........................................
return 1;
} else if (!xx) {
/* check if the element is too large or the list
* becomes too long *before* executing zzlInsert. */
//元素不存在,则新增,需要先判断ziplist长度是否超标,元素的大小是否已超
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value ||
!ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{
//表示超出了,则需要转换为skiplist编码
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
//没有超出,就直接往ziplist插入
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*out_flags |= ZADD_OUT_ADDED;
return 1;
}
} else {
*out_flags |= ZADD_OUT_NOP;
return 1;
}
}
//本身就是skiplist编码,无需进行转换,就插入即可
if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
..................................
} else {
serverPanic("Unknown sorted set encoding");
}
return 0; /* Never reached. */
}而ziplist本身没有排序功能,而且没有键值对的概念,因此需要由zset通过编码来实现:
- ziplist是连续内存,所以score和member是紧挨在一起的两个entry,member在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
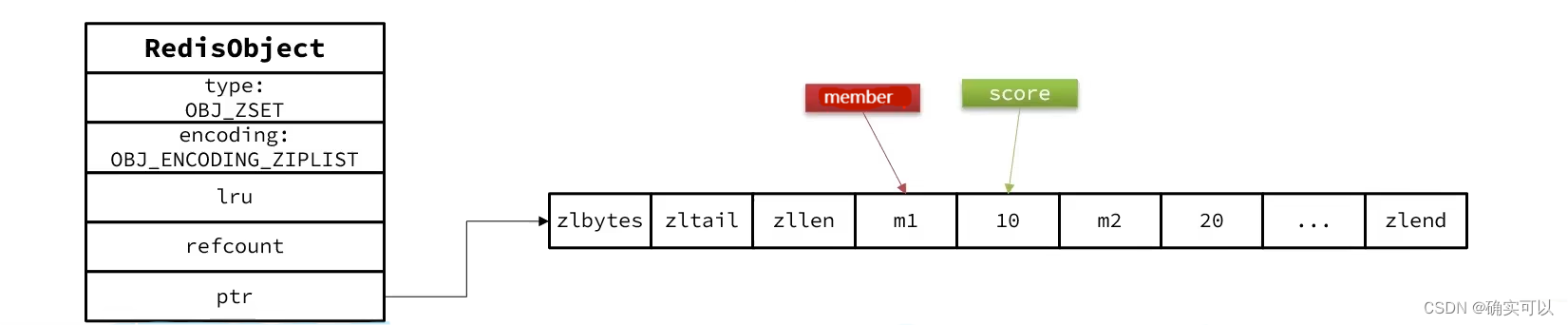
查看编码示例

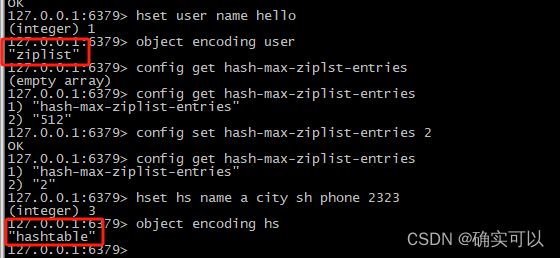
5.hash
这个很明显是用dict。所以,hash采用的编码与zset也基本一致的,只需把排序相关的skiplist去掉即可。
而hash结构默认使用ziplist编码,这是为了节省内存。ziplist中相邻的两个entry分别保存field和value。
当数据量较大时,hash结构会转换成HT编码,即是dict,触发条件有2个:
- ziplist中的元素个数超过了hash-max-ziplist-entries,默认512。
- ziplist中任意entry大小超过了hash-max-ziplist-value,默认64字节。

hash结构的源码
从hash结构的插入元素的代码入手:
//命令格式例子:hset key filed value [filed value]...
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
.................................
//1. 判断hash的key是否存在,若不存在就创建新的,默认是采用ziplist编码
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//2. 判断是否需要把ziplist编码转换为dict编码
hashTypeTryConversion(o,c->argv,2,c->argc-1);
//3. 遍历每一对field和value,并执行hset命令
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
..................................
}1.判断key是否存在,若不存在就创建hash
robj *hashTypeLookupWriteOrCreate(client *c, robj *key) {
robj *o = lookupKeyWrite(c->db,key); //查找是否有该key
if (checkType(c,o,OBJ_HASH)) return NULL; //检查编码类型
if (o == NULL) {
o = createHashObject(); //不存在就创建新的
dbAdd(c->db,key,o);
}
return o;
}
//从代码可见,其默认编码是ziplist
robj *createHashObject(void) {
unsigned char *zl = ziplistNew(); //创建ziplist
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}2.判断是否需要将编码转换成HT编码
/* Check the length of a number of objects to see if we need to convert a
* ziplist to a real hash. Note that we only check string encoded objects
* as their string length can be queried in constant time. */
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
size_t sum = 0;
//若编码不是ziplist,表明不用进行转换,立即返回
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
//遍历命令中的field、value参数,即是遍历argv[i]
for (i = start; i <= end; i++) {
if (!sdsEncodedObject(argv[i])) //如果编码不是OBJ_ENCODING_RAW和OBJ_ENCODING_embstring
continue;
size_t len = sdslen(argv[i]->ptr);
//若果field或value超过了hash_max_ziplist_value,则需转换,转成HT编码(dict)
if (len > server.hash_max_ziplist_value) {
hashTypeConvert(o, OBJ_ENCODING_HT);
return;
}
sum += len;
}
if (!ziplistSafeToAdd(o->ptr, sum)) //若ziplist大小超过1G,也转成HT编码
hashTypeConvert(o, OBJ_ENCODING_HT);
}
/* Don't let ziplists grow over 1GB in any case, don't wanna risk overflow in
* zlbytes*/
#define ZIPLIST_MAX_SAFETY_SIZE (1<<30)
int ziplistSafeToAdd(unsigned char* zl, size_t add) {
size_t len = zl? ziplistBlobLen(zl): 0;
if (len + add > ZIPLIST_MAX_SAFETY_SIZE)
return 0;
return 1;
}
//进行编码转换,重点就在hashTypeConvertZiplist函数中
void hashTypeConvert(robj *o, int enc) {
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
hashTypeConvertZiplist(o, enc);
} else if (o->encoding == OBJ_ENCODING_HT) {
serverPanic("Not implemented");
} else {
serverPanic("Unknown hash encoding");
}
}
void hashTypeConvertZiplist(robj *o, int enc) {
if (enc == OBJ_ENCODING_ZIPLIST) {
/* Nothing to do... */
} else if (enc == OBJ_ENCODING_HT) {//需要转换为HT编码的
hashTypeIterator *hi;
dict *dict;
int ret;
hi = hashTypeInitIterator(o);
dict = dictCreate(&hashDictType, NULL);//创建dict
//逐一把key,value赋值给新创建的dict
while (hashTypeNext(hi) != C_ERR) {
sds key, value;
//获取key,value
key = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_KEY);
value = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_VALUE);
ret = dictAdd(dict, key, value); //往dict中添加
if (ret != DICT_OK) {
serverLogHexDump(LL_WARNING,"ziplist with dup elements dump",
o->ptr,ziplistBlobLen(o->ptr));
serverPanic("Ziplist corruption detected");
}
}
hashTypeReleaseIterator(hi);
zfree(o->ptr);
o->encoding = OBJ_ENCODING_HT; //更新编码为HT编码
o->ptr = dict; //redisObject对象的ptr指针指向dict
}
}3.for循环遍历中,将field和value进行设置插入:
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
//判断编码方式
if (o->encoding == OBJ_ENCODING_ZIPLIST) { //若是ziplist编码
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);//找到head位置
if (fptr != NULL) {//head不为空,开始查找field
fptr = ziplistFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);//查找field
if (fptr != NULL) { //表明该field已存在,即是需要进行更新
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);//到达下一节点位置,即是value
serverAssert(vptr != NULL);
update = 1;
/* Replace value */ //更新该位置的值value
zl = ziplistReplace(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) { //不存在,则直接push
/* Push new field/value pair onto the tail of the ziplist */
//依次将新的field和value都push到ziplist的尾部
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
//插入了新元素,判断ziplist长度是否超过了,超过则转为HT编码
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) { //若是HT编码,直接插入或更新
dictEntry *de = dictFind(o->ptr,field);
..................................
} else {
serverPanic("Unknown hash encoding");
}
......................
return update;
}
Redis中key和value的对应关系
首先,Redis内部会将key和value都封装成对应的redisObject对象。
- 其中key是string数据类型的redisOect。
- value的redisObject就根据用户使用插入命令时候设置的。比如set结构类型的插入,sadd name jack。jack就会封装成type是set的redisObject。
那key是怎么对应上该value,其是如何可以快速通过key找到value的呢?
其实,Redis也是使用一个数据结构来存放key和value。要想查找效率高,那就是使用dict数据结构。所以key和value是通过hash表进行关联的。每个哈希表都有一个键值对,其key是唯一的,并且与对应的value相关联。
所以说,整个Redis是个大的dict。我们通过string的获取来查看下,比如命令get age。这时redis会调用getCommand函数。该函数最终会调用db.c文件的lookupKey函数,该函数内部是从dict中查找该key。
//命令格式 get key
void getCommand(client *c) {
getGenericCommand(c);
}
//其重点就在lookupKeyReadOrReply函数中
int getGenericCommand(client *c) {
robj *o;
//查找是否有该key
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.null[c->resp])) == NULL)
return C_OK;
if (checkType(c,o,OBJ_STRING)) {
return C_ERR;
}
addReplyBulk(c,o);
return C_OK;
}
robj *lookupKeyReadOrReply(client *c, robj *key, robj *reply) {
robj *o = lookupKeyRead(c->db, key);
if (!o) SentReplyOnKeyMiss(c, reply);
return o;
}
robj *lookupKeyRead(redisDb *db, robj *key) {
return lookupKeyReadWithFlags(db,key,LOOKUP_NONE);
}
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) {
robj *val;
................
val = lookupKey(db,key,flags);//查找该key
.......................
return val;
..........................
}
//db.c
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr); //在dict中查找
if (de) {
robj *val = dictGetVal(de);
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}














 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









