







Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
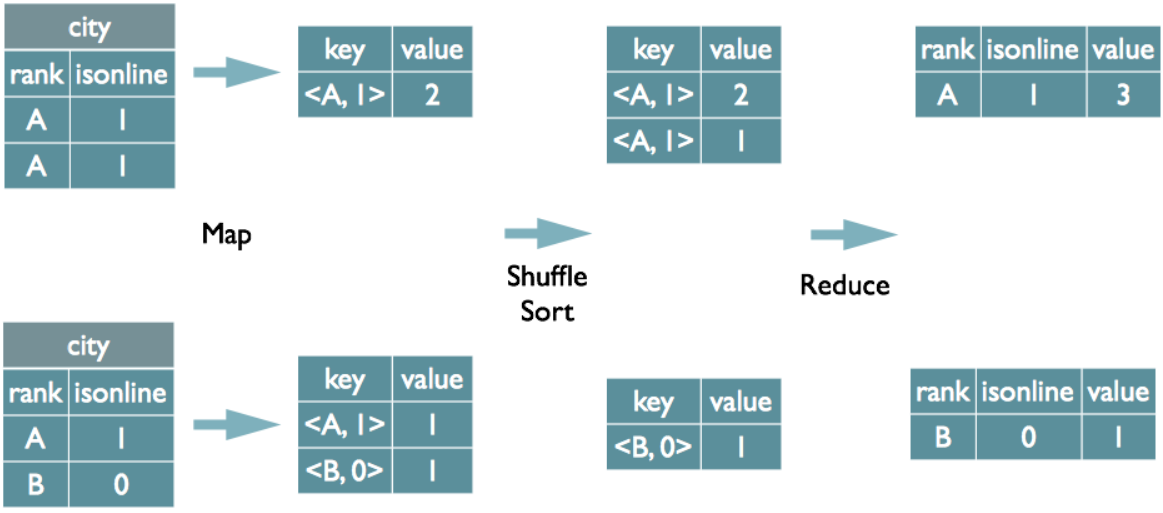
但并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
1)开启Map端聚合参数设置
(1)是否在Map端进行聚合(默认为true)
set hive.auto.convert.join = true;
(2)在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
(3)有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









