







Hive性能优化时,把HiveQL当作M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换局面。通俗一点来说,就是在执行sql的时候,尽量少占用系统资源,其次让处理时间尽量短一些。
1. 列裁剪
- Hive在读取数据的时候,只读取查询中需要用到的列,忽略其他列,不进行select *。
可以把表设计为orc或者parquet的存储格式,都是按行分块,每块按列存储,核心思想就是把表分成一个一个行组row group,行组中是一列转成一行(列块)来存储,列块中封装的就是一列的部分数据。如果只想查询某一列或者某几列,那么只需要扫描相应的列块即可,如果查询的列越多,那么扫描的列块就越多,扫描的数据量也就越大。
2. 分区裁剪
- 在查询的过程中减少不必要的分区,不用扫描全表。比如要查询某一个分区中的数据,只需要扫描对应分区目录下的文件即可。
3. 合理设置reduce的数量(要看服务器的配置)
sql转换为mapreduce的过程中,map的数量取决于切片的数量,但reduce的数量是可以自己设置的,且reduce个数的设定极大影响任务执行效率,在设置reduce个数的时候考虑两个原则:
使大数据量利用合适的reduce数;使每个reduce任务处理合适的数据量
在不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
- 参数1:hive.exec.reducers.bytes.per.reducer (每个reduce任务处理的数据量,在Hive 0.14.0及更高版本中默认为256M)
- 参数2:hive.exec.reducers.max (每个任务最大的reduce数,在Hive 0.14.0及更高版本中默认为1009)
计算reducer数的公式:N = min(参数2,总输入数据量 / 参数1)
min(1009, 1G / 256M=4)则会启动4个reduce - 例:
-- 每个reduce处理的数据量默认256M,查看reduce个数;
select country,count(*) from user_install_status_other where dt=20141228 group by country;
--找到表对应的目录,并且统计一下总大小
show create table user_install_status_other;
dfs -du -s -h /hive/warehouse/yae.db/user_install_status_other;
1.3G 4.0G /hive/warehouse/yae.db/user_install_status_other
--1.3*1024=1331.2 1331.2 / 256 = 5.2≈6个reduce task计算
--设置每个reduce处理的数据量为近似500M(要看给reduce task分配的资源是多少,设置内存和cpu核越大,能干的活就越多),再查看reduce个数,1332.2 / 500≈3个:
set hive.exec.reducers.bytes.per.reducer=500000000;
select country,count(*) from user_install_status_other where dt=20141228 group by country;
- 也可以直接通过参数设置reduce个数
mapred.reduce.tasks(默认是-1,代表Hive自动根据输入数据设置reduce个数)
reduce个数并不是越多越好,启动和初始化reduce会消耗时间和资源;另外有多少个reduce,就会有多少个输出文件,如果生成很多小文件,那么这些小文件会作为下一个任务的输入,也会出现小文件过多的问题。
4. job并行运行设置
带有子查询的HQL,如果子查询间没有依赖关系,可以开启任务并行,设置任务并行最大线程数。
- hive.exec.parallel(默认是false,true:开启并行运行)
- hive.exec.parallel.thread.number(最多可以并行执行多少个作业,默认是8)
测试并行运算:
关闭并行运行,发现没有依赖的子查询不会同步执行
-- 关闭并行运行,默认是false
set hive.exec.parallel=false;
select a.country, a.cn, round(a.cn / b.cn * 100, 6) from
(select country,count(1) cn, 'nn' as joinc from user_install_status_other where
dt='20141228' group by country) a
inner join
(select count(1) cn, 'nn' as joinc from user_install_status_other where dt='20141228') b
on a.joinc=b.joinc;
开启并行运行,发现没有依赖的子查询会同步执行
--开启并行运行
set hive.exec.parallel=true;
select a.country, a.cn, round(a.cn / b.cn * 100, 6) from
(select country,count(1) cn, 'nn' as joinc from user_install_status_other where
dt='20141228' group by country) a
inner join
(select count(1) cn, 'nn' as joinc from user_install_status_other where dt='20141228') b
on a.joinc=b.joinc;5. 小文件的问题优化
如果小文件多,在map输入时,一个小文件产生一个map任务,这样会产生多个map任务;启动和初始化多个map会消耗时间和资源,所以hive默认是将小文件合并成大文件。
- set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;(默认)
- set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;(关闭小文件合并大文件)
如果map输出的小文件过多,hive默认是开启map输出合并。
配置map端输出的小文件合并的,比如没有reduce没有shuffle,map直接输出,默认输出的数据不合并
- set hive.merge.mapfiles=true(默认是false)
配置mapreduce有map和reduce阶段,reduce输出文件默认不合并文件,如果设置合并,则默认是256M
set hive.merge.mapredfiles=true(默认是false)
hive.merge.size.per.task(合并文件的大小,默认是256M)
hive.merge.smallfiles.avgsize(文件的平均大小小于该值时,会启动一个MR任务执行merge,默认16M)
6. join操作优化
(1) 多表join,如果join字段一样,只生成一个job任务;
join的字段类型要一致。
--关闭mapjoin的前提下,执行三个表join
--join的字段一致,只产生一个job任务
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from test_a a
inner join test_b b on a.id=b.id
inner join text_c c on a.id=c.id;
--join的字段不一致,产生多个job任务
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from from test_a a
inner join test_b b on a.id=b.id
inner join test_c c on a.name=c.name;
--job任务数生成的越多,需要占用的资源越多,可能影响时长(2) Map join操作
适合于大表小表的join,可以使用mapjoin在map阶段完成,不需要reduce,hive默认开启mapjoin
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from user_install_status_other u join country_dict c on u.country=c.code limit 10;
--将小表刷入内存中,默认是true;
set hive.auto.convert.join=true;
set hive.ignore.mapjoin.hint=false;
--刷入内存表的大小(字节),根据自己的数据集加大;
set hive.mapjoin.smalltable.filesize=2500000;
select * from user_install_status_other u join country_dict c on u.country=c.code limit 10;
开启mapjoin后,会把小表放到maptask所在节点,运行的时候会加载到内存中,读取的时候是读取大表的数据,在map阶段进行join,没有reduce,避免了shuffle和频繁大量溢写磁盘,节省时间提高效率。
7. SMBJoin(适合大表和大表join的优化)
SMB Join是sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive中和分区表类似的技术,就是按照key进行hash,相同的hash值都放都相同的bucket中去。在进行两个表联合的时候,首先进行分桶,再join会大幅度的对性能进行优化。
(1) SMB Join成立的前提条件
①两张表必须是桶表,且分桶的字段和排序的字段要一致。在创建表的时候需要指定:
create table(...) clusterd by (字段a) sort by (字段a) into buckets_nums buckets②Join的时候,join的key必须是分桶的字段
③设置bucket的相关参数,默认是false,true代表开启SMB Join
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;④桶的数量可以相等,也可以是倍数关系。
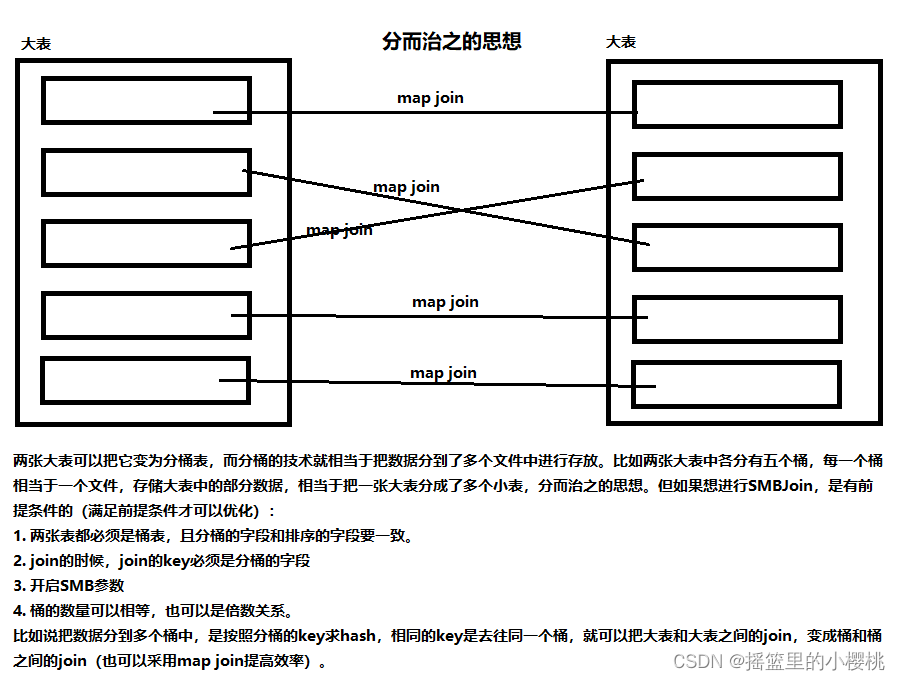
(2) 两个桶表数量相等的Join
① 创建桶表(按照country分桶,桶内文件按照country排序)
create table user_buckets(
`aid` string,
`pkgname` string,
`uptime` bigint,
`type` int,
`country` string,
`gpcategory` string)
comment 'This is the buckets_table table'
clustered by(country) sort by(country) into 20 buckets;② 导入数据
insert overwrite table user_buckets select aid,pkgname,uptime,type,country,gpcategory
from user_install_status_other where dt='20141228';③ 设置桶相关参数,并进行执行计划对比
-- 都设置为true,查看执行计划发现没有Reducer Operator Tree,采用SMB Join
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
explain select t2.* from user_buckets t1
inner join user_buckets t2 on t1.country = t2.country;(3) 执行SQL看对比情况
结论:开启SMB Join要比不开启快得多,大表优化可以采用。
8. Hive的数据倾斜优化
(1) Hive的数据倾斜
主要表现在:map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数要比其他key多很多,这条key所在的reduce节点所处理的数据量也就比其他节点大很多,从而导致某几个节点迟迟运行不完。
(2) 数据倾斜的原因
- key分布不均匀,本质上就是业务数据可能存在倾斜
- 某些sql语句本身就有数据倾斜
| 关键词 | 情形 | 后果 |
| join | 其中一个表很小,但是key集中 | 分发到某一个或几个reduce上的数据远高于平均值 |
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce非常耗时 |
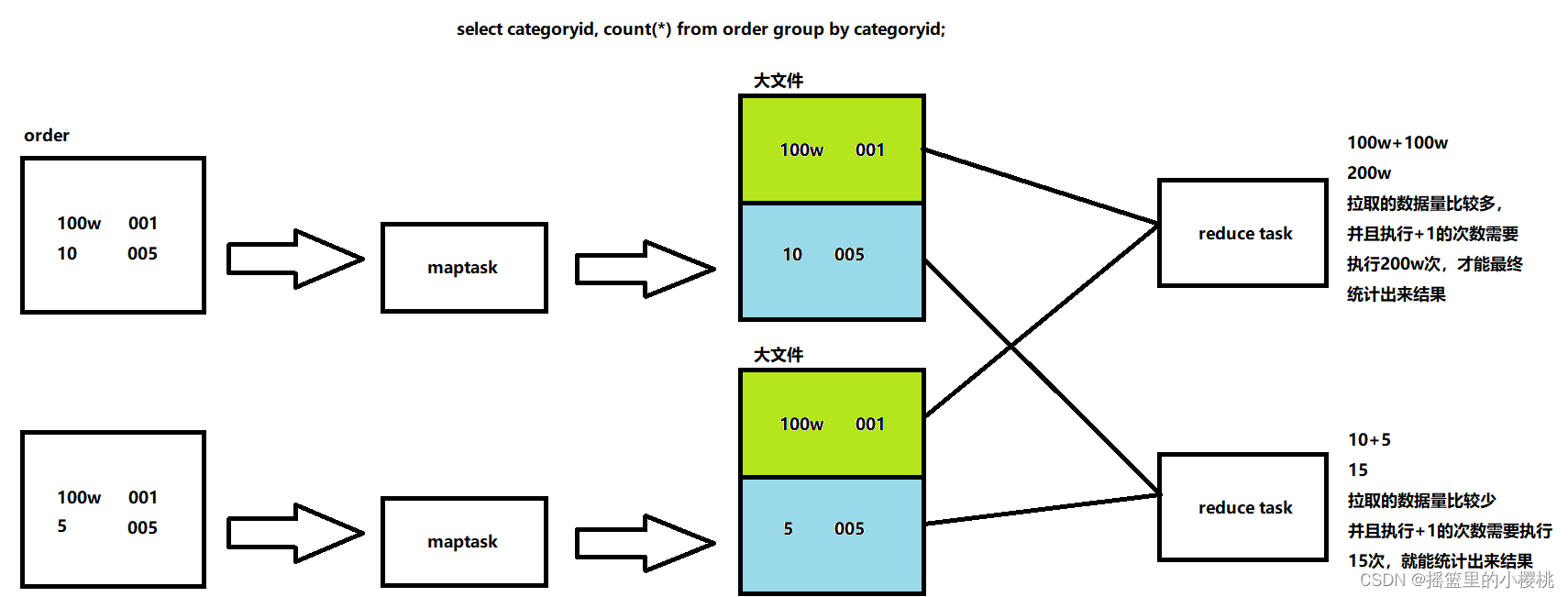
对于group by:切成两块,每一块对应一个切片,一个切片对应一个map task,最终经过把数据写入到缓冲区,溢写,merge,每个maptask会生成一个大文件,比如有两个reduce task,在订单表中,业务数据有可能会存在倾斜。reduce要拉取属于自己分区的数据,在环形缓冲区中会进行分区,第一个reduce task会比第二个reduce task拉取的数据多,而在第一个reduce task拉取数据的时候,第二个reduce task可能已经把数据拉取完了,且执行完了15次加一的操作,这就造成了数据倾斜。
对于join:要把map reduce中map输出的key设计为categoryid,只有设计为两张表都有的共用字段,才会最终到reduce聚合成一个迭代器。和group by数据倾斜本质原理相同(即经过分区之后,不同reduce拉取数据不同)
(3) 数据倾斜的解决方案
对于group by分组统计时产生数据倾斜的问题:
① 在map阶段对数据进行combiner,到了reduce阶段需要统计的次数就会变少(减少reduce拉取的数据量)
set hive.map.aggr=true;(默认是true)② 将存在倾斜的数据分发到不同的reduce进行处理,达到负载均衡的效果
set hive.groupby.skewindata=true;(默认是false)会生成两个MR Job,第一个MR Job中,map的输出结果集合会随机分布到reduce中,每个reduce做部分聚合操作,并输出结果,这样处理的结果是,相同的group by key可能被分到不同的reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照group by key分布到reduce中(这个过程可以保证相同的group by key被分布到同一个reduce中),最后完成最终的聚合操作。 开启负载均衡,向reduce发送数据是随机发的rand()。
对于join时产生数据倾斜的问题:
select * from test_a a
left join test_b b
on a.id=b.id;
解决方法:
select * from test_a a
left join test_b b
on case when a.id is null then ceil(rand()*100) else a.id end =b.id;
注: b.id是int类型,因此产生的随机值也得是int类型在进行join的时候,mapreduce把两个表公有的字段id作为map输出的key,之所以不同的reduce拉取的数量不同,是因为map会根据输出的key求hash,然后对reduce task数量取余。a.id里有七百万个null,null肯定会去往同一个分区,被同一个reduce task拉取到,就产生了数据倾斜。想要解决,就要让七百万条null去往不同的reduce。把id为null的数据,产生一个随机值,每次join的时候不用null join用随机值和b.id进行join,因为a.id不断变化,key就会不断变化,求完hash对map task取余的结果也在不断变化,就会使七百万条null分发到不同的reduce,达到负载均衡的效果。
对于count distinct产生数据倾斜的问题:
在执行下面sql时,即使设置了reduce个数也不起作用,会忽略设置的reduce个数,强制使用1。意味着所有的数据倾斜到一个reduce task进行处理,压力过大。
set mapred.reduce.tasks=3;
-- 关闭负载均衡
-- distinct本质上和group by类似,即去重统计
set hive.groupby.skewindata=false;
select count(distinct country) from user_install_status_limit;
解决方法:
1. 开启负载均衡,reduce task的数量设置就生效了
set mapred.reduce.tasks=3;
set hive.groupby.skewindata=true;
select count(distinct country) from user_install_status_limit;
2. 设置多个reduce时,在reduce阶段可以多个reduce处理数据,而不是只有一个reduce处理数据
先对country字段group by/distinct去重,再求count*(count和distinct不连着用)
set mapred.reduce.tasks=3;
select count(*) from (select country from user_install_status_limit group by country) t;
或者
select count(*) from (select distinct country from user_install_status_limit) t;















 2694
2694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









