






 该代码示例展示了如何使用Python进行谱聚类,具体步骤包括计算拉普拉斯矩阵、求解特征值和特征向量、选取非零特征值对应的特征向量,最后利用KMeans进行聚类。示例中,数据被分为两类,聚类结果为[111000],表明123一组,456一组。
该代码示例展示了如何使用Python进行谱聚类,具体步骤包括计算拉普拉斯矩阵、求解特征值和特征向量、选取非零特征值对应的特征向量,最后利用KMeans进行聚类。示例中,数据被分为两类,聚类结果为[111000],表明123一组,456一组。
1、例题
应用谱聚类将下图中的数据集聚为2 类,其中取前2个(不包括0特征值)小的特征值对应的特征向量.
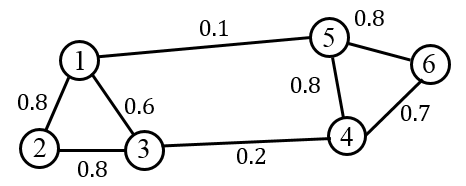
请用pyhton实现例题过程和结果,包括:
输入权重矩阵-->计算Laplace矩阵L-->求特征值和特征向量-->特征值排升序-->取前两个特征值(不包括0)-->对对应特征向量进行Kmeans聚类(调用sklearn.kmeans命令)-->给出最终聚类结果。
2、代码
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 25 21:22:22 2023
@author: 18705
"""
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import math
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#输入值
# =============================================================================
# 6
# 0 0.8 0.6 0 0.1 0
#
# 0.8 0 0.8 0 0 0
#
# 0.6 0.8 0 0.2 0 0
#
# 0 0 0.2 0 0.8 0.7
#
# 0.1 0 0 0.8 0 0.8
#
# 0 0 0 0.7 0.8 0
# =============================================================================
def spectral_cluster(W,k):
'''
Parameters
----------
W : TYPE np.ndarray
DESCRIPTION.权重矩阵
k : TYPE int
DESCRIPTION.聚类数量
Returns
-------
TYPE np.ndarray
DESCRIPTION.聚类结果(颜色)
ev_k : TYPE np.ndarray
DESCRIPTION.坐标点,特征向量
'''
#计算拉普拉斯矩阵
D=np.diag(np.sum(W,axis=1))#行和相加然后生成对角阵
L=D-W
#构建标准化拉帕拉斯矩阵
D_2=np.diag((np.sum(W,axis=1))**(-0.5))
L_b=np.matmul(D_2,L,D_2)#矩阵相乘
#求矩阵的特征值
eigen_values,eigen_vectors=np.linalg.eig(L_b)
#根据特征值对特征向量排序
idx=eigen_values.argsort()
eigen_vectors=eigen_vectors[:,idx]
eigen_values=sorted(eigen_values)
#取前k个非0特征值对应的特征向量
ev_k=eigen_vectors[:,1:k+1]
#特征向量的标准化
#注意int和float的转化
#a=a.astype(np.float32,order='C')
sum_evk=np.sum(ev_k**2,axis=0)
for i in range(k):
for j in range(len(ev_k[:,i])):
ev_k[j,i]=ev_k[j,i]/math.sqrt(sum_evk[i])
#k-means进行聚类
Kmeans=KMeans(n_clusters=k).fit(ev_k)
return Kmeans.labels_,ev_k
#聚类标签才是最终聚类的结果。
#输入矩阵
n=int(input('请输入权重矩阵的秩:'))
a=[]
for i in range(n):
a.append(list(map(float,input('请输入矩阵第%d行:' %(i+1)).split())))
a_a=np.array(a)
#append()是向列表尾部追加一个新元素,列表只占一个索引位,在原有列表上增加。
#extend()向列表尾部追加一个列表,将列表中的每个元素都追加进来,在原有列表上增加.
#map输出是map对象,再用list转化一下
k=2#分成几类
labels,X=spectral_cluster(a_a, k)
#打印结果
print("聚类结果:",labels)
print("特征向量:\n",X)
#绘制效果图
colors=['r','g','b']
for i in range(len(labels)):
plt.scatter(X[i,0], X[i,1], color=colors[labels[i]])
plt.text(X[i,0]+0.02, X[i,1], i+1)
plt.title('预测聚类中心个数: %d' %k)
plt.show()
3、结果
聚类结果: [1 1 1 0 0 0]
特征向量:
[[-0.41139873 -0.60116427]
[-0.44605599 -0.04157209]
[-0.37554212 0.62721672]
[ 0.36826457 0.39752139]
[ 0.40207561 -0.21678801]
[ 0.43985187 -0.19609228]]
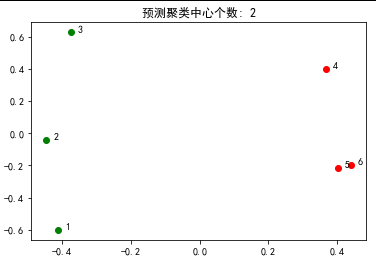
所以123一类,456一类。


















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









