






Map接口定义,方法
Map接口是Java中一种用于存储键值对(key value)的数据结构,它可以根据键(key)来快速地检索或者更新对应的值(value)。Java中有多个类实现了Map接口,常见的有HashMap, TreeMap, LinkedHashMap, Hashtable,ConcurrentHashMap等,它们各自有不同的特点和优劣。
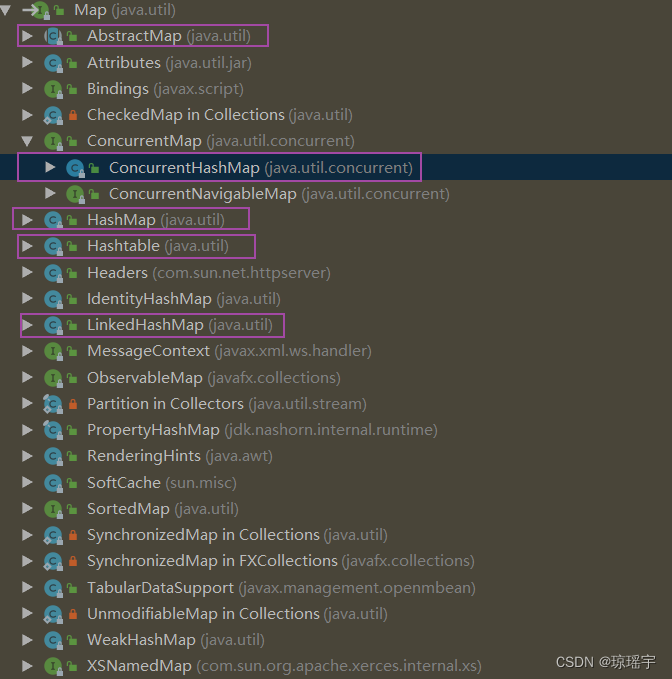
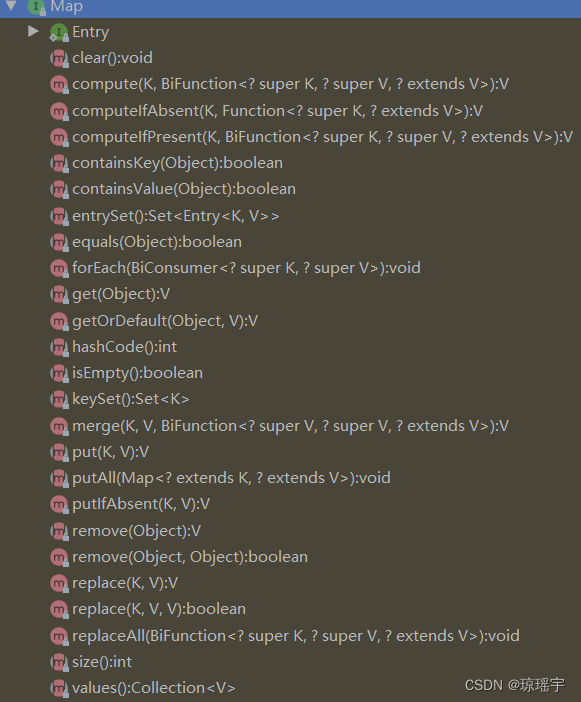
Map接口提供了以下方法:
clear(): 从此映射中移除所有映射关系。
containsKey(Object k): 如果此映射包含指定键的映射关系,则返回 true。
containsValue(Object v): 如果此映射将一个或多个键映射到指定值,则返回 true。
entrySet(): 返回此映射中包含的映射关系的 Set 视图。
equals(Object obj): 比较指定的对象与此映射是否相等。
get(Object k): 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null
hashCode(): 返回此映射的哈希码值。
isEmpty(): 如果此映射未包含键-值映射关系,则返回 true。
keySet(): 返回此映射中包含的键的 Set 视图。
put(Object k, Object v): 将指定的值与此映射中的指定键关联。
putAll(Map m): 从指定映射中将所有映射关系复制到此映射中。
remove(Object k): 如果存在一个键的映射关系,则将其从此映射中移除。
size(): 返回此映射中的键-值映射关系数。
values(): 返回此映射中包含的值的 Collection 视图。
Map接口下的常用实现类
HashMap
(1)底层数据结构
底层基于数组和链表或红黑树(也就是散列表,哈希表)实现,通过哈希算法将键映射到数组的索引位置,以实现快速的插入和查找操作。
(2)扩容机制
JDK8中,HashMap的初始容量默认为16,负载因子默认为0.75,阈值默认为12(容量乘以负载因子)。当HashMap中的元素数量超过阈值时,就会触发扩容操作。扩容操作主要包括以下几个步骤:1,创建一个新的数组,大小为原来数组的两倍。2,遍历原来数组中的每个元素,计算它们在新数组中的位置。3,将元素插入到新数组中对应的位置,如果有哈希冲突,则维持链表或者红黑树的结构。4,更新HashMap的容量、阈值等属性。
HashMap中哈希冲突用链表或红黑树解决,那什么时候使用链表什么时候使用红黑树?JDK8中。当桶中的元素数量超过8时,就会触发链表转换为红黑树的操作;当桶中的元素数量小于6时,就会触发红黑树转换为链表的操作。
(3)基本使用
HashMap的主要方法和原理:
put方法:用于将键值对插入到HashMap中。首先,通过hash(key)方法计算键的哈希码,并调用putVal()方法进行插入操作。putVal()方法的核心是通过哈希码定位桶,然后在桶中进行插入操作。如果桶为空,则直接在桶中插入新节点。如果桶不为空,则遍历链表或红黑树,查找键是否已存在。如果键已存在,则替换对应的值;如果键不存在,则将新节点插入到链表的末尾,并根据链表长度是否达到阈值来决定是否将链表转化为红黑树。最后,更新修改次数和元素数量,并进行必要的扩容操作。
get方法:用于根据键来获取值。首先,通过hash(key)方法计算键的哈希码,然后根据哈希码找到对应的桶。接下来,在桶中遍历链表或红黑树,通过equals()方法比较键的相等性来找到对应的节点,如果找到则返回对应的值,否则返回null。
resize方法:用于动态扩容HashMap。当元素数量超过阈值时,HashMap会自动触发扩容操作。它创建一个更大的数组,并重新计算每个键的哈希码和索引位置,然后将键值对重新插入到新数组中。这样可以减少桶的数量,降低哈希冲突的概率,提高存储和检索的效率。
全部方法合集
put(K key, V value): 将指定的键和值关联到HashMap中,如果键已经存在,则替换旧值,并返回旧值;如果键不存在,则返回null。
get(Object key): 根据指定的键从HashMap中获取对应的值,如果键不存在,则返回null
remove(Object key): 根据指定的键从HashMap中删除对应的键值对,并返回被删除的值;如果键不存在,则返回null。
containsKey(Object key): 判断HashMap中是否包含指定的键,如果包含则返回true,否则返回false。
containsValue(Object value): 判断HashMap中是否包含指定的值,如果包含则返回true,否则返回false。
size(): 返回HashMap中的键值对数量。
isEmpty(): 判断HashMap是否为空,如果为空则返回true,否则返回false。
clear(): 清空HashMap中的所有键值对。
keySet(): 返回HashMap中所有键的集合。
values(): 返回HashMap中所有值的集合。
entrySet(): 返回HashMap中所有键值对的集合。
除了这些常用方法,HashMap还提供了一些其他方法,例如:
clone(): 返回HashMap的一个浅拷贝,即只复制了数组和链表或红黑树的结构,但没有复制其中的元素对象。
equals(Object obj): 比较指定对象是否和HashMap相等,即是否包含相同数量和相同内容的键值对。
hashCode(): 返回HashMap的哈希码值,即所有键值对的哈希码之和。
forEach(BiConsumer<? super K,? super V> action): 对HashMap中每个键值对执行给定的操作。
replaceAll(BiFunction<? super K,? super V,? extends V> function): 用给定函数计算出的新值替换HashMap中每个键值对的旧值。
putIfAbsent(K key, V value): 如果指定的键不存在于HashMap中,则将其和给定值关联到HashMap中,并返回null;否则不做任何改变,并返回原来的值。
remove(Object key, Object value): 如果指定的键和值在HashMap中存在,则删除该键值对,并返回true;否则不做任何改变,并返回false。
replace(K key, V value): 如果指定的键在HashMap中存在,则用给定值替换其旧值,并返回旧值;否则不做任何改变,并返回null。
replace(K key, V oldValue, V newValue): 如果指定的键和旧值在HashMap中存在,则用给定新值替换其旧值,并返回true;否则不做任何改变,并返回false。
compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction): 根据指定的键和给定函数计算出一个新值,并将其和键关联到HashMap中,如果新值为null,则删除该键值对,并返回null;否则返回新值
computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction): 如果指定的键不存在于HashMap中,则根据给定函数计算出一个新值,并将其和键关联到HashMap中,如果新值为null,则不做任何改变,并返回null;否则返回新值。
computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction): 如果指定的键存在于HashMap中,则根据给定函数计算出一个新值,并将其和键关联到HashMap中,如果新值为null,则删除该键值对,并返回null;否则返回新值。
merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction): 如果指定的键不存在于HashMap中,则将其和给定值关联到HashMap中,并返回给定值;如果指定的键存在于HashMap中,则根据给定函数计算出一个新值,并将其和键关联到HashMap中,如果新值为null,则删除该键值对,并返回null;否则返回新值。
LinkedHashMap
LinkedHashMap它继承自HashMap,并且保持了元素的插入顺序或者访问顺序。
(1)底层数据结构
LinkedHashMap的底层结构是一个数组和一个双向链表,每个数组元素是一个链表或者红黑树,用来存放哈希冲突的元素。每个元素还有两个指针,分别指向双向链表中的前一个和后一个元素。这样就形成了一个按照插入顺序或者访问顺序排列的链表。
(
而排序有:
插入顺序:默认的排序方式,按照元素插入到映射表中的顺序进行排序。这种方式可以保证迭代器遍历时,元素的顺序和插入时一致。
访问顺序:通过指定一个特殊的构造方法,可以让LinkedHashMap按照元素被访问的顺序进行排序。这种方式可以实现最近最少使用(LRU)缓存的策略。
而要使用LinkedHashMap的访问排序,需要在构造函数中指定一个特殊的参数accessOrder,将其设置为true。
// 创建一个按照访问顺序排序的LinkedHashMap
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(16, 0.75f, true);)
(2)扩容机制
Java的LinkedHashMap扩容机制与HashMap基本一致,因为它们都是基于哈希表和链表(或红黑树)的数据结构。当LinkedHashMap中的元素数量超过阈值时,就会触发扩容操作,即创建一个两倍大的数组,并将原来的元素重新分配到新的数组中。
不同之处在于,LinkedHashMap在扩容时还需要维护双向链表的顺序,保证元素按照插入顺序或者访问顺序排列。这样可以提高迭代器遍历时的效率和一致性。
(3)基本使用
put(K key, V value):将指定的键和值关联到LinkedHashMap中,如果键已经存在,则替换旧值,并返回旧值;如果键不存在,则返回null。
get(Object key):根据指定的键从LinkedHashMap中获取对应的值,如果键不存在,则返回null
remove(Object key):根据指定的键从LinkedHashMap中删除对应的键值对,并返回被删除的值;如果键不存在,则返回null
containsKey(Object key):判断LinkedHashMap中是否包含指定的键,如果包含则返回true,否则返回false
containsValue(Object value):判断LinkedHashMap中是否包含指定的值,如果包含则返回true,否则返回false
size():返回LinkedHashMap中的键值对数量
isEmpty():判断LinkedHashMap是否为空,如果为空则返回true,否则返回false
clear():清空LinkedHashMap中的所有键值对
keySet():返回LinkedHashMap中所有键的集合
values():返回LinkedHashMap中所有值的集合
entrySet():返回LinkedHashMap中所有键值对的集合。
TreeMap
TreeMap是一种基于红黑树实现的有序映射,它可以按照键的自然顺序或者指定的比较器进行排序。
(1)底层数据结构
TreeMap的底层结构是一个Entry类,它包含了键、值、左子节点、右子节点、父节点和颜色属性。TreeMap的put、get和remove等操作都利用了红黑树的特性,保证了在O(log n)的时间复杂度内完成。
(2)扩容机制
TreeMap是一种基于红黑树实现的有序映射,它不需要像HashMap那样进行扩容操作,因为它的底层结构是一个平衡二叉搜索树,而不是一个数组。
(3)基本使用
put(K key, V value) - 将指定的键/值映射(条目)插入到映射中。
putAll(Map<? extends K,? extends V> m) - 将指定映射中的所有条目插入到此映射中。
putIfAbsent(K key, V value) - 如果映射中不存在指定的键,则将指定的键/值映射插入到map中。
get(Object key) - 返回与指定键关联的值。如果找不到键,则返回null。
getOrDefault(Object key, V defaultValue) - 返回与指定键关联的值。如果找不到键,则返回指定的默认值。
remove(Object key) - 返回并从TreeMap中删除与指定键关联的条目。
remove(Object key, Object value) - 仅当指定键与指定值相关联时才从映射中删除条目,并返回布尔值。
entrySet() - 返回TreeMap的所有键/值映射(条目)的集合。
keySet() - 返回TreeMap的所有键的集合。
values() - 返回TreeMap的所有图的集合。
Hashtable
与hashmap比是线程安全的,底层所有方法都使用synchronized关键字修饰。而且Hashtable不允许使用null作为键或值,否则会抛出NullPointerException异常。(如果为了线程安全推荐使用ConcurrentHashMap,Hashtable不推荐使用,性能太差)
(1)底层数据结构
Hashtable的底层数据结构是一个数组,数组的每个元素是一个链表,链表的每个节点是一个键值对(Entry)。当我们向Hashtable中插入一个键值对时,首先会根据键的哈希码计算出数组的索引,然后将键值对插入到对应索引的链表中。如果发生哈希冲突,即不同的键映射到同一个索引,那么就会在链表中顺序查找或插入键值对。
(2)扩容机制
Hashtable的初始容量是11,Hashtable的加载因子默认是0.75,当元素数量超过阈值时,就会触发扩容操作,容量变为原来的2n+1。
(3)基本使用
put(K key, V value) - 将指定 key 映射到此哈希表中的指定 value
get(Object key) - 返回指定键所映射到的值,如果此映射不包含此键的映射,则返回 null.
remove(Object key) - 从哈希表中移除该键及其相应的值。
containsKey(Object key) - 测试指定对象是否为此哈希表中的键。
containsValue(Object value) - 如果此 Hashtable 将一个或多个键映射到此值,则返回 true。
size() - 返回此哈希表中的键的数量。
isEmpty() - 测试此哈希表是否没有键映射到值。
clear() - 将此哈希表清空,使其不包含任何键。
clone() - 创建此哈希表的浅表副本。
keys() - 返回此哈希表中的键的枚举。
elements() - 返回此哈希表中的值的枚举。
ConcurrentHashMap
ConcurrentHashMap是一种在Java中提供线程安全和可扩展的键值映射数据结构的类。它允许在哈希表中存储和检索键值对,而无需进行显式的同步。
(1)底层结构
ConcurrentHashMap的底层JDK8与JDK7有很大不同:
JDK 1.7及之前:ConcurrentHashMap的底层数据结构是一个Segments数组,每个Segments元素是一个HashEntry数组,每个HashEntry元素是一个链表节点。ConcurrentHashMap使用分段锁的机制来保证线程安全,每个Segments相当于一个独立的哈希表,拥有自己的锁,当多个线程访问不同的Segments时,可以并发地进行操作,而不会产生锁竞争。当需要扩容时,ConcurrentHashMap会逐个扩容每个Segments,而不是一次性扩容整个数组。
JDK 1.8及之后:ConcurrentHashMap的底层数据结构是一个Node数组,每个Node元素是一个链表或红黑树节点。ConcurrentHashMap使用CAS和Synchronized来保证线程安全,当发生哈希冲突时,会将链表转换为红黑树,以提高查找效率。当需要扩容时,ConcurrentHashMap会使用多线程并发地扩容整个数组,并且使用一种特殊的转移节点来标记正在扩容的位置,以避免数据丢失或重复。
(CAS : Compare and Swap,比较和交换,一种原子操作,用于实现多线程环境下的无锁编程(乐观锁实现)。它的基本思想是,给定一个内存地址、一个期望值和一个新值,如果该地址的当前值与期望值相等,则将其更新为新值,并返回成功;否则返回失败。CAS操作可以保证同时只有一个线程能够修改共享变量
)
(2)扩容机制
在Java 8中,ConcurrentHashMap的扩容流程有以下几个步骤:
首先,检查当前数组(称为oldTab)是否已经初始化,如果没有,则初始化一个默认大小(16)的数组,并将其赋值给当前数组。
然后,检查当前数组是否需要扩容,如果需要,则尝试更新一个变量(称为sizeCtl)来表示扩容状态,并创建一个新的数组(称为newTab),其大小是当前数组的两倍。
接着,遍历当前数组中的每个元素(称为f),如果f是一个普通节点,则将其复制到新数组中相应的位置;如果f是一个转移节点(ForwardingNode),则说明已经有其他线程在进行扩容,那么就跳转到新数组中继续处理;如果f是一个树节点,则将其拆分为两个链表或树,并分别复制到新数组中。
最后,当所有元素都复制完毕后,将新数组赋值给当前数组,并更新sizeCtl变量来结束扩容状态。
(3)基本使用
put(K key, V value) - 将指定 key 映射到此哈希表中的指定 value。
get(Object key) - 返回指定键所映射到的值,如果此映射不包含此键的映射,则返回 null。
remove(Object key) - 从哈希表中移除该键及其相应的值。
containsKey(Object key) - 测试指定对象是否为此哈希表中的键。
containsValue(Object value) - 如果此 ConcurrentHashMap 将一个或多个键映射到此值,则返回 true。
size() - 返回此哈希表中的键的数量。
isEmpty() - 测试此哈希表是否没有键映射到值。
clear() - 将此哈希表清空,使其不包含任何键。
clone() - 创建此哈希表的浅表副本。
keys() - 返回此哈希表中的键的枚举。
elements() - 返回此哈希表中的值的枚举。
compute(K key, BiFunction<K, V, V> remappingFunction) - 对指定键及其当前映射值(如果没有当前映射则为 null)执行给定函数,如果函数返回 null,则删除该键(如果存在),否则将其结果替换为当前映射值。这个方法是原子性的,可以用于更新或插入一个值。















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









