







一、RNN
之前在ELMO里呢有提到说ELMO就是一个RNN-based的language module。那什么是RNN-based的language module呢?你要训练一个RNN-based的language module其实不需要做什么labeling,你只需要收集一大堆一大堆的句子,这些句子不需要做任何的标注。举例来说下图有一行句子:潮水退了就知道谁没穿裤子,那你就告诉你的RNN-based的language module说如果看到一个beginning of sentence的符号,那你就要输出"潮水";那接下来再给你"潮水"这个符号,你就要输出"退了";然后给你"潮水"跟"退了"这俩个符号,你就要输出"就"...就这样子训练下去。RNN-based的language module要做的事情就是去预测句子中的下一个token会是什么。

上面呢是在ELMO中的叙述,但是RNN到底长什么样呢,它是怎么运作的呢?总体来说,RNN是一种比较复杂的网络结构,每一个layer还会利用上一个layer的一些信息。以slot filling的task为例,首先什么是slot filling的task呢?简单来说就是:标记那些对理解一段文字有意义的单词或记号,在NLP领域呢把这种方法叫做slot filling,语义槽填充。解释完slot filling之后回到正轨,假设我们有两个句子,一个是“Arrive TianJin on March 26 ”,另一个是“Leave TianJin on January 24”。我们可以发现在第一个句子中,TianJin是destination,而第二个句子中TianJin是departure。如果我们不去考虑TianJin前一个词的话,TianJin的vector只有一个,那么同样的vector进来,吐出的predict就会是一致的,而这恰恰不符合我们的预期,所以我们在train的时候就需要把前一个的结果存起来,在下一个词进来的时候用它进行参考产生不同的output。如果我们能让我们的neuron network有记忆力的话,它就可以解决input相同的词汇,output相同的vector的问题。那这种有记忆力的neuron network呢就叫做Recurrent Neural Network(RNN)
RNN长什么样子呢?它就长下面这个样子,看起来长的还蛮随意的,就是神经网络的一般结构。不过在RNN里面呢,每一次我们的hidden layerl里面的neuron产生的output都会被存到memory里面去,这是RNN的一大特性。以下图为例,用蓝色的方块呢表示memory cell,当这些hidden layer里面的neuron有output的时候,output就会被存到这个蓝色的memory cell里面去。那下一次,当有input输入的时候,hidden layer里面的neuron不是只考虑input ,它还会考虑存在memory cell里面的值。
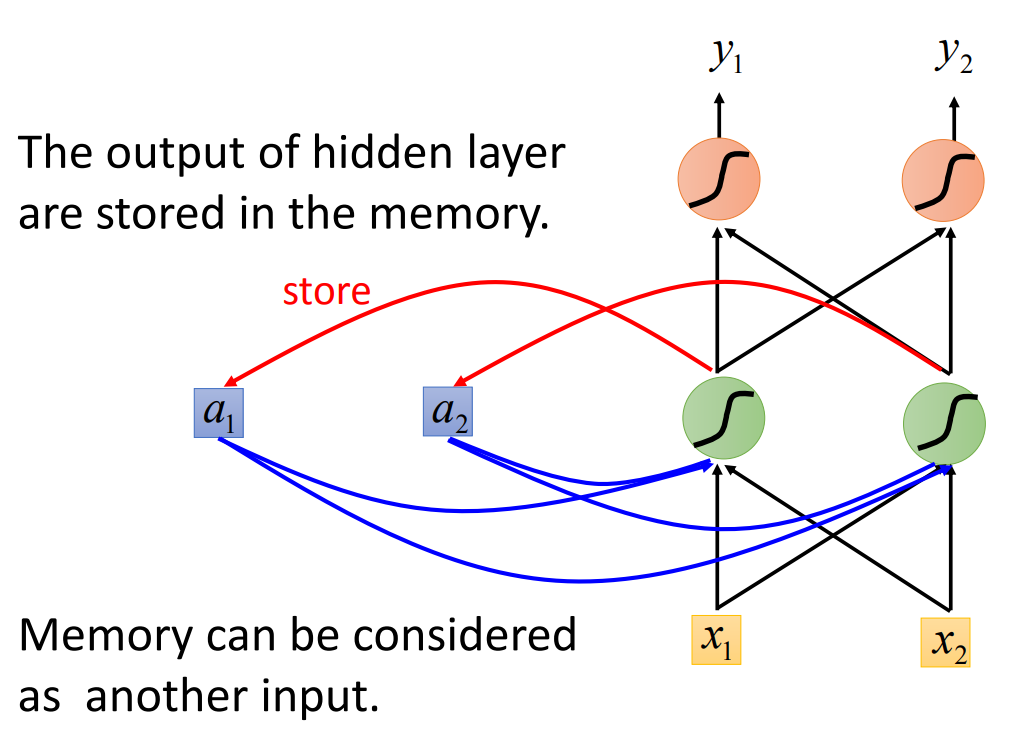
举个例子来说, 假设上图(或者看下图也可以了)中的所有weight都是1,所有的neuron都没有任何的bias,并且假设所有的activation function呢都是linear。现在假设我们的input是一个sequence:,那我们把这个sequence input到我们的RNN里面去会发生什么事呢?那首先在使用RNN的时候呢需要先给memory cell起始值,那我们这里就假设RNN在没有放进任何东西之前,memory cell的起始值是0。
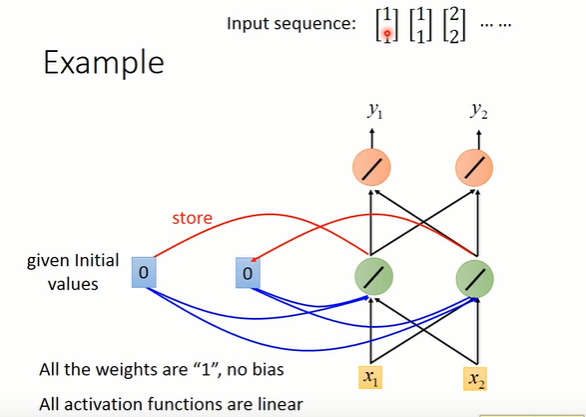
现在input第一个输入,也就是
。那hidden layer的第一个neuron除了接到
之外,它还接到memory的0跟0。因为我们之前假设说所有的weight都是1,所以hidden layer第一个neuron的output就是
。同理呢hidden layer另一个neuron的output也是2。接下来呢,由于所有的weight都是1,所以这两个红色的neuron的output就是4。所以input
的时候呢,通过RNN后的output就是
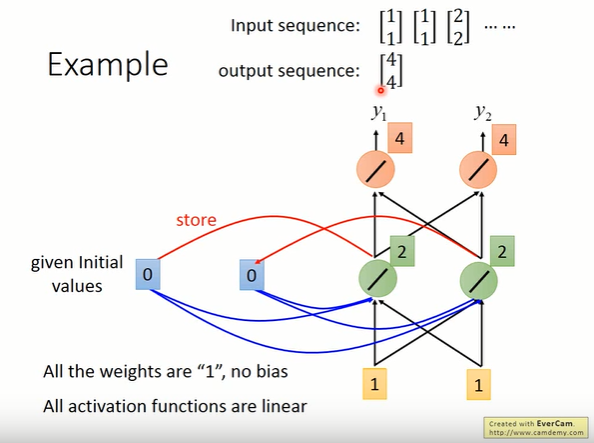
接下来RNN会把刚才hidden layer neuron的output存到memory cell里面,所以你memory cell里面的值就被update为2跟2。接下来input第二个输入,这个时候hidden layer neuron会有什么样的输出呢?显然,hidden layer neuron的输入有四个:1跟1跟2跟2。由于weight都是1,所以hidden layer neuron的输出就是
。接下来呢,由于所有的weight都是1,所以这两个红色的neuron的output就是12。所以当第二次输入
的时候,通过RNN后的输出就是
。对比第一次输入来说,可以发现,就算你输给RNN一样的东西,它的output也有可能是不一样的,因为存在memory cell里面的值呢是不一样的。
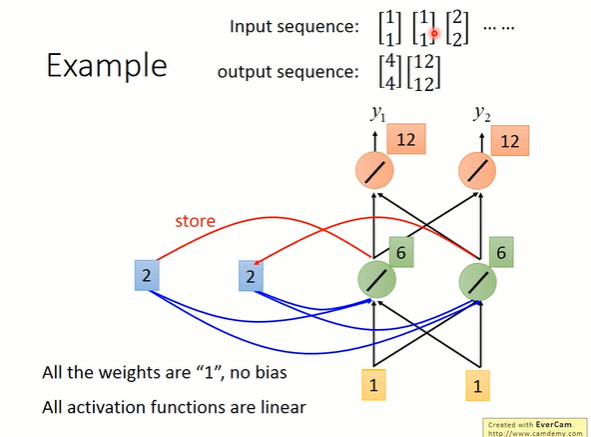
那接下来呢RNN会把刚才hidden layer neuron的output存到memory cell里面,所以你memory cell里面的值就被update为6跟6。 接下来input第三个输入,由于weight都是1,所以hidden layer neuron的输出就是
。接下来呢,由于所有的weight都是1,所以这两个红色的neuron的output就是32。所以当第三次输入
的时候,通过RNN后的输出就是
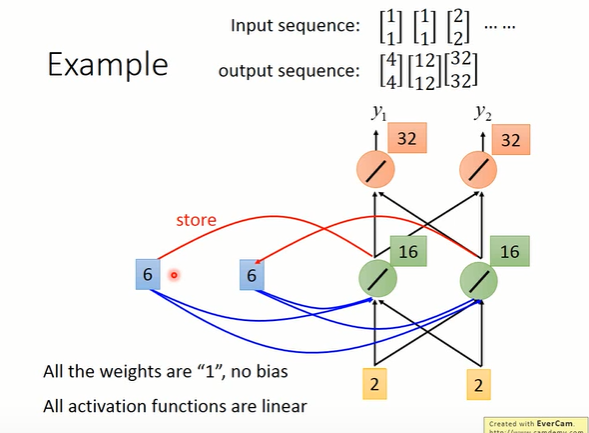
那今天在使用RNN的时候呢有一件很重要的事情就是,RNN在考虑这个input sequence的时候并不是independent。所以今天你任意调换input sequence的顺序,比如说把第三个输入挪到最前面来,那整个RNN的output会完全不一样。所以在RNN里面,它会考虑这个input sequence的order
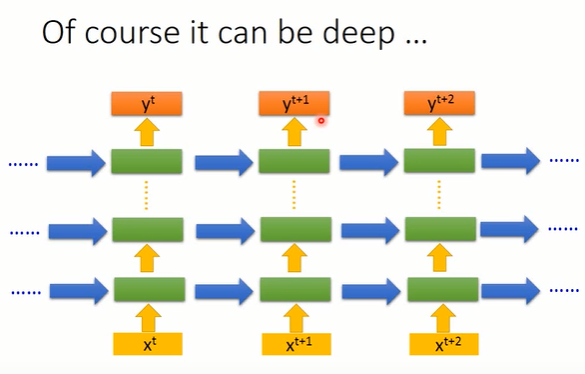
当然RNN也可以是deep的,即有多层hidden layer(下图绿色方框)。比如说我们把丢进去,它可以通过一个hidden layer,再通过第二个hidden layer,以此类推,通过很多个hidden layer以后才得到最后的output
。每一个hidden layer的output都会被存在memory cell里面,在下一个时间点的时候每一个hidden layer会把前一个时间点存的值呢再读出来,最后得到最后的output
,这个process就这样一直持续下去
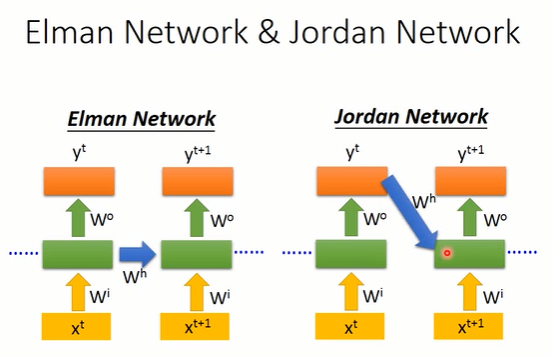
RNN呢有不同的变式,如果我们今天是把hidden layer的值存起来,在下一个时间点再读出来,这种RNN架构叫做Elman Network。那如果你不是把hidden layer的值存到memory cell,而是把output的值存进memory,再在下一个时间点读出来的话,这种RNN架构叫做Jordan Network
另外RNN也可以双向训练:将双向RNN的输出结果都存在y(t)单元中。 这在ELMO中有提到过说,正向RNN只考虑了每一个词汇它的前文,没有考虑它的后文。那怎么办呢?你可以再train一个反向的RNN,从句子的尾巴读过来。
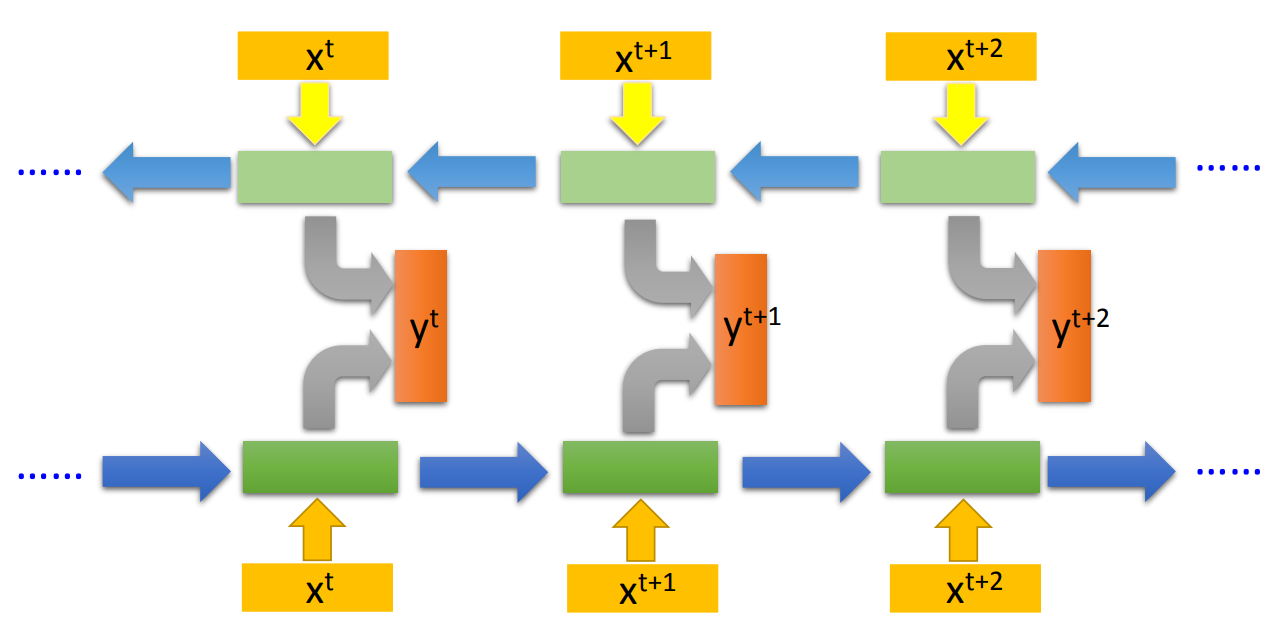
这里要注意一下,RNN不是训练好多个NN,而是一个NN用好多遍。所以可以看到RNN里面的这些network的参数都是一致的。
那上面所有写的呢都是非常原始简单的RNN,每一个输入都会被memory记住。现在RNN的标准做法基本上已经是LSTM。LSTM是一个更加复杂的设计,最简单的设计是每一个neuron都有四个输入,而一般的NN只有一个输入。
未完待续...















 1979
1979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









