







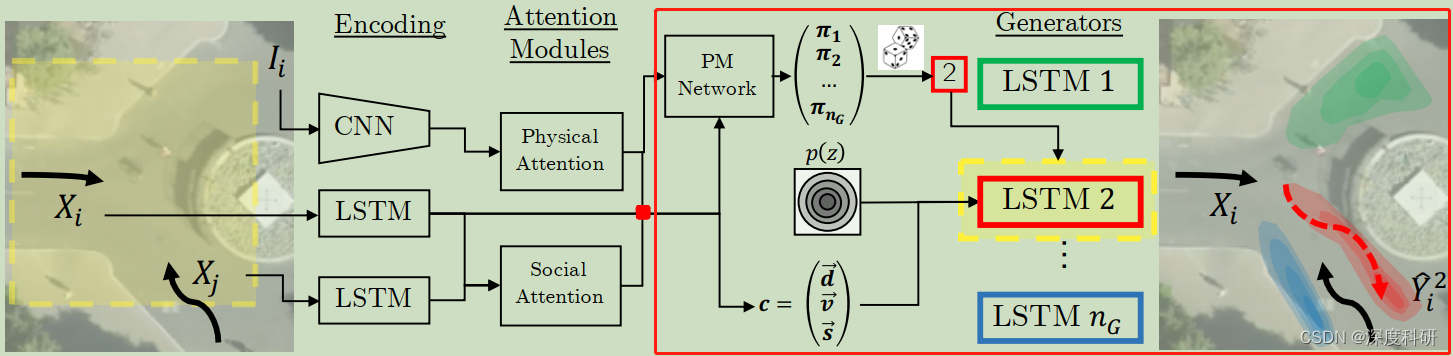
好,接下来要涉及的部分呢,就是MG-GAN的主体部分了,图一有示意说红色矩形框中的部分就是我们今天要写的东西。我们可以从MG-GAN的结构图中看到说,没有给出Discriminator部分,甚至连文章提出的Classifier 也没有给出。而我们知道,GAN的训练往往先从D开始,那没有Discriminator部分和Classifier
该怎么办呢?一个很直接的想法就是先看论文,再看代码,将文章未画在图中的部分自己表述出来。那我正是这么做的,所以博客的质量高也是情理之中的事了。
在(一)中结尾处我们说到:把得到的拼接在一起,得到
([6,192] / [120,192] for D,[6,128] for G)。对判别器D来说,
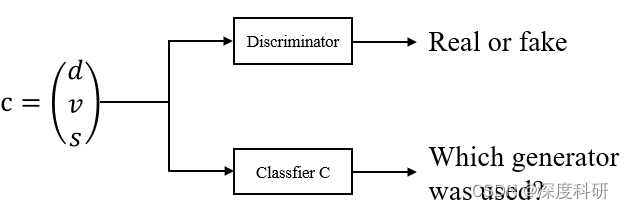
中的每一行包含了该行人20帧的轨迹信息(观测8帧+预测/GT12帧)、他更愿意出现在场景中的哪些位置,以及他对周遭哪些行人比较在意。那这样一个综合了多方面的信息的矩阵,丢给我们的判别器D,就能得到预测行人轨迹的真假;或者将其丢给classifier
,就能得到预测的轨迹信息来自哪一个generator。对生成器G来说,
中的每一行包含了该行人前八帧的观测信息、他更愿意出现在场景中的哪些位置,以及他对周遭哪些行人比较在意。那这样一个综合了多方面信息的矩阵加上噪声,丢给我们的生成器G,就能够输出行人轨迹的预测结果;或者丢给论文架构中的PM Network,就能得到每个generator的加权概率。这是一个非常精炼的总结,构成了接下来我们叙述的框架。什么意思呢?换句话说,读者不必再为generator或者PM Network的输入是什么而困惑了,我们只需要再挖掘GAN的部分是怎样运作的,那MG-GAN就学习完了。
为了方便叙述我们按照代码的逻辑来书写。在discriminator_step阶段,综合了各方面信息的矩阵会被送入判别器
和分类器 classifier
中,discriminator的作用实际上是个分类器,它由简单的一些线性层构成。那这里为什么要还要增加一个分类器分支
呢?
在传统的GAN中,我们输入一个条件word:c,再输入一个从原始照片中sample出来的分布z,经过generator后,输出一个image:x,我们希望这个x尽可能地符合条件c的描述,并且生成的照片足够清晰;为了保证x的质量,我们引入了discriminator,用来判断输入的x是真实的图片还是伪造的图片,即:
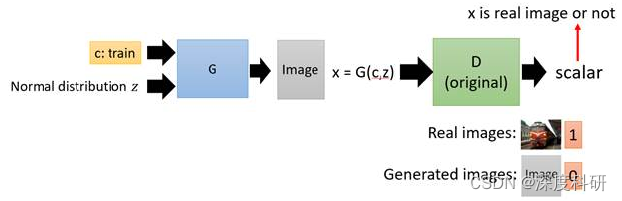
图二:传统GAN 那传统GAN会带来一个什么问题呢?传统GAN只能保证让x尽可能地像真实图片,但是忽略了让x符合条件描述c的要求。于是,为了解决这一问题,CGAN便被提出了。CGAN的目的是:既要让输出的图片真实,也要让输出的图片符合条件c的描述,Discriminator输入便被改成了同时输入c和x。输出要做两件事情,一个是判断x是否是真实图片,另一个是x和c是否匹配。举例来说,在下面这个情况中,条件c是train,图片x也是一张清晰的火车照片,那么D的输出就会是1;即便输出图片清晰,但不符合条件c,或者输出图片不真实,这两种情况中D的输出都会是0。

图二:CGAN 那CGAN又会带来什么问题呢?我们知道说在实际训练中,我们拥有的已配对的数据(c,x)往往是非常少量的,并且D需要做两件事情:既需要和G进行博弈,也就是判别输入的样本是来自真实数据分布还是生成器,还需要预测数据的类标签,也就是输出条件c。那同时做这样两个任务discriminator往往力不从心,只能关注到数据的一部分信息,即数据的来源,而无法考虑到数据的类标签信息。为了解决这个问题,我们可以增添一个classifier
去学习如何给图片x标注配对条件c,这样就能减少discriminator的压力,形成比较好的训练数据。那我们把这种GAN叫做Triple GAN。Triple GAN的框架就是下面这样图的样子:x是图片,y是条件(也就是c),(x,y)构成一个配对。从图中可以看出,TripleGAN由三个部分组成,第一个是classifier
,并将这个配对信息
整合成一个新的配对
传递给discriminator;而第二个部分discriminator就需要学会鉴别输入的配对是来自真实数据,还是generator,还是classifier。最终在discriminator的帮助下,
、
都会越来越接近
;至于第三个部分generator,就与CGAN中的generator一模一样了,输入一个条件y和先验分布z,产生一个输出图片x和条件y的配对。
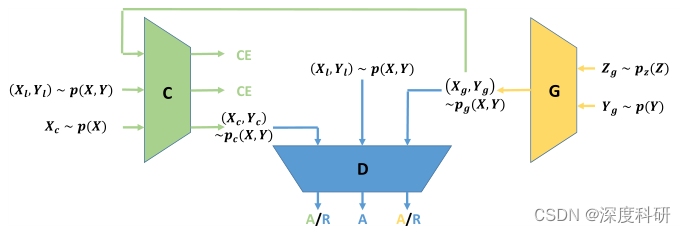
图三:Triple GAN 其实到这里,我们已经可以知道为什么要增加classifier
了。那如同所有只有单个generator的GAN一样,Triple GAN也存在模型崩塌的问题(mode collapsing problem)。mode collapse是指Gan产生的样本单一,其认为满足某一分布的结果为true,而其他为False。 那解决这一问题主要的策略就是应用多个generator,这样做不仅证明对覆盖数据模式的多样性有效,并且能够克服模型崩塌的问题,并取得SOTA的实验结果。一个最直接的应用多生成器的模型就是MGAN。它的网络结构如下图所示:
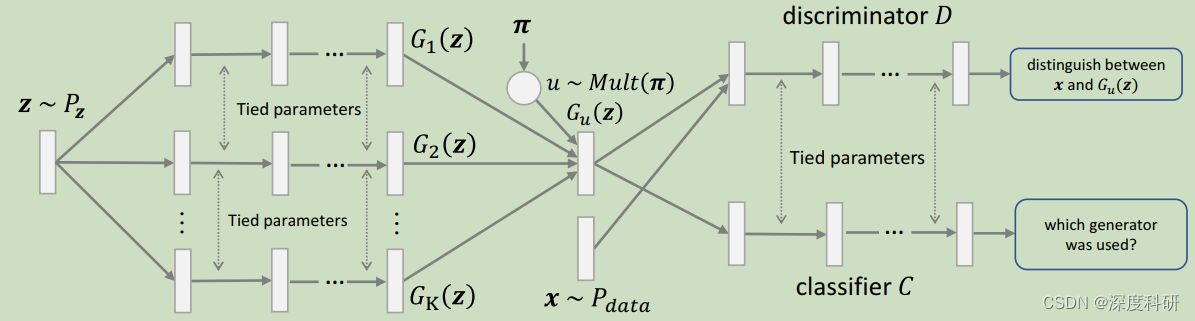
图四:MGAN

好,那我们现在知道增加classifier 的原因是分担判别器的工作,让discriminator只需要关注输入样本的真假,而不需要再对样本类别进行分类,这一部分工作由 classifier
担任。那 classifier
的输出是什么呢?classifier
的架构实际上是由两层全连接层构成,其将维度由192映射到96,再映射到2。所以一个综合了各方面信息的矩阵
[6,192](或[120,192])输入到 classifier
,输出一个纬度大小为[6,2](或[120,2])的矩阵,经维度调整后变为[6,1,2](或[6,20,2])(batch_size, n_samples, dim)。那 classifier
的输出矩阵表示什么含义呢?以输出矩阵大小为[6,1,2]为例,其代表的含义是:对每位行人预测1条预测轨迹,这一条轨迹来自哪个generator(共2个,设置为2)的概率;同理可推,[6,20,2]表示的就是:对每位行人预测20条预测轨迹,每条轨迹来自哪个generator(共2个,设置为2)的概率。
说了这么多,其实只想告诉读者两件事:1.classifier 是判别器D的一个分支;2.classifier
输出矩阵的含义。那用图示意就长下面这样:
好,D和C之后呢,就是我们的生成器G了。生成器generator的任务是根据观测的前八帧轨迹,输出后十二帧预测的轨迹以及生成器的索引。这件事怎么理解呢?你可以想说,现在有两个generator(当然你可以设置四个generator,随你的心意),我将综合了各方面信息的矩阵[6,128](那这里为什么
的维度是128,以及
代表了什么含义,在(一)中已经详细说明,不明白的读者可以移步先去了解)与噪声
concat起来,作为generator LSTM的
(
初始化),行人前八帧的相对轨迹作为generator LSTM的input
,同时丢到两个generator中,产生预测的相对轨迹
[12,6,2]与
[12,6,2]。那如果我们只需要“1条观测轨迹产生1条预测轨迹”的话,
、
的维度就变为[12,1,6,2]。紧接着我们将
、
的结果stack起来,就得到[12,1,2,6,2](seq_len, n_sample, num_gens, batch, dim)。将其调整维度,变为[12,2,6,2](seq_len, n_sample x num_gens, batch, dim)。正如我们之前所说的,我们并不需要全部generator产生的所有轨迹,而是从全部generator产生的所有轨迹中,挑出6条最符合预测结果的轨迹。那“挑”这件事用什么准则来限制呢?答案是论文中提及的PM-Network。那PM-Network的网络架构长什么样呢?它的网络架构由三层全连接层构成,将维度由128映射16,再映射到16,最后映射到2维。那PM-Network的输入是什么呢?它的输入就是我们的矩阵
[6,128]。但是你可能会说,论文原图中在PM-Network模块处有两个箭头,代表着它应该有两个输入才对啊?这一点呢,我肯定有注意到,因为博客就是我写的对不对。但是代码实现过程中,PM-Network仅以
为输入,输出一个大小为[6,2]的矩阵
。那怎么理解这个输出矩阵
的含义呢?举例来说,PM-Network的输出矩阵[6,2]代表了每个行人选择generator 1还是generator 2的概率。光有概率还是“棋差一步”,因为我们想具体知道哪个人应该从哪个generator中选择那条轨迹。那怎么做呢?
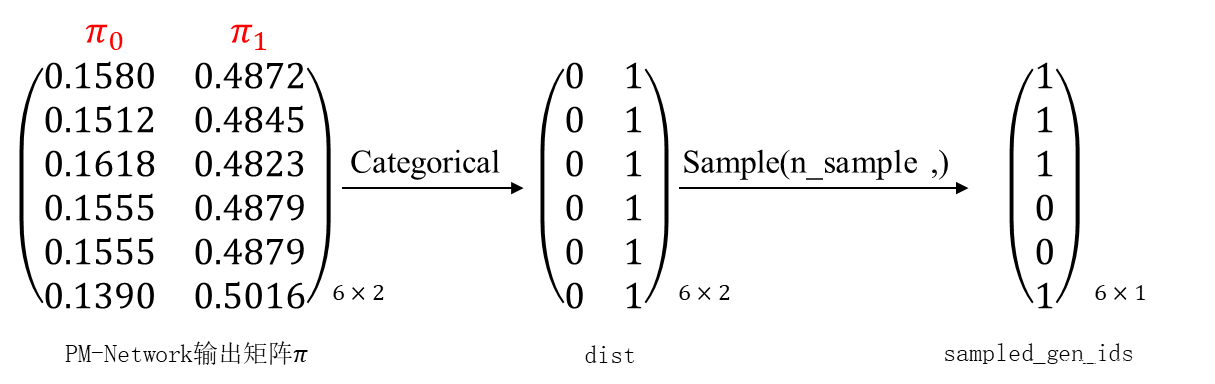
具体的做法是:将矩阵通过一个名叫Categorical(probs)的函数,该函数的作用是创建以参数probs为标准的类别分布,样本是来自 “0 … K-1” 的整数,其中 K 是probs参数的长度。也就是说,按照传入的probs中给定的概率,在相应的位置处进行取样,取样返回的是该位置的整数索引。更具体的用法,读者可以参考相关博客。下面用图示的方法告诉你说,
矩阵通过Categorical函数后得到一个dist矩阵,该矩阵里面的值对应概率值的索引。读者如果一开始理解不了,可以将
矩阵与dist矩阵前后叠在一起看。有了dist后,我们根据
矩阵的概率值对dist矩阵进行采样,采样的次数由参数n_sample决定。这里假设n_sample=1,意味着每行采样1次。那怎么进行采样呢?举例来说,对dist第一行采样得1,对dist第二行采样得1,.... 我们怎么看待dist矩阵的含义呢?从行来看,它的每一行其实代表了一位行人;从列来看,它的每一列代表了generator 1还是generator 2。那么在采样过后,得到的矩阵我们称作:sampled_gen_ids[6,1]
读者需要注意的是,如果n_sample=20,由上述可知,其代表在dist矩阵每一行中采样20次,最后得到的sampled_gen_ids矩阵的大小为[6,20]。sampled_gen_ids矩阵的物理含义为:以第一行[1,20]为例,其表示行人①的20条预测轨迹分别是由哪个generator产生。
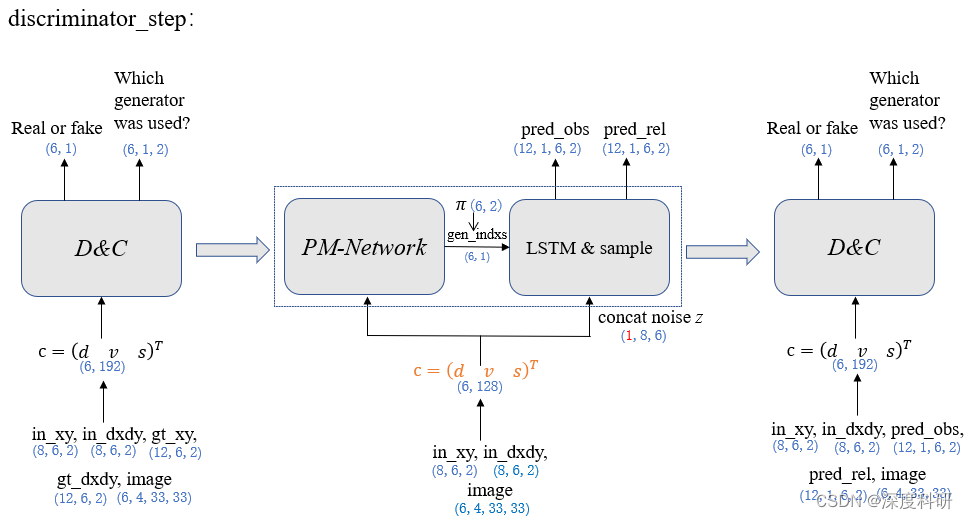
综上所述,如果读者仍然保持清醒的话,整个discriminator_step阶段可以用下图进行概括:
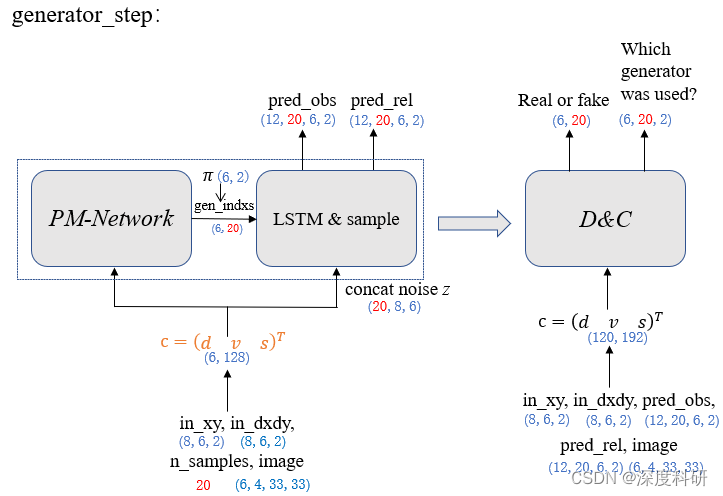
那其实到这里,我们的GAN部分就快要结束了。为什么这么说呢?因为我们已经把D、C、G是怎么运作的给讲完了, 剩下的generator_step阶段对于D、C、G来说只是输入不同而已,其它方面完全一样。你可以用上面的思想带入generator_step的过程,一次性把MG-GAN给弄明白。如上所述,整个generator_step阶段可以用下图来概括:
四、Loss
那在讲Loss之前呢,我们先整理一下MG-GAN的整体架构:
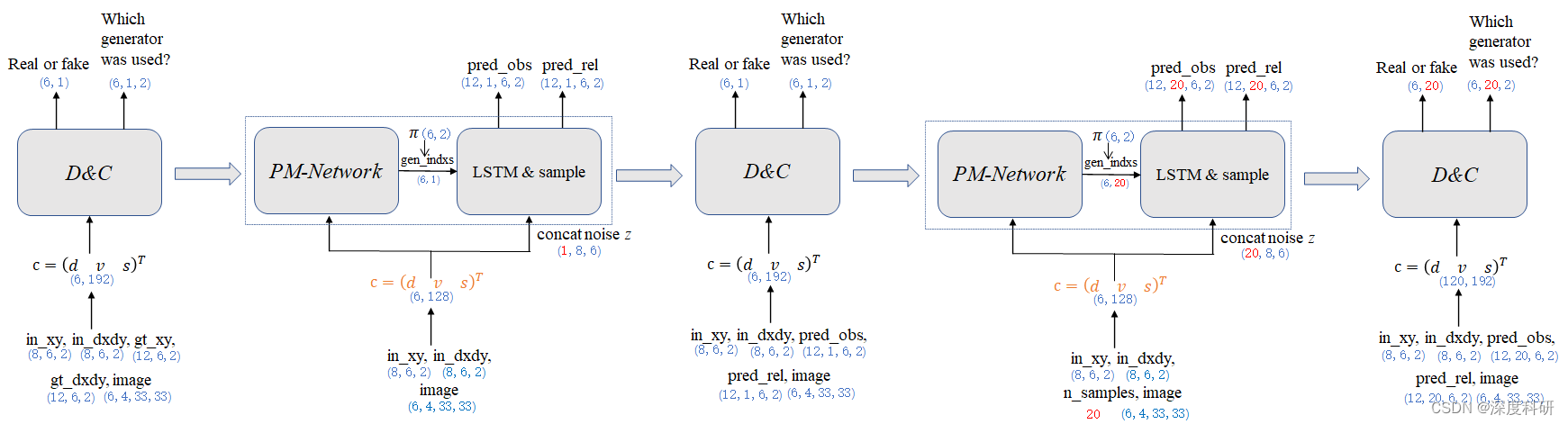
你可以看到说,MG-GAN的整体架构就是discriminator_step与generator_step的组合。 那在loss的处理上,借鉴同样的思想,我们也可以从这两个过程中窥视loss的组合:
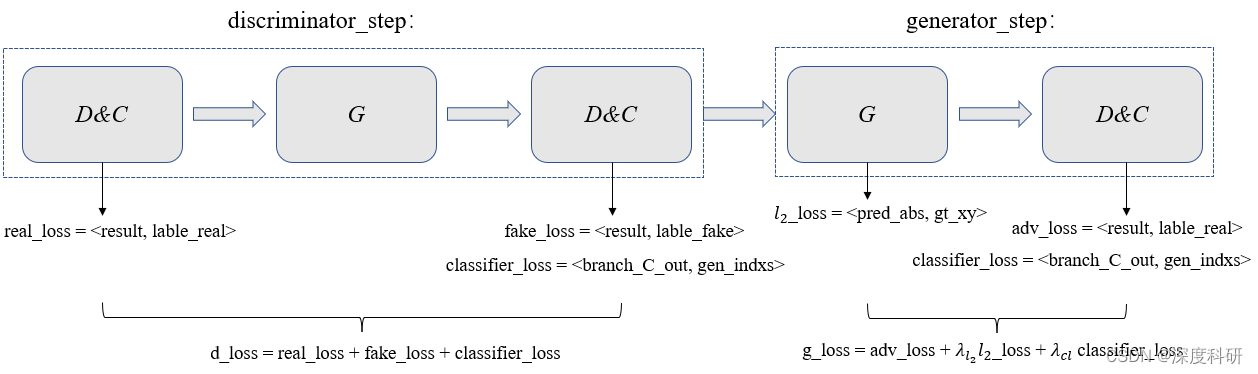 在discriminator_step阶段,用real_loss去判别判别器分类真样本的概率,real_loss越小越接近于valid。在接下来的过程中,用fake_loss去判别判别器分类假样本的概率,feak_loss越小越越接近于fake。并且,由于分类器
在discriminator_step阶段,用real_loss去判别判别器分类真样本的概率,real_loss越小越接近于valid。在接下来的过程中,用fake_loss去判别判别器分类假样本的概率,feak_loss越小越越接近于fake。并且,由于分类器承担了分类标签(用了哪个generator)的任务,所以用classifier_loss来判别分类标签的概率,并鼓励每个生成器生成与其他生成器生成的数据相分离的数据。整个discriminator_step阶段的训练损失可以表示为:
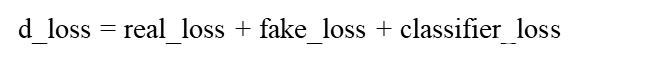
在generator_step阶段,用 loss判别预测轨迹与生成轨迹之间的差距,
loss越小,说明预测的轨迹越符合真实轨迹。在接下来的过程中, 用adv_loss来判别预测的行人轨迹“到底有多真”,adv_loss的值越小,说明判别器对预测的行人轨迹越肯定;紧接着的classifier_loss与discriminator_step阶段的classifier_loss作用相同,就不赘述了。那整个generator_step阶段的训练损失可以表示为:
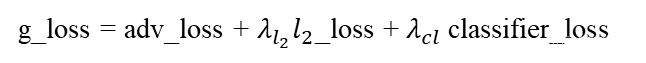
那到这里,MG-GAN 的解读就告一段落。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









