







本文旨在为读者理解和应用线性回归时提供参考。虽然线性回归算法很简单,但是只有少数人能真正理解其基本原则。最近在学习相关内容,特整理供大家共享。
本文首先会深入挖掘线性回归理论,理解其内在的工作机制,然后利用Python实现该算法,为商业问题建模。
线性回归或许是学习统计学最简单的方法。在学习更高级的方法之前,这是一个很好的入门方法。事实上,许多更高级的方法可被视为线性回归的延伸。因此,理解好这一简单模型将为将来更复杂的学习打下良好基础。
线性回归可以很好地回答以下问题:
· 两个变量间有关系吗?
· 关系有多强?
· 哪一个变量的影响最大?
· 预测的各个变量影响值能有多精确?
· 预测的目标值能有多精确?
· 其关系是线性的吗?
· 是否有交互作用?
预估系数
假设仅有一个自变量和因变量,那么线性回归表达如下:
一个自变量和因变量线性模型的方程式
在上图的方程中,两个β就是系数。在模型中预测结果需要用到这些系数。
那么,如何算出这些参数呢?
为此,需要最小化最小二乘法或者误差平方和。当然,线性模型也不是完美的,也不能准确预测出所有数据,这就意味着实际值和预测值间存在差异。该误差能用以下方程简单算出:
线性回归或许是学习统计学最简单的方法。在学习更高级的方法之前,这是一个很好的入门方法。事实上,许多更高级的方法可被视为线性回归的延伸。因此,理解好这一简单模型将为将来更复杂的学习打下良好基础。
线性回归可以很好地回答以下问题:
· 两个变量间有关系吗?
· 关系有多强?
· 哪一个变量的影响最大?
· 预测的各个变量影响值能有多精确?
· 预测的目标值能有多精确?
· 其关系是线性的吗?
· 是否有交互作用?
预估系数
假设仅有一个自变量和因变量,那么线性回归表达如下:
一个自变量和因变量线性模型的方程式
在上图的方程中,两个β就是系数。在模型中预测结果需要用到这些系数。
那么,如何算出这些参数呢?
为此,需要最小化最小二乘法或者误差平方和。当然,线性模型也不是完美的,也不能准确预测出所有数据,这就意味着实际值和预测值间存在差异。该误差能用以下方程简单算出:
实际值和预测值间存在差异。该误差能用以下方程简单算出:
实际值减去预测值
但为什么要平方误差呢?
平方误差,是因为预测值可能大于也可能小于实际值,从而分别产生负或正的误差。如果没有平方误差值,误差的数值可能会因为正负误差相消而变小,而并非因为模型拟合好。
此外,平方误差会加大误差值,所以最小化平方误差可以保证模型更好。
下图有助于更好地理解这个概念:
线性拟合数据集
在上述图表中,红点是实际值,而蓝线是线性模型。灰线展现了预测值和实际值之间的误差。因此,蓝线就是灰线长度平方的最小值。
经过一系列超出本文难度的数学计算,最终可以得到以下这个方程式,用以计算参数。
x和y代表平均值
预估系数的相关性
目前已得知系数,那么如何证明系数与因变量是否相关?
最好的方法就是找到p值。p值被用于量化数据的重要性,它能判断零假设是否被否定。
什么是零假设?
所有建模任务都是在自变量和因变量存在一定关联的假设下进行的。而零假设则正好相反,也就是说自变量和因变量之间没有任何关联。
因此,算出每一个系数的p值就能得知,从数据值上来说,该变量对于预估因变量是否重要。一般来说,如果p值小于0.05,那么自变量和因变量就之间存在强烈关系。
评估模型的准确性
通过找出p值,从数据值上来说,自变量是非常重要的。
如何得知该线性模型是拟合好呢?
通常使用RSE(残差标准差)和 R 来评估模型。
RSE计算公式
R计算公式
第一个误差度量很容易理解:残差越小,模型数据拟合越好(在这种情况下,数据越接近线性关系)。
R可以衡量因变量的变化比例,并用自变量x表述。因此,假设在一个线性方程中,自变量x可以解释因变量,那么变化比例就高, R 将接近1。反之,则接近0。
多元线性回归理论
在现实生活中,不会出现一个自变量预测因变量的情况。所以,线性回归模型是一次只分析一个自变量吗?当然不是了,实际情况中采取多元线性回归。
该方程式和一元线性回归方程很像,只不过是再加上预测数和相应的系数。
多元线性回归等式。p表示自变量的个数。
评估自变量的相关性
在前文中,通过找出p值来评估一元线性回归中自变量的相关性。在多元线性回归中,F统计量将被用于评估相关性。
F统计量计算公式。n表示数据量,p表示自变量的个数。
F统计量在整个方程中计算,而p值则针对特定的自变量。如果两者有强烈的相关性,F大于1。相反,F大约等于1。
比1大多少是足够大呢?
这是一个很难回答的问题。通常,如果数据中有一个很大的数值的话,F可以仅比1大一点点,而又代表了强烈的相关性。如果数据集中的数据量很小的话,F值一定要比1大很多,才能表示强烈的相关性。
为什么在这种情况下不能使用p值呢?
因为我们拟合了许多自变量,所以我们需要考虑一个有很多自变量的情况(p值很大)。当自变量的数量较大时,通常会有大约5%的自变量的p值会很小——即使它们在统计上并不显著。因此,我们使用F统计量来避免将不重要的自变量视为重要的自变量。
评估模型准确性
和一元线性回归模型一样,多元线性回归模型的准确性也可以用R来评估。然而,需要注意的是,随着自变量数量的增加,R的数值也会增大。这是因为模型必然和训练数据拟合得更好。
但是,这并不意味着该模型在测试数据上(预测未知数据时)也会有很好的表现。
增加干扰
在线性模型中,多元自变量意味着其中一些自变量会对其他自变量产生影响。
比如说,已知一个人年龄和受教育年数,去预测她的薪资。很明显,年龄越大,受教育时长就越长。那么,在建模时,要怎样处理这种干扰呢?
以两个自变量为例:
多元线性回归中的干扰
从上式可知,我们将两个自变量相乘,得到一个新的系数。从简化的公式中可以看到,该系数受到另一个特征值的影响。
通常来说,在将干扰模型考虑在内时,也需要考虑个体特征的影响,即使在p值不重要时也要这么做。这就是分层递阶原则。该原则背后的根据是,如果两个自变量互相干扰,那么将它们个体影响考虑在内将会对建模有很小的影响。
以上就是线性回归的基本原理。接下来本文将介绍如何在Python中实现一元线性回归和多元线性回归,以及如何评估两种模型的模型参数质量和模型整体表现。
强烈建议读者在阅读本文之后动手在Jupyter notebook上复现整个过程,这将有助于读者充分理解和利用该教程。
那么开始吧!
本文用到的数据集包括在电视、广播和报纸上花费的广告费用及各自带来的销售额。
该实验旨在利用线性代数了解广告费用对销售额的影响。
导入库
利用Python编程有一个好处,就是它可以提供多个库的渠道,使得我们可以快速读取数据、绘制数据和执行线性回归。
笔者习惯于将所有必要的库放在代码的开头,使代码井然有序。导入:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import statsmodels.api as sm
读取数据
下载数据集后,将数据集放在项目文件的数据目录中,读取数据:
data = pd.read_csv(“data/Advertising.csv”)
查看数据时,输入:
data.head()
得到结果如下:
可以看到,“未命名:0”列是多余的。所以,我们把这一列删除。
data.drop([‘Unnamed: 0’], axis=1)
现在数据已经清理完毕,可以运行线性回归了!
简单线性回归
建模
使用简单线性回归建模时,这里只考虑电视广告对销售额的影响。在正式建模之前,首先查看一下数据。
可以利用matplotlib(一个常用的Python绘制库)来画一个散点图。 

电视广告费用和销售额散点图
从图中可以看到,电视广告费用和销售额明显相关。
基于此数据,可以得出线性近似。操作如下:
X = data[‘TV’].values.reshape(-1,1)
y = data[‘sales’].values.reshape(-1,1)
reg = LinearRegression()
reg.fit(X, y)
print(“The linear model is: Y = {:.5} + {:.5}X”.format(reg.intercept_[0], reg.coef_[0][0]))
就这么简单?
对的!对数据集给出一条拟合直线并查看等式参数就是这么简单。在该案例中,可以得到: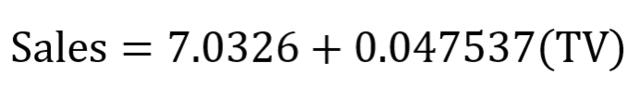
一元线性回归等式
接下来将数据拟合线可视化。
predictions = reg.predict(X)
plt.figure(figsize=(1
8))plt.scatter(data[‘TV’],data[‘sales’],c=‘black’)plt.plot(data[‘TV’],predictions,c=‘blue’,linewidth=2)plt.xlabel(“Money spent on TV ads ()")pll.ylabel("Sales()"plt.show()
可以得到:
线性拟合
从上图可以发现,一元线性回归模型似乎就可以大致解释电视广告费用对销售额的影响。
评估模型相关性
接下来是检验一个模型表现是否良好,需要查看它的R值和每个系数的p值。
输入以下代码:
X = data[‘TV’]y = data[‘sales’]
X2 = sm.add_constant(X)est = sm.OLS(y, X2)est2 = est.fit()print(est2.summary())
可以得到如下输出:

R值和p值
观察两个系数可以发现,p值虽然并不一定是0,但是非常低。这意味着这些系数和目标值(此处即销售额)之间有很强烈的联系。
同时可以观察到,R值为0.612。这说明大约60%的销售额变化是可以由电视广告花费来解释的。这样的结果是合理的。但是,这一定不是可以用来准确预测销售额的最好的结果。在报纸和广播广告上的花费必定对销售额有一定的影响。
接下来将检测多元线性回归模型是否能取得更好的结果。
多元线性回归
建模
和一元线性回归的建模过程一样,定义特征值和目标变量,并利用scikit-learn库来执行线性回归模型。
Xs = data.drop([‘sales’, ‘Unnamed: 0’], axis=1)
y = data[‘sales’].reshape(-1,1)
reg = LinearRegression()
reg.fit(Xs, y)
print(“The linear model is: Y = {:.5} + {:.5}*TV + {:.5}*radio + {:.5}*newspaper”.format(reg.intercept_[0], reg.coef_[0][0], reg.coef_[0][1], reg.coef_[0][2]))
就是这么简单!根据上述代码可以得到如下等式:
多元线性回归等式
当然,由于一共有四个变量,这里无法把三种广告媒介对销售额的影响可视化,那将需要一个四维图形。
需要注意的是,报纸的系数是负数,并且很小。这和模型有关吗?为了回答这个问题,我们需要计算模型的F统计量、R值以及每个系数的p值。
评估模型相关性
正如你所想,这一步骤和一元线性回归模型中的相应步骤非常相似。
X = np.column_stack((data[‘TV’], data[‘radio’], data[‘newspaper’]))
y = data[‘sales’]
X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
可以得到:
多元线性回归
建模
和一元线性回归的建模过程一样,定义特征值和目标变量,并利用scikit-learn库来执行线性回归模型。
Xs = data.drop([‘sales’, ‘Unnamed: 0’], axis=1)
y = data[‘sales’].reshape(-1,1)
reg = LinearRegression()
reg.fit(Xs, y)
print(“The linear model is: Y = {:.5} + {:.5}*TV + {:.5}*radio + {:.5}*newspaper”.format(reg.intercept_[0], reg.coef_[0][0], reg.coef_[0][1], reg.coef_[0][2]))
就是这么简单!根据上述代码可以得到如下等式:
多元线性回归等式
当然,由于一共有四个变量,这里无法把三种广告媒介对销售额的影响可视化,那将需要一个四维图形。
需要注意的是,报纸的系数是负数,并且很小。这和模型有关吗?为了回答这个问题,我们需要计算模型的F统计量、R值以及每个系数的p值。
评估模型相关性
正如你所想,这一步骤和一元线性回归模型中的相应步骤非常相似。
X = np.column_stack((data[‘TV’], data[‘radio’], data[‘newspaper’]))
y = data[‘sales’]
X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
可以得到:
多元线性回归
建模
和一元线性回归的建模过程一样,定义特征值和目标变量,并利用scikit-learn库来执行线性回归模型。
Xs = data.drop([‘sales’, ‘Unnamed: 0’], axis=1)
y = data[‘sales’].reshape(-1,1)
reg = LinearRegression()
reg.fit(Xs, y)
print(“The linear model is: Y = {:.5} + {:.5}*TV + {:.5}*radio + {:.5}*newspaper”.format(reg.intercept_[0], reg.coef_[0][0], reg.coef_[0][1], reg.coef_[0][2]))
就是这么简单!根据上述代码可以得到如下等式:
多元线性回归等式
当然,由于一共有四个变量,这里无法把三种广告媒介对销售额的影响可视化,那将需要一个四维图形。
需要注意的是,报纸的系数是负数,并且很小。这和模型有关吗?为了回答这个问题,我们需要计算模型的F统计量、R值以及每个系数的p值。
评估模型相关性
正如你所想,这一步骤和一元线性回归模型中的相应步骤非常相似。
X = np.column_stack((data[‘TV’], data[‘radio’], data[‘newspaper’]))
y = data[‘sales’]
X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
可以得到:
R值,p值和F统计量
可以看到,多元线性回归模型的R值比一元线性回归模型要高得多,达到了0.897!
其F统计量为570.3。这比1要大得多。由于本文使用的数据集比较小(只有200个数据),这说明广告花费和销售额之间有强烈的联系。
最后,由于本文只用了三个自变量可以利用p值来衡量它们是否与模型相关。从上表可以发现,第三个系数(即报纸广告的系数)的p值比另外两个要大。这说明从数据来看,报纸广告花费并不重要。去除这个自变量可能会使R有轻微下降,但是可以帮助得到更加准确的预测结果。
线性回归模型也许不是表现最好的模型,但了解线性回归是非常重要的,这将帮助我们打好基础,理解更加复杂的统计学方法。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









