




 本文深入探讨了 Python 中的并发模型,包括线程、进程和协程,以及臭名昭著的全局解释器锁 (GIL)。通过示例介绍了并发 Hello World,展示了在不同并发模型下的实现。强调了 GIL 对于 CPU 密集型任务的影响,并指出多进程在多核环境中可以更好地利用计算资源。文章还提到了在系统管理、数据科学和服务器端开发中Python的广泛应用,并讨论了如何在这些领域克服 GIL 的限制。
本文深入探讨了 Python 中的并发模型,包括线程、进程和协程,以及臭名昭著的全局解释器锁 (GIL)。通过示例介绍了并发 Hello World,展示了在不同并发模型下的实现。强调了 GIL 对于 CPU 密集型任务的影响,并指出多进程在多核环境中可以更好地利用计算资源。文章还提到了在系统管理、数据科学和服务器端开发中Python的广泛应用,并讨论了如何在这些领域克服 GIL 的限制。
并发是同时处理很多事情。
并行是同时执行很多事情。
虽然概念不一样,但是是相关的。
一是关于程序的结构,一是关于程序的执行。
并发提供了一种构建解决方案的方法,以解决一个可能(但不一定)可并行的问题
--------Rob Pike, Co-inventor of the Go language
本章是关于如何让 Python “同时处理很多事情”。这可能涉及并发或并行编程——即使是热衷于行话的学者也不知道如何使用这些术语。我将采用上面引用的 Rob Pike 的非正式定义,但请注意,我找到了声称与并行计算有关但却是关于并发的论文和书籍。
在 Pike 看来,并行是并发的一种特例。所有并行系统都是并发的,但并非所有并发系统都是并行的。在 2000 年代初期,我们使用了在 GNU Linux 上同时处理 100 个进程的单核CPU的机器。具有 4 个 CPU 内核的现代笔记本电脑在正常、随意使用的情况下,在任何时间通常会运行 200 多个进程。要并行执行 200 个任务,您需要 200 个内核。因此,在实践中,大多数计算是并发的而不是并行的。操作系统管理数百个进程,确保每个进程都有机会获得CPU的时间,即使 CPU 本身不能同时处理4件以上的事情。
本章假设读者没有并发或并行编程的经验知识。在简单的概念介绍之后,我们将学习简单的例子来介绍和比较 Python 并发编程的核心包:threading、multiprocessing和 asyncio。
本章的最后 30% 是对第三方工具、库、应用服务器和分布式任务队列的高级概述——所有这些都可以增强 Python 应用程序的性能和可扩展性。这些都是重要的主题,但超出了一本专注于 Python 语言核心特性的书的范围。尽管如此,我觉得在 Fluent Python 的第二版中介绍这些主题很重要,因为 Python 对并发和并行计算的适用性不仅限于标准库提供的内容。这就是为什么 YouTube、DropBox、Instagram、Reddit 和其他公司在开始使用 Python 作为他们的主要语言时能够实现 大规模Web应用 的原因——尽管他们一直声称“Python 无法扩展”。
本章的新内容
本章是 Fluent Python,第二版中的新增内容。 “并发 Hello World”中的spinner示例之前在有关 asyncio 的章节中。在这里,它们得到了改进,并首次展示了 Python 的三种并发方法:线程、进程和原生协程。
除了最初出现在关于 concurrent.futures 和 asyncio 的章节中的几段之外,剩下的内容是全新的。
“Python in the multi-core world” 与本书的其余部分不同:没有代码示例。目标是提及您可能想要研究的重要工具,以实现超出 Python 标准库所能实现的高性能并发性和并行性。
伟大的架构图The Big Picture
有很多因素使并发编程变得困难,但我想谈谈最基本的因素:启动线程或进程很容易,但如何跟踪它们?
当您调用函数时,调用代码将被阻塞,直到函数返回。所以你知道函数什么时候完成,你可以很容易地得到它返回的值。如果函数抛出异常,调用代码可以用 try/except 包围相应代码以捕获错误。
当您启动线程或进程时,这些熟悉的选项将不可用:您不会自动知道它何时完成,并且返回的结果或错误信息需要先建立一些通信通道才能获取,例如消息队列。
此外,启动一个线程或进程的代价并不低,因此您不想只是为了执行单个计算并退出而启用一个进程/线程。通常,您希望通过使每个线程或进程成为进入循环并等待输入工作的“工人”来分摊启动成本。这进一步使沟通复杂化并引入了更多问题。当你不再需要worker时,你如何让worker退出?以及如何让它在不中断工作的情况下退出,留下只处理部分的数据和未发布的资源——比如打开的文件?同样,通常的答案涉及消息和队列。
启动协程代价很低。如果你使用 await 关键字启动协程,很容易得到它返回的值,可以安全地取消它,并且你有一个明确的途径来捕获异常。但是协程通常由异步框架启动,这会使它们像线程或进程一样难以监控。
最后,我们将看到,Python 协程和线程不适合 CPU 密集型任务。
这就是并发编程需要学习新概念和编码模式的原因。让我们首先确保我们在一些核心概念上保持一致。
一部分行话
以下是我将在本章的其余部分和接下来的两章中使用的一些术语。
并发
处理多个待处理任务的能力,一次或并行(如果可能)获得进展,以便它们中的每一个最终都会执行成功或失败。如果单核 CPU 运行 OS 调度器来交错执行挂起的任务,则它具有并发能力。也称为多任务处理。
并行性
同时执行多个计算的能力。这需要一个多核 CPU、多个 CPU、一个 GPU 或集群中的多台计算机中的一种。
执行单元
并发执行代码的对象的总称,每个对象都有独立的状态和调用堆栈。 Python 原生支持三种执行单元:进程、线程和协程。
进程
运行中的计算机程序实例,使用内存和 CPU 时间片段。现代桌面操作系统通常同时管理数百个进程,每个进程都隔离在自己的私有内存空间中。进程通过管道、套接字或内存映射文件进行通信——所有这些都只能携带原始字节。Python 对象必须序列化(转换)为原始字节才能从一个进程传递到另一个进程。这代价高昂,而且并非所有 Python 对象都是可序列化的。一个进程可以产生sub-processes,每个sub-process称为一个子进程。这些子进程也彼此隔离并与父进程隔离。进程允许抢占式多任务处理:也就是挂起——每个正在运行的进程周期性地允许其他进程运行。这意味着从理论上冻结的进程不能冻结整个系统。
线程
一个进程中的执行单元。当一个进程启动时,它使用一个线程:也就是主线程。一个进程可以通过调用操作系统 API 来创建更多的线程进行并发操作。进程内的线程共享相同的内存空间,其中包含活动的 Python 对象。这允许线程之间轻松共享数据,但当多个线程同时更新同一个对象时,也会导致数据损坏。与进程一样,线程也可以在操作系统调度程序的监督下启用抢占式多任务处理。线程消耗的资源少于执行相同工作的进程。
协程
可以暂停自身并稍后恢复的功能。在 Python 中,经典协程是由生成器函数构建的,而原生协程是使用 async def 定义的。“经典协程”介绍了这个概念,第 21 章介绍了原生协程的使用。 Python 协程通常在事件循环的监督下在单个线程中运行,也在同一线程中。异步编程框架(例如 asyncio、Curio 或 Trio)为基于协程的非阻塞 I/O 提供事件循环和支持库。协程支持协作多任务处理:每个协程必须使用 yield 或 await 关键字显式放弃控制,以便另一个协程可以并发(但不能并行)进行。这意味着协程中的任何阻塞代码都会阻塞事件循环和所有其他协程的执行——与进程和线程支持的抢占式多任务处理形成相反的对比。另一方面,每个协程比执行相同工作的线程或进程消耗更少的资源。
队列
一种允许我们放入和获取元素的数据结构,通常按 FIFO 顺序:先进先出。队列允许单独的执行单元交换应用程序数据和控制消息,例如错误代码和终止信号。队列的实现因底层并发模型不同而变化:Python 标准库中的 queue 包提供了队列类来支持线程,而 multiprocessing 和 asyncio 包实现了自己的队列类。queue 和 asyncio 包还包括非 FIFO 的队列:LifoQueue 和 PriorityQueue。
锁
执行单元用于同步操作并避免损坏数据的对象。在更新共享数据结构时,正在运行的代码应该持有与之相关联的锁。这向程序的其他部分发出信号,在访问相同的数据结构之前等待锁被释放。最简单的锁类型也称为互斥锁(用于互斥)。锁的实现取决于底层并发模型。
竞争
对有限资源的竞争。当多个执行单元尝试访问共享资源(例如锁或存储)时,就会发生资源竞争。当计算密集型进程或线程必须等待操作系统调度程序为它们分配 CPU 时间时,还会发生 CPU 争用。
现在让我们使用一些术语来理解 Python 对并发的支持。
进程、线程和 Python 臭名昭著的 GIL
以下是我们刚刚看到的概念如何应用于 Python 编程的十点。
- Python 解释器的每个实例都是一个进程。您可以使用 multiprocessing 或 concurrent.futures 库启动其他 Python 进程。Python 的sub-processing库旨在启动进程以运行外部程序,无需关注编写外部程序的语言。
- Python 解释器使用单线程运行用户程序和内存垃圾收集器。您可以使用 threading 或 concurrent.futures 库启动其他 Python 线程。
- 对对象引用计数和其他内部解释器状态的访问由锁控制,全局解释器锁 (GIL)。任何时候只有一个 Python 线程可以持有 GIL。这意味着在任何时候都只有一个线程可以执行 Python 代码,和CPU 内核的数量无关。
- 为了防止 Python 线程无限期地持有 GIL,Python 的字节码解释器默认每 5 毫秒暂停当前 Python 线程 ,从而释放 GIL。然后线程可以尝试重新获取 GIL,但如果有其他线程在等待它,操作系统调度程序可能会选择其中之一继续。
- 当我们编写 Python 代码时,我们无法控制 GIL。但是用 C 编写的内置函数或扩展(或任何在 Python/C API 级别接口的语言)可以在运行耗时任务时释放 GIL。
- 每个调用syscall 的 Python 标准库函数都会释放 GIL。这包括执行磁盘 I/O、网络 I/O 和 time.sleep() 的所有函数。NumPy/SciPy 库中的许多 CPU 密集型函数以及来自 zlib 和 bz2 模块的压缩/解压缩函数也都会释放 GIL。
- 在 Python/C API 级别集成的扩展也可以启动不受 GIL 影响的其他非 Python 线程。这样的GIL-free线程一般不能改变Python对象,但它们可以对支持 buffer protocol的内存底层对象进行读写,例如bytearray、array.array和NumPy数组。
- GIL 对使用 Python 线程进行网络编程的影响相对较小,因为 I/O 函数会释放 GIL,并且与读取和写入内存相比,对网络的读取或写入总是意味着高延迟。因此,无论如何,每个单独的线程都会花费大量时间等待,因此它们的执行可以交错执行,而不会对整体吞吐量产生重大影响。这就是为什么 David Beazley 说:“Python 线程擅长无所事事。”
- 对 GIL 的争用会降低计算密集型 Python 线程的速度。对于此类任务,顺序的单线程代码更简单、更快。
- 要在多个内核上运行 CPU 密集型 Python 代码,您必须使用多个 Python 进程。
这是threading模块文档中的一个很好的总结:
CPython 实现细节:在 CPython 中,由于全局解释器锁,一次只有一个线程可以执行 Python 代码(即使某些面向性能的库可能会克服这一限制)。如果你想让你的应用更好地利用多核机器的计算资源,建议你使用 multiprocessing 或 concurrent.futures.ProcessPoolExecutor。但是,如果您想同时运行多个 I/O 密集型任务,线程仍然是一个合适的模型。
上一段以“CPython 实现细节”开头,因为 GIL 不是 Python 语言定义的一部分。Jython 和 IronPython 实现都没有 GIL。不幸的是,两者都落后了——仍处于 Python 2.7的阶段。高性能 PyPy 解释器在其 2.7 和 3.7 版本中也有一个 GIL——最新版本截至 2021 年 6 月。
Note:
本节没有提到协程,因为默认情况下,它们之间共享同一个 Python 线程,并且具有异步框架提供的监督事件循环,因此 GIL 不会影响协程。在一个异步程序中可以使用多个线程,但最佳实践是一个线程运行事件循环和所有协程,而其他线程可以执行特定任务。这将在“将任务委派给执行者”中解释。
现在我们了解了足够多的概念。让我们看一些代码。
并发的 Hello World
在讨论线程以及如何避免 GIL的影响 时,Python 贡献者 Michele Simionato 发布了一个类似于并发“Hello World”的示例:展示 Python 如何“一边走路一边嚼口香糖”的最简单程序。
Simionato 的程序使用multiprocessing,但我对其进行了修改以引入threading和asyncio。让我们从threading版本开始,如果您研究过 Java 或 C 中的线程,它可能看起来很熟悉。
使用threads的Spinner
下面几个例子的想法很简单:启动一个函数,在终端中动画字符的同时阻塞 3 秒,让用户知道程序正在“思考”而不是停止。
该脚本制作了一个动画spinner,在同一屏幕位置切换显示字符串“\|/-”中的每个字符。当慢计算完成时,带有spinner的那一行被清除并显示结果:answer:42。
图 19-1 显示了旋转示例的两个版本的输出:首先使用线程,然后使用协程。如果您没有电脑,请想象最后一行中的 \ 正在旋转。
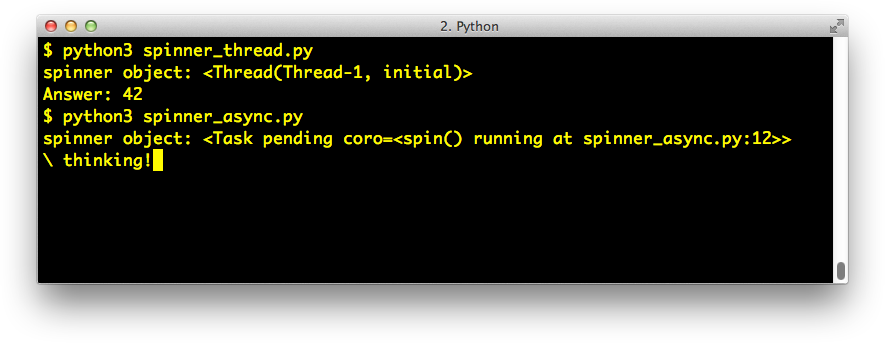
Figure 19-1. The scripts spinner_thread.py and spinner_async.py produce similar output: the repr of a spinner object and the text “Answer: 42”. In the screenshot, spinner_async.py is still running, and the animated message “/ thinking!” is shown; that line will be replaced by “Answer: 42” after 3 seconds.
让我们先看一下 spinner_thread.py 脚本。示例 19-1 列出了脚本中的前两个函数,示例 19-2 显示了其余部分。
例 19-1。 spinner_thread.py:spinner和slow函数。
import itertools
import time
from threading import Thread, Event
def spin(msg: str, done: Event) -> None: 1
for char in itertools.cycle(r'\|/-'): 2
status = f'\r{char} {msg}' 3
print(status, end='', flush=True)
if done.wait(.1): 4
break 5
blanks = ' ' * len(status)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









