



1. select()
select函数选择DataFrame的一列或者多列,返回新的DataFrame
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
data = [("James","Smith","USA","CA"),
("Michael","Rose","USA","NY"),
("Robert","Williams","USA","CA"),
("Maria","Jones","USA","FL")
]
columns = ["firstname","lastname","country","state"]
df = spark.createDataFrame(data = data, schema = columns)
df.show(truncate=False)

1.1 选择单列
df.select("firstname").show(

1.2 选择多列
df.select("firstname","lastname").show()

1.3 纵向显示
行也可以垂直显示。当行太长而无法水平显示时,纵向显示就很明显。
df.show(1, vertical=True)
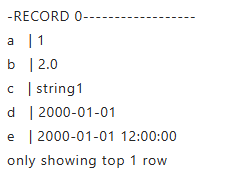
1.4 查看DataFrame格式和列名
df.columns
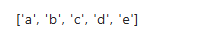
df.printSchema()

1.5 查看统计描述信息
df.select("a", "b", "c").describe().show()

DataFrame.collect()将分布式数据收集到驱动程序端,作为Python中的本地数据。请注意,当数据集太大而无法容纳在驱动端时,这可能会引发内存不足错误,因为它将所有数据从执行器收集到驱动端。
df.collect()

为了避免引发内存不足异常可以使用DataFrame.take()或者是DataFrame.tail():
df.take(1)
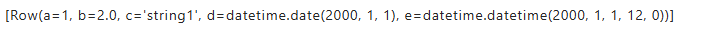
df.tail(1)
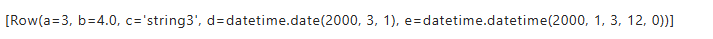
1.6 PySpark DataFrame转换为Pandas DataFrame
PySpark DataFrame还提供了到pandas DataFrame的转换,以利用pandas API。注意,toPandas还将所有数据收集到driver端,当数据太大而无法放入driver端时,很容易导致内存不足错误。
df.toPandas()
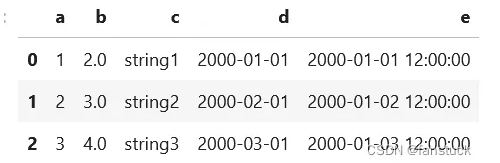
1.6 嵌套列的选择
data = [
(("James",None,"Smith"),"OH","M"),
(("Anna","Rose",""),"NY","F"),
(("Julia","","Williams"),"OH","F"),
(("Maria","Anne","Jones"),"NY","M"),
(("Jen","Mary","Brown"),"NY","M"),
(("Mike","Mary","Williams"),"OH","M")
]
from pyspark.sql.types import StructType,StructField, StringType
schema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField('state', StringType(), True),
StructField('gender', StringType(), True)
])
df2 = spark.createDataFrame(data = data, schema = schema)
df2.printSchema()
df2.show(truncate=False) # shows all columns

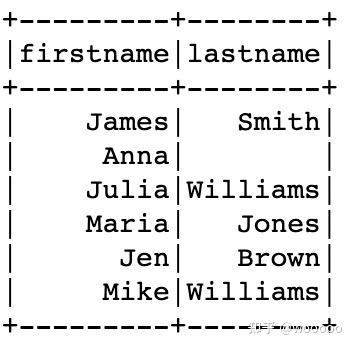
1.6.1 指定嵌套列元素
df2.select("name.firstname","name.lastname").show(truncate=False)
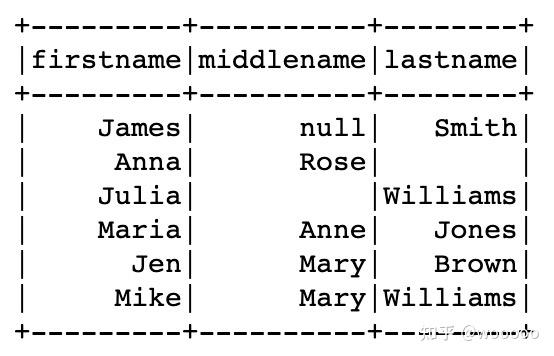
1.6.2 访问嵌套列所有元素
df2.select("name.*").show(truncate=False)
2.collect()
collect将收集DataFrame的所有元素,因此,此操作需要在较小的数据集上操作,如果DataFrame很大,使用collect可能会造成内存溢出。
df2.collect()

3.withColumn()
withColumn函数可以更新或者给DataFrame添加新的列,并返回新的DataFrame
data = [('James','','Smith','1991-04-01','M',3000),
('Michael','Rose','','2000-05-19','M',4000),
('Robert','','Williams','1978-09-05','M',4000),
('Maria','Anne','Jones','1967-12-01','F',4000),
('Jen','Mary','Brown','1980-02-17','F',-1)
]
columns = ["firstname","middlename","lastname","dob","gender","salary"]
df = spark.createDataFrame(data=data, schema = columns)
3.1 更新列的数据类型
df2 = df.withColumn("salary",col("salary").cast("Integer"))
df2.printSchema()
3.2 更新列值
df3 = df.withColumn("salary",col("salary")*100)
df3.printSchema()
3.3 添加新的列
df4 = df.withColumn("CopiedColumn",col("salary")* -1)
df4.printSchema()
# lit添加常值
df5 = df.withColumn("Country", lit("USA"))
df5.printSchema()
3.4 rename列名
df.withColumnRenamed("gender","sex").show(truncate=False)
3.5 删除列
df4.drop("CopiedColumn").show(truncate=False)
4.where() & filter()
where和filter函数是相同的操作,对DataFrame的列元素进行筛选。
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField, StringType, IntegerType, ArrayType
from pyspark.sql.functions import col,array_contains
spark = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
arrayStructureData = [
(("James","","Smith"),["Java","Scala","C++"],"OH","M"),
(("Anna","Rose",""),["Spark","Java","C++"],"NY","F"),
(("Julia","","Williams"),["CSharp","VB"],"OH","F"),
(("Maria","Anne","Jones"),["CSharp","VB"],"NY","M"),
(("Jen","Mary","Brown"),["CSharp","VB"],"NY","M"),
(("Mike","Mary","Williams"),["Python","VB"],"OH","M")
]
arrayStructureSchema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField('languages', ArrayType(StringType()), True),
StructField('state', StringType(), True),
StructField('gender', StringType(), True)
])
df = spark.createDataFrame(data = arrayStructureData, schema = arrayStructureSchema)
df.printSchema()
df.show(truncate=False)
df.filter(df.state == "OH") \
.show(truncate=False)
df.filter(col("state") == "OH") \
.show(truncate=False)
df.filter("gender == 'M'") \
.show(truncate=False)
df.filter( (df.state == "OH") & (df.gender == "M") ) \
.show(truncate=False)
df.filter(array_contains(df.languages,"Java")) \
.show(truncate=False)
df.filter(df.name.lastname == "Williams") \
.show(truncate=False)
5. dropDuplicates & distinct
二者用法相同,去重函数,即能对整体去重,也能按照指定列进行去重
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import expr
spark = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
data = [("James", "Sales", 3000), \
("Michael", "Sales", 4600), \
("Robert", "Sales", 4100), \
("Maria", "Finance", 3000), \
("James", "Sales", 3000), \
("Scott", "Finance", 3300), \
("Jen", "Finance", 3900), \
("Jeff", "Marketing", 3000), \
("Kumar", "Marketing", 2000), \
("Saif", "Sales", 4100) \
]
columns= ["employee_name", "department", "salary"]
df = spark.createDataFrame(data = data, schema = columns)
df.printSchema()
df.show(truncate=False)
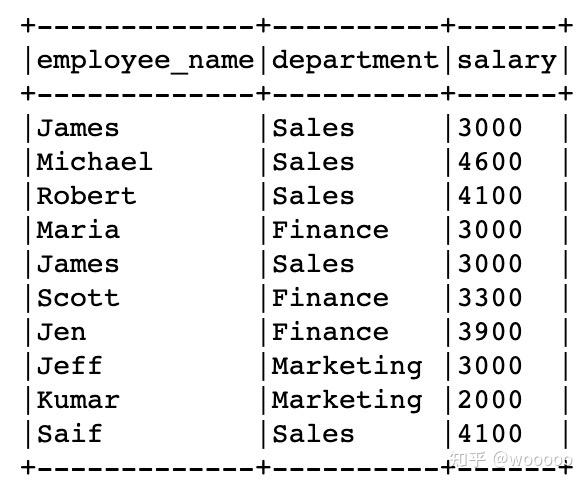
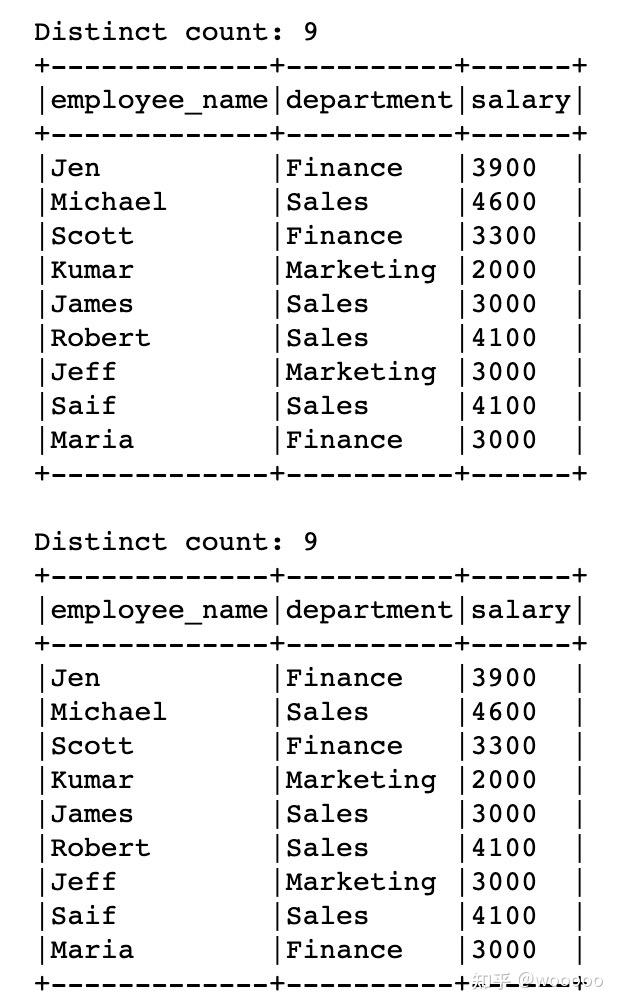
5.1 整体去重
# 整体去重,返回新的DataFrame
distinctDF = df.distinct()
print("Distinct count: "+str(distinctDF.count()))
distinctDF.show(truncate=False)
df2 = df.dropDuplicates()
print("Distinct count: "+str(df2.count()))
df2.show(truncate=False)
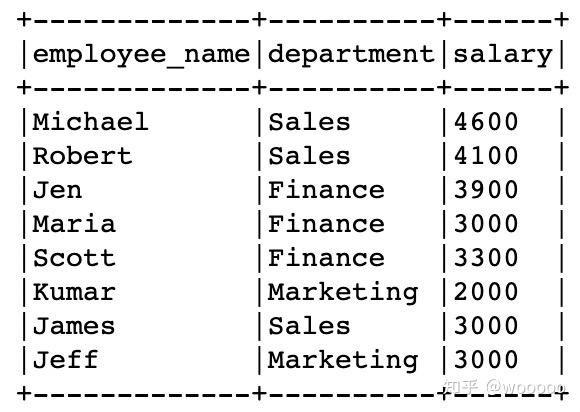
5.2 按照指定列去重
# 对部分列元素进行去重,返回新的DataFrame
dropDisDF = df.dropDuplicates(["department","salary"])
print("Distinct count of department salary : "+str(dropDisDF.count()))
dropDisDF.show(truncate=False)
6 orderBy & sort
orderBy和sort都可以指定列排序,默认为升序
df.sort("department","state").show(truncate=False)
df.sort(col("department"),col("state")).show(truncate=False)
df.orderBy("department","state").show(truncate=False)
df.orderBy(col("department"),col("state")).show(truncate=False)
6.1 指定排序方式
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("department").asc(),col("state").asc()).show(truncate=False)
df.orderBy(col("department").asc(),col("state").asc()).show(truncate=False)
df.sort(df.department.desc(),df.state.desc()).show(truncate=False)
df.sort(col("department").desc(),col("state").desc()).show(truncate=False)
df.orderBy(col("department").desc(),col("state").desc()).show(truncate=False)
6.2 通过sql排序,先创建表视图,然后再编写sql语句进行排序
df.createOrReplaceTempView("EMP")
spark.sql("select employee_name,department,state,salary,age,bonus from EMP ORDER BY department asc").show(truncate=False)
7 groupBy
通常与聚合函数一起使用
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col,sum,avg,max
from pyspark.sql.functions import sum,avg,max,min,mean,count
spark = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
simpleData = [("James","Sales","NY",90000,34,10000),
("Michael","Sales","NY",86000,56,20000),
("Robert","Sales","CA",81000,30,23000),
("Maria","Finance","CA",90000,24,23000),
("Raman","Finance","CA",99000,40,24000),
("Scott","Finance","NY",83000,36,19000),
("Jen","Finance","NY",79000,53,15000),
("Jeff","Marketing","CA",80000,25,18000),
("Kumar","Marketing","NY",91000,50,21000)
]
schema = ["employee_name","department","state","salary","age","bonus"]
df = spark.createDataFrame(data=simpleData, schema = schema)
df.printSchema()
df.show(truncate=False)
## 普通的聚合函数 sum,count,max,min等
df.groupBy("department").sum("salary").show(truncate=False)
df.groupBy("department").count().show(truncate=False)
df.groupBy("department","state") \
.sum("salary","bonus") \
.show(truncate=False)
# agg可以同时聚合多列
df.groupBy("department") \
.agg(sum("salary").alias("sum_salary"), \
avg("salary").alias("avg_salary"), \
sum("bonus").alias("sum_bonus"), \
max("bonus").alias("max_bonus") \
) \
.show(truncate=False)
# 聚合的同时进行过滤操作
df.groupBy("department") \
.agg(sum("salary").alias("sum_salary"), \
avg("salary").alias("avg_salary"), \
sum("bonus").alias("sum_bonus"), \
max("bonus").alias("max_bonus")) \
.where(col("sum_bonus") >= 50000) \
.show(truncate=False)
8 join
join类型,主要有
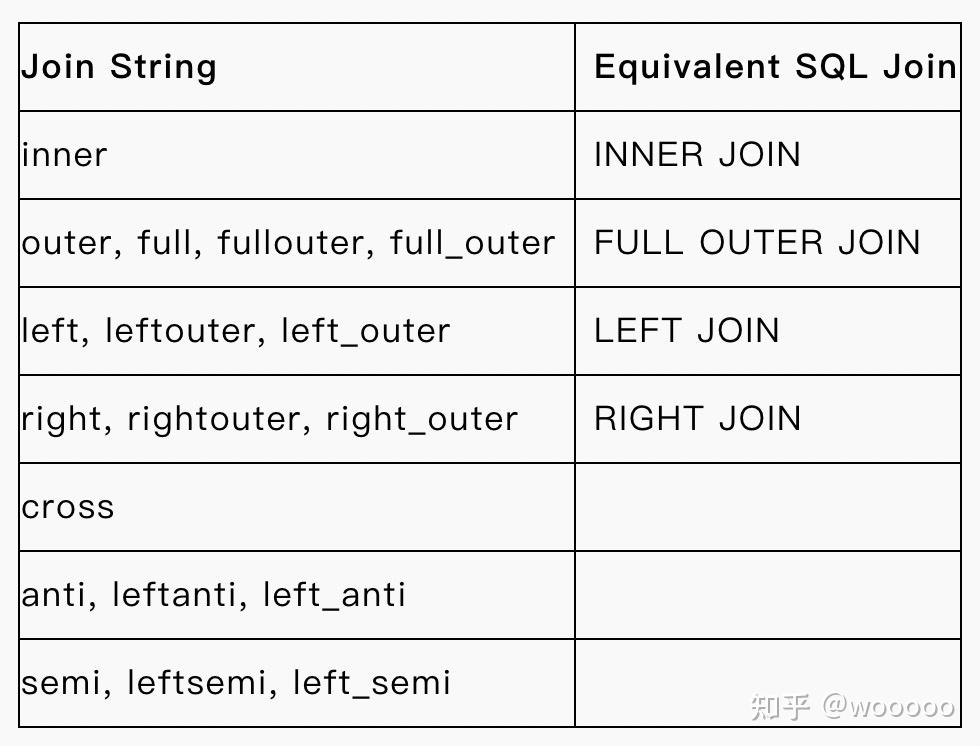
df = df1.join(df2,df1.key_id == df2.key_id,'inner')
9.获取数据输入/输出
9.1 CSV
CSV简单易用。Parquet和ORC是高效紧凑的文件格式,读写速度更快。
PySpark中还有许多其他可用的数据源,如JDBC、text、binaryFile、Avro等。另请参阅Apache Spark文档中最新的Spark SQL、DataFrames和Datasets指南。Spark SQL, DataFrames and Datasets Guide
df.write.csv('foo.csv', header=True)
spark.read.csv('foo.csv', header=True).show()
这里记录一个报错:

将Hadoop安装目录下的 bin 文件夹中的 hadoop.dll 和 winutils.exe 这两个文件拷贝到 C:\Windows\System32 下,问题解决。
9.2 Parquet
1. df.write.parquet('bar.parquet')
2. spark.read.parquet('bar.parquet').show()
9.3 ORC
df.write.orc('zoo.orc')
spark.read.orc('zoo.orc').show()


















 6442
6442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









