








PySpark - DataFrame的基本操作
- 连接spark
- 1、添加数据
- 2、修改数据
- 3、查询数据
- 3.1、行数据查询操作
- 3.1.1、show(): 可用int类型指定要打印的行数
- 3.1.2、dtypes(): 查看dataframe中每一列的类型
- 3.1.3、printSchema(): 查看dataframe中每一列的类型和是否允许为空
- 3.1.4、head()、limit()、first()和take() : 获取头几行到本地
- 3.1.5、tail(): 查看dataframe的后N行
- 3.1.6、count(): 查询总行数
- 3.1.7、取别名: dataframe.column.alias('new_col_name')
- 3.1.8、查询数据框中某列为null的行
- 3.1.9、输出list类型,list中每个元素是Row类:
- 3.1.10、describe() 和 summary(): 查看数据框中数值型列的统计情况(stddev是标准差的意思)
- 3.1.11、distinct() 和 dropDuplicates(): 去重操作
- 3.1.12、sample(): 随机抽样
- 3.2、列元素操作
- 4、提取数据
- 5、删除数据
- 6、合并数据
- 7、统计数据
- 8、格式转换
- 9、SQL操作
- 10、读写数据
ps: 笔记:20221205更新版
连接spark
ps:我使用的是单机版spark3.0版本
import socket
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
import pandas as pd
localIpAddress = socket.gethostbyname(socket.gethostname())
# 创建Spark配置
sparkConf = SparkConf()
# 初始化我们的Spark集群,这实际上会生成工作节点。
spark = SparkSession.builder.config(conf=sparkConf).getOrCreate()
sc = spark.sparkContext
sqlContext = SQLContext(sc)
spark

1、添加数据
创建spark的数据框有这么两种常规的新建数据方式:
①.createDataFrame ()
②.toDF()
1.1、createDataFrame(): 创建空dataframe
from pyspark.sql.types import *
schema = StructType([
StructField("user_id", StringType(), True),
StructField("name", StringType(), True),
StructField("age", IntegerType(), True),
StructField("score", FloatType(), True)
])
empty_dataframes = spark.createDataFrame(spark.sparkContext.emptyRDD(), schema)

1.2、createDataFrame() : 创建一个spark数据框
sdf = sqlContext.createDataFrame([("a1", "小明", 12, 56.5), ("a2", "小红", 15, 23.0),\
("a3", "小强", 23, 84.0), ("a3","小小",9,93.5)],\
("user_id", "name", "age", "score"))

1.3、toDF() : 创建一个spark数据框
from pyspark.sql import Row
row = Row("user_id","name","age","score")
row_user_id = ['a1','a2','a3','a4']
row_name = ['小明','小红','小强','小小']
row_age = [12,15,23,9]
row_score = [56.5,23.0,84.0,93.5]
sdf1 = sc.parallelize([row(row_user_id[i],row_name[i],row_age[i],row_score[i]) for i in range(len(row))]).toDF()

1.4、withColumn(): 新增数据列
withColumn是通过添加或替换与现有列有相同的名字的列,返回一个新的DataFrame
sdf2 = sdf1.withColumn('score_new',sdf1.score/2.0)

如果不想在原有列的基础上添加新的列,而是添加一列全新的,不同于原有数据框的列,可以考虑join()函数
import numpy as np
sdf3 = sqlContext.createDataFrame([("a1",3.0), ("a2",3.0), ("a3",np.nan)], ("user_id_class", "class"))

sdf4 = sdf2.join(sdf3,sdf2.user_id==sdf3.user_id_class,'left').drop('user_id_class')

2、修改数据
2.1、withColumn(): 修改原有数据框中某一列的值(统一修改)
sdf5 = sdf4.withColumn('score_new',sdf4.score_new/2)

2.2、cast() 和 astype(): 修改列的类型(类型投射)
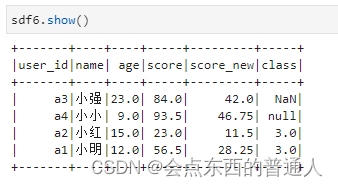
sdf6 = sdf4.withColumn('score_new',sdf4.score_new.cast("Int"))

sdf6 = sdf4.withColumn('age',sdf4.age.astype("Float"))
2.3、withColumnRenamed(): 修改列名
sdf6 = sdf6.withColumnRenamed("score_new","new_score")

2.4、fillna(): 填充NA
sdf6.fillna(-1)

2.5、replace(): 全局替换
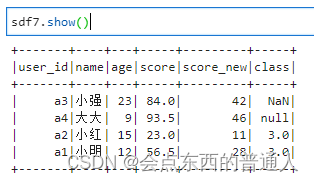
sdf7 = sdf6.replace("小小", "大大")
3、查询数据
3.1、行数据查询操作
3.1.1、show(): 可用int类型指定要打印的行数
sdf.show(5)

3.1.2、dtypes(): 查看dataframe中每一列的类型
sdf.dtypes

3.1.3、printSchema(): 查看dataframe中每一列的类型和是否允许为空
sdf.printSchema()

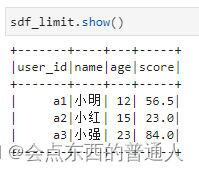
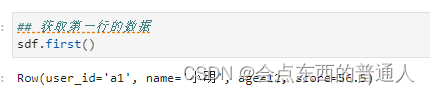
3.1.4、head()、limit()、first()和take() : 获取头几行到本地
list = sdf.head(3)

sdf_limit = sdf.limit(3)
## 获取第一行的数据
sdf.first()
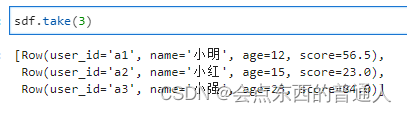
sdf.take(3)
3.1.5、tail(): 查看dataframe的后N行
sdf.tail(3)

3.1.6、count(): 查询总行数
sdf_num = sdf.count()

3.1.7、取别名: dataframe.column.alias(‘new_col_name’)
# 给age列取别名
sdf.select('user_id',sdf.age.alias('age_value'),'name').show()

3.1.8、查询数据框中某列为null的行
from pyspark.sql.functions import isnull
# 查询class列中含有空数据的那一行
sdf11 = sdf4.filter(isnull("class"))

3.1.9、输出list类型,list中每个元素是Row类:
list = sdf.collect()

3.1.10、describe() 和 summary(): 查看数据框中数值型列的统计情况(stddev是标准差的意思)
sdf.describe()

sdf.summary()

3.1.11、distinct() 和 dropDuplicates(): 去重操作
sdf.select(['user_id','name','age','score']).distinct()
sdf.select(['user_id','name','age','score']).dropDuplicates()

3.1.12、sample(): 随机抽样
sample = sdf.sample(False,0.5,2) # 随机选择50%的行,取其中两个

3.2、列元素操作
3.2.1、column: 获取数据框的所有列名
sdf.columns

3.2.2、select(): 选择一列或多列
sdf['age']
sdf.age

sdf.select('age').show() #选择sdf数据框中age列
sdf.select(sdf.user_id,sdf.age,sdf.name).show() #选择sdf数据框中user_id列,age列,name列

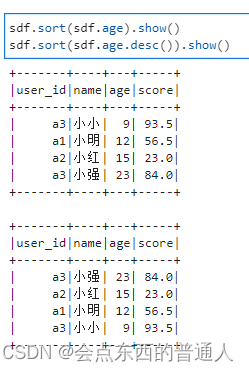
3.2.3、orderBy 或 sort: 排序
sdf.orderBy(sdf.age).show() # 根据age列升序排序
sdf.orderBy(sdf.age.desc()).show() # 根据age列降序排序

sdf.sort(sdf.age).show()
sdf.sort(sdf.age.desc()).show()
4、提取数据

4.1、将dataframe转为字典
dict_sdf = sdf.rdd.map(lambda x: x.asDict(True)).collect()

4.2、将dataframe的某一列转化为list
list_name = sdf.select('name').collect()
list = [row[0] for row in list_name]

4.3、过滤数据 : filter和where方法的效果相同
sdf7 = sdf6.filter(sdf6.age>10)

sdf7 = sdf6.where(sdf6.age>9).where(sdf6.age<23)

4.4、对null或者NaN数据进行过滤
from pyspark.sql.functions import isnan, isnull
sdf9 = sdf6.filter(isnull("class")) # 把a列里面数据为null的筛选出来(代表python的None类型)
sdf10 = sdf6.filter(isnan("class")) # 把a列里面数据为nan的筛选出来(Not a Number,非数字数据)

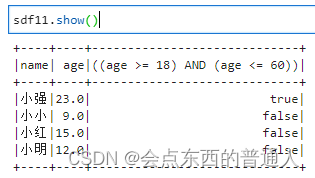
4.5、between(): 查询数据是否在某个区间
sdf11 = sdf6.select("name", "age", sdf6.age.between(18,60))
5、删除数据
5.1、drop(): 删除某一列
sdf12 = sdf.drop('age')
sdf13 = sdf.drop(sdf.age)

5.2、na.drop() 或 dropna(): 删除任何包含na的行
sdf14 = sdf5.na.drop()

# 扔掉user_id或class中任一一列包含na的行
sdf15 = sdf5.dropna(subset=['user_id','class'])

6、合并数据
6.1、横向拼接 : union()
sdf_union = sdf.union(sdf1)

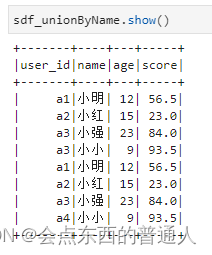
6.2、unionByName(): 根据列名横向拼接
union有一个缺点就是合并的时候是直接拼接的,如果两个sdf的列名一样,但是列的顺序不一样,这样合并起来的值没有意义
sdf_unionByName = sdf.unionByName(sdf1)
6.3、纵向拼接:join()

sdf16 = sdf5.join(sdf14, sdf5.user_id == sdf14.user_id,'inner')

PS:其中,方法可以为:inner, outer, left_outer, right_outer, leftsemi。
6.4、求差集 : subtract()
sdf17 = sdf5.subtract(sdf14)

6.5、求交集 : intersect()
sdf18 = sdf5.intersect(sdf14)

6.6、cube()与rollup(): 多维聚合
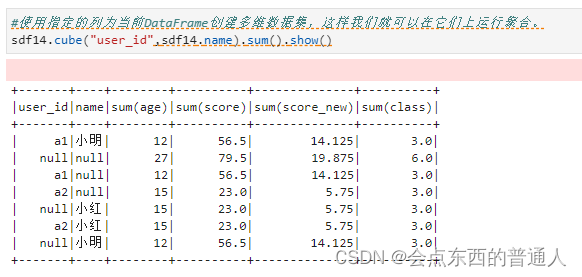
#使用指定的列为当前DataFrame创建多维数据集,这样我们就可以在它们上运行聚合。
sdf14.cube("user_id",sdf14.name).sum().show()
#使用指定的列为当前DataFrame创建多维数据集,这样我们就可以在它们上运行聚合。
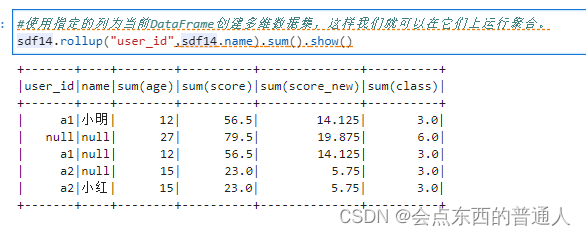
sdf14.rollup("user_id",sdf14.name).sum().show()
7、统计数据
7.1、交叉统计 : crosstab()
# 分析关于name列在class列中各个不同的值的数量
sdf19.crosstab('name','class')

7.2、分组统计 : groupBy()
先创建一个案例数据框
from pyspark.sql import Row
row = Row("user_id","product_id","name","money")
row_user_id = ['a1','a2','a3','a3','a1','a2']
row_product_id = ['b1','b2','b3','b1','b2','b3']
row_name = ['小明','小红','小强','小强','小明','小红']
row_money = [56.5, 23.0, 84.0, 93.5, 12.7, 43.5, 86.1]
sdf_gb = sc.parallelize([row(row_user_id[i],row_product_id[i],row_name[i],row_money[i]) for i in range(len(row_user_id))]).toDF()

# 分组统计不同名字的人的平均消费水平
sdf_gb.groupby('name').agg({'money':'mean'})
# 分组统计不同名字的人最大的一笔消费
sdf_gb.groupby('name').agg({'money':'max'})
# 分组统计不同名字的人最小的一笔消费
sdf_gb.groupby('name').agg({'money':'min'})
# 分组统计不同名字的人的消费总和
sdf_gb.groupby('name').agg({'money':'sum'})
# 分组统计不同名字的人一共有多少笔消费
sdf_gb.groupby('name').count()


7.3、应用于多个函数
PS:整合后GroupedData类型可用的方法(均返回DataFrame类型):
- avg(*cols) —— 计算每组中一列或多列的平均值
- count() —— 计算每组中一共有多少行,返回
- DataFrame有2列,一列为分组的组名,另一列为行总数
- max(*cols) —— 计算每组中一列或多列的最大值
- mean(*cols) —— 计算每组中一列或多列的平均值
- min(*cols) —— 计算每组中一列或多列的最小值
- sum(*cols) —— 计算每组中一列或多列的总和
from pyspark.sql import functions
sdf_gb.groupby('name').agg(functions.avg('money'),functions.min('money'),functions.max('money'),functions.sum('money'),functions.count('money')).show()

8、格式转换
8.1、pandas.DtataFrame 与 Spark.DataFrame两者互相转换
pandas_df = sdf.toPandas()

spark_df = spark.createDataFrame(pandas_df)

8.2、Spark.DataFrame与Koalas.DataFrame两者互相转换
import databricks.koalas as ks
koalas_df = spark_df.to_koalas()

spark_df = koalas_df.to_spark()

8.3、spark.DataFrame与RDD两者相互转换
rdd_df = spark_df.rdd
rdd_df.collect()

saprk_df = rdd_df.toDF()

9、SQL操作
9.1、createOrReplaceTempView():创建临时视图
为spark.DataFrame创建一张能进行SQL操作的表:
sdf.createOrReplaceTempView("sdf_SQL")
9.2、正常的查询语句
将spark.DataFrame注册成相关名字的SQL表之后:就可以进行SQL查询了(返回DataFrame):
select_sql = "select * from sdf_SQL where name like '%{}%' and score>{}".format('小',60)
Spark_dataframe = spark.sql(select_sql)

9.3、转换某一列的时间格式
sdf_date = sqlContext.createDataFrame([("a1", "小明","2020-09-01 23:00:00"),\
("a2", "小红","2020-09-02 13:00:00"),\
("a3", "小强", "2020-09-03 03:00:00"),\
("a4","小小","2020-09-04 23:00:00")],\
("user_id", "name","date_time"))

将date_time这一列的时间从精确到秒修改为精确到日:
import pyspark.sql.functions as F
sdf_date1 = sdf_date.select('user_id','name',F.date_format('date_time','yyyy-MM-dd')).withColumnRenamed('date_format(date_time, yyyy-MM-dd)','date_time')

同理,也可以将精确到日修改为精确到秒(默认为凌晨12点整):
sdf_date2 = sdf_date1.select('user_id','name',F.date_format('date_time','yyyy-MM-dd HH:mm:ss')).withColumnRenamed('date_format(date_time, yyyy-MM-dd HH:mm:ss)','date_time')

10、读写数据
10.1、spark.DataFrame与csv文件的相互转换
# 将spark.dataframe保存为csv文件
sdf.write.csv("sdf.csv",header=True,sep=",",mode='overwrite')
# 读取csv文件为spark.dataframe
sdf_spark = spark.read.csv("sdf.csv",header=True, inferSchema=True)
其中,sdf.csv文件是存储在当前目录的,如果想指定目录,把指定的路径也写上去就行。
10.2、spark.DataFrame与parquet文件的相互转换
# 将spark.dataframe保存为parquet文件
sdf.write.parquet("sdf.parquet",mode='overwrite')
# 读取parquet文件为spark.dataframe
sdf_spark = spark.read.parquet("sdf.parquet")
最后,如果大家不再进行任何操作的话,记得把spark停掉!!!
spark.stop()
















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











