







目录
先SQL SERVER-创建文件组,放在不同的磁盘上
新建数据库,选择文件组

添加文件组

以上内容为转载,我创建了一个mydatabase数据库,默认mydatebase文件组放在E盘,创建了两个文件组mydatabase1,和madatabase2放在D盘mydb文件夹。
除了文件组名,逻辑名称也需要自己起,路径自己改,文件类型为行数据,其他不用改。
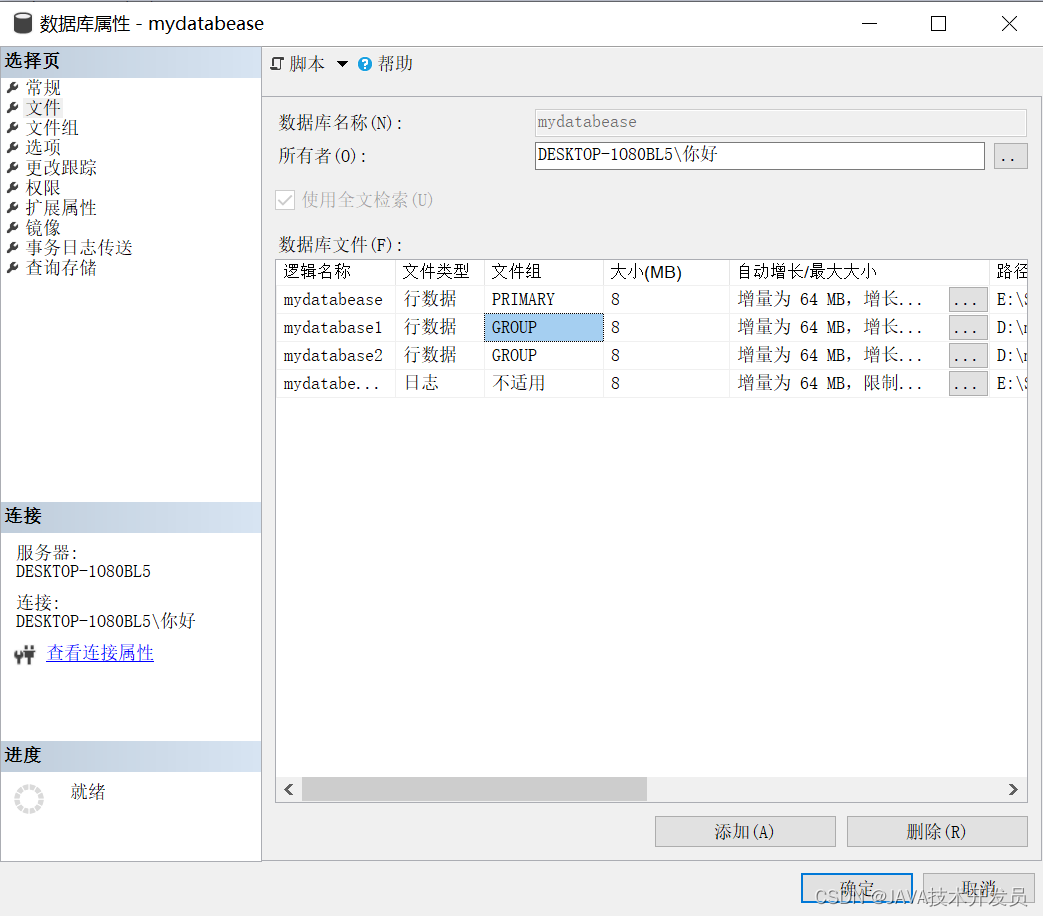
导入数据
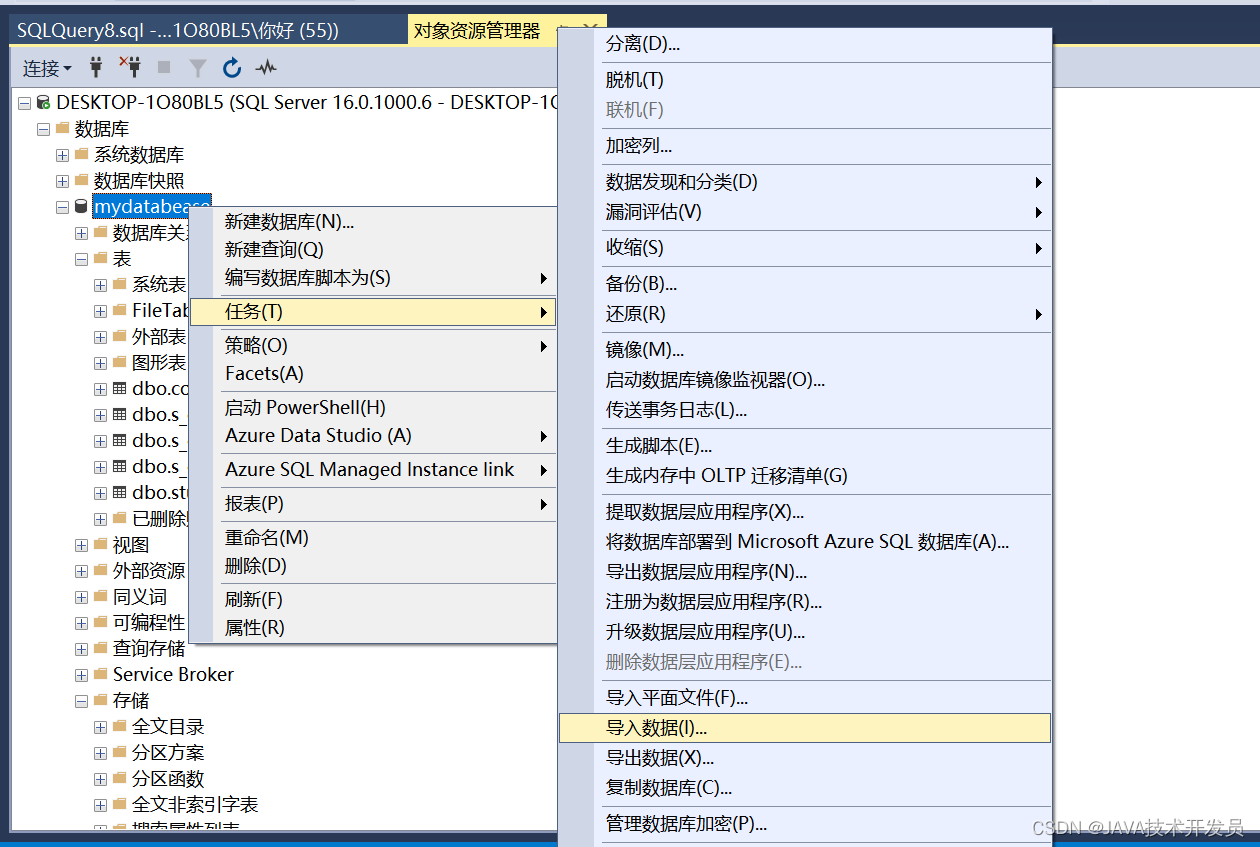
由于我要导入的是.csv文件,所以数据源选择Flat File Source
下面要选.csv文件

选择要导入的文件后,点左边菜单里的高级,设置各列的数据类型 ,默认都是字符串,所以有的INT类型需要自己改,我选的四字节不带符号的整数。(根据自己需要改)

选择目标如下
之后一路NEXT就可以了,或者直接Finnish就可以了。
定义分区
定义分区函数
存储-分区函数 目录下可以查看当前数据库中包含哪些分区函数
创建方式查看后面【定义分区表】部分
定义分区表
右键选择你要进行分区的表,选择存储-创建分区
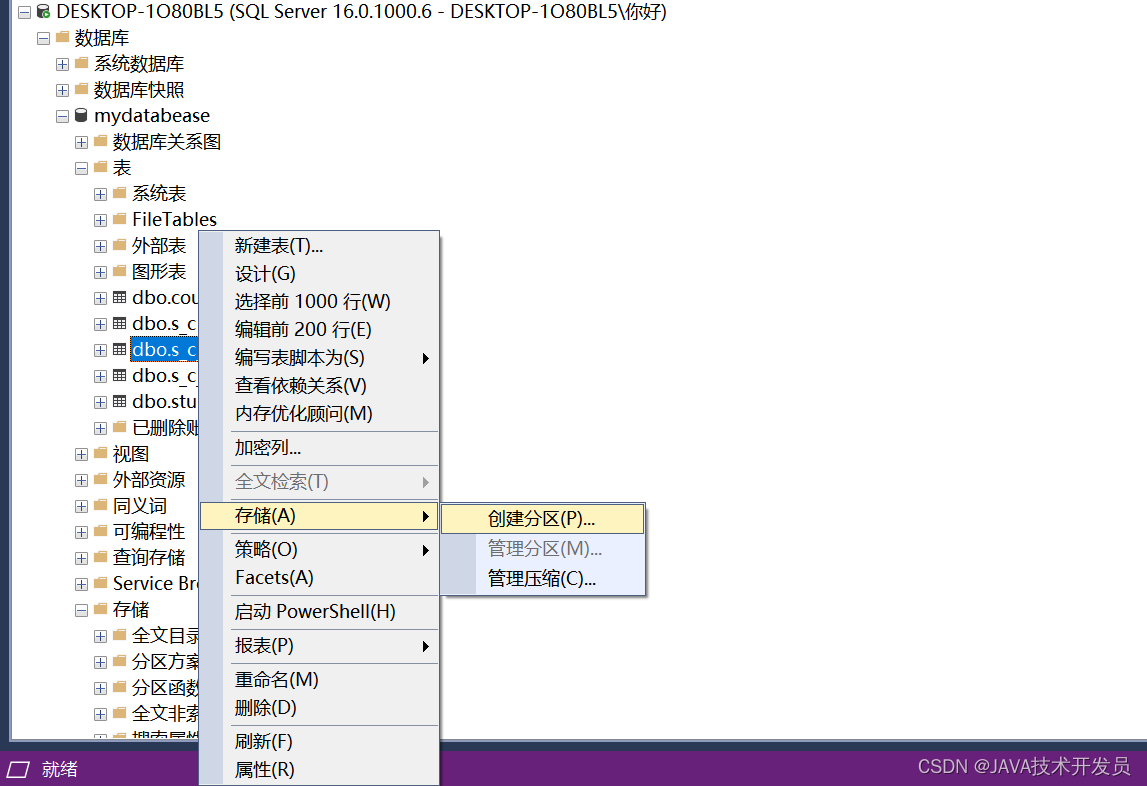
起始页直接下一步。
一般分区会按照时间或者流水号编码进行拆分,举例:这个采购流向数据通常只操作最近6个月的,历史的很少操作,这时可以按照业务日期,6个月为一组进行拆分,这里我选择采购日期。
这里我拆一下grade
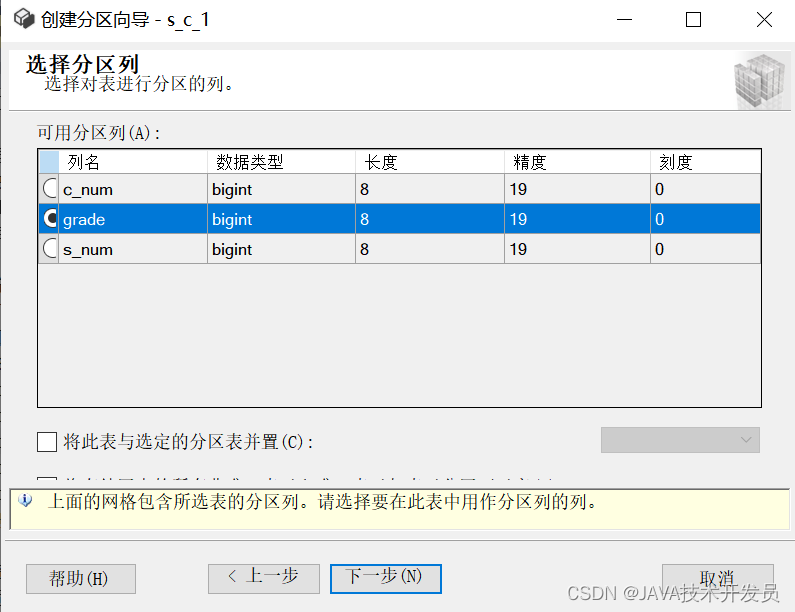
设置名称,注意增加标识符,避免和其他表名视图名等其他对象名称冲突,具体的函数内容在后面设置。
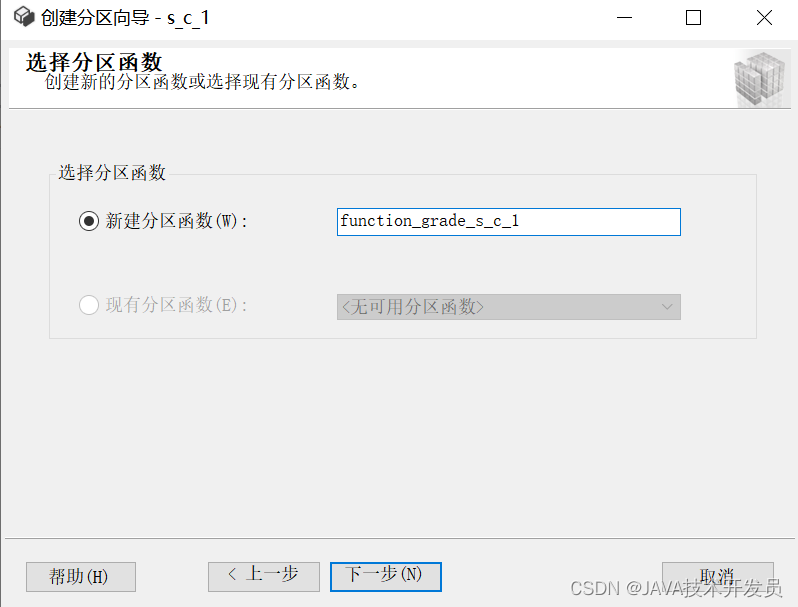
设置名称,注意增加标识符,避免和其他表名视图名等他对象名称冲突,具体的分区架构内容在下一步设置。(这里我设置成一样的)
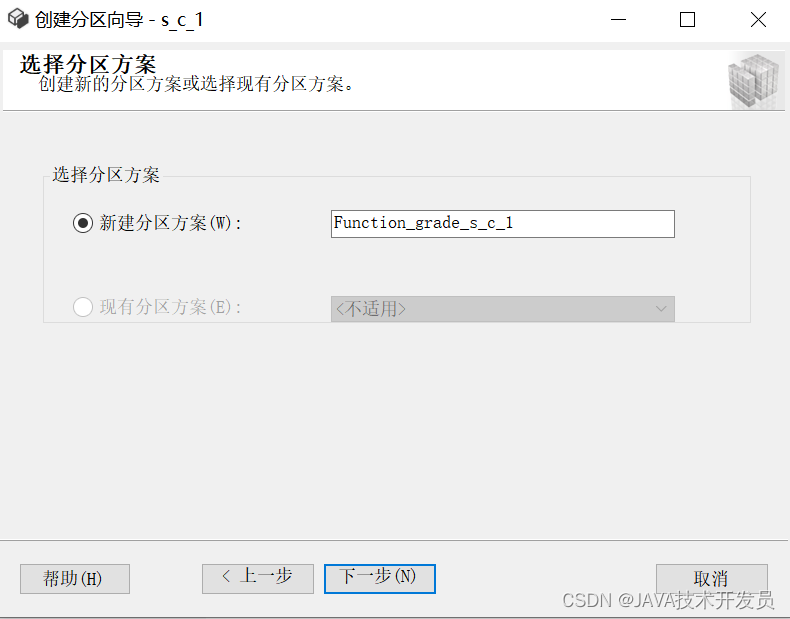
开始设置分区规则,也就是设置分区函数和分区架构(分区方案),最后一行数据的分组,一定要空着边界那列,来存储不满足分区函数规则的数据,否则提示报错,不予通过。
(右边界就是<边界为一个分区)我设置的小于60在PRIMARY文件组,和大于等于60在GROUP文件组。
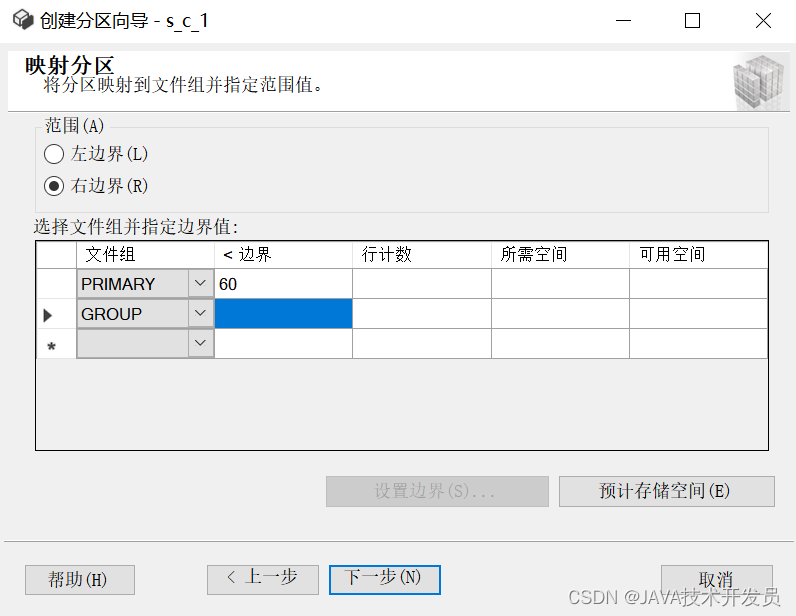
当设置完文件组和边界两列的值之后,可以点击【预计存储空间】,查看具体的数据分配计划。
也可以通过设置边界,快速拆分,前提你要创建了足够多的文件组。
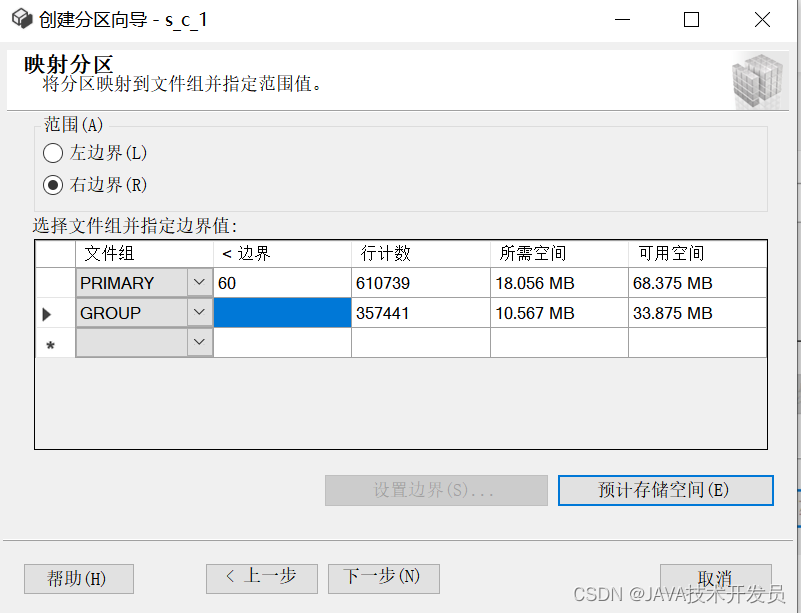
根据内容所需选择创建脚本还是立即执行,点击下一步,再点击完成,操作结束
(我点立即运行,直接分区)如果是创建脚本的话,需要自己去执行。
这样分区就完成了!
测试
先打开实时统计信息

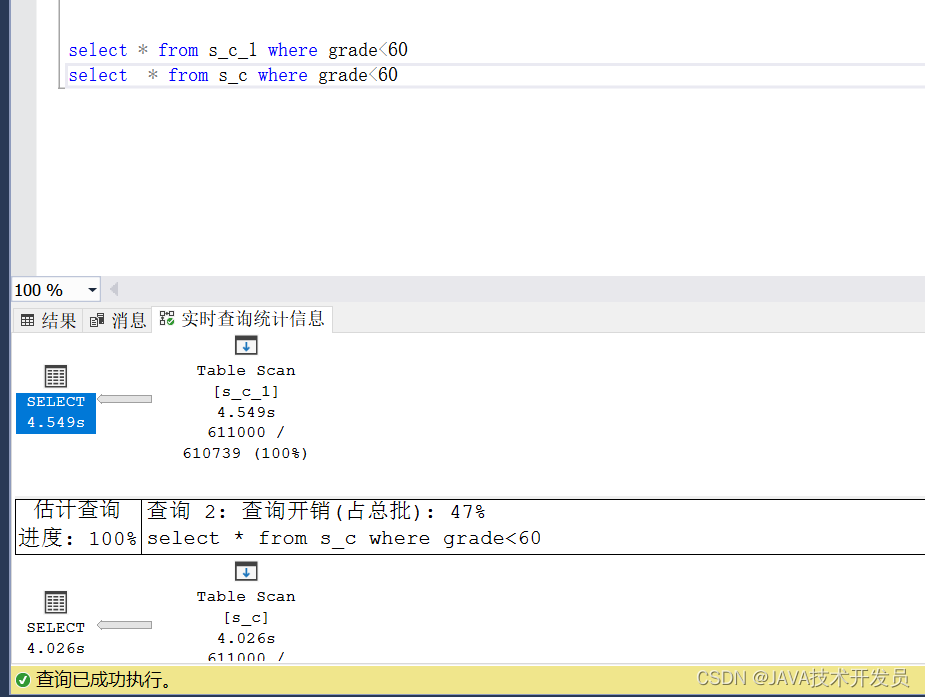
这里我导入了两个同样的表,s_c分区了。
图中分区的是s_c,要比没分区的s_c_1快一些,由于数据太少,所以差距不明显。
















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











