






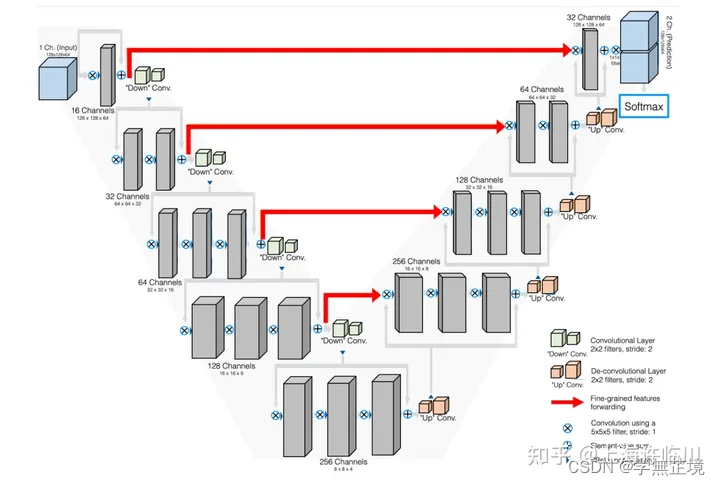
Volumetric images
Volumetric medical images, such as computed tomography (CT) scans, consist of a series of stacked two-dimensional (2D) images, allowing for more accurate representation of the three-dimensional (3D) nature of the body's anatomical structures.
Volumetric images是一种在三维空间中呈现图像的方式,也可以被理解为3D图像或者立体图像。常见的如CT或MRI(核磁共振)扫描结果,它们能够从各个角度和深度呈现出人体内部的结构。
传统的2D图像以高度和宽度两个方向来呈现信息,而volumetric images则增加了一个深度的维度,可以捕捉更多的空间信息。在一些医疗图像分析的应用中,使用volumetric images可以更好地理解和诊断患者的病情。
V-Net网络是一种利用volumetric images进行三维图像分割的卷积神经网络。该网络的主要特点是将3D图像的分割问题转化为端到端训练的问题,通过学习3D图像中的信息来预测每个体素(3D中的像素)的标签。
Exponential Logarithmic Loss
Wong等人建议使用Dice Loss指数对数形式与交叉熵Loss指数对数形式的加权和。主要解决Dice损失对小目标分割计算不佳的问题。因为对于较小目标一旦分割错误就会引起dice系数的大幅下降。对于出现频率较高的类别赋予较低权重,而对出现频率较小的类别赋予更高权重,这样就有效解决了小目标分割的问题。
重叠度量(Overlap metric)
图像分割(尤其是医学图像)中的一个重要问题是克服类的不平衡,对此,基于重叠度量的方法在克服不平衡方面表现得相当好.
类的不平衡是指在分类问题中,不同类别的样本数量存在显著差异的现象。在医学图像分割中,这通常表示的是目标对象(如病灶)的像素数远少于背景像素数。这种状况下,如果直接使用标准的机器学习和深度学习方法,可能会导致模型偏向于预测占主导地位的类,也就是说模型倾向于将大多数像素预测为背景,从而忽视了我们实际关心的目标对象。因此,克服类的不平衡对于医学图像分割尤为重要。
基于重叠度量的方法在克服不平衡方面的确表现得相当好。它通过一种特殊的度量方式--重叠度量(Overlap metric),衡量分割结果与真实目标的重叠程度,而不是简单的计算准确度。这样做的目标是让模型更关注少数类,降低了类不平衡带来的负面影响,从而能得到更准确的分割结果。
解决类的不平衡
即在损失函数中提供权重/惩罚项的小前景与大背景。其他方法包括首先确定感兴趣的对象,围绕这个对象进行裁剪,然后用更均衡的方法执行任务(例如。 分割),然后用更好的平衡类来执行。
图像分割网络的计算复杂度降低
Computational Complexity Reduction for Image Segmentation Networks
在减少深度分类网络的时间和计算复杂度方面已经做了一些工作。通过张量分解、通道剪枝、网络剪枝或者网络连接稀疏化等方式简化网络结构以及NAS(network architecture search).
Yu et al. 通过提出空间和上下文路径来保存丰富的空间信息并获得大的感受野,从而解决了与U形架构中的高分辨率特征地图相关联的高计算成本。
一些方法集中于深度图像分割网络的复杂性优化。
Liu et al. 提出了一种通过执行cell和network-level搜索来进行语义图像分割的分级神经架构搜索。
Chen et al. 侧重于使用随机搜索来搜索小得多的atrous spatial pyramid pooling module。
深度方向可分离卷积(Sifre,2014;Chollet,2017)提供了计算复杂度的降低,因为它们具有更少的参数,因此也被用于深度分割模型(Chen et al,2018b;Sandler et al,2018)。
除了网络架构搜索,Srivastava et al.通过connection来控制信息流修改了ResNet。
Lin et al. 采用一步融合,无需滤波通道。
基于注意力的语义图像分割
Attention-based Semantic Image Segmentation
Li等人提出了一种基于金字塔注意力的网络用于语义分割。他们结合了注意力机制和空间金字塔,以提取精确的密集特征进行像素标记,而不是复杂的扩张卷积和人为设计的解码器网络。 Chen等[22]将注意力集中在采用多尺度输入的DeepLab上。
多模态医学影像融合方法研究
多模态医学影像是指使用不同成像技术采集的同一生物体的医学图像。这些成像技术包括CT(计算机断层扫描)、MRI(磁共振成像)、PET(正电子发射断层扫描)、SPECT(单光子发射计算机断层扫描)等。这些成像技术各有优劣,能够提供不同的特性和信息,比如结构信息,功能信息,生物化学过程信息等。多模态医学影像融合就是将这些不同源的医学影像融合在一起,提供更全面的信息。
多模态医学影像融合方法主要有以下三类:
1. 像素级融合:直接在像素级别进行融合,这是最直接的方法。常用的像素级融合方法包括加权平均法,最大值法,最小值法,逻辑运算法等。
2. 特征级融合:首先从各个源图像中抽取特征,然后将特征融合在一起。这种方法能够更好地利用源图像的信息,但是抽取特征的过程可能会造成信息的丢失。
3. 决策级融合:在决策级别进行融合,这是在高级别进行融合的方法。常用的决策级融合方法包括规则融合法,模糊融合法,神经网络融合法等。
在具体实现过程中,可能需要进行图像配准,变换等操作,以确保源图像在空间上的一致性。整个融合过程需要考虑到源图像的特性,选择合适的融合方法,以获得最佳的融合效果。 多模态医学影像融合能够提供更全面的信息,促进医生对疾病的诊断和治疗,因此有着广泛的应用前景。
T1指的是“纵向弛豫时间”(自旋—晶格弛豫)。
也就是撤销磁场脉冲后,氢原子释放能量恢复平衡态,表现为纵向磁化矢量由零逐渐增大,这个矢量恢复到原来数的63%的时间就叫做“纵向弛豫时间”。
T1信号主要反映组织解剖结构方面的情况,该部位与周围组织差异大不大,差异越大,T1就越长。
比如液体、固体部分的能量释放慢,T1数值就比较长;脂肪的能量释放快,T1数值就比较短。
短T1就是强信号,图像上的颜色比较白;长T1就是弱信号,图像上的颜色比较黑。
T2指的是“横向弛豫时间”(自旋—自旋弛豫)。
是指在撤销磁场脉冲后,氢原子的横向磁化矢量会逐渐减小,减小到原来数值的37%所需要的时间,称为“横向弛豫时间”。
T2信号主要反映组织病变的性质。
长T2就是强信号(比较白),短T2就是弱信号(比较黑),正好跟T1的情况相反
T1加权像(T1WI)
T1加权像(T1WI)就是通过计算机分析,突出T1信号的差别;T2加权像(T2WI)则是突出T2信号的差别。可以反映所检查人体部位的不同特性。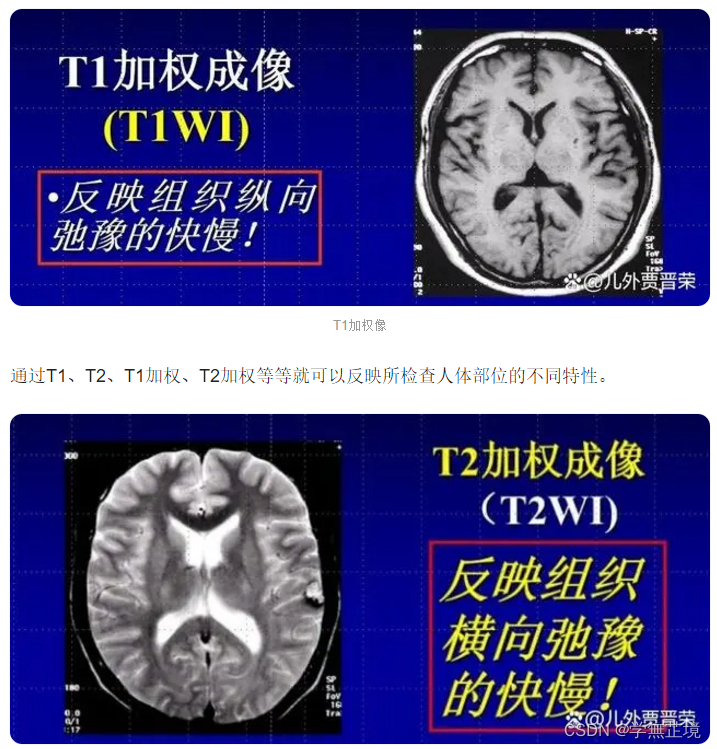
软件
horos(only Mac)
mimics
vitria
3DSlicer
存储CT扫描的存储文件类型:DICOM文件
重建方向
(一)用动脉期增强图像,重建出血管图像,叫CT血管成像(CTA),所用的方法叫最大密度投影(MIP) ;
(二)三维重建后,观察表面空间结构的方法,叫表面重建(SSD),三维空间感极强,类似解剖标本;
(三)利用三维数据,观察管腔内部表面情况,类似于内窥镜的视角,这种方法叫仿真内窥镜(VR),类似虚拟现实的技术;
(四)将横断面采集的原始图像重组成其它方向上的平面图像,如冠状位(左右)矢状位(前后)或任意斜面图像,叫多平面重建(MPR) ;
(五)将横断面的原始图像沿某解剖结构,如弯曲的肋骨、血管等,重组成一个平面图像,叫曲面重建(CPR) ;
分割算法
(问题:边界之间图像,外突 还是内凹。扫描结果切片像素点应该有区别)
(针对现有脑部磁共振图像三维重建算法难以应对切片曲率变化及曲面不连续的问题)
现有医学图像分割方法主要分为以下几类:
基于边界检测
串行检测
根据前一像素的检测结果来判断当下像素是否属于图像的边界像素。基于串行边界检测的分割方法优势在于可以得到简单、连续的边界,但其缺陷是检测结果极其依赖最开始的检测点。不同初始点会造成不同的检测结果,初始搜索点的错误选择会导致后续所有分割边缘的侧偏。
区域生长的方法、分裂合并法
并行检测
其主要思路是对图像进行平行滤波,
再通过梯度算子估计梯度图获得与之对应的梯度方向角,遍历所有梯度图的梯度值,由
中心像素四周的梯度值决定中心像素是否属于边缘。常见的并行方法分割方法有 Ghiasi等人[12]的拉普拉斯算子(Laplacian)、Wang 等人13]的索贝尔算子及 Kong 等人[14]的Laplace of Gaussian (Lo G)微分梯度算子分割
基于阈值设置
基于阈值设置的分割方法属于传统的图像分割方法,其处理思路是设定不同的特征阈值,按照不同灰度或 RGB 类别的域划分图像中的像素点,从而实现范围区域的分割
大津法 OTSU[16]是一种自适应阈值分割法,通过对图像进行二值化,按图像灰度特性划分图像的背景域和前景域。
基于卷积神经网络的分割
在医学图像处理领域中,通常将基于神经网络的分割细分为
基于像素级的语义分割算法:全卷积神经网络、基于二阶段级联的全嵌套卷积网络 HNNs
基于特征空间数据的神经网络分割算法:空间金字塔的图卷积神经网络(
Graph Convolutional Network
)
以及一些特殊的理论分割方法,例如Zheng等人[4]将马尔科夫随机场模型应用于分割或是韩哲等人[5]将遗传算法聚类应用于分割等。
重建算法
切片级三维重建研究的意义是在充分利用二维图像的前提下,以某种特定的方式进行区域整合、补片连接,实现被测物体形态的立体展示。因此,图像分割算法的精确度会对三维可视化的呈现效
果、速度及抗干扰能力等造成直接影响。
通过立方卷积插值放大图像横、纵列,随即构造空间坐标系利用顶点和面采样提取等值面,从而拓扑形成重建体的表面。
立方卷积,即3D卷积(Three-Dimensional Convolution),是卷积运算在三维矩阵(像素)上的适用。它在三个方向(长度、宽度和深度)对输入数据进行滤波。
面绘制
MC 算法
体绘制
光线投射法
Marching Cubes算法提取等值面
在医学图像三维重建中,一种常见的提取等值面(即等灰度值的二值化数据的表面)的算法是“Marching Cubes”,这是一种面采样的方法。
以下是利用Marching Cubes算法提取等值面的基本步骤:
-
数据准备:首先,获取的二维层次的医学图像被堆叠起来,形成体素(Voxel)数据集,每个体素有自己的灰度值。
-
立方体格网:将这个体素数据集分解为多个小的立方体(或者称之为“cells”),这些立方体依据体素的顶点进行创建。
-
搜索等值面:在每个cube中,根据某一个给定的等值面值,所有的体素均可以被分类为在等值面上、等值面下或等值面上。
-
生成多边形:对于在等值面上或等值面下的体素,Marching Cubes算法通过查找预定的查找表,生成一系列的三角形顶点,这些顶点将代表等值面与立方体交界的位置。
-
连接所有多边形:在所有的立方体中都执行了上述过程后,由所有立方体生成的三角形一起形成了等值面的一个近似表示。
通过等值面重建目标的表面:
-
获取数据:我们首先需要获取到三维立体的数据,如CT、MRI等医学扫描图像,这些图像通常可以被堆叠起来形成体素(Voxels)数据。
-
等值面提取:选定一个阈值,这个阈值对应于所需的等值面。这个阈值通常基于需求选择,例如,我们可能希望提取人体的骨骼结构的等值面,这时候我们就可以选择一个适当的阈值代表骨骼等值面。一种常用的等值面提取算法是Marching Cubes算法。
-
生成多面网格:Marching Cubes算法通过查找预设的查找表,生成具有等值面信息的三角形网格,这个网格表征的就是等值面与体素的交界处。这就形成了我们希望得到的重建体的表面。
-
表面重建:将所有的三角形网格连接起来,形成连续的表面。对于有噪声的数据或者希望得到平滑表面的应用,我们还可能需要对生成的表面进行去噪和平滑处理,这一步通常使用一些表面编辑或者网格平滑的算法,如Laplacian smoothing等。
-
可视化:最后,我们可以通过各种方式来将表面进行可视化,包括直接渲染,或使用光影等效果。
三维空间数据场中可视化的方法
-
直接体素(voxel)渲染:对于离散的三维空间数据,可以直接在空间中以体素的形式进行渲染,每个体素的颜色和透明度可以表示数据的属性,如温度、压力等。
-
等值面(Isosurface)或等高面(Contour surface):等值面是表示三维空间中某一特定值的二维表面,如医学图像的CT扫描中,某一种特定的灰度值可能代表了人体的某一部位,如骨头或器官。
-
箭头或向量场(Vector Field):在表示速度、方向性的物理量(如风速、电磁场等)时,可以通过在三维空间中布置一系列的箭头来表示,箭头的长度和方向表示物理量的大小和方向。
-
数据的切片(Slicing)和分割(segmentation):对于复杂的3D数据场,我们可以通过选择一个特定的平面,绘制切面分析数据,或者选择数据的子区域进行展示,减少信息的复杂度。
-
管线或流线流场(Streamlines):用于表示流体的流动路径,常用于气象、海洋、汽车空气动力学等流体领域。
-
体渲染(Volume Rendering):将数据映射为半透明的体素,使得能够深度观察到体内部的信息。
轮廓跟踪法
轮廓跟踪法(Contour Tracing)是图像处理中的一种技术,主要用于提取图像中对象的轮廓。这种方法在许多应用中都非常重要,比如物体识别、分割、匹配等。 在进行轮廓跟踪时,首先要找到一个轮廓点作为起点,然后沿着轮廓的方向逐点移动,直到回到起点,从而得到完整的轮廓。 轮廓跟踪法有许多不同的变体,包括Freeman链码、边界追踪算法、广义Voronoi图轮廓跟踪等。这些方法各有优势,可以根据实际问题选用最合适的方法。
一般步骤如下: 1. 二值化:将图像转化为二值图像,使得需要跟踪的对象和背景有明显区分。 2. 寻找起始点:选择一个位于对象边缘的点作为轮廓跟踪的起始点。 3. 跟踪轮廓:从起始点开始,根据一定的策略(如顺时针或逆时针方向)逐点追踪对象的轮廓,直到回到起始点。 4. 记录轮廓:记录得到的轮廓信息,这些信息可以用于下一步的分析或处理。
轮廓跟踪的结果,可以直观地显示出图像中的形状信息,有助于我们对图像进行进一步的分析和理解。
研究意义
可以对不同组织的区域大小、病理形态进行详尽测,量与精准定位,进而在辅助医疗中为患者提供不包含主观意识的诊断依据
具有教学意义:医学生、住院医师、研究员,3D可视化可以帮助他们更好的了了解、学习他们所研究的对象。
对患者来说很有用,有助于患者清晰了解病变位置可以帮助患者更好理解医生的治疗计划,缩短医生对患者讲解时间,加强患者对病情了解情况。
对复杂病例的术前分析很有用,需要找到病变部分的微小细节,开决定采用微创式或开放式的手术方式。3D可视化将帮助医生更好作出决定。
原型级对比学习(Prototype-level contrastive learning)
原型级对比学习(Prototype-level contrastive learning)是一种深度学习方法,它在自监督学习(self-supervised learning)的框架下工作,目的是通过比较不同的数据样本来学习更好的特征表示。
在传统的对比学习中,模型通过将正样本(相似的或相同的样本)拉近,将负样本(不同的样本)推远的方式来学习特征。这种方法通常需要大量的负样本来有效地工作。
而原型级对比学习则是在这个概念上的一种变体,它不是直接比较单个样本,而是比较样本和原型之间的相似性。这里的“原型”指的是学习到的、代表某一类或类别中心的特征向量。通过这种方式,模型可以更有效地学习区分不同类别的特征,因为它关注的是样本与其所属类别的原型之间的关系,而不是单个样本之间的差异。
具体来说,原型级对比学习的步骤包括:
-
特征提取:首先,从输入数据中提取特征表示。
-
原型表示:接着,算法会定义一组原型,这些原型代表不同类别或概念的中心点。
-
相似性度量:然后,计算样本特征和原型之间的相似性。这通常通过计算它们之间的距离(如余弦相似性)来完成。
-
损失函数:最后,定义一个损失函数,用于优化模型的参数。这个损失函数会鼓励相似的样本和其对应原型之间的相似性更高,而不相似的样本与该原型之间的相似性较低。
原型级对比学习特别适合于聚类和分类任务,因为它能够捕捉到类内的紧凑性和类间的分离性,从而提升了模型在无标签数据上的表现和泛化能力。在医学图像分析、自然语言处理等领域都有应用。

















 5703
5703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









