






-
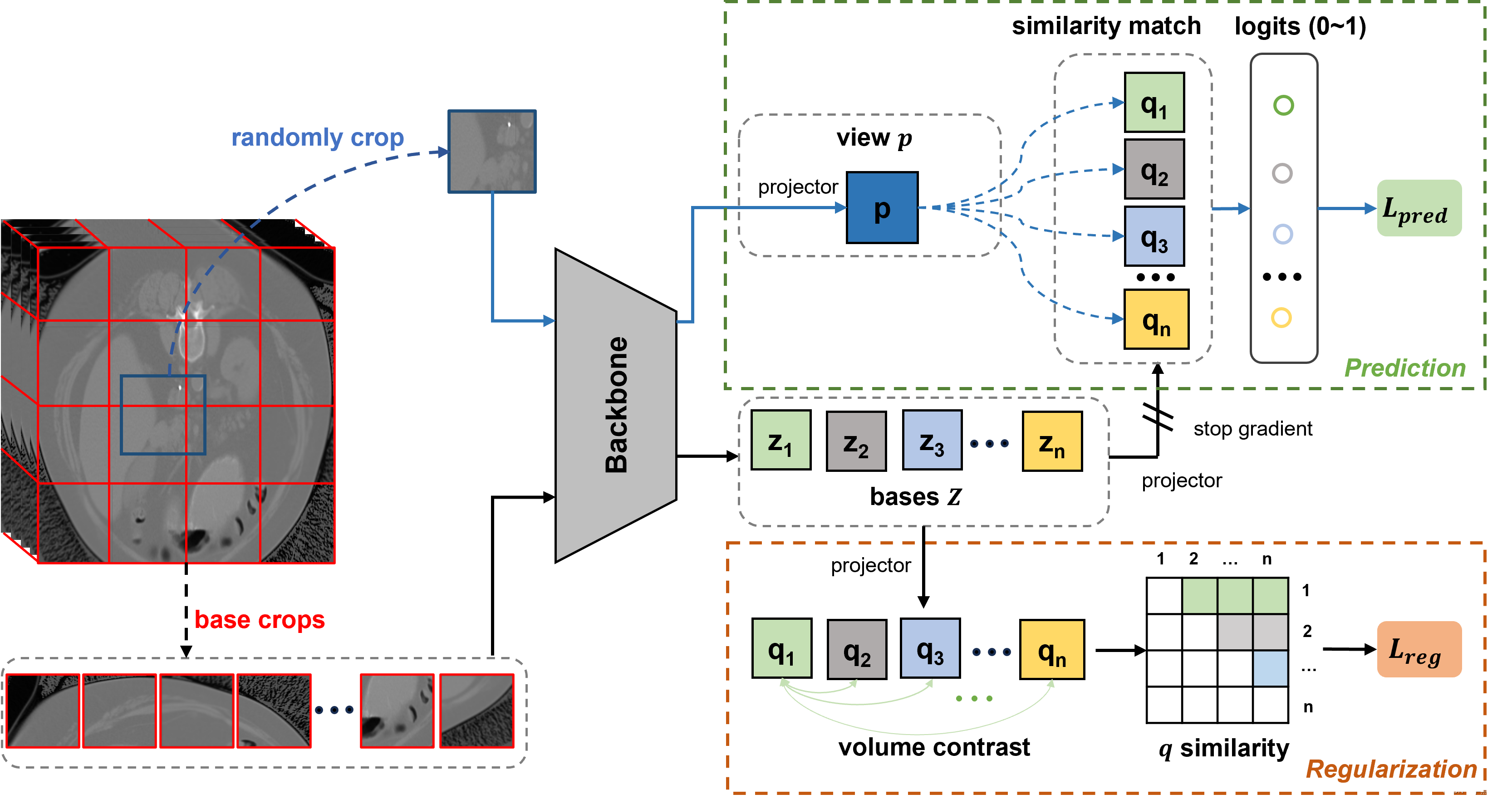
输入:一个3D医学影像被划分为更小的3D体积("基础裁剪")。从中随机选择一个体积,并进一步裁剪以为网络生成不同视图。
-
主干网络:裁剪后的体积被输入到CNN主干网络中,该网络提取特征表示(表示为基础Z,包含Z1, Z2, Z3, …, Zn)。
-
投影器:特征表示随后通过两个投影器:
- 视图投影器(P)生成相似性匹配所用的视图表示(p)。
- 体积投影器生成每个基础的查询表示(q1, q2, q3, …, qn),用于体积对比。
-
相似性匹配:视图表示(p)与查询表示(q1, q2, ..., qn)进行比较,以找到最相似的一个。这用于预测,目标是确定视图来自哪个基础裁剪。
-
Logits:视图表示和查询表示间的相似性被转换为logits,这是0到1之间的值。这些logits用于计算预测损失(L_pred)。
-
规范化:体积对比步骤强制不同体积的表示保持区分。计算不同查询表示间的相似性,并用于计算规范化损失(L_reg)。
-
损失:预测损失和规范化损失结合生成总损失,用于训练网络。
在医学影像预处理的卷积神经网络架构中,视图表示(p)和查询表示(q)是网络学习过程中的关键概念,它们代表了从输入的医学影像中提取的特征信息。
视图表示(p):
- 视图表示(p)是通过视图投影器(P)产生的,它是从原始3D医学影像中裁剪出来的较小体积(或视图)的特征表示。
- 视图表示的目的是用于相似性匹配,即网络通过比较视图表示与一系列查询表示来预测该视图来自影像的哪个部分。
- 视图表示应该捕捉到足够的信息,使得网络能够准确地与特定的查询表示匹配,从而实现准确的预测和识别。
查询表示(q):
- 查询表示(q)是由体积投影器生成的,它代表了整个3D影像中不同体积(基础裁剪)的特征表示。
- 在体积对比学习中,每个基础裁剪都会产生一个查询表示(q1, q2, q3, …, qn),这些表示用于与视图表示进行相似性匹配。
- 查询表示的目的是为了使网络能够区分来自同一3D影像内不同位置的体积,并通过比较它们的特征表示来增强网络的区分能力。
简而言之,视图表示(p)和查询表示(q)是网络为了学习如何从一个复杂的3D医学影像中提取有用特征并进行有效匹配而创建的内部表示。视图表示关注的是单个视图的特征,而查询表示则关注的是整个影像不同体积的特征,二者通过相似性匹配来共同训练网络,以提高医学影像分析的准确度和效率。
abstract
自监督学习 (SSL) 在 3D 医学图像分析中取得了可喜的成果。然而,预训练中缺乏高级语义仍然严重阻碍了下游任务的性能。我们观察到 3D 医学图像包含相对一致的上下文位置信息,即不同器官之间的一致几何关系,这导致我们在预训练期间学习一致的语义表示的潜在方法。在本文中,我们提出了一个简单而有效的体积对比 (VoCo) 框架来利用上下文位置先验进行预训练。具体来说,我们首先从不同区域的一组基本作物,同时强制它们之间的特征差异,我们将它们用作不同区域的类分配。然后,我们随机裁剪子体积,并通过对比它们与不同基本作物的相似性来预测它们属于哪个类(位于哪个区域),这可以看作是预测不同子体积的上下文位置。通过这个代理任务,VoCo 在注释的指导下隐式地将上下文位置先验编码到模型表示中,使我们能够有效地提高需要高级语义的下游任务的性能。在六个下游任务上的广泛实验结果证明了VoCo的优越性能 .
introduction
深度学习在 3D 医学图像分析 [52, 21, 39, 33] 中取得了出色的成就,但受到所需专家注释昂贵成本的严重阻碍 [49, 23]。为了解决这个问题,自监督学习 (SSL) 因其在没有注释的情况下学习表示的有前途的能力而备受关注 [10, 11, 6, 28, 20],因此成为3D医学图像分析中一个重要的标签高效解决方案。
现有的方法[49,73,69,13]大多基于信息重构来学习三维医学图像的增广不变表示,该方法首先对图像采用强数据增强,然后重构原始信息。具体来说,旋转和重构[49,50,73,51]提出随机旋转3D体积图像并学习恢复它们,这鼓励模型学习旋转不变特征。最近的方法[68,69,32,25,60]进一步提出恢复图像不同视图之间的信息。PCRL[68,69]裁剪全局和局部补丁,然后进行多尺度恢复。GVSL[32]通过仿射增强和匹配进一步探索了多扫描之间的几何相似性。Mask-reconstruct 方法 [13, 71, 54] 也被广泛使用,它是从 MAE [28] 中引入的,旨在通过掩蔽图像和重建缺失的像素来学习表示。尽管已经展示了有希望的结果,但之前的工作证明预训练中缺乏高级语义会严重阻碍下游任务的性能。为了应对这一挑战,我们认为应该进一步涉及更强大的高级语义来进行 3D 医学图像预训练。
为此,我们认为应该进一步利用 3D 医学图像的上下文位置先验。如图1(a)所示,我们观察到在3D医学图像中,不同的器官(语义区域)包含相对一致的上下文位置,具有相对一致的解剖特征(形状)。因此,不同器官之间几何关系的一致性为我们学习3D医学图像预训练的一致语义表示提供了一种潜在的方法。在本文中,我们提出了一种用于上下文位置预测的代理任务,该任务旨在将上下文位置先验编码到模型表示中,使我们能够有效地提高需要高级语义的下游任务的性能。
在本文中,我们提出了一个简单而有效的体积对比(VoCo)框架,用于三维医学图像分析,如图1(b)所示。具体来说,我们首先裁剪来自不同位置的一组非重叠体积,同时强制它们之间的特征差异。我们将这些体积表示为学习高维空间中的一组基,我们将它们用作不同位置的类分配。然后,我们随机裁剪子体积,并通过对比它们与不同基的相似性来预测它们属于哪个类(位于该位置),这可以看作是预测不同子体积的上下文位置。通过这种方式,我们为 3D 医学图像 SSL 制定了上下文位置预测代理任务。通过学习预测上下文位置,我们隐式地将高级语义先验纳入模型表示中,这使我们能够显着提高下游任务的性能。我们提出的VoCo明显优于现有的最先进的3D医学图像SSL方法。
图2:我们的VoCo遵循原型级对比学习的思想。具体来说,我们没有使用耗时的在线聚类和更新程序,而是利用 3D 医学图像的宝贵上下文位置先验并利用基础作物生成原型(基础)。
Related Works
在本节中,我们首先介绍以前的主流对比学习范式。然后,我们调查了现有的医学图像分析SSL方法,特别是对于3D医学图像。最后,我们回顾了与我们的方法比较的位置相关 SSL 方法,并强调了差异。
对比学习。对比学习是SSL的主流范式之一,旨在通过对比正样本和负样本对来学习一致的表示,而不需要额外的注释[10,6,29,11]。根据[6],实例级和原型级对比学习是两种典型的对比学习类型,如图1所示。
实例级对比学习[10,11,29,22,7]转换具有不同增强或模型扰动的输入图像,旨在比较彼此的特征。原型级对比学习 [5, 6, 55, 44, 15, 16] 建议生成原型(也称为集群或基础)以对比每个输入图像。具体来说,有两种典型的方法来生成原型。首先,Caron 等人。提出了 DeepCluster [5] 对整个数据集进行在线聚类以生成原型。然而,在大型数据集上计算集群非常耗时。因此,最近的一些工作 [6, 55, 15, 16] 提出随机初始化一组原型,然后在训练期间通过反向传播更新它们,这已经显示出有希望的结果。然而,仍然没有明确的保证这些随机初始化的原型可以在训练期间很好地更新。我们的VoCo遵循原型级对比学习的主要思想。如图2(c)所示,为了解决上述问题,VoCo不是随机初始化和更新原型,而是利用3D医学图像有价值的上下文位置先验来生成基本作物作为原型,这也不需要在大型数据集上耗时的聚类。
用于医学图像分析的 SSL。由于标签高效学习的巨大潜力[29,56,59,57,58,37],SSL在医学图像分析领域也受到了极大的关注[68,32,31,50,19]。现有的方法主要基于比较SSL[69]。具体地说,周等人。[67]将Mixup[64]结合到MoCo[29]中,以学习InfoNCE[43]中正负样本的多样性。Azizi 等人。使用多实例学习来比较每个患者的图像的多个视图。还有一些方法[25,68,69]通过从原始图像中恢复低级信息来监督模型。
在 3D 医学图像分析中,重建原始信息是学习表示的流行借口任务 [49,50, 69]。现有的方法主要基于从增强图像重构信息。这些以前的方法首先进行了强大的数据增强,例如旋转[50,73,51]、多视图作物[68,69,32]和掩码[13,71,54]。然后重建原始的3D信息来监督模型。尽管已经展示了有希望的结果,但这些方法大多仍然很大程度上忽略了将高级语义集成到模型表示中的重要性,这严重阻碍了下游任务的性能。
位置相关的SSL。在自然图像领域的许多以前的工作[8,9,40,46,42,17,62,66]中也探索了与位置相关的SSL方法。Noozi等人[42]提出预测一组洗牌补丁的顺序。Zhai等人[62]和Caron等人[8]提出训练一个ViT[18]来预测每个输入补丁的位置。然而,由于不同物体的几何关系在自然图像中不是很一致,因此仅使用视觉外观有效地学习一致的位置表示仍然很困难(如 [66] 中所述)。此外,以前的工作[62,8,66]主要训练了一个线性层来直接输出位置,这以黑盒方式工作。
在本文中,我们将上下文位置预测的借口任务引入到 3D 医学图像领域,其中不同器官之间的几何关系相对一致,引导我们在预训练中学习一致的语义表示。与之前的方法不同,在本文中,我们介绍了一种完全不同的位置预测范式。具体来说,我们没有使用线性层直接输出位置,而是基于体积对比度预测上下文位置,这是更直观和有效的。
Methodology
在本节中,我们首先在 3.1 节中介绍我们提出的 VoCo 的总体框架。之后,我们在第 3.2 节中介绍上下文位置预测的过程。然后,在我们提出的 VoCo 框架中通过体积对比的正则化过程在第 3.3 节中描述。
我们提出的VoCo整体框架如图3所示,包括一个上下文位置预测分支和一个规范化分支。预测分支用于预测不同裁剪体积之间的上下文位置。具体来说,给定一个输入体积,我们首先将其裁剪成不重叠的基础体积,这些基础体积覆盖了整个输入体积。然后,我们随机裁剪一个体积,并使用典型的主干网络(如CNN [30] 或 Transformer [18])将其变换到高维特征空间。目标是预测随机裁剪体积与基础体积之间的上下文位置。在本文中,与之前的作品[62, 9, 8, 66]中通过训练线性分类器来预测位置不同,我们提出通过体积对比来实现这一目标。我们开发了一个损失函数Lpred来监督最终的预测。此外,我们进一步使用损失函数Lreg来规范化不同基础的特征差异,通过扩大它们的距离,以学习更具区分性的类别分配。具体细节在第3.2节和3.3节呈现。
基础与随机裁剪。给定一个输入体积,我们首先将其裁剪成n个不重叠的基础体积,这些体积共同覆盖了整个输入体积。然后,我们使用提取的特征z作为类别分配(我们称之为基础),它们代表来自不同位置的原型级特征。接着,跟随之前的自监督学习(SSL)工作[10, 11, 29],一个含有线性层的投影器被用来将z投影到潜在特征q中。然后,我们随机裁剪一个体积,并将其转换为高维特征空间,表示为p。主干网络和投影器也用来投影来自随机裁剪体积的特征。
体积对比进行上下文位置预测。使用从主干网络和投影器提取的特征,跟随之前的SSL工作[10, 11, 29],我们首先进行3D自适应平均池化,将它们调整为一维,即p∈R1×C和q∈R1×C,其中C是通道数。特别是,我们根据经验将C设置为2048,如同在[10, 11, 29]中所做的。然后,我们计算p和qi之间的相似性logits l。具体来说,我们使用余弦相似度来计算l,如下所示:其中 qi 是每个基本作物的投影特征。li表示qi中p之间的相似度,取值范围为0 ~ 1。值得注意的是,在计算Eq. 1时,我们停止q的梯度,旨在避免特征崩溃[10,11,6]。
直观地说,较高的 li 表示 p 与 qi 共享重叠区域的概率更高。通过这种方式,我们可以明确地将相似度值与位置信息相关联,即具有较高 li 的 p 更有可能位于第 i 个碱基的区域。因此,我们不是训练一个黑盒线性层,而是通过体积对比来预测上下文位置,这是更直观和有效的。
位置标签生成。生成位置标签的过程如图4所示。如图4所示,当我们生成n = 4×4基作物时,将有n个类分配。然后我们计算随机裁剪的体积和 n 个基本作物之间的重叠面积。然后将重叠区域的比例指定为位置标签,范围从 0 到 1。因此,我们可以通过计算预测 logits l 和位置标签 y 之间的距离来轻松监督模型。基本作物数量 n 的设置将在第 4.4 节中讨论。
用于上下文位置预测的损失函数。预测损失函数 Lpred 的公式基于熵。具体来说,我们首先计算预测 logits l 和位置标签 y 之间的距离 d:
其中 |.|表示绝对值。然后,Lpred 是用公式表示:
值得注意的是,VoCo预测体积的上下文位置(与其所有上下文重叠体积的高度相似性),因此不需要一一对应:例如,在图4中,高值li同时属于yi>0,i=5,6,9,10。然后我们计算 li 和 yi 之间的距离(等式 2)
3.3
我们的目标是学习更具辨别力的类分配(基础)以进行体积对比。由于直观地说,不同的子体积往往包含不同的器官(语义差异)。因此,我们的目标是扩大不同碱基之间的高维特征差异。为此,我们设计了一个正则化损失 Lreg 来扩大不同基 z 之间的特征差异。
首先,给定投影基 q,我们还计算了不同 qi 和 qj 之间的余弦相似度 sij,如下所示:
我们的目标是将sij正则化为0,强制不同碱基之间的特征差异。因此,损失函数 Lreg 表示为:
其中 |.|表示绝对值。在损失 Lreg 的情况下,我们的目标是将 q 优化为线性独立的基:
利用正则化损失函数Lreg,我们的目标是学习一组线性独立的基来表示高维特征[6]的所有方向。通过这种方式,我们可以学习一组更具辨别力的类分配来监督最终的位置预测。
整体损失函数。因此,总损失函数 L 是 Lreg 和 Lpred 的组合:
其中 λ 用于平衡这两个损失项的相对贡献,并根据经验设置为 1.0,因为我们平等地考虑它们的重要性。λ 的烧蚀研究在补充材料中提供。
4. Experiments
在本节中,我们首先描述预训练和下游任务中使用的数据集。然后,我们将简要介绍 VoCo 的实现细节。最后,我们报告了我们提出的VoCo与其他最先进的3D医学图像SSL方法相比的详细实验结果。更多细节在补充材料中
预训练数据集。为了与之前的工作 [50, 54, 68, 69, 13, 71] 进行公平比较,我们还对相同的三个公共数据集(即 BTCV [35]、TCIA Covid19 [14] 和 LUNA [47] 数据集)进行了预训练实验,包括大约总共 1.6k CT 扫描进行预训练。值得注意的是,为了与之前的工作[71,13]进行公平的比较,我们只使用 BTCV [35] 和 TCIA Covid-19 [14] 在 BTCV [35] 的下游实验中进行预训练。对于其他下游任务,我们使用所有三个数据集进行预训练。详细信息在补充材料中提供。
下游数据集。为了评估我们的VoCo的有效性,我们对包括分割和分类任务在内的六个公共数据集(BTCV[35]、LiTs[4]、MSD Spleen[1]、MMWHS[72]、BraTS 21[48]和CC-CCII[65])进行了下游实验。前五个数据集用于分割,而 CC-CCII [65] 用于 COVID-19 分类。请注意,在预训练期间仅使用 BTCV [35],其他数据集在预训练期间不可见。此外,为了评估跨模态泛化能力,我们将CT数据集预训练的模型转移到MRI数据集BraTS 21[48]。我们采用与之前的作品[13,71,26,54,32]一致的设置。我们还评估了 2D 医学数据集 [53] 的性能。详细信息在补充材料中提供。
4.2
继之前的工作[50,54]。我们在所有实验中使用 AdamW [38] 优化器和余弦学习率调度器。我们在预训练过程中设置了 100K 训练步骤,并应用切片窗口推理来与之前的工作进行公平比较 [50, 54, 13, 71]。为了评估纯有效性,我们不使用基础模型或后处理[34,36]。详细信息在补充材料中提供。
比较方法。我们将 VoCo 与 General 和 Medical SSL 方法进行了比较。首先,我们与典型的SSL方法MAE[28,13]和MoCo v3[29,12]进行了比较,因为它们代表了两种主流的SSL范式,即掩码自动编码器和对比学习。由于计算成本,为 3D 医学图像设置大批量是不切实际的,为了公平比较,我们采用与 MAE [28, 13] 和 MoCo v3 [29, 12] 中其他方法一致的设置。我们还根据[13]报告了SimCLR[10]和SimMIM[61]的结果。我们进一步评估了Jiasaw[9]和PositionLabel[66]的性能,因为它们与我们的位置感知方法有关。在我们的实验中比较了大多数现有的最先进的医疗 SSL 方法。
4.3
在 BTCV 数据集上优于现有方法。我们首先对BTCV[35]进行了实验,如表1所示。具体来说,在比较方法中,MAE3D[28,13]、SimCLR[10]、SimMIM[61]、MoCo v3[29,12]和GL-MAE[71]使用UNETR[27]。包括VoCo在内的其他方法采用Swin-UNETR[26]作为以前工作[50]的默认设置。
备注。从表1可以看出,一般的SSL 方法的性能比大多数医疗SSL方法差。具体来说,MoCo v3 [29, 12] 只能达到 79.54% 的 Dice 分数。由于MoCo v3[29,12]严重依赖大批量来获取足够的负样本,由于计算负担巨大,这在3D医学图像中是不现实的。MoCo中使用的不同图像之间的负相关关系[29,12]不适用于医学图像。MAE[28,13]、SimCLR[10]和SimMIM[61]([13]的结果)也获得了有限的性能。我们的VoCo也明显优于基于位置的方法Jigsaw[9]和PositionLabel[66]。因此,我们得出结论,一般的 SSL 方法不太适合 3D 医学图像。考虑医疗SSL中医学图像的特征是至关重要的。
Note: Spl: spleen, RKid: right kidney, LKid: left kidney, Gall: gallbladder, Eso: esophagus, Liv: liver, Sto: stomach, Aor: aorta, IVC: inferior vena cava, Veins: portal and splenic veins, Pan: pancreas, AG: left and right adrenal glands.
划痕 Swin-UNETR [26] 仅达到 80.53% 的 Dice 分数。使用 VoCo 预训练,我们在 83.85% 的 Dice 分数上获得了 3.32% 的改进,这也明显优于现有方法。在比较方法中,GL-MAE [71] 获得了最高的 Dice Score (82.01%)。我们的 VoCo 将其超过 1.84% 的 Dice 分数,这是该数据集的明显改进
Unseen 数据集上的有希望的性能。我们进一步在训练前对看不见的数据集进行了实验,即 LiTs [4]、MSD Spleen [1] 和 MM-WHS [72]。LiTs[4]的结果如表2所示。我们根据[68,69,63]报告比较方法的结果。由于 scratch Swin-UNETR [26] 可以获得更高的 Dice Score (93.42%),我们进一步基于 VoCo 预训练 3D UNet [45],旨在进行公平比较。可以看出,通过VoCo预训练,Swin-UNETR[26]提高了3.10%,Dice得分为96.52%。使用3D UNet[45]作为骨干,VoCo也实现了96.03% 的 Dice 分数,证明了 VoCo 与不同网络架构的有效性。
MSD Spleen [1] 和 MM-WHS [72] 数据集的结果如表 3 所示。在以前的方法中,GVSL [32] 以 95.47% 和 88.27% 的 Dice Score 实现了最佳性能,而我们的 VoCo 在 MSD Spleen [1] 和 MM-WHS [72] 数据集上分别超过了所有以前的方法 96.34% 和 90.54% 的 Dice Score
MRI 数据集上的泛化能力。为了验证MRI数据集上的泛化能力,我们进一步评估了VoCo在BraTS 21[48]上的性能。如表 4 所示,VoCo 实现了 78.53% 的 Dice 分数,并优于现有的最先进方法,证明了 VoCo 的跨模型泛化能力。

COVID-19分类评估。我们在表 5 中进一步评估了分类任务在 CCCCII [65] 数据集上的性能。由于现有的 SSL 方法在该数据集上没有进行实验,我们重现了相关的比较方法进行比较。可以看出,VoCo 也可以以 90.83% 的准确率取得优异的成绩,证明了它在分类任务中的有效性。
4.4
我们进一步进行消融研究以评估 VoCo 中的损失函数和设置,这些设置在 BTCV [35] 和 MM-WHS [72] 数据集上得到验证。
损失函数。我们首先研究了两个损失函数(即 Lpred 和 Lreg)的重要性,如表 6 所示。可以看出,通过我们提出的 Lpred 损失函数,性能显着提高,即 BTCV 为 80.53% 至 8.96%,MM-WHS 为 86.11% 至 88.82%。这些结果证明了我们提出的位置预测借口任务的有效性。此外,通过提出的正则化损失 Lreg,可以进一步提高性能。因此,我们可以看到在 VoCo 中学习判别基至关重要。
基数数量。我们进一步评估了VoCo中基数n的不同设置。我们在消融研究中比较了不同的n设置,如表7所示。值得注意的是,由于Z方向上感兴趣区域(ROI)大小不一致,我们不实际去在Z方向上裁剪多个基数,因为我们必须在裁剪后调整体积大小,这将导致体积尺度不一致。此外,由于计算限制,增加n的值代价很大。如表7所示,当n=2×2×1时,VoCo在BTCV和MM-WHS上分别只达到了81.56%和86.73%的Dice得分。当我们将n的值增加到3×3×1和4×4×1时,性能明显提高。具体来说,当n为4×4×1时,我们在BTCV和MM-WHS上分别达到了83.85%和90.54%。然而,我们观察到更高的n(5×5×1)不能进一步带来更高的性能。我们进一步验证了在Z方向上生成基础作物的性能。可以看出3×3×2和4×4×2不能产生改进。因此,为了平衡性能和效率,我们将VoCo中的n设置为4×4×1。可见,n的设置对VoCo至关重要
5. Conclusion and Future Directions
在本文中,我们开发了一个简单而有效的 SSL 框架 VoCo 用于 3D 医学图像分析。受 3D 医学图像在不同器官之间包含相对一致的上下文位置的观察的启发,我们建议利用上下文位置先验来学习预训练中一致的语义表示。具体来说,我们从输入体积的不同位置裁剪体积,并将它们表示为一组基来表示不同方向的特征。然后,我们通过对比随机裁剪的体积与不同碱基的相似性来预测其上下文位置。通过这种方式,VoCo 有效地将上下文位置先验编码为模型表示,使我们能够有效地提高需要高级语义的下游任务的性能。大量实验表明,我们提出的 VoCo 在六个下游数据集上取得了卓越的性能
未来,我们将进一步考虑几种扩展方式:(1)扩大预训练数据集以评估 VoCo 的最佳性能。(2) 对更多下游数据集进行更多实验。(3) 评估 VoCo(例如半监督学习)的标签高效性能。(4) 我们将进一步探索VoCo在挖掘体积间关系方面的能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









