







用来放其他对象或者基本数据类型(数组本身就是一种容器)
数组优势:简单的线性序列,快速访问,效率高。
劣势:不灵活。容量需要事先定义好,因此需要更加功能强大的容器。

泛型
用来规范容器里保存数据的类型,因为不规定泛型容器中可以任何object类型。本质是数据类型的参数化,可以把泛型理解为数据类型的一个占位符(形式参数),即告诉编译器,在调用泛型时必须传入实际类型。
List接口是有序、可重复的容器。
有序:List中每个元素都有索引标记。可以根据元素索引标记访问元素。
可重复:List中允许加入重复的元素。更确切地说,list通常允许满足e1.equals(e2)的元素重复加入容器。
List接口常用的实现类有三个:ArrayList(底层数组)、LinkedList(底层链表)、和 Vector(底层也是数组,只不过线程安全)。
ArrayList
底层是用数组(占用空间连续)实现的存储。特点:查询效率高,增删效率低,线程不安全
数组扩容:ArrayList默认长度10(也可以直接定义长度),如果数组满了,就会重新定义一个比原数组大1.5倍的数组,然后把原数组的元素拷贝进来。
LinkedList
底层是用双向链表(占用空间不连续)实现的存储。特点:查询效率低,增删效率高,线程不安全
(这个不用定义容量,直接添加节点就行了,然后前驱后继连接)
Vector
底层是用数组实现的List,相关的方法都加了同步检查,因此线程安全,效率低。

Map接口(key-value)
Map就是用来存储键值对的。Map类中存储的键值对通过键来标识,所以键对象不能重复。
Map接口的实现类有HashMap、TreeMap、HashTable、Propertties。Map中键不能重复,如果重复则覆盖value。
HashMap
底层实现采用了哈希表,哈希表的基本结构就是数组+链表,这里使用的位桶数组(默认长度16)
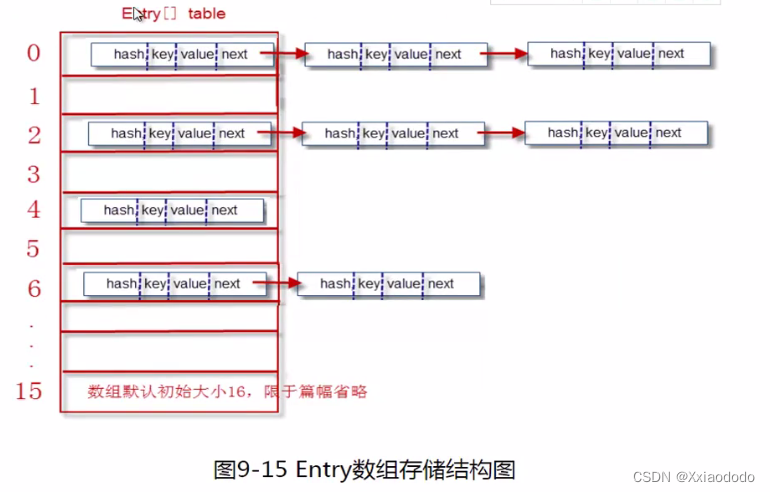
存储过程:第一步计算健对象的hashcode,第二步hashcode对数组长度取余数,计算出hash值,第三步生成entry对象,第四步根据hash,将Entry对象存储到数组索引位置。(如果有内容,就会在后面链表追加)。在JDK8中,当链表长度大于8时,链表就转换为红黑树,大大提高查找效率。
扩容问题:hashmap的位桶数组,初始大小为16。实际使用大小是可变的。如果位桶数组中的元素达到(0.75*数组长度),就重新调整数组大小为原来2倍大小。(扩容比较耗时,本质是定义新的更大的数组,并将旧数组挨个拷贝到新数组中)
TreeMap
hashmap效率比它高。是红黑二叉树的典型实现,在需要排序的Map时才选用。(类实现comparable接口,重写compareTo方法)
HashTable
HashTable和HashMap用法几乎一致,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashMap:线程不安全,效率高。允许key和value为null。
HashTable:线程安全,效率低。不允许key和value为null。
Set接口
继承collection接口,Set接口中没有新增方法。
特点:无序、不可重复。无序指的是Set元素没有索引,我们只能遍历查找,可以放入一个null元素
Set常用的实现类:HashSet、TreeSet。
HashSet
是采用哈希算法实现,底层实际是用HashMap实现的(本质就是一个简化版的HashMap,都是map的key),因此,查询效率和增删效率都很高。
TreeSet
底层实际是用TreeMap实现的,内部维持了一个简化版的TreeMap,通过key来存储Set的元素。TreeSet内部需要对存储的元素进行排序。因此,对应的类需要实现comparable接口,这样才能根据compareTo()方法比较对象之间的大小,才能进行内部排序。















 1662
1662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









