







第一章:数据载入及初步观察 + 探索性数据分析
1.1 载入数据
1.1.1 任务一:导入numpy和pandas
# 导入numpy和pandas
import pandas as pd
import numpy as np
1.1.2 任务二:载入数据
注:上传本地数据 [ 在 Jupyter 中操作需要 Upload]
(1) 使用相对路径载入数据
pd.read_csv('train.csv')
(2) 使用绝对路径载入数据
import os # 添加此头文件 否则会报错
# 查询数据集的绝对路径
os.path.abspath('train.csv')
# 载入数据
pd.read_csv('C:\\Users\\DELL\\train.csv')
相对路径:是指由这个文件所在的路径引起的跟其它文件(或文件夹)的路径关系
绝对路径:是指目录下的绝对位置,直接到达目标位置,通常是从盘符开始的路径
(3) 查看数据集头部和尾部数据
df = pd.read_csv('train.csv')
df.head()
df.tail()
(4) 数据转置
df.T
【思考】知道数据加载的方法后,试试pd.read_csv()和pd.read_table()的不同,如果想让他们效果一样,需要怎么做?
【思考回答】pd.read_table(‘C:\Users\DELL\train.csv’,sep = ‘,’)能够解决问题
pd.read_table('C:\\Users\\DELL\\train.csv')
pd.read_table() 以制表符 \t 作为数据的标志。以行为单位进行存储,所以没有分隔
pd.read_table('C:\\Users\\DELL\\train.csv',sep = ',')
【思考】了解一下’.tsv’和’.csv’的不同,如何加载这两个数据集?
【思考回答】TSV 文件和 CSV 的文件的区别是:前者使用 \t 作为分隔符,后者使用 , 作为分隔符。
1.1.3 任务三:每1000行为一个数据模块,逐块读取
# 原数据类型
type(pd.read_csv('train.csv'))
# 模块读取数据的数据类型
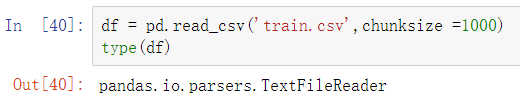
df = pd.read_csv('train.csv',chunksize =1000)
type(df)
# 逐块读取
df.get_chunk()
【思考】什么是逐块读取?为什么要逐块读取呢?
【思考回答】是将文本分成若干块;面对大量数据时,我们只想截取其中一部分来进行问题分析。
【提示】chunker(数据块)是什么类型?
1.1.4 任务四:将表头改成中文,索引改为乘客ID [对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据
# 将表头改成中文形式
# 方法一(替换)
df = pd.read_csv('train.csv')
df.columns = ['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口']
df
# 方法二(增加)
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'])
df
1.2 初步观察
导入数据后,要对数据的整体结构和样例进行概览,比如说,数据大小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









