







第二章:数据清洗及特征处理
熟悉的开始~
# 导入numpy和pandas
import pandas as pd
import numpy as np
#加载数据train.csv
df = pd.read_csv('train.csv')
df
2.1 缺失值观察与处理
2.1.1 任务一:缺失值观察
(1) 请查看每个特征缺失值个数
# 查看数据内缺失值字段
df.info()
# 查看每个特征缺失值个数
df.isnull().sum()
info()用于打印DataFrame的简要摘要,显示有关DataFrame的信息,包括索引的数据类型dtype和列的数据类型dtype,非空值的数量和内存使用情况。
info()方法最后输出的是每列不为空的数量。也就是说如果有某列数据的数量比实际的索引数量要少,说明该列存在缺少值。
注意info()和describe()的区别:
describe()函数用于生成描述性统计信息。 描述性统计数据:数值类型的包括均值,标准差,最大值,最小值,分位数等;类别的包括个数,类别的数目,最高数量的类别及出现次数等;输出将根据提供的内容而有所不同。
(2) 请查看Age, Cabin, Embarked列的数据
# 查看Age, Cabin, Embarked列的数据
df[['Age','Cabin','Embarked']] # ['Age','Cabin','Embarked'] 作为索引标签
2.1.2 任务二:对缺失值进行处理
(1)处理缺失值一般有几种思路
- 直接使用含有缺失值的特征
- 删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的时候)
- 缺失值补全
(2) 请尝试对Age列的数据的缺失值进行处理
- 均值插补
- 同类均值插补
- 建模预测
- 高维映射
- 多重插补
- 极大似然估计
- 压缩感知和矩阵补全
(3) 请尝试使用不同的方法直接对整张表的缺失值进行处理
处理缺失值的一般思路:
- 删除
- 插补(重点)
- 不处理缺失值
缺失值处理 —— 传送门
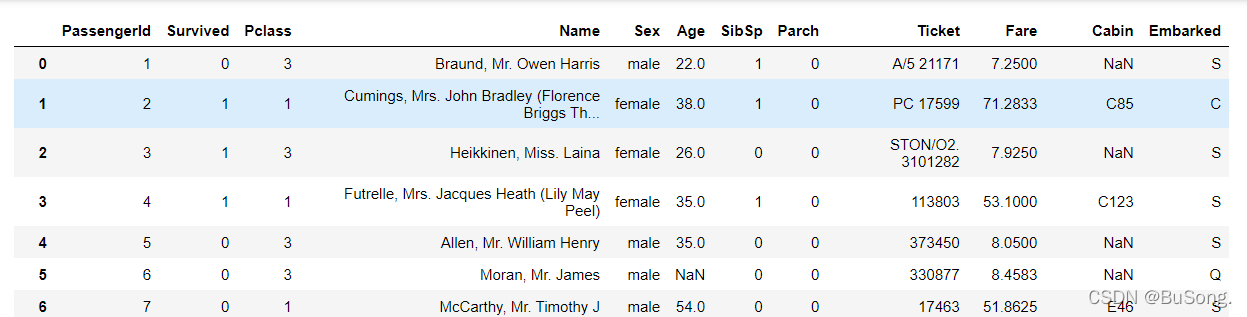
# 缺失值处理(方法一)
df[df['Age']==None]=0 # 空值部分未用“0”填充
# Age这一列的哪一行是空,就在Age那一列给它补上0
df
效果如下:
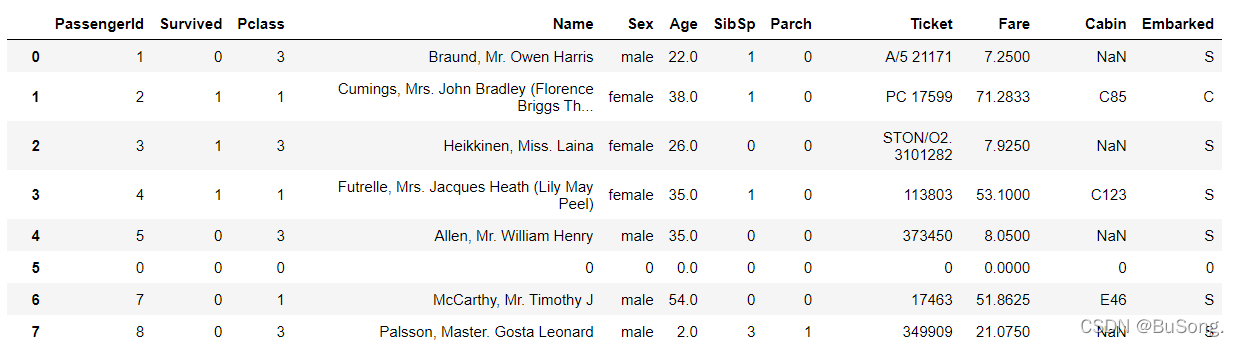
# 缺失值处理(方法二)
df = pd.read_csv('train.csv')
df[df['Age'].isnull()] = 0 # 可行操作 空值部分用“0”来填充
df
效果如下:
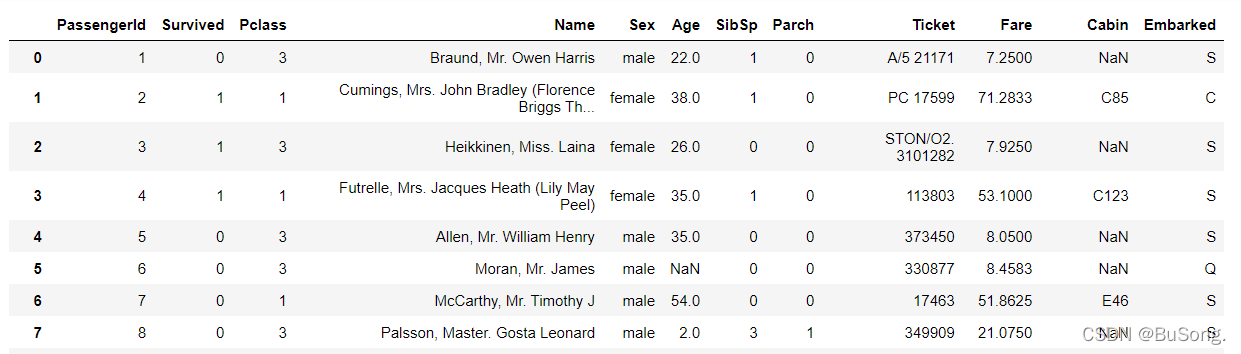
# 缺失值处理(方法三)
df = pd.read_csv('train.csv')
df[df['Age'] == np.nan] = 0 # 空值部分未用“0”填充
df
效果如下:
# 缺失值处理(方法四)
df = pd.read_csv('train.csv')
df[df['Age' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









