







新浪微博可以在发言中嵌入“话题”,即将发言中的话题文字写在一对“#”之间,就可以生成话题链接,点击链接可以看到有多少人在跟自己讨论相同或者相似的话题。新浪微博还会随时更新热门话题列表,并将最热门的话题放在醒目的位置推荐大家关注。
本题目要求实现一个简化的热门话题推荐功能,从大量英文(因为中文分词处理比较麻烦)微博中解析出话题,找出被最多条微博提到的话题。
输入格式:
输入说明:输入首先给出一个正整数N(≤10^5),随后N行,每行给出一条英文微博,其长度不超过140个字符。任何包含在一对最近的#中的内容均被认为是一个话题,输入保证#成对出现。
输出格式:
第一行输出被最多条微博提到的话题,第二行输出其被提到的微博条数。如果这样的话题不唯一,则输出按字母序最小的话题,并在第三行输出And k more ...,其中k是另外几条热门话题的条数。输入保证至少存在一条话题。
注意:两条话题被认为是相同的,如果在去掉所有非英文字母和数字的符号、并忽略大小写区别后,它们是相同的字符串;同时它们有完全相同的分词。输出时除首字母大写外,只保留小写英文字母和数字,并用一个空格分隔原文中的单词。
输入样例:
4
This is a #test of topic#.
Another #Test of topic.#
This is a #Hot# #Hot# topic
Another #hot!# #Hot# topic
输出样例:
Hot
2
And 1 more ...
思路:
是一道典型的哈希表问题,使用C++的话直接调用unordered_map容器即可。
本题的难度并不是在哈希表上,而是字符串的处理上。首先需要将话题内容从字符串中切分出来,同时将非字母及数字(注意,这里的意思是既不是字母也不是数字,题目中的说法是有歧义的)的字符替换成空格再进行单词提取,最后将第一个开头字符改成大写字母即可。
同时不要忘记了,在同一行(也就是同一条微博)里出现的相同话题是不能重复计算的,以及还要记录和最热门话题提及次数相同的话题有多少条。
给大家归纳一下需要解决的问题:
1.将话题内容从微博内容中切割出来(根据#位置来,不难)
2.话题内容中的非字母及非数字字符的处理(全部替换为空格,其余的处理方式都有可能会错)
3.话题内容的单词切割及合并(主要是删除多余的空格以及进行首字母大写)
4.哈希表的实现(调用C++unordered_map即可)
5.考虑如何判断一个话题是否在同一条微博里出现过(之前看到过有其他的朋友选择再开哈希,比如map或者数组,我觉得这种方法太过低效,所以选择使用结构体来存储话题,内置一个变量Last_Appear_Weibo记录该话题最后出现的微博的编号,在处理话题的时候同时维护这个变量即可。如果某个话题当前出现的微博编号与最后出现的微博编号相同那么就证明它在同一条微博中重新出现了,此时不需要再进行计数)
6.如何记录最热门话题以及提及次数相同的话题数(设置两个变量Target_Str,cnt,前者用于存储最热门话题,后者用于存储和最热门话题提及次数相同的其他话题的条数。每次处理一个话题并计入哈希的时候维护这两个变量,如果有话题出现次数更多就存入Target_Str,同时cnt归零,否则如果处理的话题出现次数与最热门话题次数相同,那么判断两者字符串字典序谁更小,将更小的存入Target_Str,同时不要忘记cnt加1)
题干对于话题字符串到底该如何处理说的非常少,初次写可能一直WA或者部分正确,在此附上两个额外的测试样例,如果这两个样例都能过,基本上是可以过的(虽然我当时就算过了这两个样例当时第四个测试点也是一直过不了,修改修改后莫名其妙就过了)
总之这道题的题干给的信息太少,连必要的信息都没有,甚至还有歧义,称不上是一道好题。
下面给出补充样例,样例来源:https://blog.csdn.net/weixin_43581819/article/details/104102928
补充样例1:
输入:
4
This is a #test of 1 topic#.
Another #Test of (1)topic.#
This is a #Hot# topic
This is a test of 1 topic
输出:
Test of 1 topic
2
补充样例2:
输入:
3
Test #for@ diff words#
Test #ford iff words#
#more than# one #topics.#
输出:
For diff words
1
And 3 more…
代码(C++):
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
void StrPreprocess(string& s)//注意这里用的是引用传参,所以可以在函数体内修改s
{
string temp, word;
s += " ";
bool flag = false, is_first_word = true;
for(auto i : s)
{
if(i >= 'A' && i <= 'Z')
{
word.push_back(i + 32);
flag = true;
}
else if((i >= 'a' && i <= 'z') || (i >= '0' && i <= '9'))
{
word.push_back(i);
flag = true;
}
else if(flag)
{
if(word != "")
{
if(is_first_word)is_first_word = false;//用于防止字符串开头为空格
else temp += " ";
temp += word;
word.clear();
}
flag = false;
}
}
if(temp.length() && isalpha(temp[0]))temp[0] -= 32;//开头字母大写
s = temp;
}
struct Data
{
int Appear_Count_of_Weibo, Last_Appear_Weibo;
Data() : Appear_Count_of_Weibo(0), Last_Appear_Weibo(-1) {}
};
int main()
{
string temp;
int N;
scanf("%d", &N);
unordered_map<string, Data> Topic;
int flag = 0, cnt = 0, Max_Count = -1;
string Target_Str;
getchar();
char ch;
while(N--)
{
while((ch = getchar()) != '\n')
{
if(ch == '#')flag++;
else if(flag == 1)
{
if(!isalnum(ch))ch = ' ';
temp.push_back(ch);
}
if(flag == 2)
{
StrPreprocess(temp);
flag = 0;
if(Topic[temp].Last_Appear_Weibo != N)
{
Topic[temp].Last_Appear_Weibo = N;
int Count = ++Topic[temp].Appear_Count_of_Weibo;
if(Max_Count < Count)
{
Max_Count = Count;
Target_Str = temp;
cnt = 0;
}
else if(Max_Count == Count)
{
cnt++;
Target_Str = Target_Str < temp ? Target_Str : temp;
}
}
temp.clear();
}
}
}
cout << Target_Str << endl << Max_Count;
if(cnt)
printf("\nAnd %d more ...", cnt);
return 0;
}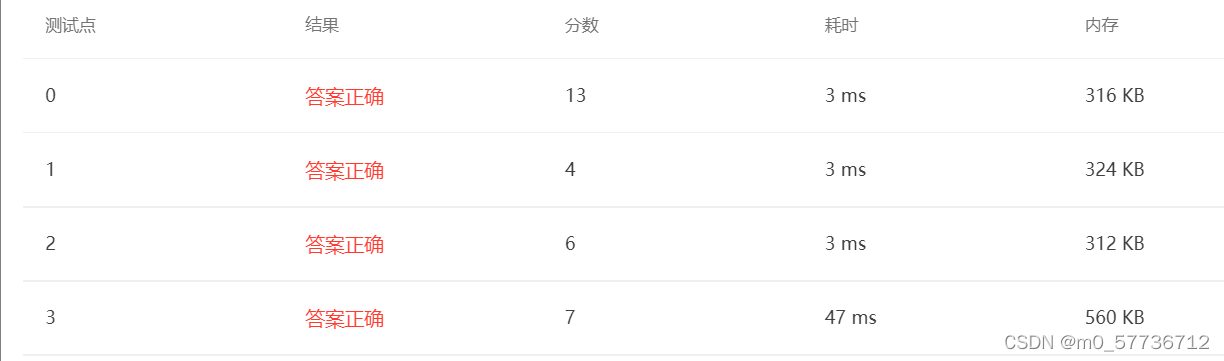
可以看到时空效率都是比较优秀的。
题外话:
其实unordered_map和map基本上是可以通用的,只不过一个底层为哈希结构,一个底层为红黑树结构。
所以从结构上来说unordered_map是正统的哈希表,map只是一个查找效率高效(为logn)的二叉树结构,但是因为map的查找性能相当好,基本上可以认为它查找效率与unordered_map(在n较小时基本上为O(1))
但是在n较大时unordered_map容易产生哈希冲突,此时的查找效率会下降很多,但是map受到的影响却不大。所以综合来说在n小时map与unordered_map查找效率差不多,但是n大时又优于unoredered_map,所以才说map完全可以替代unordered_map(个人理解,还是得看题目具体问题具体讨论)
例如下面是笔者在PTA的另一道题 QQ帐户的申请与登陆 上进行的测试结果:
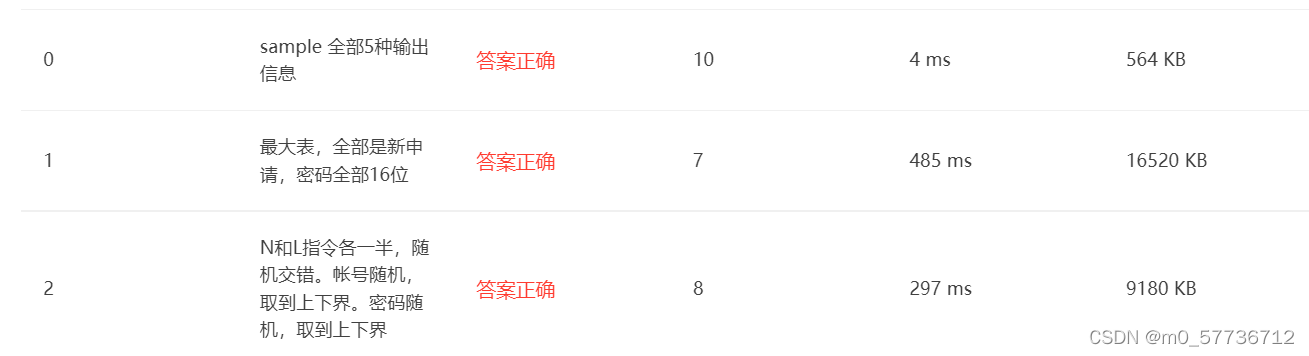
这是unordered_map的结果
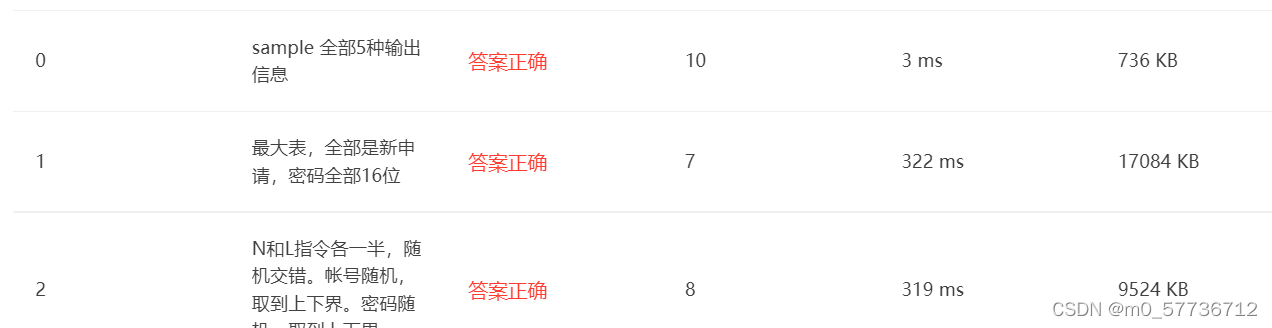
这是map的结果
可以看到二者空间效率相差无几,当n较小时二者时间效率基本上一致;但是当n较大时,时间上map显然优于unordered_map
所以map虽然不是哈希结构,却能够经常优于正统的哈希结构的unordered_map,这也就是为什么很多人偏爱直接使用map来作为哈希表了。
个人建议是,如果有些题使用map(unordered_map)超时了,那么不妨把它换成unordered_map(map),说不定就能过了呢(笑)。毕竟它们如果当做哈希表来使用的话,在函数成员的使用上根本没有区别,只需要把头文件和声明改了就行了。

















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









