






网站:https://sc.chinaz.com/tupian/
我们一开始要查找爬取指定含有图片的网页内容(结合这预览与响应看有可能图片源没有这种情况)

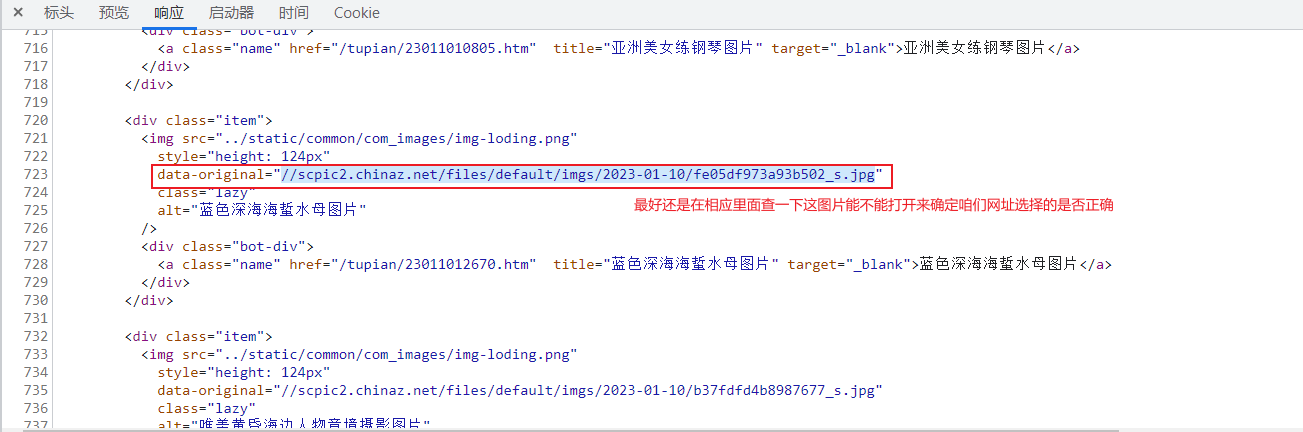

使用链接后显示成功
再然后我们需要定位到源代码,使用xpath定位:

如图示定位到

这里需要注意一个问题:图片网站在初始化页面时,由于图片资源占用太多。所以大多图片网站采用 懒加载。即我们未访问到该图片时,该图片的标签存储是另一个标签存在(省下资源)。例如:在翻到已加载的图片时,该图片在xpath中的路径(下载源)是src,但是当我们刷新重新访问元素栏查看未查看的图片源码的时候, 可以发现路径是src2。这是大多数图片网站会使用的一个方法。爬取类似图片网站时需要注意懒加载的获取, 或许xpath会是//xxxx/@src2的格式。
在python中会获取不到(当然xpath中src可以获取到,毕竟扫描过了)
遇到的错误
然后就算解决了懒加载问题之后还是遇到了错误,在xpath中定位的时候浏览器是解析的到的。但是到了python中使用lxml的时候,列表没有获取到具体信息,是一个空列表。网站升级源码了,现在这个网站不只是懒加载获取不到图片的问题了,html源码响应加载也有问题(真的会谢)

解决方法
排除了半天,我把获取到的content下载成html以后查出了问题:
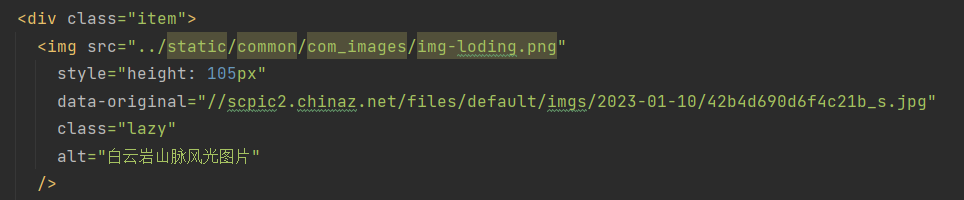
这是content下载成html文件后获取到的部分源码

这是Chrome浏览器元素的部分源码
很明显,两个源码部分不一样,在class部分,Chrome的图片部分class名为item masonry-brick,但是我通过python发送请求获取到的content的class名为item。
这样就会导致xpath上解析没有任何问题(因为依赖的是chrome的源码解析)但是python解析有问题(因为源码被修改了)。 所以最后的解决方法就是当再遇见这种情况下载content为html文件查看源码是否不一致。不一致以content内容为准。
这里查了一下:原因是HTML不是源文件 只是生成的 所以用xpath解析不到 现在很多网页都是这种了 注意下即可
附:还有两种可能1)数据是动态加载,静态网页数据获取这一套用不上。2)例如Firefox,Chrome,Edge浏览器在某些网站上会自动加上tbody标签,删除就好。
附代码
import urllib.request
from lxml import etree
# https://sc.chinaz.com/tupian/
# https://sc.chinaz.com/tupian/index_2.html 变的是页码,但是第一页没有加这个(结构不一样
def get_request(page):
if page == 1:
url = 'https://sc.chinaz.com/tupian/'
else:
url = 'https://sc.chinaz.com/tupian/index_' + str(page) + '.html'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36"
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
return content
def get_download(content):
# 定制tree对象
tree = etree.HTML(content)
# 使用xpath获取图片名字和源码
alt_list = tree.xpath('//div[@class="item"]/img/@alt')
src_list = tree.xpath('//div[@class="item"]/img/@data-original')
for i in range(0, len(alt_list)):
url = 'https:' + src_list[i]
name = alt_list[i]
urllib.request.urlretrieve(url=url, filename='./img/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入要下载的起始网页:'))
end_page = int(input('请输入要下载的结束网页:'))
for i in range(start_page, end_page + 1):
# 定制对象
request = get_request(i)
# 获取content内容
content = get_content(request)
# 下载文件
get_download(content)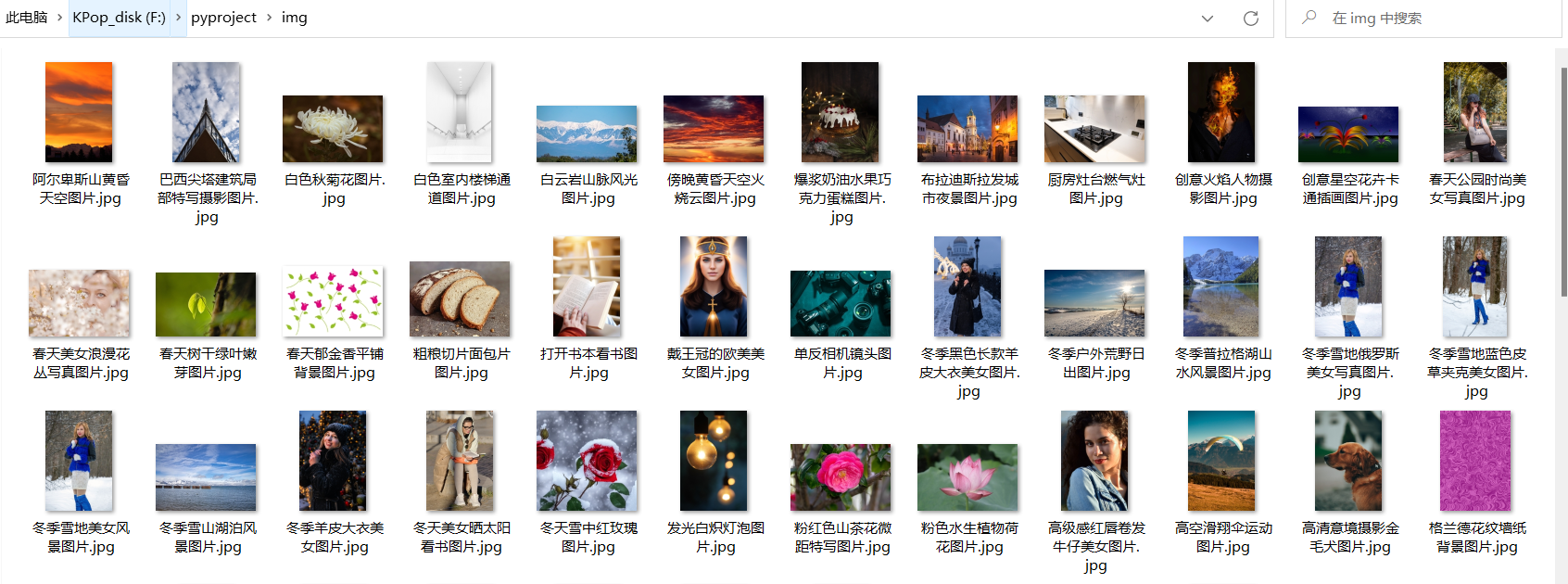
结果图
这里还有一些细节问题:比如获取到的src是:
//scpic2.chinaz.net/files/default/imgs/2023-01-10/20f8879d58d79bd8_s.jpg
这类格式有问题,下载不了,需要加上协议https: 才可以下载

















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









