










目录
二.KafkaUtils.createDirectStream方式


温习
Kafka是由Apache软件基金会开发的一个开源流处理平台,它使用Scala和Java语言编写,是一个基于Zookeeper系统的分布式发布订阅消息系统,该项目的设计初衷是为实时数据提供一个统一、高通量、低等待的消息传递平台。
①、Kafka的众多优点:其优点具体:
(1)解耦。Kafka 具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程。
(2)高吞吐量、低延迟。即使在非常廉价的机器上,Kafka也能做到每秒处理几十万条消息,而它的延迟最低只有几毫秒。
(3)持久性。Kafka 可以将消息直接持久化在普通磁盘上,且磁盘读写性能优异。
(4)扩展性。Kafka 集群支持热扩展,Kafka集群启动运行后,用户可以直接向集群添加新的Kafka服务。
(5)容错性。Kafka 会将数据备份到多台服务器节点中,即使Kafka集群中的某台节点宕机,也不会影响整个系统的功能。
(6)支持多种客户端语言。Kafka 支持Java.. NET .PHP、Python等多种语言。
Kafka使用消费组(Consumer Group)的概念统了点对点消息传递模式和发布订阅消息传递模式,当Kafka使用点对点模式时,它可以将待处理的工作任务平均分配给消费组。
一.KafkaUtils.createDstream方式
1.编写SparkStreaming_Kafka_createDstream.scala
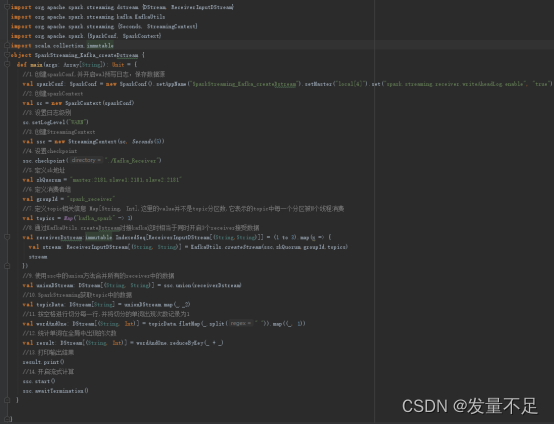
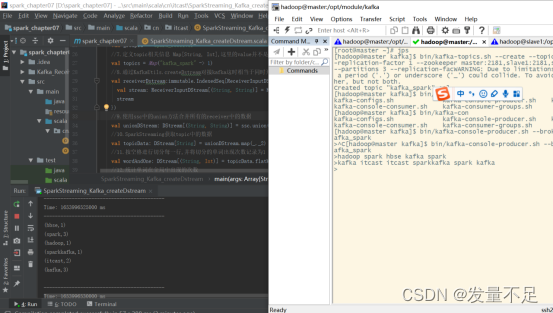
2.切到master节点上创建topic,指定消息的类别
Cd /opt/module/kafkabin/kafka-topics.sh --create --topic kafka_spark --partitions 3 --replication-factor 1 --zookeeper master:2181,slave1:2181,slave2:2181
3.先运行程序,启动kafka的消息生产者
[hadoop@master kafka]$ bin/kafka-console-producer.sh --broker-list master:9092 --topic kafka_spark![]()
4.在master节点发送消息,可以看到控制台输出内容
kafka itcast itcast spark_kafka spark_kafka
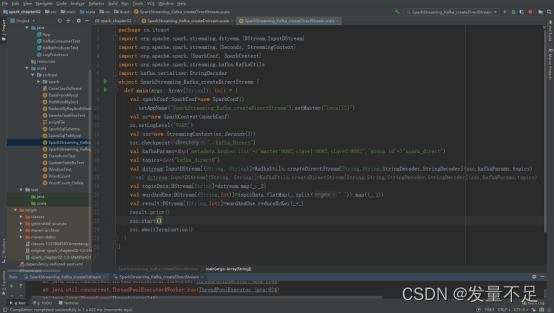
二.KafkaUtils.createDirectStream方式
1.编写SparkStreaming_Kafka_createDirectStream.scala并运行程序
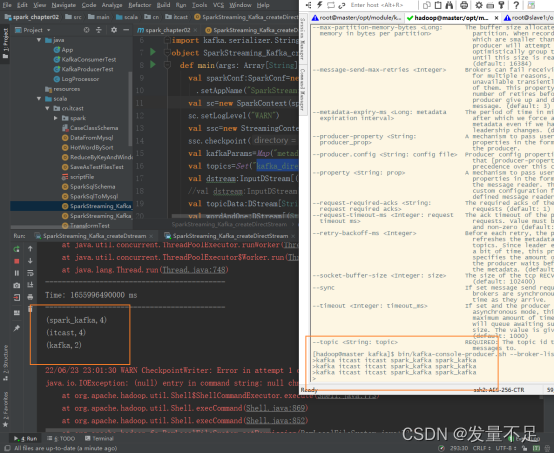
2.创建topic,发送消息
[hadoop@master kafka]$ bin/kafka-topics.sh --create --topic kafka_direct0 --partitions 3 --replication-factor 1 --zookeeper master:2181,slave1:2181,slave2:2181
3.启动kafka的消费生产者
[hadoop@master kafka]$ bin/kafka-console-producer.sh --broker-list master:9092 --topic kafka_direct0![]()
4.在master节点发送消息,可以看到控制台输出内容

















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











