






摘要
本周跟着吴恩达老师的机器学习系列课程学习了机器学习基础,包括机器学习的意义,定义与分类等。同时根据pytorch深度学习快速入门教程比较并选择了相应编辑器,配置了环境。
Abstract
This week, I studied the fundamentals of machine learning following Professor Andrew Ng's machine learning series course, including the significance, definition, and classification of machine learning. Additionally, I compared and selected a suitable editor based on the PyTorch deep learning quick start guide, and configured the environment accordingly.
1 机器学习基础
1.1 机器学习的意义
最开始的计算机编程只能完成比较基础简单的事情,比如找到从A到B的最短路径,但不能完成更复杂的事情(如网页搜索,垃圾邮件过滤)。因此让机器自己进行学习,即机器学习作为人工智能中的一个领域逐渐发展,这赋予了计算机新的能力。
1.2 机器学习的定义
总的来说,机器学习有两种定义。
一种由开发了跳棋程序的Arthur Samuel于1959年提出,他认为机器学习是在没有显式编程的情况下,能使计算机具有学习能力的研究领域。
另一种则更为现代,由Tom Mitchell于1998年提出,他认为机器学习主要指计算机程序从经验E中学习解决某一任务T进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
1.3 机器学习的分类
机器学习主要可分为监督学习与无监督学习两大类,其中监督学习是指人教会计算机做某件事情,无监督学习则是让计算机自己学会做某件事情,具体在下文会详细介绍。除此之外,机器学习还包括强化学习、推荐算法等小类。
1.3.1 监督学习
监督学习的特点是输入数据具有确定的标签,类似于给出带答案的题目,要求可以得到新题目的答案。它主要包括两个任务。
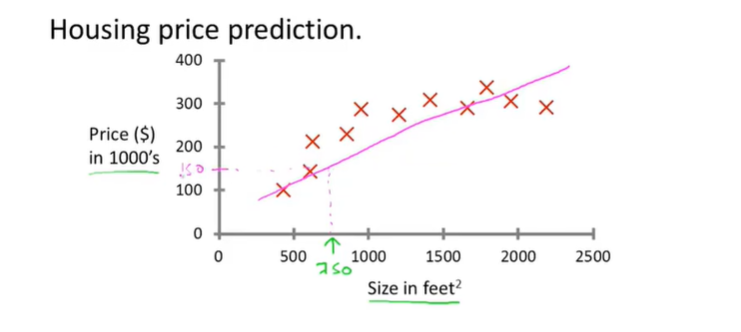
一是回归,输出为连续值,如房价预测。下图中横坐标代表房屋面积,纵坐标代表房价,图中每一个红叉所对应的房屋面积都具有明确的标签(房价),而对于这些红叉,可以使用不同的函数进行拟合,从而得到给定值的预测输出,即给定房屋面积的预测房价。
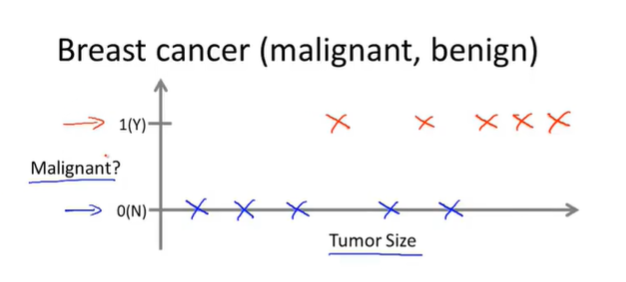
二是分类,输出为离散值,如肿瘤预测。下图中横坐标表示肿瘤大小,纵坐标表示是否为恶性肿瘤,同样图中的每个叉所对应的肿瘤大小都具有明确的标签(即是否为恶性肿瘤)。
1.3.2 无监督学习
无监督学习的输入数据则没有确定的标签,需要从数据中发现结构或模式。
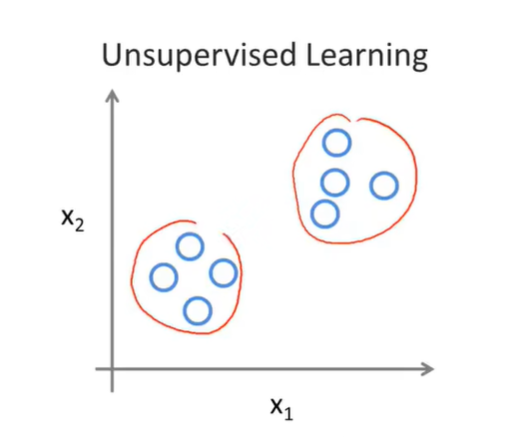
无监督学习的一个常用算法为聚类,如下图。其应用包括组织大型计算机集群,社交网络分析,市场细分与天文数据分析等。
2 环境配置
由于之前的相关学习,已经配置了anaconda环境,并安装了pycharm,所以本节主要对pycharm与jupyter两大编辑器进行对比。
总的来说,pycharm更加全面传统,jupter更加注重交互。
在使用场景上,pycharm更加适合大型项目开发、软件工程任务以及需要复杂调试的应用程序,jupyter则主要用于数据科学、机器学习实验、教学和快速原型开发,能立即看到结果;在用户体验上,pycharm强调项目的组织结构,适合长时间的编码工作,jupyter更便于分享和展示分析过程;在编程环境上,pycharm提供了一个完整的开发环境,支持多种语言,而jupter则专注于python。
为了方便日后的学习,决定将两者结合起来使用,于是在已经配好的环境里安装了jupyter编辑器,具体步骤如下:
1.在anaconda命令行中输入代码激活环境:conda activate chen(chen为之前配置好的环境名称)
2.在激活的环境中下载jupyter:conda install nb_conda
3.打开jupyter:jupyter notebook(下载成功后直接输入)
3 总结
本周跟着吴恩达老师的机器学习系列课程学习了机器学习的基础部分,虽然以前有过相关的学习,但对机器学习的分类与应用等有了更加清晰和明确的了解。同时根据pytorch深度学习快速入门教程了解了新的编辑器,拓宽了该方面的认识。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









