







梯度下降算法
梯度下降是深度学习中常见的算法,其实梯度下降算法就是一种求解最值的算法,函数
f
(
x
)
f(x)
f(x)的值受
x
x
x影响。
目标:找到合适的
x
x
x值,使得
f
(
x
)
f(x)
f(x)最小
先总结方法:
1.任取一点
x
0
x_0
x0,计算在这一点的导数值
f
(
x
0
)
f(x_0)
f(x0)
2.根据导数的正负,决定
x
0
x_0
x0应当调大还是调小
3.迭代进行多次直到x不在变化(或变化极小)
理解梯度下降
假如我们要求解的目标函数的最值是一个二次函数原函数为
y
=
x
2
y = x^2
y=x2
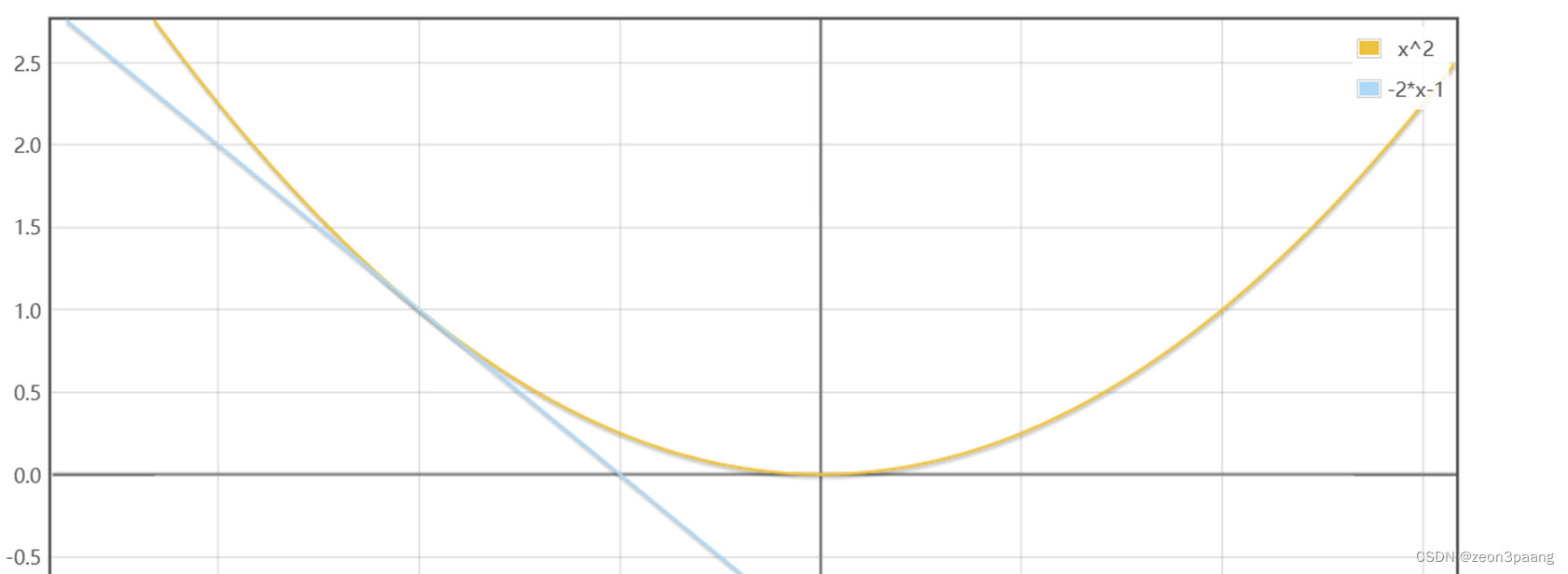
假设x<0,比如说x = -1这个点,导数值为 -2,该点导数为负数,说明在这一点,如果x增大,y会减小
所以f(x)最小值的点应当在-1的右侧(大于-1)
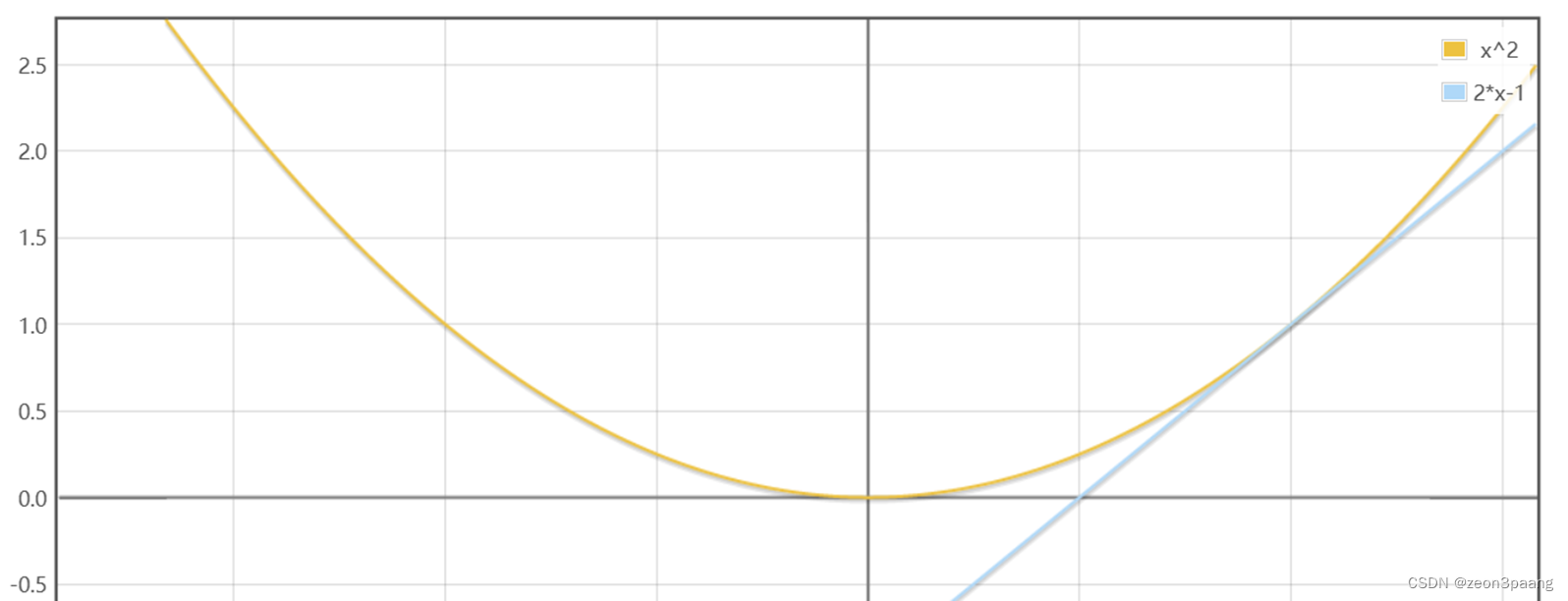
假设x>0,比如说x = 1这个点,导数值为 2,该点导数为正数,说明在这一点,如果x增大,y会增大
所以f(x)最小值的点应当在-1的左侧(小于1)
根据以上示例,想必聪明的你们可以看出,靠近最值的下一个x值有如下表达:
x
t
+
1
=
x
t
−
a
∇
L
(
x
t
)
x_{t+1}=x_t-a{\nabla}L(x_t)
xt+1=xt−a∇L(xt)
其中
a
a
a是学习率,可以用来调整每次x变动的幅度,
∇
L
(
x
t
)
{\nabla}L(x_t)
∇L(xt)是梯度,在一元函数中导数和梯度是相同的,在多元函数中是方向变化最快的导数。
深度学习
深度学习学习的目标就是找到损失函数中的参数使损失函数最小化,损失函数越小,模型越好。(千万不要搞混参数和样本)。
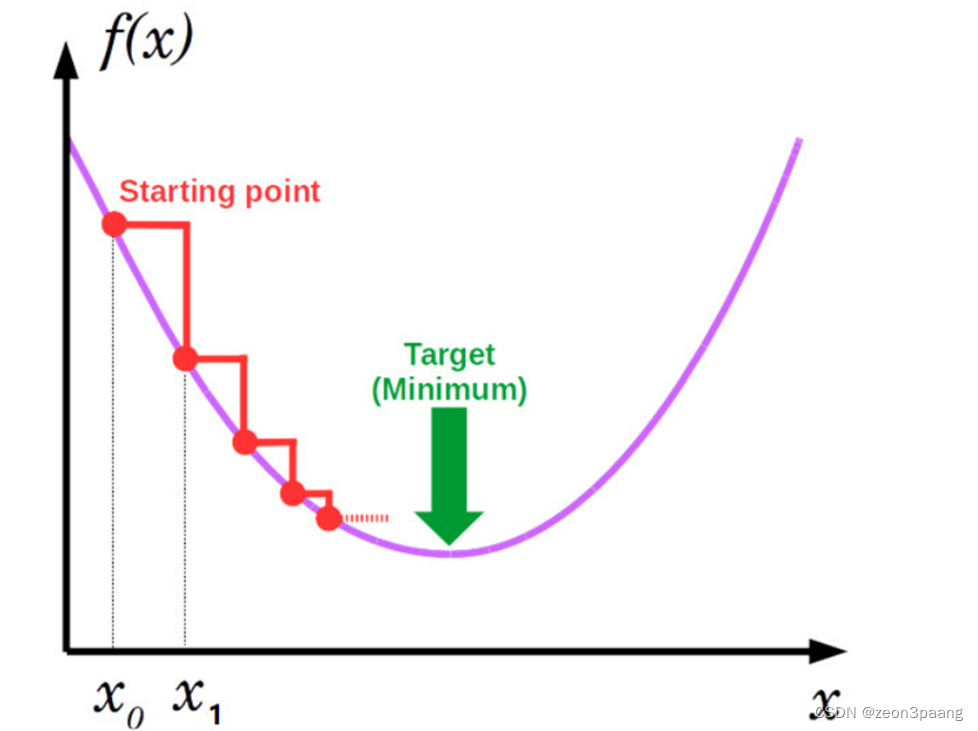
完整的反向传播过程
1.根据输入样本
x
x
x和模型当前权重,计算预测值
y
1
y^{1}
y1
2.根据
y
1
y^{1}
y1和
y
y
y使用loss函数计算loss
3.根据loss计算模型权重的梯度
4.使用梯度和学习率,根据优化器调整模型权重
参数的更新方式
Gradient descent
所有样本一起计算梯度(累加)
Stochastic gradient descent
每次使用一个样本计算梯度
Mini-batch gradient descent
每次使用n个样本计算梯度(累加)
每种参数的计算速度不同
代码实现(SGD)
import matplotlib.pyplot as pyplot
import math
import sys
X = [0.01 * x for x in range(100)]
Y = [2*x**2 + 3*x + 4 for x in X]#生成样本
def func(x):
y = w1 * x**2 + w2 * x + w3#这里换成其他函数也可以拟合
return y
def loss(y_pred, y_true):
return (y_pred - y_true) ** 2
# 权重随机初始化
w1, w2, w3 = 1, 0, -1
# 学习率设置
lr = 0.1
# 训练过程
for epoch in range(1000):
epoch_loss = 0
for x, y_true in zip(X, Y):
y_pred = func(x)
epoch_loss += loss(y_pred, y_true)
#梯度计算
grad_w1 = 2 * (y_pred - y_true) * x ** 2
grad_w2 = 2 * (y_pred - y_true) * x
grad_w3 = 2 * (y_pred - y_true)
#权重更新
w1 = w1 - lr * grad_w1 #sgd
w2 = w2 - lr * grad_w2
w3 = w3 - lr * grad_w3
epoch_loss /= len(X)
print("第%d轮, loss %f" %(epoch, epoch_loss))
if epoch_loss < 0.0001:
break
print(f"训练后权重:w1:{w1} w2:{w2} w3:{w3}")
#使用训练后模型输出预测值
Yp = [func(i) for i in X]
#预测值与真实值比对数据分布
pyplot.scatter(X, Y, color="red")
pyplot.scatter(X, Yp)
pyplot.show()
思考
1、深度学习为什么不直接让损失函数导数等于0直接求最值?
深度学习中样本数据量很大,直接计算导数等于0的点,内存和算力不够。
2、学习率的大小有什么优缺点?
学习大可以减少迭代轮数,但是过大有可能会梯度爆炸,找不到最值。
学习率过小会迭代速度慢,可能陷入局部最小值,梯度消失。
















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











