







文章目录
Redis
Redisd的简介
Redis(Remote Dictionary Server 远程字段服务) 是一个开源的,支持键值对(Key-Value)、列表(List)、哈希表(Hash)、集合(Set)和有序集合(Sorted Set)等数据结构的内存数据库。它可以将数据存储在内存中,从而提供极高的读写性能和数据处理速度。 Redis 还支持事务、持久化、复制和 Lua 脚本等功能。它可以用作缓存、消息队列、数据库和批量数据处理等用途。
Redisd的特点
- 开源和高性能:Redis 是一个开源的内存数据库,可以在 Linux、macOS 和 Windows 等操作系统上运行。它在内存中存储数据,因此具有极高的读写性能和数据处理速度。
- 多种数据结构:Redis 支持多种数据结构,包括键值对(Key-Value)、列表(List)、哈希表(Hash)、集合(Set)和有序集合(Sorted Set)。这些数据结构可以用于存储和处理不同类型的数据。
- 原子性:Redis 中的操作具有原子性,即要么成功执行,要么完全失败。这可以确保数据的一致性和完整性。
- 持久化:Redis 支持将数据持久化到磁盘,以便在重启或出现故障时可以恢复数据。可以使用 RDB(Redis Database)或 AOF(Append-Only File)等持久化机制来实现数据持久化。
- 复制:Redis 支持复制功能,可以将一个 Redis 实例的数据复制到另一个 Redis 实例中。这可以用于实现故障转移、读写分离和数据备份等用途。
- 事务:Redis 支持事务,可以确保一组操作的原子性、一致性、隔离性和持久性。事务可以确保多个操作按照预定的顺序执行,并在发生错误时回滚。
- Lua 脚本:Redis 支持 Lua 脚本,可以在 Redis 中运行简单的、高效的 Lua 代码。Lua 脚本可以用于执行批量操作,减少网络传输和 CPU 开销。
- 分布式:Redis 支持分布式部署,可以在多个 Redis 实例之间进行数据共享和通信。可以使用 Redis 集群、Redis Sentinel 或 Redis Cluster 等分布式方案来实现 Redis 的分布式部署。
- 高可用:Redis 支持高可用性,可以在多个节点之间进行故障转移和数据同步。可以使用 Redis Sentinel 或 Redis Cluster 等方案来实现 Redis 的高可用性。
- 插件支持:Redis 支持插件,可以通过加载额外的模块来扩展 Redis 的功能。Redis 的插件生态系统丰富,可以实现各种高级功能,如实时统计、日志记录和图形化界面等。
NoSQL技术
在我们日常的Java Web开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
为了克服上述问题,java web项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
Redis和MongoDB是当前使用最广泛的NoSQL, 而就Redis技术而言,它的性能十分优越,可以支持每秒十几万的读写操作,其性能远超数据库,并且还支持集群、分布式、主从同步等配置,原则上可以无限扩展,让更多的数据存储在内存中,更让人欣慰的是它还支持一定的事务能力,这保证了高并发的场景下数据的安全和一致性。
Redis 的安装
下载
不同版本的 Redis 分别从不同地⽅进⾏下载
Linux:https://redis.io/download/
Windows:https://github.com/MSOpenTech/redis/releases
注意:windows 版本的 Redis 更新⽐较慢。
解压
这个没什么好说,不管哪个版本的都需要解压。
启动
进⼊命令提示符,切换到 Redis ⽬录
windows 执⾏:
redis-server.exe redis.windows.conf
Linux 执⾏:
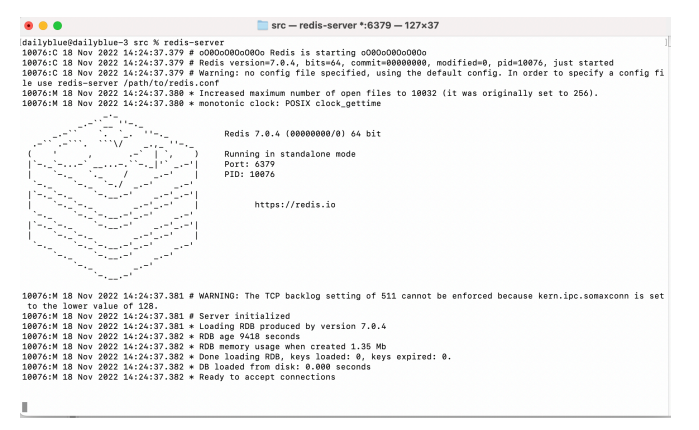
redis-server
看到这个界⾯就是成功了!

用完 ——flushall
Redis 的分类
redis ⾃身是⼀个 Map ,其中所有的数据都是采⽤ key : value 的形式存储 key 是⼀个字符串;
value 是具有具体类型的数据。 Redis 中包含5种基本数据类型和3种特殊类型。
redis的五种数据类型是:
1、string(字符串):
字符串类型是Redis中最基本的数据存储类型,它是一个由字节组成的序列,在Rediss中是二进制安全的。这意味着该类型可以接受任何格式数据,如JPEG图像数据和Json对象说明信息。它是标准的key-value,通常用于存储字符串、整数和浮点。Value可容纳高达512MB的数据。
由于所有数据都在单个对象中,Redis 中的字符串操作速度非常快。**基本的 Redis 命令(如 SET、GET 和 DEL**)允许您对字符串值执行基本操作。
SET 键值 – 设置指定键的值。GET 键 – 检索指定键的值。DEL 键 – 删除给定键的值。
应用程序场景:非常常见的场景用于计算站点访问量、当前在线人数等。
其中,string(字符串)是redis中最基本的数据类型,一个key对应一个value,string 可以包含任何数据。
2、hash(哈希):
Redis hash 是一个键值(key=>value)对集合。Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。和String略像,但value中存放的是一张表,一般用于多个个体的详细事项排列,String也可以做到,但要比hash麻烦许多。
哈希命令允许您独立访问和更改单个或多个字段。
- **
HSET** – 将值映射到哈希中的键。 - **
HGET** – 检索与哈希中的键关联的各个值。 HGETALL – 显示整个哈希内容。- **
HDEL** – 从哈希中删除现有的键值对。
应用程序方案:存储部分更改数据,如用户信息、会话共享。
3、list(列表):
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。Redis的列表允许用户从序列的两端推入或者弹出元素,列表由多个字符串值组成的有序可重复的序列,是链表结构,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着,即使有数以千万计的元素列表,也可以极快地获得10条记录在头部或尾部。可列入名单的要素最多只有4294967295个。
此字符串链表允许您执行一组操作,例如:
- **
LPUSH** – 将值推送到列表的左端。 - **
RPUSH** – 将值推送到列表的尾端。 - **
LRANGE** – 检索一系列项目。 LPOP/RPOP – 用于显示和删除两端的项目。LINDEX – 从列表中的特定位置获取值。
应用场景:最新消息排行榜;消息队列,以完成多程序之间的消息交换。
4、set(集合):
Redis 的 Set 是 string 类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。所谓集合就是一堆不重复值的组合,并且是没有顺序的。在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还提供了诸如collection、union和differences等操作,使得实现诸如commandism、poperhike、secondfriends这样的功能变得很容易,或者选择是将结果返回给客户机,还是将它们保存到使用不同命令的新的集合中。
使用以下命令添加、删除、检索和检查集合中的各个项目:
- **
SADD** – 向集合中添加一个或多个项目。 - **
\**SISMEMBER\**** – 找出一个项目是否是集合的一部分。 - **
SMEMBERS** – 从集合中检索所有项目。 - **
SREM** – 从集合中删除现有项。
5、sort set (有序集合):
sorted set也叫Redis zset ,和set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
您可以按成员、排序顺序和分数值访问排序集中的项目。基本命令允许您根据成员值和分数范围提取、添加、删除单个值或检索项目。
ZADD – 将具有分数的成员添加到排序集。ZRANGE – 根据项目在排序顺序中的位置检索项目。**withscores **选项生成实际分数值。ZRANGEBYSCORE – 根据定义的分数范围从排序集中提取项目。withscores 选项生成实际分数值。ZREM –从已排序的集中删除项目。
使用场景:带有权重的元素,比如一个游戏的用户得分排行榜;比较复杂的数据结构,一般用到的场景不算太多。
Redis 的常⽤命令
传统的关系型数据库是使⽤表来存储数据,在 Redis 中存储数据使⽤类似于 JavaMap 集合的⽅式存储,使⽤ key-value 存储, key 不允许重复,值可以重复。 在 Redis 中存储的数据都有别于传统数据库(如 MySQL/Oracle 等),对 Redis 内存数据库的操作也不在使⽤ SQL 语句,⽽是使⽤各种命令来完成。
要使⽤命令必须通过客户端访问,客户端访问⽅式:

基本命令
# 1.切换数据库
select index
# 2.清屏命令
clear
# 3.获得当前库中的key
# "*"匹配任意数量的任意字符 "?"匹配任意⼀个字符 "[]"匹配其中的任意⼀个字符
keys pattern
keys * (获得所有的key)
keys d* (获得所有以d开头的key)
keys *blue (获得所有以blue结尾的key)
keys ?ava (获得前⾯有⼀个任意字符,并且以ava结尾的key)
keys u[se]r (获得前⾯第⼀个字符是u,第⼆个字符是s或e,结尾为r的key)
# 4.判断key是否存在
exists key
# 5.判断key是什么类型
type key
# 6.删除指定的key
del key
# 7.设置key的过期时间
expire key 1 (秒为单位)
pexpire key 1 (毫秒为单位)
# 8.查看过期剩余时间(-1表示永不过期,-2表示已过期)
ttl key
# 9.将key的有效期设置为永不过期
persist key
# 10.修改key的名字
rename key newkey #如果newkey存在则会替换原来的value
rename str str1 #将str的key改名为str1
renamenx str str1 #将str的key改名为str1,如果str1不存在才修改,如果存在则修改失败
# 11.对key中的数据进⾏排序,只针对集合类型(list,set)
sort key
sort list [asc|desc] #对key为list的集合进⾏排序(注意不改变原始数据)
# 12.查看库中key的数量
dbsize
# 13.清楚当前库的所有key
flushdb
# 14.清楚所有库的所有数据命令
flushall
# 15.退出命令
quit exit ESC键
# 16.检测客户端与服务器连通命令
ping
# 17.控制台打印命令
echo message
# 18.数据在不同的库中移动 move key db
move name 1 #将当前库中的name数据移动到1号库中(注意:当前库中存在name数据,1号库中不存在同名的数据)
# 19.获得当前Redis的运⾏属性值
info
字符串相关命令
String 是 Redis 中最基本的类型, String 类型是⼆进制安全的, redis 的 string 可以存储任何数据,如 图⽚、对象等。
# 存值命令
set key value # 存放单个元素
mset key1 value1 key2 value2 key3 value3 ... # 批量存放
# 取值命令 获取数据时返回值为nil表示空,没有获取数据
get key # 获取单个元素
mget key1 key2 key3 ... # 批量获取多个元素
# 获得字符串的⻓度
strlen key
# 向value中追加数据(如果原始数据存在就追加,否则新建)
append key value
# 截取字符串 endIndex:-1代表⾃然结束
getrange key startIndex endIndex
# 替换内容
setrange key startIndex 替换内容
# 如果存在就不设置,不存在就新建
setnx key value #如果存在什么都不做,如果不存在就新建⼀个数据
# 数值运算指令
# 加法操作
incr key #对key的值⾃加1,等同于i++
incrby key number #对key的值加上指定的数值(负值进⾏减法运算),等同于i=i+n
# 减法运算
decr key #对key的值⾃减1,等同于i--
decr by key number #对可以的值减去指定的数值
# 设置带有时效的数据
# 以秒为单位设置存活时间
setex key seconds value
# 以毫秒为单位设置存活时间
psetex key milliseconds value
# 使⽤set⽅式设置key的存活期
set key value [ex seconds][px milliseconds]
Hash 相关命令
# 添加/修改数据
hset key field value
# 获取数据
hget key field
# 删除数据
hdel key field
# 添加/修改多个数据
hmset key field1 value1 field2 value2 ...
# 获取多个数据
hmget key field1 field2 ...
# 获取hash中的字段数量
hlen key
# 获取hash中是否包含指定字段
hexists key field
# 获取hash中的所有字段名和字段值
hkeys key #获得所有的字段名
hvals key #获得所有字段值
# 设置指定字段的数值增加或减少
hincrby key field number #增加或减少整数(负数为减少)
hincrbyfloat key field number #增加或减少⼩数(负数为减少)
List 相关命令
在Redis中可以把list⽤作栈、队列、阻塞队列
list中允许存放重复数据 list中存储的数据有序(指进⼊顺序<分左右 >)。
# 向列表中添加数据(左部添加/右部添加)
lpush key value #向队列的头部插⼊元素(左)
lpush list aaa #向队列的头部插⼊⼀个元素
lpush list aaa bbb ccc #向队列中插⼊多个元素
rpush key value #向队列的尾部插⼊元素(右)
rpush list aaa #向队列的尾部插⼊⼀个元素
rpush list aaa bbb ccc #向队列中插⼊多个元素
# 从list中获取元素
lrange key startIndex endIndex #根据起始和结束下标获取此范围内的列表元素
lrange list 0 1 #结果 aaa,bbb
lrange list 0 -1 #将list中的所有元素取出
# 从list中弹出元素
lpop key #获得列表头部的第⼀个元素并从列表中移除
lpush list aaa bbb ccc ddd
lpop key #获取并移除元素"ddd"
rpop key #获得列表尾部的第⼀个元素并从列表中移除
rpop key #获取并移除元素aaa
# 通过下标获取list中的某个元素
lindex key index
# 获得列表中元素的数量(⻓度)
llen key
# 根据元素值从列表中移除指定数量的元素
lrem key count value
lrem list 2 aaa #将list中的aaa元素移除,存在两个移除两个(最多移除两个)
# 截取⼦list(截断⼦元素)
ltrim key start end
lpush list aaa bbb ccc ddd eee
ltrim list 0 3 结果:eee ddd ccc bbb
# 将原列表中最后⼀个元素移到新列表中
rpoplpush oldkey newkey
lpush list aaa bbb ccc ddd eee
rpoplpush list newlist #将list中的最后⼀个元素移动到newlist中
lrange list #结果 bbb ccc ddd eee
lrange newlist #结果 aaa
# 根据下标重置list中的⼀个元素(根据下标修改list中的⼀个元素)
lset key index value
# 向某个元素前或后插⼊⼀个元素
linsert list before|after oldvalue insertvalue
Set 相关命令
不保证顺序,集合不能存放重复数据
# 向set集合添加⼀个元素
sadd key value1 value2 ....
# 查看set集合中的所有元素
smembers key
# 判断⼀个元素是否存在于set集合中(0表示不存在 1表示存在)
sismember key value
# 获取set中元素的个数
scard key
# 移除⼀个元素
srem key value
# 随机抽取⼀个元素
srandmember key [count] #随机抽取⼀个或多个元素
# 随机删除元素
spop key [count] #随机删除⼀个或多个元素
# 将⼀个特定的值,移动到另⼀个set集合中
smove oldkey newkey value
# 集合操作
# 1. 差集
sdiff key1 key2
# 2. 交集
sinter key1 key2
# 3. 并集
sunion key1 key2
ZSet 相关命令
该集合是对 set 集合的改造,在 set 集合中加⼊了⼀个字段值,⽤于存储排序规则数据,该数据只负责排序不起 其他作⽤。
# 向zset集合添加元素
zadd key score1 value1 score2 value2 #向zset集合添加⼀个或多个成员
# 获取zset中的元素
# 1.zrange key start end [withscores] #从⼩到⼤的顺序显示元素信息,withscores显示排序规则字段
# 2.zrevrange key start end [withscores] #从⼤到⼩的顺序显示元素信息,withscores显示排序规则字段
# 按条件获取zset中的元素
# 1.zrangebyscore key min max [limit] [withscores]
zrangebyscore salary 9000 12000 limit 0 2 withscores #查询⼯资在9000到12000之间的员⼯名并显示前两个
# 2.zrevrangebyscore key max min [limit] [withscores] #降序
zrevrangebyscore salary 13000 10000 limit 0 2 withscores #查询⼯资在12000到90000之间的员⼯名并显示前两个
# 增加或减少zset中元素的score值
zincrby key increment value
zincrby topn 200 java #把key为topn的的java属性的score添加200
# 删除zset中的元素
zrem key member1 member2 ... #根据元素名删除⼀个或多个元素
zrem salary xiaoming xiaoqiang
zremrangebyrank key start stop #删除下标指定范围的元素
zremrangebyrank salary 0 2
zremrangebyscore salary min max #根据socres指定范围删除元素
zremrangebyscore salary 9000 12000
# 获取指定值的分数
zscore key value
# 获得元素在集合中的排名
zrank key member # 升序排名
zrank topn java #排名从0开始,根据score升序排序
zrevrank key member # 降序排名
zrevrank topn java #排名从0开始,根据score降序排序
# 获得集合中元素数量
# 1.zcard key #获得集合中元素数量
zcard salary
# 2.zcount key min max #获得指定范围的元素数量
zcount salary 9000 12000
# 集合交集和并集
#1.zinterstore newset setcount set1 set2 ...#集合交集操作,将多个集合的交集存⼊到newset集合中,
相交集合的数量个setcount指定的数量要⼀致,默认对交集数据进⾏求和运算,也可以获得最⼤值或最⼩值等运算
zinterstore ss 2 s1 s2 [aggregate max|min]
#2.zunionstore newset setcount set1 set2 ...#集合并集操作
zunionstore ss 2 s1 s2 [aggregate max|min]
雪崩、击穿、穿透
随着移动互联⽹的快速发展,互联⽹的⽤户数量越来越多,产⽣的数据规模也越来越⼤,对数据库也提出了更⾼的 要求,为了减少直接访问数据库,我们会⽤ Redis 作为缓存层。
因为 Redis 是内存数据库,我们可以将数据库的数据缓存在 Redis ⾥,相当于数据缓存在内存,内存的读写速度⽐硬盘快好⼏个数量级,这样⼤⼤提⾼了系统性能。
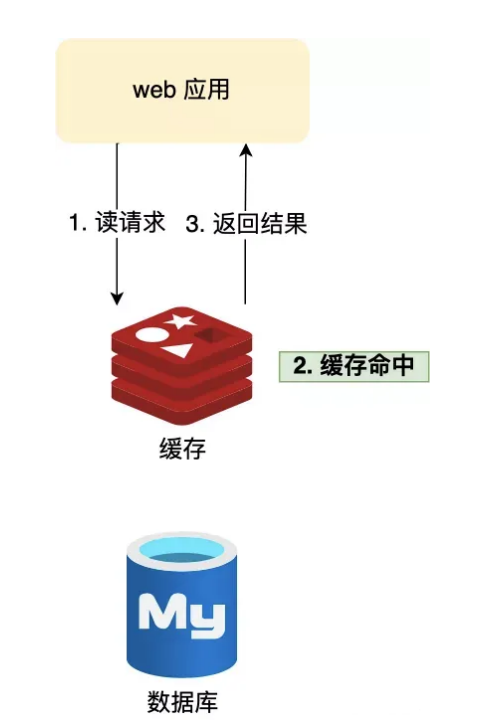
在今天的互联⽹⾥,⾼并发、⼤数据量、⼤流量已经成为了代⾔词,那么我们的系统也承受着巨⼤的压⼒,⾸当其 冲的解决⽅案就是 redis 。
那么 redis 使⽤不当就会产⽣雪崩、穿透、击穿等问题,这也是考验⼀个程序员技术能⼒的时刻。
缓存雪崩
通常我们为了保证缓存中的数据与数据库中的数据⼀致性,会给 Redis ⾥的数据设置过期时间,当缓存数据过期 后,⽤户访问的数据如果不在缓存⾥,业务系统需要重新⽣成缓存,因此就会访问数据库,并将数据更新到 Redis ⾥,这样后续请求都可以直接命中缓存。
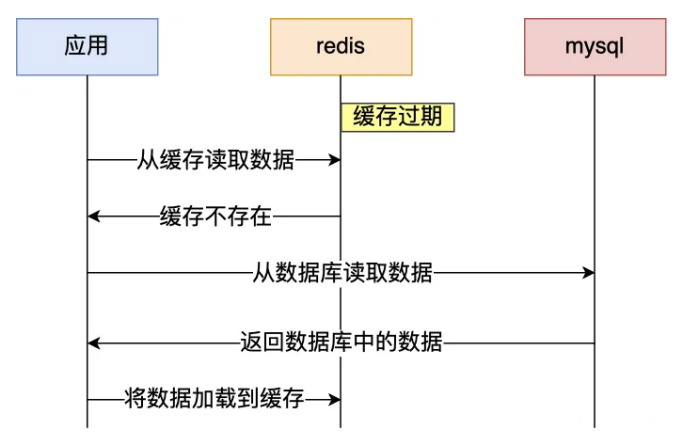
可是,当⼤量缓存数据在同⼀时间过期(失效)或者 Redis 故障宕机时,这时⼤量的⽤户请求,就直接访问到数 据库了,从⽽导致数据库的压⼒骤增,严重的会造成数据库宕机,从⽽造成整个系统崩溃,这就是造成缓存雪崩的 原因。
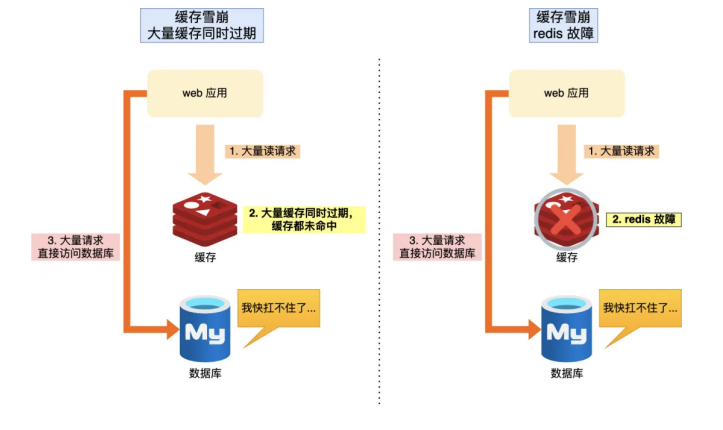
双⼗⼀期间,所有⽤户⼀打开淘宝就是进⼊⾸⻚,⾸⻚的压⼒⾮常⼤,为了提⾼并发,将⽹站⾸⻚数据都缓 存到 Redis ⾥,所有的 Redis key 失效时间都是3⼩时。 双⼗⼀当天⼤量⽤户剁⼿狂欢,这时候3个⼩时过去了, Redis ⾥⾸⻚的 key 缓存全部失效,这时候 Redis ⾥查询不到数据了,只能去数据库中查询,造成数据库⽆法响应挂掉。 ⽤户进不去⾸⻚没法剁⼿了,⻢爸爸就不开⼼了,这个程序员就外派到⾮洲了。
⼀句话总结 :在⾼并发下,⼤量缓存 key 在同⼀时间失效,⼤量请求直接落在数据库上,导致数据库宕机。
原因
可以看到,发⽣缓存雪崩有两个原因:
1.⼤量数据同时过期。
2.Redis 故障宕机。
不同的原因,应对的策略也不同。
1.⼤量数据同时过期
应对策略:
针对⼤量数据同时过期⽽引发的缓存雪崩问题,常⻅的应对⽅法有下⾯⼏种:
1.均匀设置过期时间
2.互斥锁
3.双 key 策略
4.后台更新缓存
a.均匀更新过期时间
如果要给缓存数据设置过期时间,应该避免将⼤量的数据设置成同⼀个过期时间。我们可以在对缓存数据设置过期 时间时,给这些数据的过期时间加上⼀个随机数,这样就保证数据不会在同⼀时间过期。
b.互斥锁
当业务线程在处理⽤户请求时,如果发现访问的数据不在 Redis ⾥,就加个互斥锁,保证同⼀时间内只有⼀个请 求来构建缓存,当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就 返回空值或者默认值。
实现互斥锁的时候,最好设置超时时间,不然第⼀个请求拿到了锁后,发⽣了某种意外⼀直阻塞,这时其他请求也 ⼀直拿不到锁,整个系统就会出现⽆响应现象。
c.双 key 策略
我们对缓存数据可以使⽤两个 key ,⼀个是主 key ,会设置过期时间,⼀个是备 key ,不会设置过期,它们只是 key 不⼀样,但是 value 值是⼀样的,相当于给缓存数据做了个副本。
当业务线程访问不到 主key 的缓存数据时,就直接返回 备key 的缓存数据,然后在更新缓存的时候,同时更新 主 key 和 备key 的数据。
d.后台更新策略
业务线程不再负责更新缓存,缓存也不设置有效期,⽽是让缓存“永久有效”,并将更新缓存的⼯作交给后台线程定 时更新。
2.Redis 故障宕机
应对策略:
针对 Redis 故障宕机⽽引发的缓存雪崩问题,常⻅的应对⽅法有下⾯这⼏种:
1.服务熔断或请求限流机制
2.构建 Redis 缓存⾼可靠集群
服务熔断或请求限流机制
因为 Redis 故障宕机⽽导致缓存雪崩问题时,我们可以启动服务熔断机制,暂停业务应⽤对缓存服务的访问,直接 返回错误,不⽤再继续访问数据库,从⽽降低对数据库的访问压⼒,保证数据库系统的正常运⾏,然后等到 Redis 恢复正常后,再允许业务访问缓存服务。
服务熔断机制是保护数据库的正常允许,但是暂停了业务应⽤访问缓存系统,全部业务都⽆法正常⼯作。 为了减少对业务的影响,我们可以启动请求限流机制,只将少部分发送到数据库进⾏处理,再多的请求就在⼊⼝直 接拒绝服务,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
构建 Redis 缓存⾼可靠集群
服务熔断或请求限流机制是缓存雪崩发⽣后的应对⽅案,我们最好通过主从节点的⽅式构建 Redis 缓存⾼可靠集 群。
如果 Redis 缓存的主节点故障宕机,从节点可以切换成主节点,继续提供缓存服务,避免了由于 Redis 故障宕 机⽽导致缓存雪崩问题。
缓存击穿
原因:
我们的业务通常会有⼏个数据会被频繁地访问,⽐如秒杀活动,这类被频繁地访问的数据被称为热点数据。
如果缓存中的某个热点数据过期了,此次⼤量的请求访问了该热点数据,就⽆法从缓存中读取,直接访问数据库, 数据库很容易就被⾼并发的请求冲垮,这就是缓存击穿的问题。
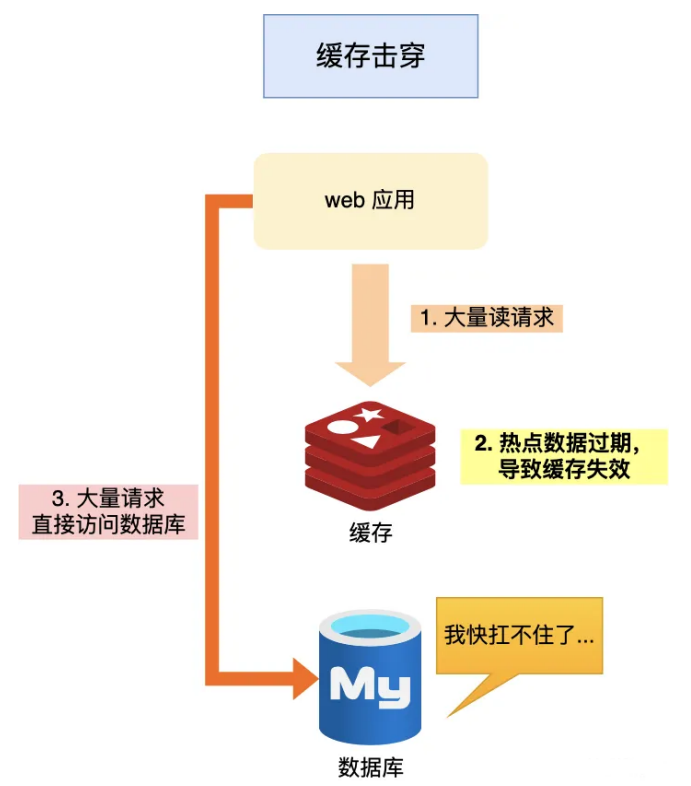
可以发现缓存击穿跟缓存雪崩很相似,可以认为缓存击穿是缓存雪崩的⼀个⼦集。
应对⽅案:
1.互斥锁⽅案,保证同⼀时间只有⼀个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取 缓存,要么就返回空值或者默认值。
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓 存以及重新设置过期时间。
双⼗⼀⻢爸爸突发奇想,想拍卖⾃⼰穿了20年的⽼布鞋,并且附带本⼈签名,程序员将该鞋的信息存到了 redis 中,设置了3⼩时过期。寻思3⼩时够他们抢了吧,但他低估了⻢爸爸的魅⼒。 该商品引起了⼀千万⼈关注,这些⼈不断的竞拍这双鞋,价格越拍越⾼,⻢爸爸乐开了花。 竞拍了2⼩时59分,⻢上要拍到⼀个亿了,突然这双鞋在 redis ⾥的 key 数据过期了,导致该 key 的⼤量请 求,都打到了数据库,直接导致数据库挂掉了,服务⽆法响应。 竞拍到此结束,鞋没卖出去,⻢爸爸⼜不开⼼了,把这个程序员也外派到⾮洲了。
⼀句话总结
某⼀个热点 key,在不停地扛着⾼并发,当这个热点 key 在失效的⼀瞬间,持续的⾼并发访问就击破缓存直 接访问数据库,导致数据库宕机。
缓存穿透

发⽣的两种情况
1. 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据。
2. ⿊客恶意攻击,故意⼤量访问某些读取不存在数据的业务。
三种应对缓存穿透的⽅案
1.⾮法请求的限制。
2.缓存空值或者默认值。
3.使⽤布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在。
⾮法请求的限制
当有⼤量恶意请求访问不存在数据的时候,也会发⽣缓存穿透,因此在 API ⼊⼝处我们要判断请求参数是否合 理,请求参数是否含有⾮法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进⼀步访问缓存 和数据库。
缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置⼀个空值或者默认值,这样后续请求 就可以从缓存中读取到空值或者默认值,返回给应⽤,⽽不会继续查询数据库。
布隆过滤器
使⽤布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在。我们可以在写⼊数据库数据 时,使⽤布隆过滤器做个标记,然后在⽤户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速 判断数据是否存在,如果不存在,就不⽤通过查询数据库来判断数据是否存在。
即使发⽣了缓存穿透,⼤量请求只会查询 Redis 和布隆过滤器,⽽不会查询数据库,保证了数据库能正常运 ⾏, Redis ⾃身也是⽀持布隆过滤器的。
⼩⻢哥做了⼀个⽹站⽕了,动了别⼈的蛋糕,于是开始疯狂攻击⼩⻢哥的⽹站,由于⼩⻢哥⽹络安全⽅⾯学 艺不精被⼈钻了空⼦。 某⼈⽤脚本疯狂的给⼩⻢哥发送请求,查询 id = -1 的数据,Redis 并没有这样的数据,这时候就穿透 Redis,直接打到了数据库上。 半夜⼩⻢哥在睡觉并没有察觉,他疯狂攻击⼩⻢哥⼀晚上,结果把数据库搞挂了,然后⼩⻢哥的⽹站也挂 了。
⼀句话总结
Redis 缓存和数据库中没有相关数据,Redis 中没有这样的数据,⽆法进⾏拦截,直接被穿透到数据库,导致 数据库压⼒过⼤宕机。
总结的话
雪崩是⼤⾯积的 key 缓存失效;
穿透是 Redis ⾥不存在这个缓存 key ;
击穿是 Redis 某⼀个热点 key 突然失效,
最终的受害者都是数据库。
SpringBoot 中使⽤ Redis
SpringBoot 使⽤ Spring Data 与 Redis 进⾏整合,在 SpringData 中提供了⼀个模板类 RedisTemplate 来 实现 redis 的相关操作。
操作 Redis 主要通过两种⽅式来完成:
1.RedisTemplate 模版类
2.注解⽅式
1、RedisTemplate 模版类
RedisTemplate 是简化 Redis 数据访问代码的⼯具类。在给定对象的基础⼆进制数据之间执⾏⾃动序列化/反序 列化。
中⼼⽅法是 execute ,⽀持实现 X 接⼝的 Redis 访问代码,它提供了 RedisConnection 处理,使得 RedisCallback 实现和调⽤代码都不需要显式关⼼检索/关闭 Redis 连接,或处理连接⽣命周期异常。
对于典型 的单步动作,有各种⽅便的⽅法。⼀旦配置好,这个类就是线程安全的。
这是 Redis ⽀持的核⼼类。⼀般我们使 ⽤它的⼦类 StringRedisTemplate 类。
SpringBoot 提供的 Redis 数据结构的操作类
ValueOperations 类,提供 Redis String API 操作
ListOperations 类,提供 Redis List API 操作
SetOperations 类,提供 Redis Set API 操作
ZSetOperations 类,提供 Redis ZSet(Sorted Set) API 操作
HashOperations 类,提供 Redis Hash API 操作
下来我们分别看看各个数据结构操作类的使⽤⽅式:
项目一
引⼊依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.0</version>
</dependency>java
搭建如图项目
配置application.yml(最好不带中文)
spring:
redis:
host: 192.168.65.3
port: 6379
jedis:
pool:
max-active: 8
min-idle: 2
max-idle: 5
max-wait: 2000
ValueOperations 类
@RestController
@RequestMapping("/string")
public class StringController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/a")
public String a() {
// 创建一个ValueOperations对象,用于操作Redis中的Value
ValueOperations<String, String> value = stringRedisTemplate.opsForValue();
// 设置A为"aaa"
value.set("A", "aaa");
// 设置B为"bbb",超时时间为10秒
value.set("B", "bbb", 10, TimeUnit.SECONDS);
// 设置A为"aaa2",如果不存在则设置
value.setIfAbsent("A", "aaa2");
//存在,失效;不存在,添加 value.setIfAbsent
//存在,覆盖;不存在,失效 value.setIfPresent
// 设置C为"ccc"
value.set("C", "ccc");
// 设置D为"1"
value.set("D", "1");
// 设置E为"eee"
value.set("E", "eee");
// 设置F为"fff"
value.set("F", "fff");
// 返回一个空字符串
return "";
}
@GetMapping("/b")
public String b() {
// 创建一个ValueOperations对象,用于操作Redis中的Value
ValueOperations<String, String> value = stringRedisTemplate.opsForValue();
// 获取A的值
String v1 = value.get("A");
// 获取B的值
String v2 = value.get("B");
// 获取C的值
String v3 = value.get("C");
// 将v1、v2、v3拼接起来返回
return v1 + ".." + v2 + ".." + v3;
}
@GetMapping("/c")
public String c() {
// 创建一个ValueOperations对象,用于操作Redis中的Value
ValueOperations<String, String> value = stringRedisTemplate.opsForValue();
// 在A后面追加"999888"
value.append("A", "999888");
// 将D的值加1
value.increment("D");
// 将D的值加3
value.increment("D", 3);
// 将D的值减1
value.decrement("D");
// 将D的值减3
value.decrement("D", 3);
// 设置C的过期时间为1分钟
value.getAndExpire("C", 1, TimeUnit.MINUTES);
// 删除E
String v1 = value.getAndDelete("E");
// 设置F的值为空字符串,过期时间为1毫秒
value.set("F", "", 1, TimeUnit.MILLISECONDS);
// 返回一个空字符串
return "";
}
}
ListOperations 类
@RestController
@RequestMapping("/list")
public class ListController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/a")
public String a() {
// 创建一个ListOperations对象,用于操作Redis中的List
ListOperations<String, String> list = stringRedisTemplate.opsForList();
// 向List中的"A"键添加两个元素
list.leftPush("A", "aa");
list.leftPushAll("A", "bb", "cc", "dd", "ee", "ff", "gg");
// 向List中的"A"键添加一个元素
list.rightPush("A", "11");
// 向List中的"A"键添加五个元素
list.rightPushAll("A", "22", "33", "44", "55", "66", "77", "88");
// 返回一个空字符串
return "";
}
@GetMapping("/b")
public String b() {
// 创建一个ListOperations对象,用于操作Redis中的List
ListOperations<String, String> list = stringRedisTemplate.opsForList();
// 获取List中的所有元素
List<String> allList1 = list.range("A", 0, -1);
// 获取List中的左边的元素
String l1 = list.leftPop("A");
// 获取List中的右边的元素
String l2 = list.rightPop("A");
// 获取List中的左边的前三个元素
List<String> lefts = list.leftPop("A", 3);
// 获取List中的右边的前两个元素
List<String> rights = list.rightPop("A", 2);
// 获取List中的所有元素
List<String> allList2 = list.range("A", 0, -1);
// 获取List中索引为3的元素
String v1 = list.index("A", 3);
// 返回一个空字符串
return "";
}
@GetMapping("/c")
public String c() {
// 创建一个ListOperations对象,用于操作Redis中的List
ListOperations<String, String> list = stringRedisTemplate.opsForList();
// 移除List中索引为2和"dd"的元素
list.remove("A", 2, "dd");
// 将List中索引为3的元素设置为"MMMMM"
list.set("A", 3, "MMMMM");
// 获取List中的元素数量
long size = list.size("A");
// 打印List的内容
System.out.println(list + ".....");
// 获取List中索引为3的元素
Long index1 = list.indexOf("A", "a");
// 获取List中索引为3的元素
Object index2 = list.indexOf("A", "aa");
// 返回一个空字符串
return "";
}
}
SetOperations 类
@RestController
@RequestMapping("/set")
public class SetController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/a")
public String a() {
// 创建一个SetOperations对象,用于操作Redis中的Set
SetOperations<String, String> set = stringRedisTemplate.opsForSet();
// 向Set中添加四个元素
set.add("A", "aa", "bb", "cc", "11", "22", "33", "44", "55");
// 向Set中添加两个元素
set.add("B", "aa", "bb", "cc", "dd", "ee");
// 向Set中添加三个元素
set.add("C", "bb", "22", "33", "ee", "44");
// 返回一个空字符串
return "";
}
@GetMapping("/b")
public String b() {
// 创建一个SetOperations对象,用于操作Redis中的Set
SetOperations<String, String> set = stringRedisTemplate.opsForSet();
// 获取Set中的所有元素
Set<String> all = set.members("A");
// 获取Set中的随机元素
String v1 = set.randomMember("A");
// 获取Set中的随机元素列表,数量为4
List<String> list = set.randomMembers("A", 4);
// 获取Set中的唯一元素列表,数量为4
Set<String> set1 = set.distinctRandomMembers("A", 4);
// 返回一个空字符串
return "";
}
@GetMapping("/c")
public String c() {
// 创建一个SetOperations对象,用于操作Redis中的Set
SetOperations<String, String> set = stringRedisTemplate.opsForSet();
// 获取Set中的B和C两个Set的差集
Set<String> set1 = set.difference("B", "C");
// 获取Set中的B和C两个Set的交集
Set<String> set2 = set.union("B", "C");
// 获取Set中的B和C两个Set的并集
Set<String> set3 = set.intersect("B", "C");
// 返回一个空字符串
return "";
}
}
ZSetOperations 类
@RestController
@RequestMapping("/zset")
public class ZSetController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/a")
public String a() {
// 创建一个ZSetOperations对象,用于操作Redis中的ZSet
ZSetOperations<String, String> zset = stringRedisTemplate.opsForZSet();
// 向ZSet中添加四个元素
zset.add("A", "aa", 9.8);
zset.add("A", "bb", 5.7);
zset.add("A", "cc", 1.5);
zset.add("A", "dd", 11);
zset.add("A", "ee", 2);
zset.add("A", "bb", 2);
zset.addIfAbsent("A", "ff", 4.7);
zset.addIfAbsent("A", "cc", 4.23);
// 获取ZSet中的所有元素
Set<String> set1 = Set.of("aa", "bb", "cc", "dd", "ee", "ff");
// 获取ZSet中的所有元素
Set<String> set2 = Set.of("aa", "mm", "33", "cc", "ff", "kk");
// 向ZSet中的B键添加元素
for (String s : set1) {
zset.add("B", s, Math.random() * 100);
}
// 向ZSet中的C键添加元素
for (String s : set2) {
zset.add("C", s, Math.random() * 100);
}
// 返回一个空字符串
return "";
}
@GetMapping("/b")
public String b() {
// 创建一个ZSetOperations对象,用于操作Redis中的ZSet
ZSetOperations<String, String> zset = stringRedisTemplate.opsForZSet();
// 获取ZSet中的所有元素
Set<String> set1 = zset.range("A", 0, -1);
// 获取ZSet中的元素数量
Long size = zset.count("A", 3, 7);
// 获取ZSet中的随机元素
String v1 = zset.randomMember("A");
// 获取ZSet中的随机元素列表,数量为3
List<String> set2 = zset.randomMembers("A", 3);
// 获取ZSet中的唯一元素列表,数量为3
Set<String> set3 = zset.distinctRandomMembers("A", 3);
// 返回一个空字符串
return "";
}
@GetMapping("/c")
public String c() {
// 创建一个ZSetOperations对象,用于操作Redis中的ZSet
ZSetOperations<String, String> zset = stringRedisTemplate.opsForZSet();
// 获取ZSet中的B和C两个ZSet的差集
Set<String> set1 = zset.difference("B", "C");
// 获取ZSet中的B和C两个ZSet的交集
Set<String> set2 = zset.union("B", "C");
// 获取ZSet中的B和C两个ZSet的并集
Set<String> set3 = zset.intersect("B", "C");
// 返回一个空字符串
return "";
}
}
注意:1、List集合产生最快的集合是Array.aList
2、怎么最快产生set集合是Set.of
HashOperations 类
@RestController
@RequestMapping("/hash")
public class HashController {
@Resource
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/a")
public String a() {
// 创建一个HashOperations对象,用于操作Redis中的Hash
HashOperations<String, String, String> hash = stringRedisTemplate.opsForHash();
// 向Hash中的"A"键添加四个键值对
hash.put("A", "A", "aaa");
hash.put("A", "B", "bbb");
hash.put("A", "C", "ccc");
hash.put("A", "D", "ddd");
// 使用putIfAbsent()方法向Hash中的"A"键添加一个新的键值对,如果该键已存在则不添加
hash.putIfAbsent("A", "B", "ddd");
// 创建一个HashMap对象,用于向Hash中的"A"键添加新的键值对
Map<String, String> map = new HashMap<>();
map.put("M1", "mmm1");
map.put("M2", "mmm2");
map.put("M3", "mmm3");
map.put("M4", "mmm4");
// 向Hash中的"A"键添加新的键值对
hash.putAll("A", map);
// 返回一个空字符串
return "";
}
@GetMapping("/b")
public String b(){
// 创建一个HashOperations对象,用于操作Redis中的Hash
HashOperations<String, String, String> hash = stringRedisTemplate.opsForHash();
// 使用get()方法获取Hash中键为"A",值为"B"的键值对
String v1 = hash.get("A","B");
// 使用entries()方法获取Hash中键为"A"的所有键值对
Map<String, String> map = hash.entries("A");
// 使用keys()方法获取Hash中键为"A"的所有键
Set<String> keys = hash.keys("A");
// 使用values()方法获取Hash中键为"A"的所有值
Collection<String> values = hash.values("A");
// 随机返回一个Hash中的键
String randomKey = hash.randomKey("A");
// 随机返回三个Hash中的键
List<String> list = hash.randomKeys("A",3);
// 返回null
return null;
}
@GetMapping("/c")
public String c(){
// 创建一个HashOperations对象,用于操作Redis中的Hash
HashOperations<String, String, String> hash = stringRedisTemplate.opsForHash();
// 使用delete()方法删除Hash中键为"A",值为"A"和"M2"的键值对
hash.delete("A","A","M2");
// 使用size()方法获取Hash中键为"A"的键值对数量
long len = hash.size("A");
// 返回null
return null;
}
}
SpringBootRedis1Application
@SpringBootApplication
public class SpringBootRedis1Application {
// 启动Spring Boot应用
public static void main(String[] args) {
SpringApplication.run(SpringBootRedis1Application.class, args);
}
}
/*
SpringApplication.run(SpringBootRedis1Application.class, args);
该行代码是Spring Boot应用的入口,用于启动Spring Boot应用。
其中,SpringApplication.run()方法是Spring Boot提供的用于启动应用的方法,它的参数包括:
SpringBootRedis1Application.class:表示要启动的应用类,即SpringBootRedis1Application类。
args:表示应用启动时传递的参数,通常可以为空。
因此,当我们调用SpringApplication.run()方法时,Spring Boot会自动加载SpringBootRedis1Application类,并执行该类的main方法。
在main方法中,Spring Boot会根据应用配置和环境等信息,自动创建并启动应用的各个组件,例如数据库连接池、缓存池、Web服务器等。
最终,Spring Boot会将应用启动成功的消息输出到控制台,并等待应用的退出信号。
*/
项目二
1.跟数据库相关的一些操作
2.redis一定是写在service中的
查询流程:
前段向后端的controller发送请求,controller接受到请求并查询请求,向service发送请求,service接收到请求会在redis中找信息。
如果有信息,会将redis的数据获取,返回给controller,再返回前端页面;
如果redis没有信息,它会查询mapper,mapper会连接数据库进行查询,把结果返回给service,service会把这个数据存放到redis里面去,再返回到controller,再返回给前端页面。
引⼊依赖
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.0.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
配置application.yml文件
spring:
datasource:
url: jdbc:mysql://192.168.65.3:3306/test
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
redis:
host: 192.168.65.3
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false
搭建如图项目
SpringBootRedis2Application:
@SpringBootApplication
public class SpringBootRedis2Application {
public static void main(String[] args) {
SpringApplication.run(SpringBootRedis2Application.class, args);
}
}
Emp:
@Data
@TableName("emp")
public class Emp implements Serializable {
@TableId(value = "empno", type = IdType.AUTO)
private Integer empNo; // 自动---emp_no
private String ename;
private String job;
private Integer mgr;
private String hireDate;
private Double sal;
private Double comm;
//@TableField("deptno")
private Integer deptNo;
@TableLogic(delval = "0", value = "1")
private Integer state;
}
JsonResult:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class JsonResult<T> {
private Boolean success;
private String error;
private Integer code;
private T data;
}
ResultTool:
public class ResultTool {
public static JsonResult success() {
return new JsonResult(true, null, 200, null);
}
public static JsonResult success(Object data) {
return new JsonResult(true, null, 200, data);
}
public static JsonResult fail(String msg){
return new JsonResult(false, msg, 500, null);
}
}
EmpMapper:
@Mapper
public interface EmpMapper extends BaseMapper<Emp> {
}
EmpService:
public interface EmpService extends IService<Emp> {
JsonResult find();
//
JsonResult delete(int empNo);
}
EmpServiceImpl:
@Slf4j//该注解用于声明该类使用日志框架为SLF4J,这意味着该类可以使用SLF4J来记录日志。
@Service//该注解用于声明该类是一个Service类,这意味着该类可以被Spring容器管理。
public class EmpServiceImpl extends ServiceImpl<EmpMapper, Emp> implements EmpService {
@Resource//该注解用于将一个StringRedisTemplate对象注入到该类中。
private StringRedisTemplate stringRedisTemplate;
@Override
public JsonResult find() {//该方法用于查询emp表数据,并返回查询结果。
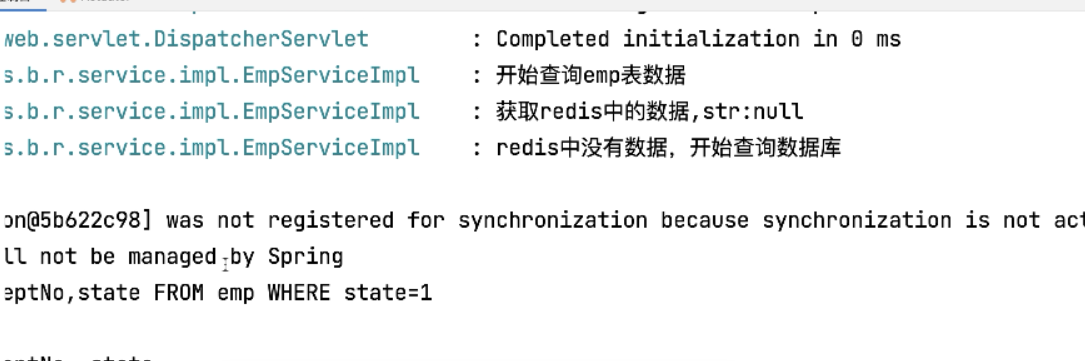
log.info("开始查询emp表数据");//该语句用于记录日志,表明查询emp表数据的操作开始了。
// 判断redis中是否存在数据
ValueOperations<String, String> operations = stringRedisTemplate.opsForValue();//该语句用于获取一个ValueOperations对象,该对象用于操作stringRedisTemplate对象中的值。
String str = operations.get("EMP_LIST");//该语句用于从stringRedisTemplate对象中获取"EMP_LIST"键对应的值。
log.info("获取redis中的数据,str:{}",str);//该语句用于记录日志,表明获取了redis中的数据,并将其打印输出。
if (str == null) {//该语句用于判断str是否为null,如果是,则说明redis中没有数据。
log.info("redis中没有数据,开始查询数据库");
// redis没有数据
// 查询数据库
List<Emp> list = list();
// 1.放入到redis中
operations.set("EMP_LIST", JSONArray.toJSONString(list));
log.info("将数据从数据库中获取到后,存放到redis");
// 2.返回给controller
return ResultTool.success(list);
}
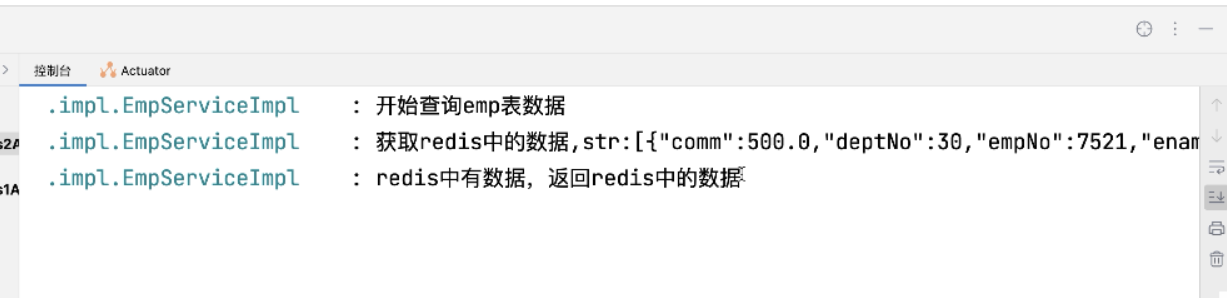
log.info("redis中有数据,返回redis中的数据");
// 将json字符串转换成list
List<Emp> emps = JSONArray.parseArray(str, Emp.class);
return ResultTool.success(emps);
}
@Override
public JsonResult delete(int empNo) {//该方法用于删除emp表中对应的数据,并返回删除结果。
removeById(empNo);//该语句用于删除emp表中对应的数据。
// 更新redis
ValueOperations<String,String> operations = stringRedisTemplate.opsForValue();//该语句用于获取一个ValueOperations对象,该对象用于操作stringRedisTemplate对象中的值。
operations.getAndDelete("EMP_LIST");//该语句用于从stringRedisTemplate对象中删除"EMP_LIST"键对应的值。
return ResultTool.success();//该语句用于从stringRedisTemplate对象中删除"EMP_LIST"键对应的值。
}
}
EmpController:
@RestController
@RequestMapping("/emp")
public class EmpController {
@Resource
private EmpService empService;
@GetMapping
public JsonResult find() {
return empService.find();
}
@DeleteMapping("/{id}")
public JsonResult delete(@PathVariable int id) {
return empService.delte(id);
}
}
运行结果:
1、查询功能
1.启动程序,并清除控制台

2、第一次测
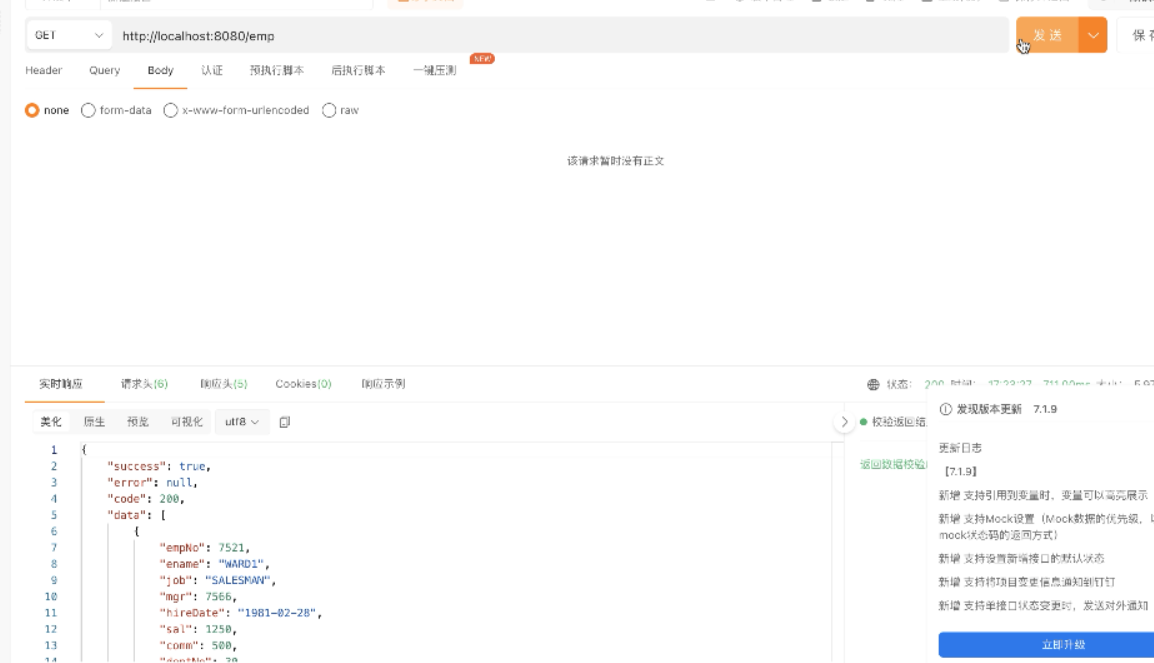
3、

4、
中文被编译后的内容

5、第2次测
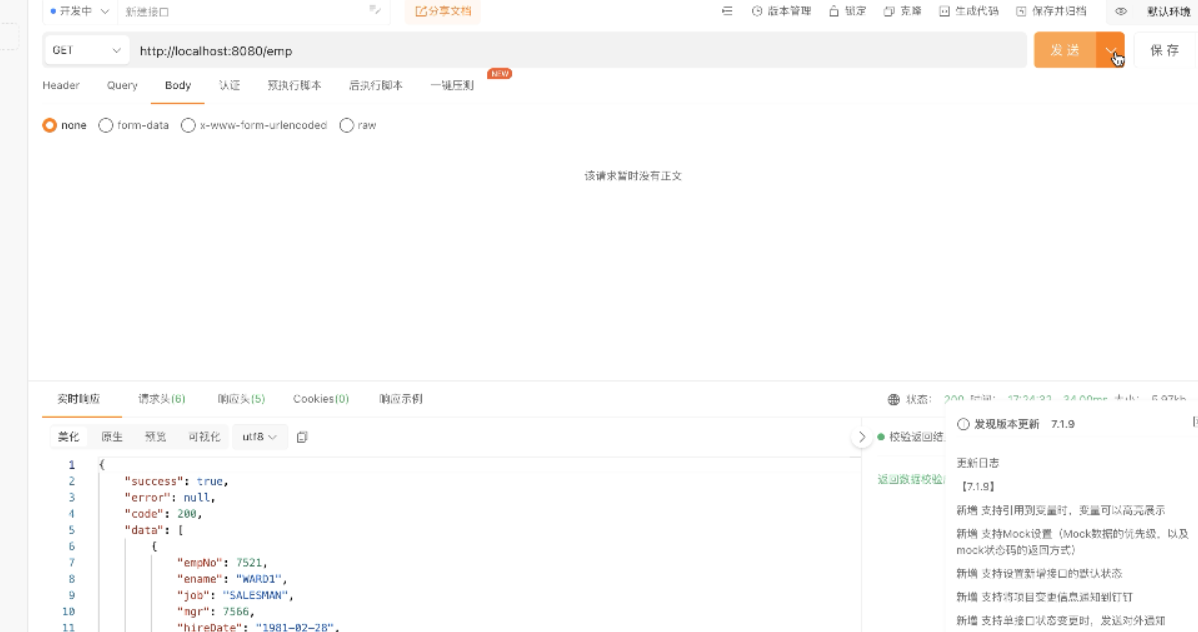
6、查看控制台,不从数据库中取,而从redis中取
2、删除功能
1.启动程序
2.第一次测试

3.查看控制台,成功删掉

3.第二次测试,查询没有对应的7521

2、注解⽅式
刚才的模版类可以处理 SpringBoot 对 Redis 的操作,但是⼜略显麻烦,有没有⼀种简单⽅式呢?
答案:
注解,我们可以使⽤提供的注解来对 Redis 进⾏操作。Spring 从 3.1 开始就引⼊了对 Cache 的⽀持。定义 了 org.springframework.cache.Cache 和 org.springframework.cache.CacheManager 接⼝来统⼀不同的 缓存技术。并⽀持使⽤注解简化我们的开发。
@CacheConfig 注解
@Cacheable() ⾥⾯都有⼀个 value=“xxx” 的属性,这显然如果⽅法多了,写起来也是挺累的,如果可以⼀次 性声明完 那就省事了。
所以,有了 @CacheConfig 这个配置, @CacheConfig is a class-level annotation that allows to share the cache names ,如果你在你的⽅法写别的名字,那么依然以⽅法的名 字为准。
@Cacheable 注解
缓存注解,如果redis中有数据,从redis中取,如果redis没有数据,从数据库中取,从数据库取完之后,再缓存到redis中取。
@Cacheable 注解在⽅法上,表示该⽅法的返回结果是可以缓存的。也就是说,该⽅法的返回结果会放在缓存中, 以便于以后使⽤相同的参数调⽤该⽅法时,会返回缓存中的值,⽽不会实际执⾏该⽅法。

注意:异步:张三和李四去吃饭,张三吃完了,不等李四,先走了
同步:张三和李四去吃饭,张三吃完了,等李四,一起走
keyGenerator 说明

/*
cacheNames:在缓存中的名称,和value作⽤⼀致
key:参数名,和cacheNames⼀起组成最终的缓存Key
unless:当ID⼤于5时不缓存数据,符合条件不缓存
condition:当age⼩于30时才缓存数据,符合条件缓存
*/
@Cacheable(cacheNames = "dailyblue", key = "#id", unless = "#id>5", condition =
"#age<=30")
public JsonResult dailyblue(int id, int age) {
return ResultTool.success(mapper.find(id,age));
}
@CachePut 注解
不管redis中有没有数据,都要连数据库,并且把数据库中的数据更新到缓存中
@CachePut 的作⽤主要针对⽅法配置,能够根据⽅法的请求参数对其结果进⾏缓存;
和 @Cacheable 不同的是, 它每次都会触发真实⽅法的调⽤。⼀般⽤于更新操作,调⽤这个注解后会访问数据库,并将数据库的内容同步到 Redis 中。
@CacheEvict 注解
对指定的数据进行删除
@CachEvict 的作⽤主要针对⽅法配置,能够根据⼀定的条件对缓存进⾏清空。
// 清空当前cache name下的所有key
@CachEvict(allEntries = true)
@Caching 注解
@Caching 可以使注解组合使⽤,⽐如根据 id 查询⽤户信息,查询完的结果为{key = id,value = userInfo},但我们现 在为了⽅遍,想⽤⽤户的⼿机号,邮箱等缓存对应⽤户的信息,这时候我们就要使⽤ @Caching 。例:
@Caching(put = {
@CachePut(value = "user", key = "#user.id"),
@CachePut(value = "user", key = "#user.username"),
@CachePut(value = "user", key = "#user.email")
})
public User getUserInfo(User user){
...
return user;
}
注意:如果要使⽤注解⽅式必须在启动类前引⼊ @EnableCaching 注解。
项目三
引⼊依赖
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.0.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.2</version>
</dependency>
</dependencies>
配置application.yml文件
spring:
datasource:
url: jdbc:mysql://192.168.65.3:3306/test
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
redis:
host: 192.168.65.3
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false
搭建如图项目
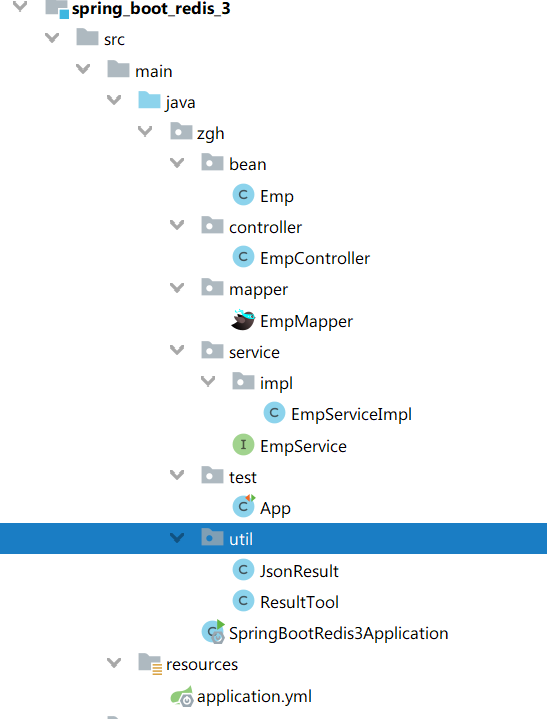
SpringBootRedis3Application:
//开启缓存
@EnableCaching
@SpringBootApplication
public class SpringBootRedis3Application {
public static void main(String[] args) {
SpringApplication.run(SpringBootRedis3Application.class, args);
}
}
/*
@EnableCaching 是 Spring 框架中的一个注解,用于启用缓存功能。当我们在应用中使用 Spring 框架提供的缓存时,需要在相应的类或方法上添加 @EnableCaching 注解,以启用缓存。
通过 @EnableCaching 注解,Spring 会自动为我们创建一个缓存管理器,该管理器可以管理多个缓存,包括缓存的清除、更新、添加等操作。我们可以通过配置缓存的参数来控制缓存的生命周期、缓存的大小、缓存的过期时间等。
启用缓存有助于提高应用的性能和响应速度,特别是在一些数据量较大、访问频率较高的场景中,缓存的作用更为明显。但是,启用缓存也需要注意缓存的副作用,例如缓存的命中率、缓存的过期时间、缓存的数据一致性等问题,需要我们根据实际情况进行合理的配置和管理。
*/
Emp:
@TableName("emp")
@Data
public class Emp implements Serializable {
@TableId(value = "empno", type = IdType.AUTO)
private Integer empNo; // 自动---emp_no
private String ename;
private String job;
private Integer mgr;
private String hireDate;
private Double sal;
private Double comm;
//@TableField("deptno")
private Integer deptNo;
@
TableLogic(delval = "0", value = "1")
private Integer state;
}
JsonResult
@Data
@NoArgsConstructor
@AllArgsConstructor
public class JsonResult<T> implements Serializable {
private Boolean success;
private String error;
private Integer code;
private T data;
}
ResultTool
public class ResultTool {
public static JsonResult success() {
return new JsonResult(true, null, 200, null);
}
public static JsonResult success(Object data) {
return new JsonResult(true, null, 200, data);
}
public static JsonResult fail(String msg) {
return new JsonResult(false, msg, 500, null);
}
}
EmpMapper
@Mapper
public interface EmpMapper extends BaseMapper<Emp> {
}
EmpController
@CrossOrigin
@RestController
@RequestMapping("/emp")
public class EmpController {
@Resource
private EmpService service;
@GetMapping("/{page}")
public JsonResult find(@PathVariable int page) {
return service.findByPage(page);
}
}
EmpService
public interface EmpService extends IService<Emp>{
JsonResult find(int id);
JsonResult updateEmp(Emp emp);
JsonResult deleteEmp(int id);
JsonResult findEmp(int id, String name, String job);
JsonResult findByPage(int page);
}
EmpServiceImpl
@Slf4j
@Service
public class EmpServiceImpl extends ServiceImpl<EmpMapper, Emp> implements EmpService {
//注入Mapper
@Resource
private EmpMapper empMapper;
//查询单条数据(查询注解)
@Cacheable(cacheNames = "emp_find_id", key = "#id")
public JsonResult find(int id) {
//日志输出
log.info("开始查询{}的数据", id);
//查询数据
Emp emp = empMapper.selectById(id);
//返回数据
return ResultTool.success(emp);
}
//更新数据(更新注解)
/*
先执行代码,再将结果重新更新到redis里面去
*/
@CachePut(cacheNames = "emp_find_id", key = "#emp.empNo")
public JsonResult updateEmp(Emp emp) {
//更新数据
empMapper.updateById(emp);
//返回更新成功信息,重新查
return ResultTool.success(empMapper.selectById(emp.getEmpNo()));
}
//删除数据(清缓存注解)
@CacheEvict(cacheNames = "emp_find_id", key = "#id")
public JsonResult deleteEmp(int id) {
//删除数据
empMapper.deleteById(id);
//返回删除成功信息
return ResultTool.success();
}
//根据id查询数据
//组合注解
@Caching(
put = {//一次可以更新多个缓存
@CachePut(cacheNames = "findEmp", key = "#id"),
@CachePut(cacheNames = "findEmp", key = "#name"),
@CachePut(cacheNames = "findEmp", key = "#job"),
},
evict = {//一次可以删除多个和缓存
@CacheEvict(cacheNames = "findEmp", key = "#name")
},
cacheable = {//一次可以添加多个缓存
@Cacheable(cacheNames = "find_emp_id", key = "#id"),
@Cacheable(cacheNames = "find_emp_id", key = "#name"),
}
)
public JsonResult findEmp(int id, String name, String job) {
//构造查询Wrapper
QueryWrapper<Emp> wrapper = new QueryWrapper<>();
wrapper.eq("empno", id);
wrapper.like("ename", name);
wrapper.eq("job", job);
//查询数据
Emp emp = empMapper.selectOne(wrapper);
//返回数据
return ResultTool.success(emp);
}
//分页查询数据
@Cacheable(cacheNames = "find_emp_page", key = "#page")
public JsonResult findByPage(int page) {
//使用PageHelper分页
PageHelper.startPage(page, 10);//第几页 每页显示多少条
//查询数据
List<Emp> list = list();//全查询
//构造分页对象
PageInfo<Emp> pageInfo = new PageInfo<>(list);//把list封装到PageInfo
//返回分页数据
return ResultTool.success(pageInfo);//发送给前端
}
}
APP
@Slf4j
@SpringBootTest
public class App {
@Resource
private EmpService empService;
@Test
public void a() {
JsonResult jsonResult = empService.find(7940);
log.info("result:{}", jsonResult);
}
@Test
public void b() {
Emp emp = new Emp();
emp.setEmpNo(7566);
emp.setEname("马熙朝");
emp.setSal(2976.00);
JsonResult jsonResult = empService.updateEmp(emp);
log.info("result:{}", jsonResult);
}
@Test
public void c() {
empService.deleteEmp(7566);
}
@Test
public void d() {
empService.findEmp(7935, "张", "程序员");
}
}
前端页面
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<!-- 引入样式 -->
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
</head>
<body>
<div id="app">
<template>
<el-table :data="pageInfo.list" style="width: 70%" max-height="640">
<el-table-column fixed prop="empNo" label="编号" width="110">
</el-table-column>
<el-table-column prop="ename" label="姓名" width="120">
</el-table-column>
<el-table-column prop="job" label="职位" width="120">
</el-table-column>
<el-table-column prop="hireDate" label="入职时间" width="160">
</el-table-column>
<el-table-column prop="sal" label="工资" width="300">
</el-table-column>
<el-table-column prop="comm" label="奖金" width="120">
</el-table-column>
<el-table-column fixed="right" label="操作" width="120">
<template slot-scope="scope">
<el-button type="text" size="small">
移除
</el-button>
</template>
</el-table-column>
</el-table>
<el-pagination background layout="prev, pager, next" :total="pageInfo.total"
@current-change='loadEmpData'>
</el-pagination>
</template>
</div>
</body>
</html>
<script src="js/vue.min.js"></script>
<script src="js/axios.min.js"></script>
<!-- 引入组件库 -->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<script>
new Vue({
el: '#app',
data() {
return {
pageInfo: {}
}
},
methods: {
loadEmpData(page) {
let _this = this
axios.get('http://localhost:8080/emp/' + page)
.then((response) => {
_this.pageInfo = response.data.data
})
}
},
created() {
this.loadEmpData(1)
}
})
</script>
运行结果:
1、执行find方法
2. 测试a方法
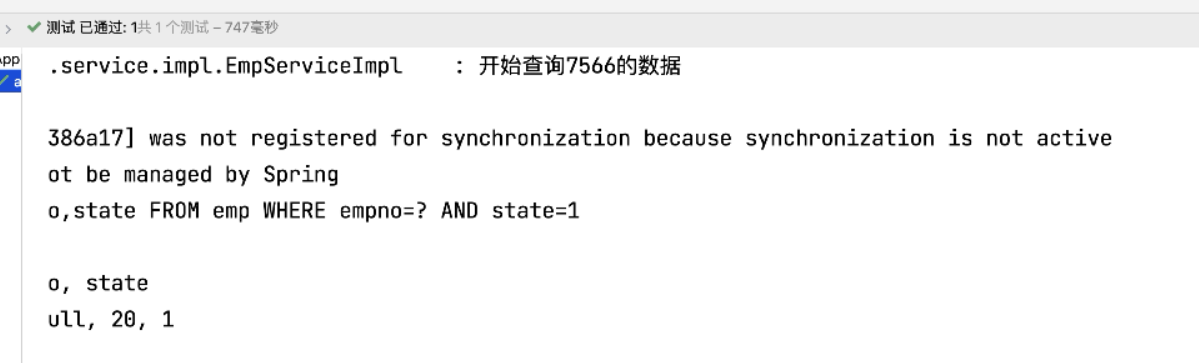
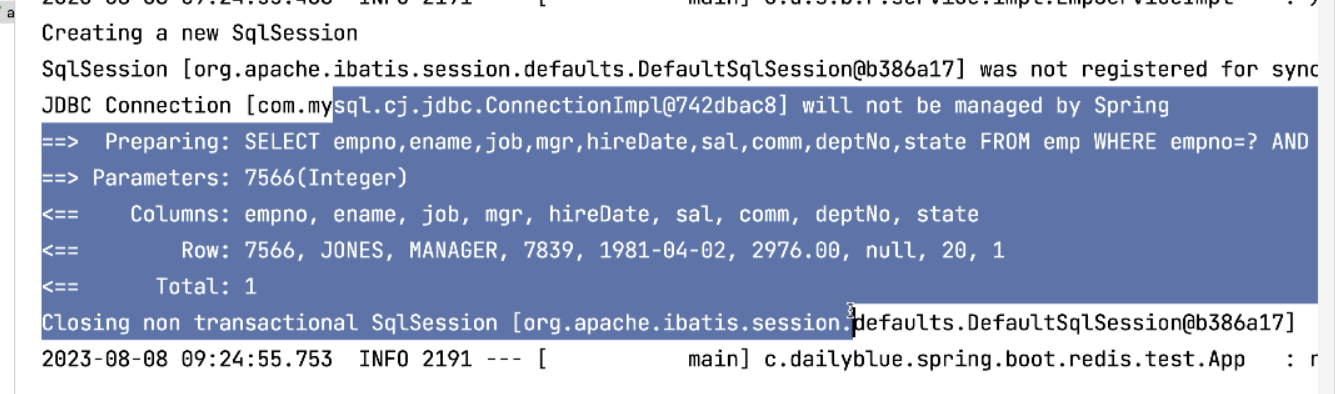
3.查看
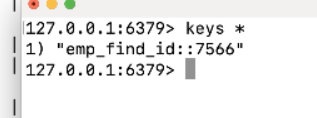
4.再查

注意:此时先从缓存中找有没有 emp_find_id:7566 这条数据,直接从缓存中取数据,
如果没数据,否则就执行(EmpServiceImpl)代码块中的代码。
2、执行updateEmp方法
更新完立马查询

再次查询,不连接数据库

3、执行deleteEmp方法


删除成功,也可以执行updateEmp方法更新删除,建议用@CacheEvict删除
4、执行findEmp方法

5、执行findByPage方法
1.开始测试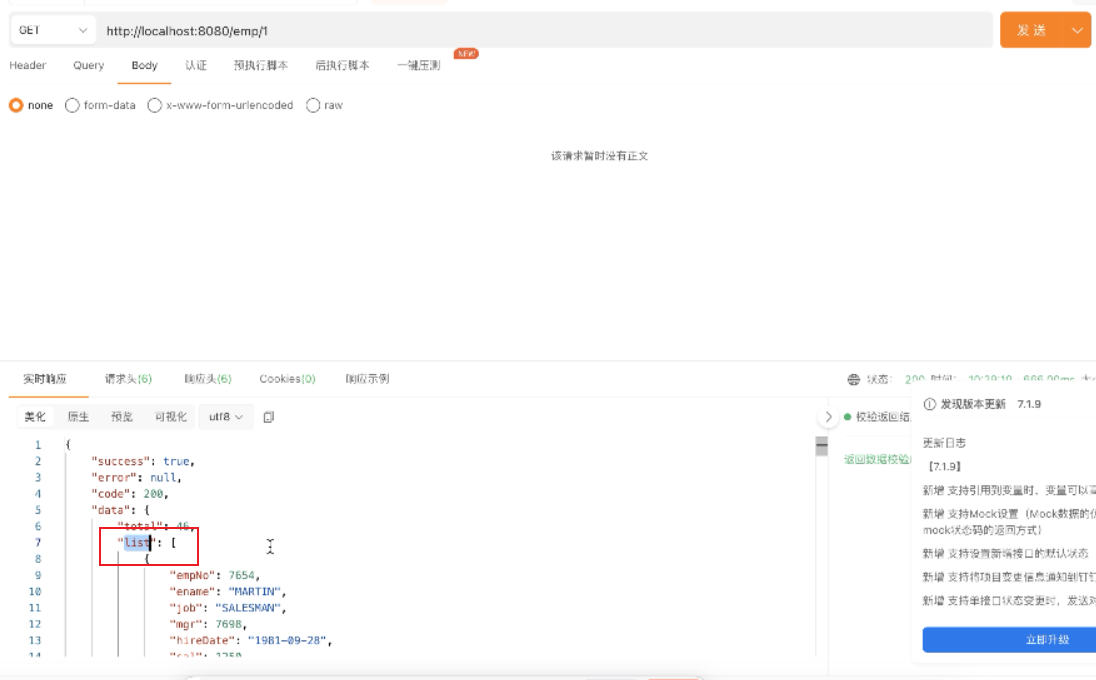
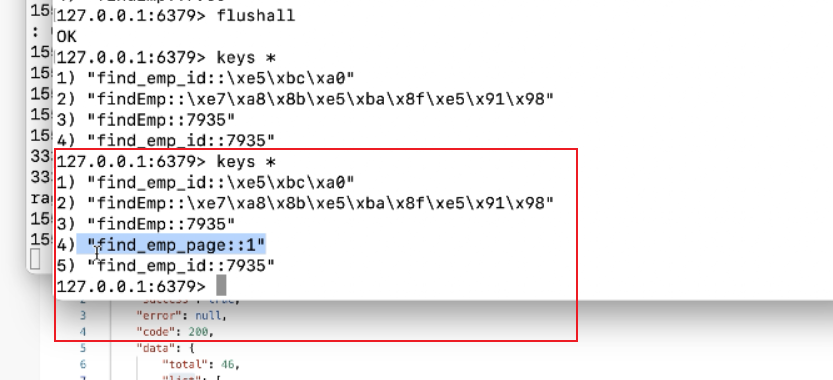
2.启动控制台,查询第一页数据,并清空控制台

redsis有数据
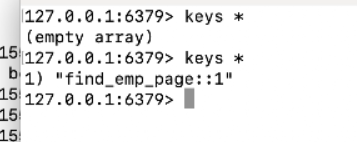
3.刷新页面

查看控制台,空的说明起作用了(没有从数据库中取,此时redis还没有第二页的数据)
 点击第2页,查看控制台
点击第2页,查看控制台

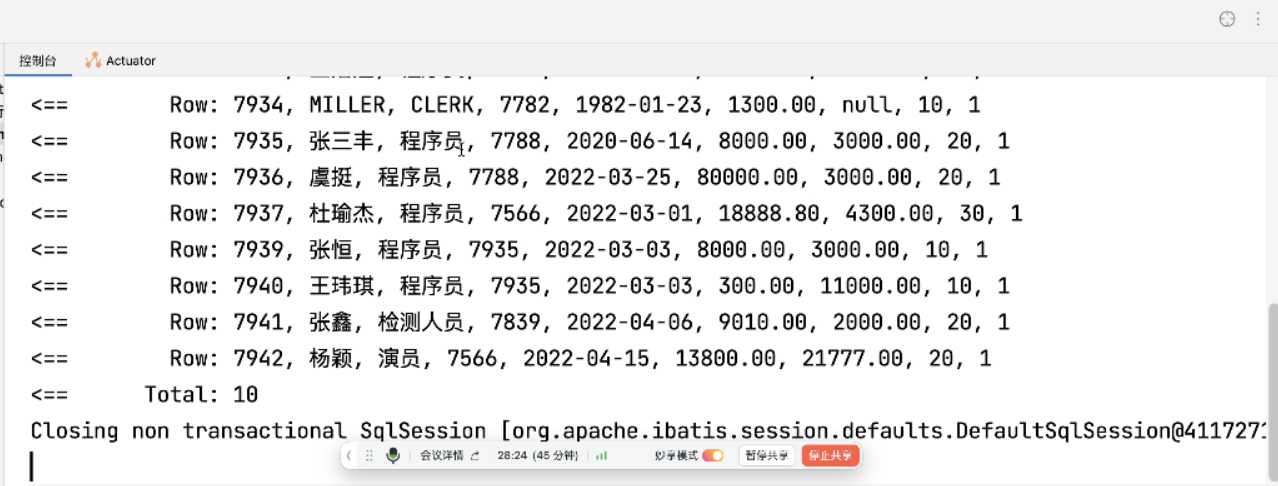
再次清空控制台,查第二页的数据
第2页中也有数据
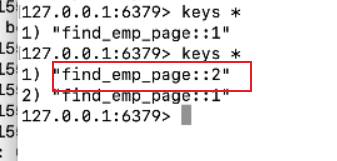
再点击3、4、5页,清空控制台,并查看

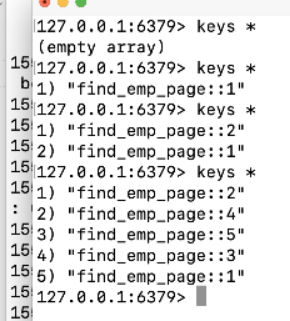
由此可见,缓存起作用了,不查询数据库,只通过缓存获取所需的数据
项目四
引⼊依赖
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.0.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.2</version>
</dependency>
</dependencies>
配置application.yml文件
spring:
datasource:
url: jdbc:mysql://192.168.65.3:3306/test
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
redis:
host: 192.168.65.3
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false
搭建如图项目
SpringBootRedis4Application
@SpringBootApplication
public class SpringBootRedis4Application {
public static void main(String[] args) {
SpringApplication.run(SpringBootRedis4Application.class, args);
}
}
JsonResult
//用于指定该类是一个JavaBean,可以被序列化和反序列化
@Data
//用于指定该类是一个无参构造函数,可以被自动创建。
@NoArgsConstructor
//用于指定该类是一个全参构造函数,可以被自动创建。
@AllArgsConstructor
public class JsonResult<T> implements Serializable {
private Boolean success;//用于存储响应是否成功,这里是true表示成功,false表示失败
private String error;//用于存储响应错误信息,这里是null表示没有错误
private Integer code;//用于存储响应错误代码,这里是0表示没有错误
private T data;//用于存储响应数据,这里是null表示没有数据
}
/*
这段代码是一个Java类,用于表示一个JSON响应对象。
该类的属性包括:响应是否成功、响应错误信息、响应错误代码和响应数据。该类的构造函数可以被自动创建,
可以用于创建JSON响应对象。该类的方法可以用于设置响应数据和错误信息。
T是一个Java类型,用于表示JSON响应对象中的数据类型。
*/
ResultTool
public class ResultTool {
//用于创建一个JSON响应对象,表示响应成功。
public static JsonResult success() {
return new JsonResult(true, null, 200, null);
}
//用于创建一个JSON响应对象,表示响应成功,并将数据作为响应数据返回。
public static JsonResult success(Object data) {
return new JsonResult(true, null, 200, data);
}
//用于创建一个JSON响应对象,表示响应失败,并将错误信息作为响应数据返回。
public static JsonResult fail(String msg) {
return new JsonResult(false, msg, 500, null);
}
}
Emp
//用于指定该Java类对应的数据库表的名称,这里是emp。
@TableName("emp")
@Data
public class Emp implements Serializable {
//用于指定该属性是该Java类的主键,type属性用于指定主键的类型,这里是自动类型。
// 在这段代码中,该属性的名称为empNo,表示该属性是该Java类的主键。
@TableId(value = "empno", type = IdType.AUTO)
private Integer empNo; // 自动---emp_no
private String ename;
private String job;
private Integer mgr;
private String hireDate;
private Double sal;
private Double comm;
//@TableField("deptno")
private Integer deptNo;
@TableLogic(delval = "0", value = "1")
private Integer state;
}
/*
序列化是将对象转换为字节流的过程,这个过程可以将对象在不同的环境之间进行传输、存储和恢复。序列化的好处在于:
可以将对象在不同的环境之间进行传输。
例如,将一个Java对象序列化后,可以将其通过网络传输到另一个计算机上,然后将其反序列化为Java对象。
可以将对象在不同的存储介质之间进行传输。
例如,将一个Java对象序列化后,可以将其存储在磁盘上,然后将其反序列化为Java对象。
可以将对象在不同的程序之间进行传输。
例如,将一个Java对象序列化后,可以将其传输到另一个Java程序中,然后将其反序列化为Java对象。
因此,序列化是一种非常有用的技术,可以帮助我们将对象在不同的环境之间进行传输、存储和恢复。
*/
EmpMapper
@Mapper
public interface EmpMapper extends BaseMapper<Emp> {
}
/*
这段代码是一个Java接口,用于继承BaseMapper接口,
表示该接口是一个Mapper接口,可以被MyBatis使用。
该接口的实现类需要继承BaseMapper接口,该接口定义了一些常用的方法,
包括插入、更新、删除、查询等。该接口的实现类需要使用MyBatis作为ORM框架,
将数据库操作和Java对象之间进行映射。
*/
EmpService
public interface EmpService extends IService<Emp> {
JsonResult find(int page);
JsonResult updateEmp(Emp emp);
JsonResult saveEmp(Emp emp);
JsonResult deleteEmp(int id);
}
/*
这段代码是一个Java接口,用于继承IService接口,表示该接口是一个Service接口,可以被Spring容器管理。
该接口的实现类需要继承IService接口,该接口定义了一些常用的方法,包括查询、更新、插入和删除等。
该接口的实现类需要使用Spring容器作为ORM框架,将数据库操作和Java对象之间进行映射。
*/
EmpServiceImpl
@Slf4j
@Service//该类实现了EmpService接口,用于实现各种查询、更新、插入和删除操作
public class EmpServiceImpl extends ServiceImpl<EmpMapper, Emp> implements EmpService {
@Resource//注入EmpMapper接口
private EmpMapper mapper;
@Resource//注入StringRedisTemplate接口
private StringRedisTemplate stringRedisTemplate;
//定义Redis中Emp表的分区列表前缀
private static final String PREFIX = "EMP_PREFIX::";
//定义Redis中Emp表的列表名
private static final String KEY = "EMP_LIST";
//定义Redis中PageInfo表的列表名
private static final String PAGE_INFO_EMP = "PAGE_INFO_EMP";
//全查询
/*
是一个查询方法,用于根据page参数查询Emp表中的数据,并将数据存储到Redis中。具体的业务逻辑如下:
1.判断当前page在Redis中是否存在,如果存在,则直接从Redis中获取数据。
2.如果不存在,则查询数据库,并将查询结果存入Redis中。
3.判断是否是第一次进入,如果是,则将pageInfo存入Redis中。
4.将查询的结果存放到Redis中,将每一个对象的引用存放到listOperations中。
5.返回查询结果。
*/
public JsonResult find(int page) {
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
ListOperations<String, String> listOperations = stringRedisTemplate.opsForList();
// 判断当前page在redis中是否存在
Long size = listOperations.size(KEY);
// 开始位置和结束位置
int begin = (page - 1) * 10;
int end = page * 10 - 1;
// 如果存在数据,返回redis中的数据
List<String> range = listOperations.range(KEY, begin, end);
log.info("range:{}", range);
if (!(range == null || range.size() == 0 || range.get(0) == null || range.get(0).trim().equals(""))) {
// 存在
List<Emp> list = new ArrayList<>();
range.forEach((e) -> {
String value = valueOperations.get(e);
Emp emp = JSONArray.parseObject(value, Emp.class);
list.add(emp);
});
PageInfo<Emp> pageInfo = new PageInfo<>(list);
return ResultTool.success(pageInfo);
}
// 如果不存在数据,查询数据库
PageHelper.startPage(page, 10);
List<Emp> list = list();
PageInfo<Emp> pageInfo = new PageInfo<>(list);
// 将pageInfo存入redis
valueOperations.set(PAGE_INFO_EMP, JSONArray.toJSONString(pageInfo));
// 判断是否是第一次进入
if (size == null || size == 0) {
for (int i = 0; i < pageInfo.getTotal(); i++) {
listOperations.rightPush(KEY, null);
}
}
// 将查询的结果存放到redis
// 将10条数据存放到valueOperations
final int[] i = {begin};
list.forEach((e) -> {
// 将一个对象存放到了redis中
valueOperations.set(PREFIX + e.getEmpNo(), JSONArray.toJSONString(e));
// 将每一个对象的引用存放到listOperations
// listOperations.rightPush("EMP_LIST", PREFIX + e.getEmpNo());
listOperations.set("EMP_LIST", i[0], PREFIX + e.getEmpNo());
i[0]++;
});
// 返回给controller
return ResultTool.success(pageInfo);
}
/*
是一个更新方法,用于将修改后的Emp对象存入数据库和Redis中。具体的业务逻辑如下:
1.修改数据库,使用Mapper的updateById方法将Emp对象更新到数据库中。
2.如果更新成功,则将修改后的Emp对象存入Redis中。
具体来说,使用ValueOperations的setIfPresent方法将Emp对象存入分区列表中,其中PREFIX是一个分区前缀,用于将数据存储到不同的分区中,
emp.getEmpNo()是Emp对象的EmpNo属性,mapper.selectById(emp.getEmpNo())是查询数据库中EmpNo为emp.getEmpNo()的Emp对象。
3.返回更新成功的结果。具体来说,使用ResultTool.success方法返回一个成功的结果。
*/
//更新方法,将修改后的Emp对象存入数据库和Redis中
@Override
public JsonResult updateEmp(Emp emp) {
//修改数据库
int row = mapper.updateById(emp);
//同步
if (row > 0) {//将修改后的Emp对象存入Redis中
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
valueOperations.setIfPresent(PREFIX + emp.getEmpNo(), JSONArray.toJSONString((mapper.selectById(emp.getEmpNo()))));
}
return ResultTool.success();
}
/*
是一个插入方法,用于将Emp对象存入数据库和Redis中。具体的业务逻辑如下:
1.插入数据库,使用Mapper的insert方法将Emp对象插入到数据库中。
2.如果插入成功,则将Emp对象存入Redis中。具体来说,使用ValueOperations的set方法将Emp对象存入分区列表中,
其中PREFIX是一个分区前缀,用于将数据存储到不同的分区中,emp.getEmpNo()是Emp对象的EmpNo属性。
然后,使用ListOperations的rightPush方法将Emp对象存入另一个分区列表中,其中KEY是一个分区列表,
用于存储所有Emp对象的EmpNo。
3.将分区列表中的数据存入另一个分区列表中。具体来说,使用ValueOperations的get方法获取分区列表中的数据,
然后使用PageInfo的setTotal和setPages方法更新分区列表中的数据。
4.返回插入成功的结果。具体来说,使用ResultTool.success方法返回一个成功的结果。
*/
//添加 插入方法,将Emp对象存入数据库和Redis中
@Override
public JsonResult saveEmp(Emp emp) {
//插入数据库
int row = mapper.insert(emp);
//如果插入成功,将Emp对象存入Redis中
if (row > 0) {
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
ListOperations<String, String> listOperations = stringRedisTemplate.opsForList();
QueryWrapper<Emp> wrapper = new QueryWrapper<>();
wrapper.select("max(empno) as empno");
Emp m = mapper.selectOne(wrapper);
emp.setEmpNo(m.getEmpNo());
//将Emp对象存入Redis中
valueOperations.set(PREFIX + m.getEmpNo(), JSONArray.toJSONString(emp));
//将Emp对象存入分区列表中
listOperations.rightPush(KEY, PREFIX + m.getEmpNo());
//将分区列表中的数据存入另一个分区列表中
String t = valueOperations.get(PAGE_INFO_EMP);
PageInfo<Emp> pageInfo = JSONArray.parseObject(t, PageInfo.class);
pageInfo.setTotal((pageInfo.getTotal() + 1));
if (pageInfo.getTotal() % 10 == 1) {
pageInfo.setPages((pageInfo.getPages() + 1));
}
valueOperations.set(PAGE_INFO_EMP, JSONArray.toJSONString(pageInfo));
}
return ResultTool.success();
}
/*
是一个删除方法,用于将Emp对象从数据库和Redis中删除。具体的业务逻辑如下:
1.从数据库中删除,使用Mapper的deleteById方法将Emp对象从数据库中删除。
2.如果删除成功,则将Emp对象从Redis中删除。具体来说,
使用ValueOperations的getAndDelete方法将Emp对象从分区列表中删除,
使用ListOperations的remove方法将Emp对象从另一个分区列表中删除。
3.将分区列表中的数据存入另一个分区列表中。具体来说,使用ValueOperations的get方法获取分区列表中的数据,
然后使用PageInfo的setTotal和setPages方法更新分区列表中的数据。
4.返回删除成功的结果。具体来说,使用ResultTool.success方法返回一个成功的结果。
*/
//删除
@Override
public JsonResult deleteEmp(int id) {
//从数据库中删除
int row = mapper.deleteById(id);
//如果删除成功,将Emp对象从Redis中删除
if (row > 0) {
ValueOperations<String, String> valueOperations = stringRedisTemplate.opsForValue();
ListOperations<String, String> listOperations = stringRedisTemplate.opsForList();
//从分区列表中删除
valueOperations.getAndDelete(PREFIX + id);
//从另一个分区列表中删除
listOperations.remove(KEY, 1, PREFIX + id);
//将分区列表中的数据存入另一个分区列表中
String t = valueOperations.get(PAGE_INFO_EMP);
PageInfo<Emp> pageInfo = JSONArray.parseObject(t, PageInfo.class);
pageInfo.setTotal(pageInfo.getTotal() - 1);
if (pageInfo.getTotal() % 10 == 0) {
pageInfo.setPages(pageInfo.getPages() - 1);
}
valueOperations.set(PAGE_INFO_EMP, JSONArray.toJSONString(pageInfo));
}
return ResultTool.success();
}
}
运行结果:
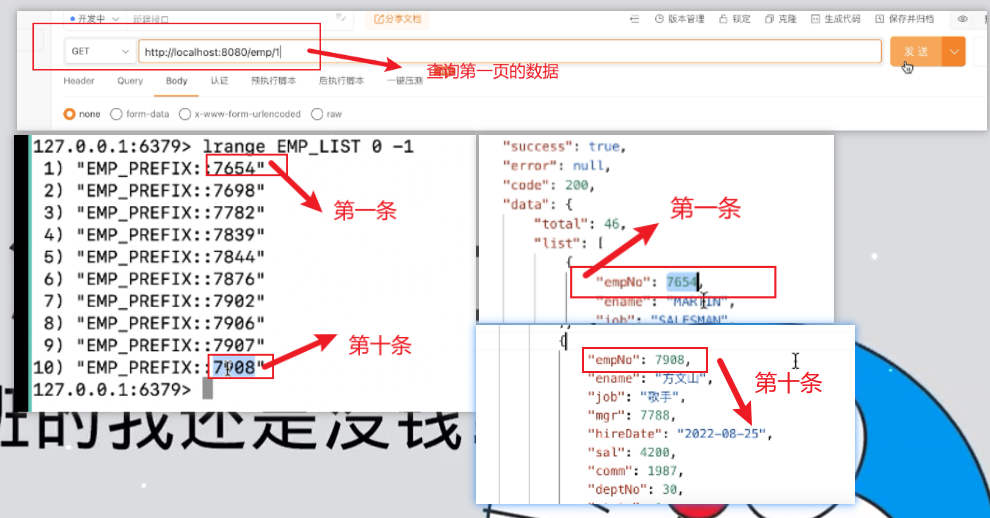
1、执行find方法
测试第一页
测试第二页

问题1:
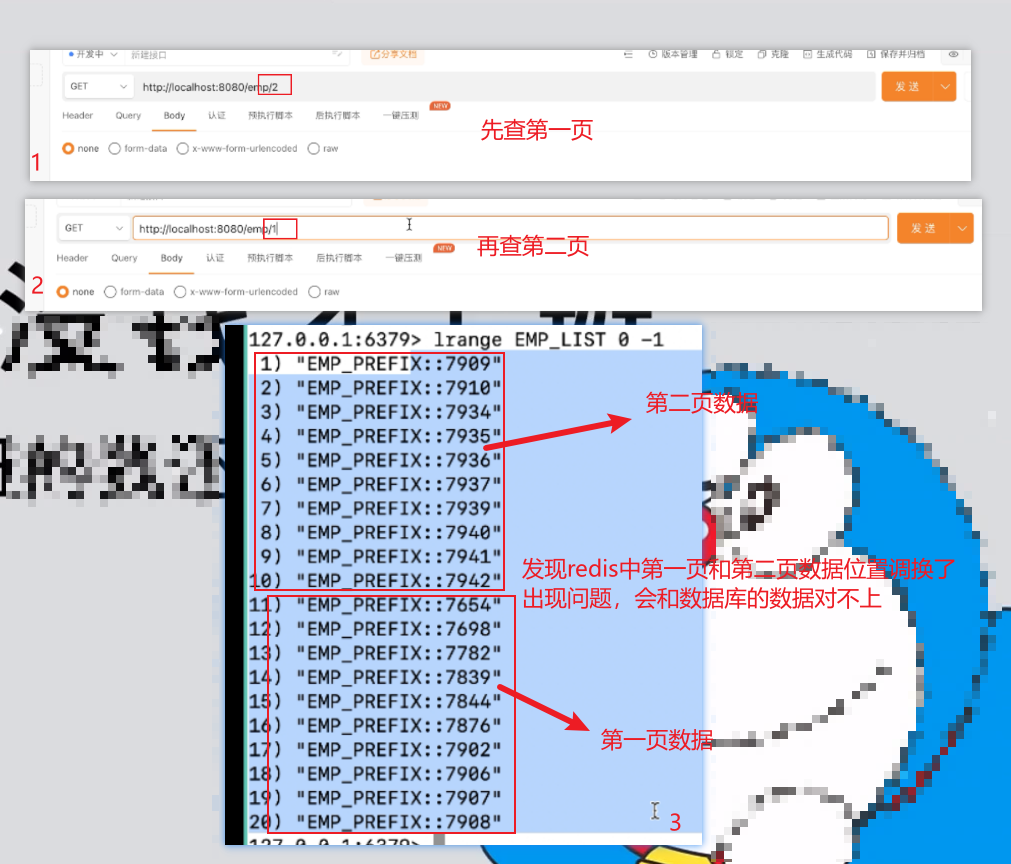
解决方法:先占位置,再依次替换null位置,把指定的页码数据添加其中(进行更新)
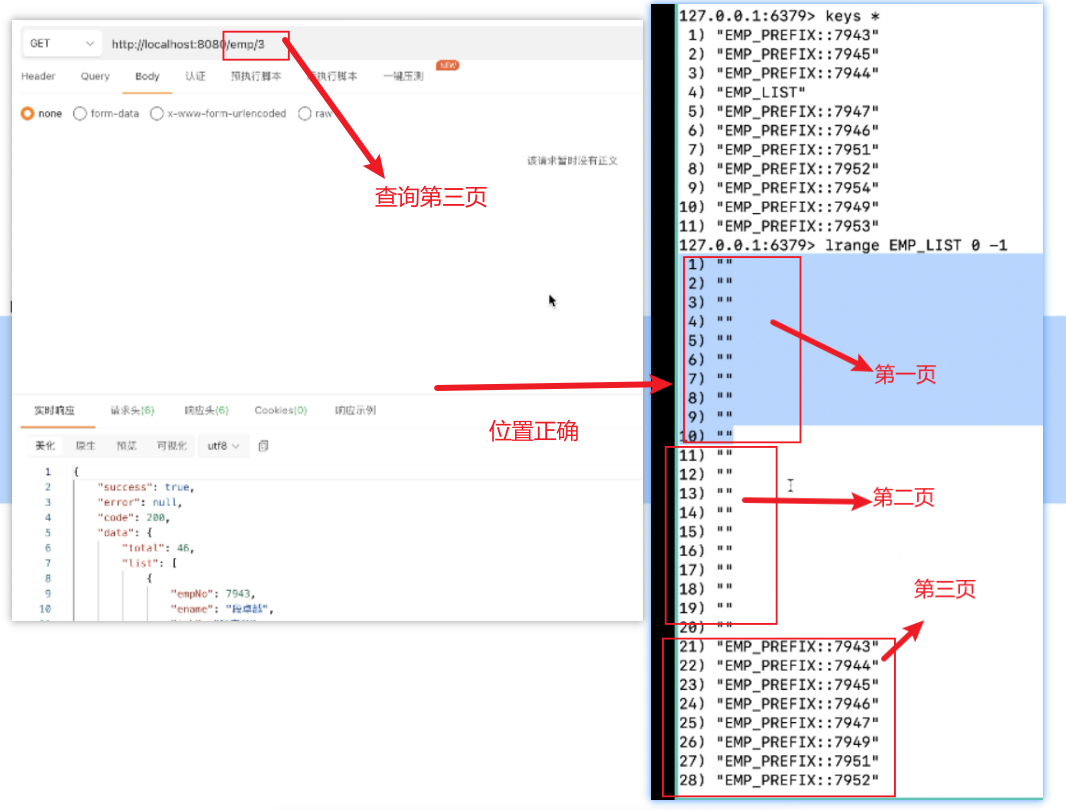
问题2:
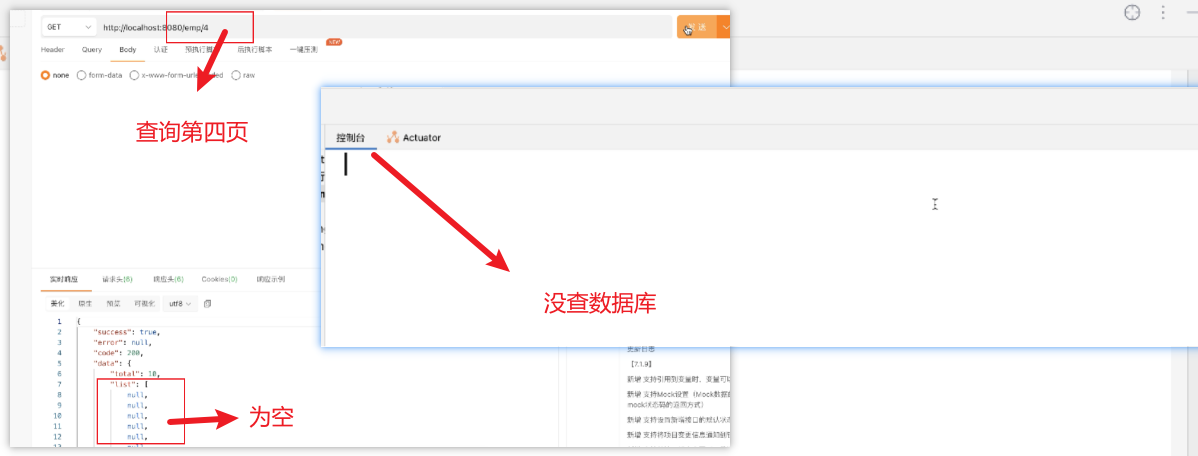
解决方法:修改条件判断
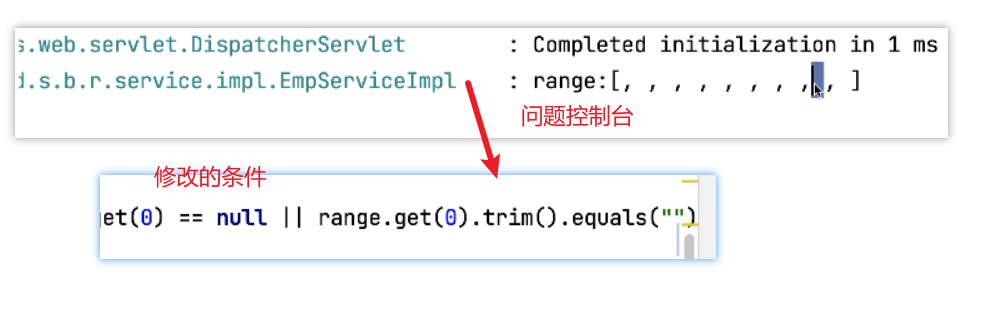
再次测试:
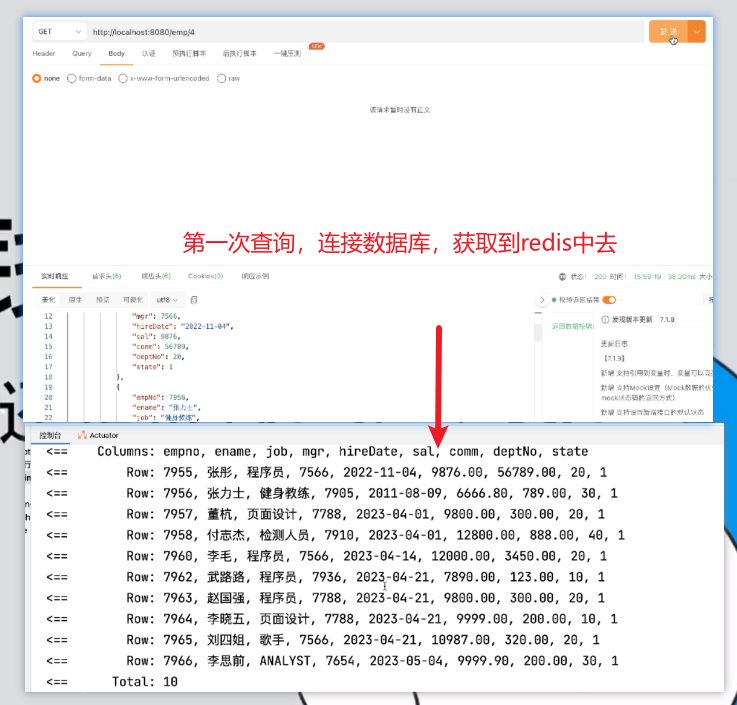

说明从redis中获取数据成功。
问题3:
上面例子中pageInfo是new出来的,不是从数据库关联出来的,想要将pageInfo放入到redis中,怎么做?
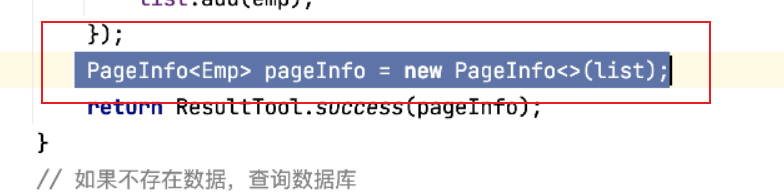
解决方法:
不newpageInfo,把原来的取出来,再把List和当前页数替换

2、执行updateEmp方法
查询redis中的信息

对7963进行修改
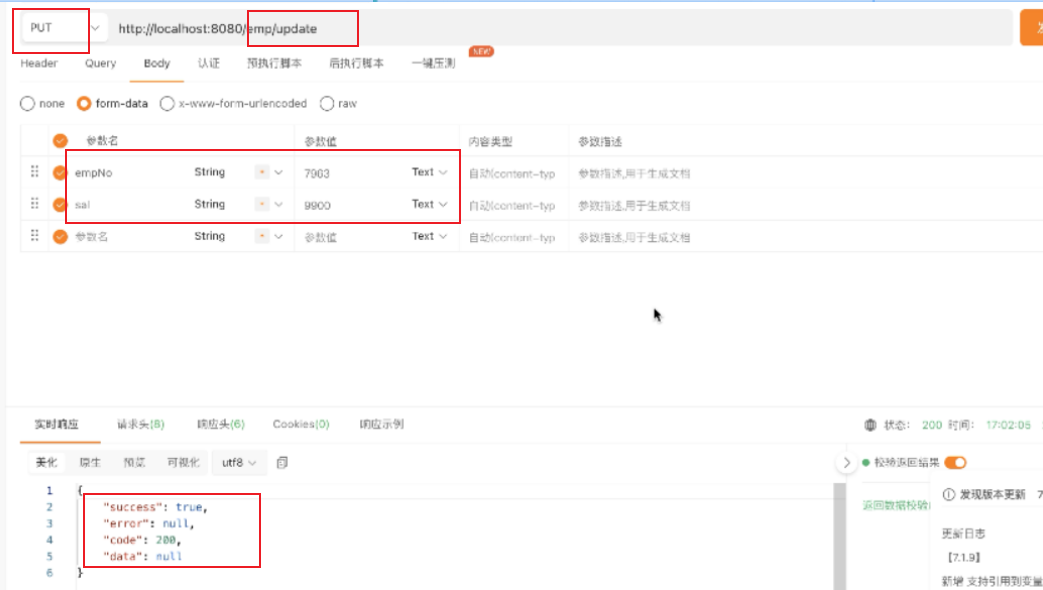
修改成功
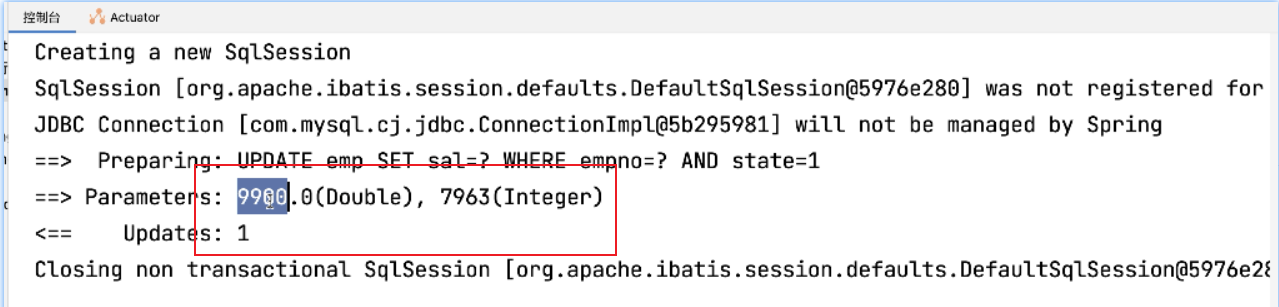
出现问题
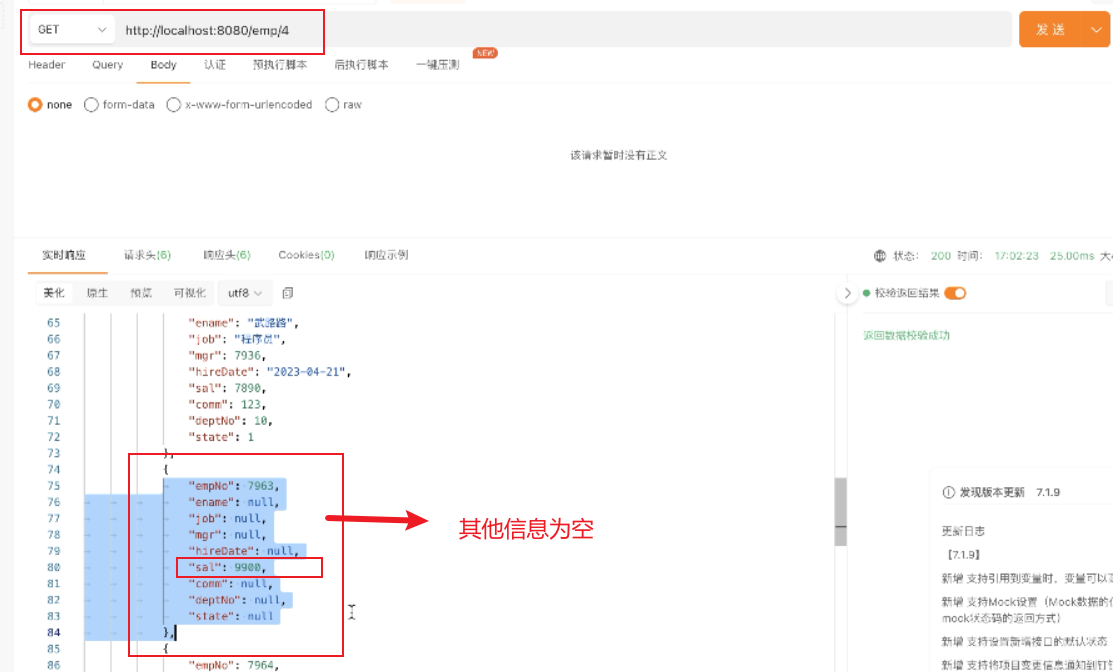
解决方法:


3、执行saveEmp方法
添加一个人
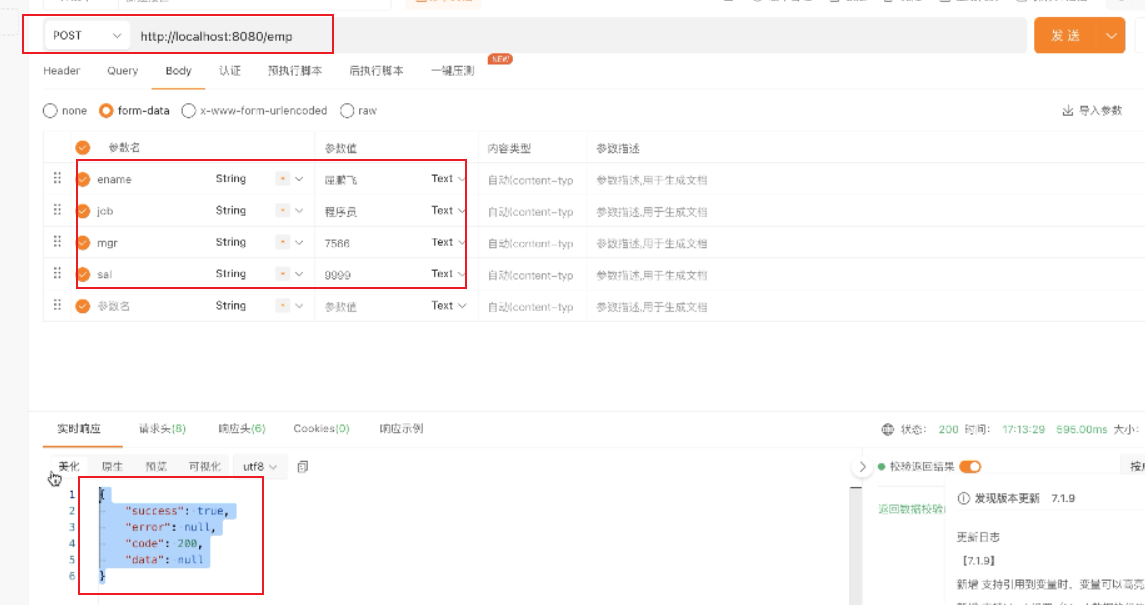

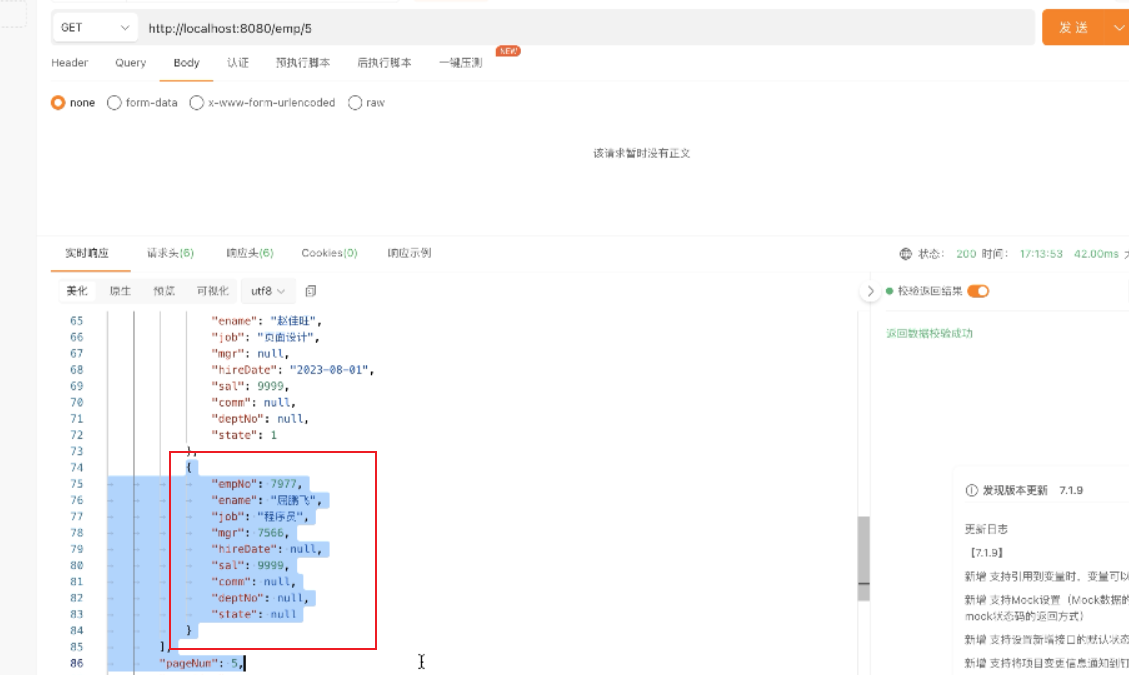

4、执行deleteEmp方法
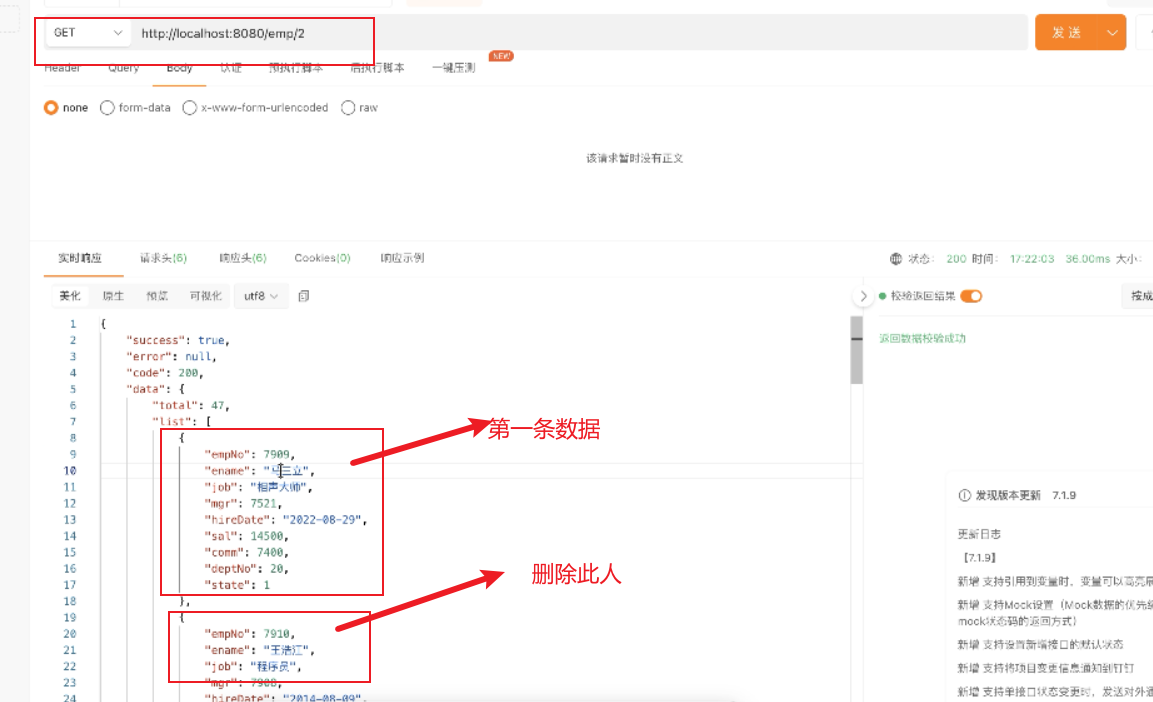
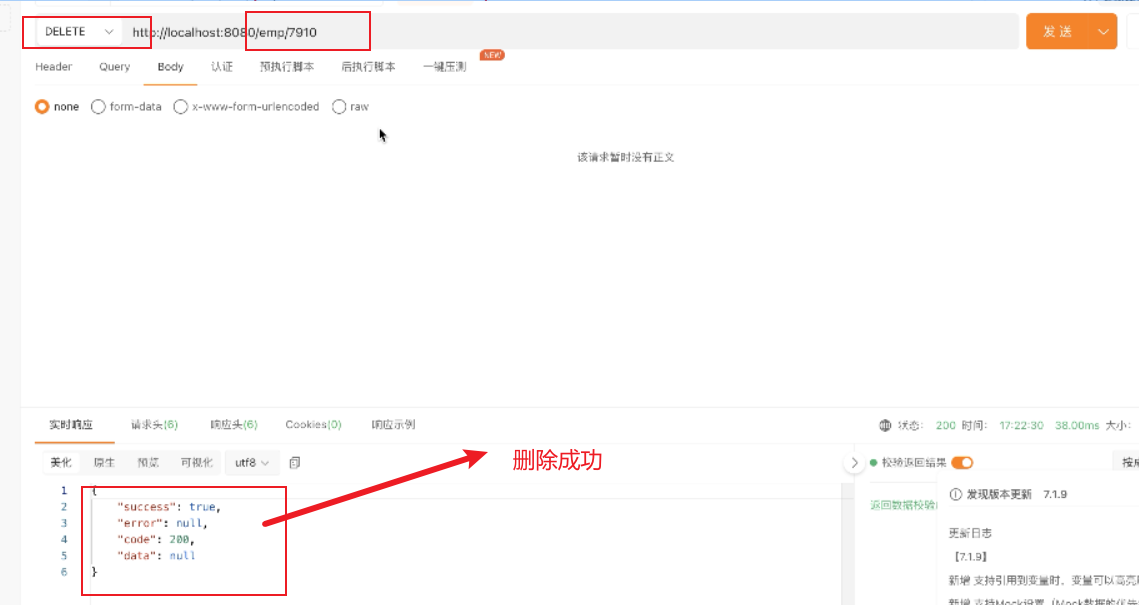


再查看redis中变化情况

持久化操作
Redis 如何将数据写⼊磁盘?
1.持久性是指将数据写⼊持久存储,例如固态磁盘 ( SSD )。 Redis 本身提供了⼀系列持久化选项:
2.RDB ( Redis 数据库): RDB 持久性以指定的时间间隔执⾏数据集的时间点快照。
3.AOF ( Append Only File ): AOF 持久化记录服务器接收到的每个写操作,在服务器启动时再次播放,重 建原始数据集。命令使⽤与 Redis 协议本身相同的格式以仅附加⽅式记录。当⽇志变得太⼤时, Redis 能 够在后台重写⽇志。
4.⽆持久性:如果您愿意,您可以完全禁⽤持久性,如果您希望您的数据只要服务器正在运⾏就存在。
5.RDB + AOF :可以在同⼀个实例中结合 AOF 和 RDB 。请注意,在这种情况下,当 Redis 重新启动 时, AOF ⽂件将⽤于重建原始数据集,因为它保证是最完整的。
最重要的是要了解 RDB 和 AOF 持久性之间的不同权衡。
持久化的意义
Redis 持久化的意义,在于数据备份和故障恢复。
⽐如你部署了⼀个 Redis ,作为 cache 缓存,当然也可以保 存⼀些较为重要的数据。如果没有持久化的话, Redis 遇到灾难性故障的时候,就会丢失所有的数据。
如果通过 持久化将数据持久化⼀份⼉在磁盘上去,然后定期⽐如说同步和备份到⼀些云存储服务上去,那么就可以保证数据 不丢失全部,还是可以恢复⼀部分数据回来的。
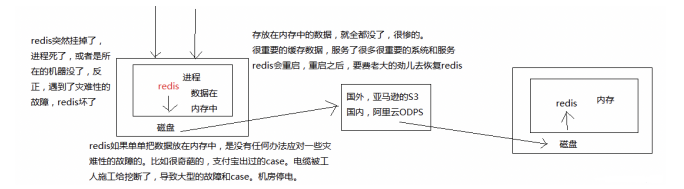
Redis 持久化 + 备份:⼀般将 Redis 数据从内存存储到磁盘。然后将磁盘数据备份⼀份即将数据上传到云服务器 上即可。如果左边的 Redis 进程坏了并且磁盘也坏了,此时可以在另⼀台服务器启动该 Redis ,然后将云服务器 上的数据 copy ⼀份到磁盘上, Redis 进程在启动过程中会从磁盘加载到内存中。
持久化主要是做灾难恢复,数据恢复,也可以归类到⾼可⽤的⼀个环节⾥⾯去。
⽐如你 Redis 整个挂了,然后 Redis 就不可⽤了,你要做的事情是让 Redis 变得可⽤,尽快变得可⽤。重启 Redis ,尽快让它对外提供服 务,但是就像刚说的,如果你没做数据备份,这个时候 Redis 启动了,也不可⽤啊,数据都没了。很可能说,⼤ 量的请求过来,缓存全部⽆法命中,在 Redis ⾥根本找不到数据,这个时候就死定了,缓存雪崩问题,所有请 求,没有在 Redis 命中,就会去 MySQL 数据库这种数据源头中去找,⼀下⼦ MySQL 承接⾼并发,然后就挂 了。 MySQL 挂掉,你都没法去找数据恢复到 Redis ⾥⾯去, Redis 的数据从哪⼉来?从 MySQL 来。
如果你把 Redis 的持久化做好,备份和恢复⽅案做到企业级的程度,那么即使你的 Redis 故障了,也可以通过 备份数据,快速恢复,⼀旦恢复⽴即对外提供服务。 Redis 的持久化,跟⾼可⽤,是有关系的。
RDB(Redis DataBase) 机制
快照( Snapshot ):
在指定的时间间隔内将内存中的数据集写⼊磁盘。
数据恢复
是将快照⽂件直接读到内存中。
Redis 会单独创建( fork )⼀个⼦进程来进⾏持久化,会先将数据写⼊到⼀个临时⽂件( dump.rdb )中,待持久化过 程结束后,再⽤本次的临时⽂件替换上次持久化后的⽂件。
fork 函数的作⽤
是复制⼀个与当前进程⼀样的进程,新进程的所有数据数值都和原进程⼀致,但是⼀个全新的进程,并作为原进程的⼦进程。
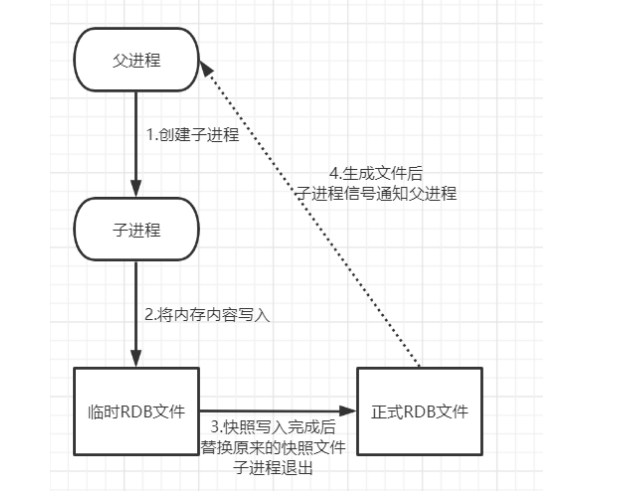
Redis 服务器在处理 bgsave 采⽤⼦线程进⾏ IO 写⼊,⽽主进程仍然可以接收其他请求,但创建⼦进程是同步 阻塞的,此时不接受其他请求。
RDB 的触发⽅式
⼿动触发:通过命令⼿动⽣成快照。
⾃动触发:通过配置参数的设置触发⾃动⽣成快照。 ⼿动触发
⼿动触发
执⾏ save 和 bgsave 命令,⼿动触发快照,⽣成 RDB ⽂件
save:该命令会阻塞当前 Redis 服务器,执⾏ save 命令期间, Redis 不能处理其他命令,直到 RDB 过程 结束为⽌(会造成⻓时间阻塞,不建议使⽤)。
bgsave:该命令执⾏后, Redis 会在后台异步进⾏快照操作,快照同时还可以响应客户端的请求,阻塞只发 ⽣在 fork 阶段,基本上 Redis 内部的所有 RDB 操作都是采⽤ bgsave 命令。
自动触发
⾃动触发有如下四种情况:
- redis.conf 配置⽂件中达到 save 参数的条件,⾃动触发 bgsave 。
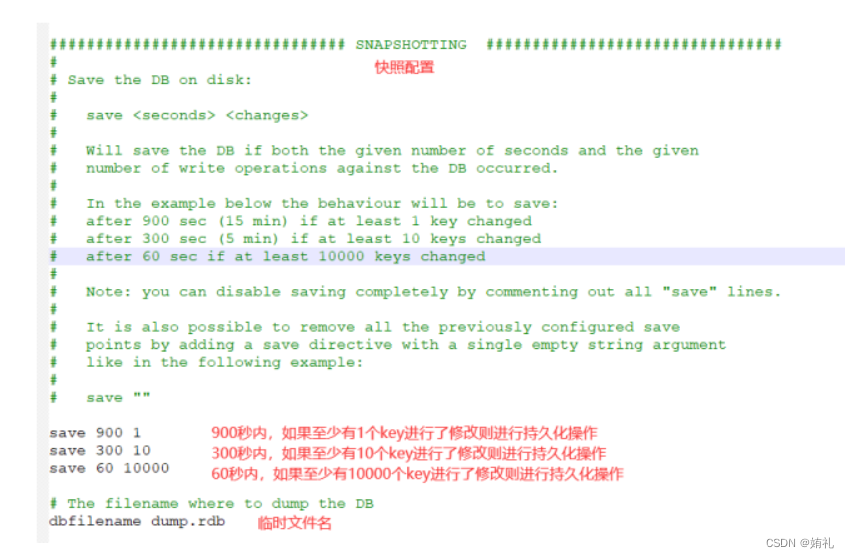
-
主从复制时,从节点要从主节点进⾏全量复制时也会触发 bgsave ,⽣成快照发送到从节点.
-
执⾏ shutdown (关闭 Redis 服务),会触发 bgsave 。
-
执⾏ flushall (⽣成⼀个空的临时⽂件 dump.rdb )。
RDB的数据恢复
将备份⽂件( dump.rdb )移动到 Redis 路径下(可以配置⽂件的存放路径)启动服务即可, Redis 启动会将⽂件数据 加载到内存,在此期间 Redis 会处于阻塞状态,直到全部数据存⼊内存。
RDB的优缺点
优点
数据恢复快。
体积⼩。
数据备份使⽤⼦进程,对redis服务性能影响⼩。
缺点
在⼀定时间间隔进⾏备份,当 Redis 意外宕机,将会丢失最后⼀次修改的数据,⽆法做到秒级持久化。
fork 进程时,会占⽤⼀定的内存空间。
RDB ⽂件是⼆进制的没有可读性。
AOF(Append Only File) 机制
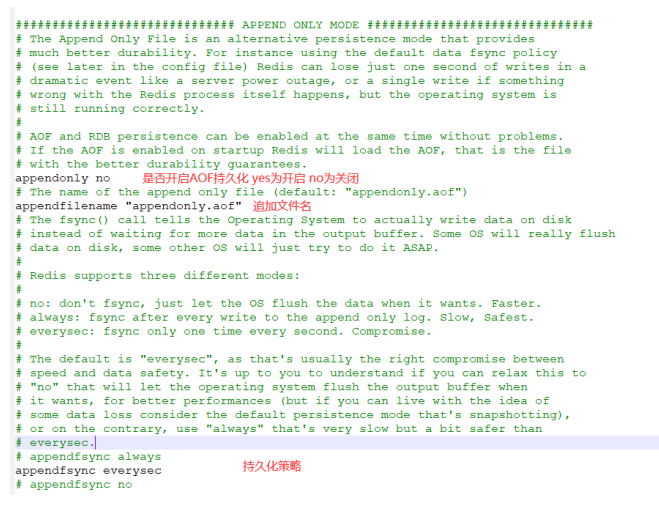
将客户端的每⼀个写操作命令以⽇志的形式记录下来,追加到 appendonly.aof 的⽂件末尾,在 Redis 服务器 重启时,会加载 aof ⽂件中的所有命令,来达到数据恢复的⽬的。
当有写命令请求时,会追加到 AOF 缓冲区内, AOF 缓冲区根据 AOF 持久化策略[ always , everysec , no ]将操作 同步到磁盘的 AOF ⽂件中,当 AOF ⽂件⼤⼩超过重写策略或⼿动重写时,会对 AOF ⽂件进⾏重写来压缩 AOF ⽂件容量, Redis 服务重启时,会重新加载 AOF ⽂件中的写操作来进⾏数据恢复。
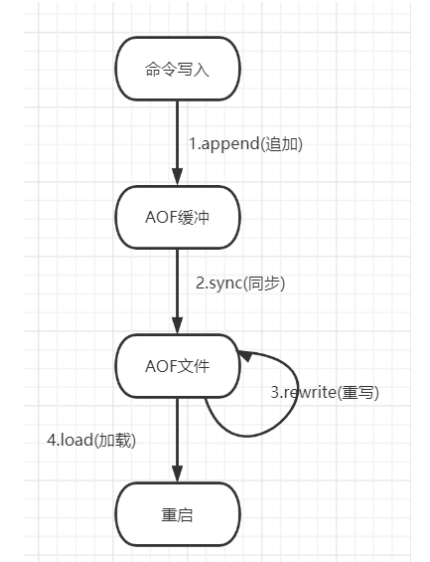
AOF的触发⽅式
⼿动触发
通过 bgrewriteaof 命令:重新 AOF 持久化⽣成 aof ⽂件(触发重写)。
⾃动触发
默认情况, Redis 是没有开启 AOF (默认使⽤ RDB 持久化),需要通过配置⽂件开启。
AOF 重写流程
主进程 fork 出⼀个⼦进程进⾏ AOF ⽂件的重写,⼦进程重写完毕后,主进程把⼦进程重写期间,其他客户端产 ⽣的写请求,追加到 AOF ⽂件中,替换旧⽂件。
AOF 的 rewirte 重写和 RDB 的 bgsave 都是由⽗进程 fork 出⼀个⼦进程来执⾏的。重写是直接把当前内存 的数据⽣成对应的命令,⽽不是读取旧 AOF ⽂件进⾏命令合并。

AOF的优缺点
优点
数据安全性⾼,不易丢数据。
AOF ⽂件有序保存了所有写操作,可读性强。
缺点
AOF ⽅式⽣成⽂件体积⼤。
数据恢复速度⽐ RDB 慢。
Redis 的事务
由于 Redis 在执⾏多条命令时,可能会被其他命令插队,从⽽影响预期结果。
所以 Redis 中为保证完成某个功 能的⼀系列指令串在执⾏的过程中不被其他指令串所影响,提供了事务处理机制。
同传统数据库的区别
传统的事务指:
1.在⼀个事务中的多个操作不能分割,
2.要么同时成功要么同时失败,
3.如果执⾏成功通过 commit 进 ⾏事务提交,如果失败通过 rollback 进⾏事务回滚,
4.具有:原⼦性、⼀致性、隔离性、持久性四个特性。
Redis 的事务指:
1.⼀个指令执⾏队列,将⼀系列预定义的指令包装为⼀个整体(队列),
2.当执⾏时,将队列中的指 令,按照既定的顺序执⾏,在执⾏过程中不允许其他命令执⾏,具有排他性。
- Redis 的事务没有回滚的概念。
基本操作
开启事务
multi 指令,该指令⽤于设置事务的开始位置,该指令后的所有指令都将加⼊到 Redis 的事务中,形成⼀个指令 队列。
执⾏事务(结束事务)
exec 指令,该指令⽤于执⾏事务,表示事务结束并执⾏事务队列中的指令,它与 multi 成对使⽤。
注意:加⼊事务的指令并没有⽴即执⾏,⽽是加⼊到了⼀个执⾏队列中,当执⾏ exec 指令时才会被执⾏。
取消事务
discard 指令,该指令必须在 multi 之后, exec 之前执⾏,该指令⽤于取消当前的事务。

注意事项
注意1:在 Redis 事务中如果出现指令语法错误,则会⾃动取消当前事务;
127.0.0.1:6380> multi
OK
127.0.0.1:6380> set name abc
QUEUED
127.0.0.1:6380> sets age 20 #语法错误,取消事务
(error) ERR unknown command 'sets'
127.0.0.1:6380> exec
(error) EXECABORT Transaction discarded because of previous errors.
注意2:在 Redis 事务执⾏过程中如果出现执⾏错误,则事务不会停⽌也不会回滚,依然执⾏
127.0.0.1:6380> multi
OK
127.0.0.1:6380> set name admin
QUEUED
127.0.0.1:6380> get name
QUEUED
127.0.0.1:6380> set age 20
QUEUED
127.0.0.1:6380> get age
QUEUED
127.0.0.1:6380> lpush age aaa bbb ccc
QUEUED
127.0.0.1:6380> get age
QUEUED
127.0.0.1:6380> exec
1) OK
2) "admin"
3) OK
4) "20"
5) (error) WRONGTYPE Operation against a key holding the wrong kind of value #执
⾏错误
6) "20"
Redis 中的锁
watch 监控锁
当⼀个数据需要改变时,可能会出现多⼈同时去改变该数据,如果其中有⼀⼈改变了,则其他⼈就不能再改变(数据 只能被改变⼀次),此时我们就需要使⽤监控锁,对要修改的数据监控起来,⼀旦数据发⽣改变(已被其他⼈修改),则 ⾃动终⽌事务的执⾏。
对指定 key 添加监控锁,在执⾏事务前如果 key 的值发⽣改变,⾃动终⽌事务的执⾏.
watch key[key1 key2 .....]
取消对所有可以的监控
unwatch key[key1 key2 .....]
注意: watch 监控锁只是监控,并不能像 java 中锁⼀样将数据锁定,只在事务中有作⽤。
假设有一个在线购物车,在处理购物车结算时需要对购物车中的商品数量进行操作。为了保证只有一个用户能够对购物车中的商品数量进行操作,可以使用 Redis 中的 watch 监控锁来实现互斥。
当用户 A 想要结算购物车时,它会向 Redis 中的一个键(key)执行 watch(notic_lock) 命令来监控 “notic_lock” 这个键值对。如果该命令执行成功,则表示用户 A 成功获取了 watch 监控锁,可以继续执行结算操作;如果该命令执行失败,则表示用户 A 获取 watch 监控锁失败,需要等待一段时间后再尝试获取 watch 监控锁。
用户 A 在获取到 watch 监控锁后,可以执行需要对购物车中的商品数量进行操作的命令,例如 set、get、del 等命令。当用户 A 执行完操作后,需要释放 watch 监控锁,可以使用 Redis 命令 unwatch(notic_lock) 来删除 “notic_lock” 这个键值对的 watch 监控。
这样,其他用户就可以再次尝试获取 watch 监控锁并对购物车中的商品数量进行操作了。 为了避免 Redis watch 监控锁出现死锁的情况,可以设置 Redis 的超时时间,让 Redis 在一段时间内没有收到释放 watch 监控锁的命令时自动释放 watch 监控锁。
另外,可以使用 Redis 的事务来保证操作的原子性和顺序性,避免多个用户同时对购物车中的商品数量进行操作导致数据错误或死锁的情况。
分布式锁
当多个线程需要同时操作⼀个数据时,为避免出现数据异常,我们要将数据锁起来,使⽤结束后再将锁打开,此时 其他线程才可以继续访问该数据, Redis 中使⽤分布式锁实现此场景
Redis 中并没有分布式锁的实现,我们可以通过 setnx 来设计⼀个分布式锁
# 添加⼀个key,该key为分布式锁,我们知道setnx在设置数据时如果数据存在则返回0
# 设置该数据为锁,其他客户端要操作数据前先通过该指令的返回值检测如果返回值为0则表示当前数据已被锁定不能
操作,如果返回值为1表示加锁,然后操作
setnx lock-num 1
# 对加锁的数据使⽤后要解锁,通过del lock-num移除数据的⽅式实现解锁过程
del lock-num
分布式锁的示例:
假设有一个电商网站,在处理订单时需要对同一个商品的库存进行操作。如果多个用户同时下单,就需要使用分布式锁来保证只有一个用户能够对该商品的库存进行操作。 为了实现分布式锁,可以使用 Redis 中的 setnx(notic_lock,1) 命令。
当用户 A 需要下单时,它会向 Redis 中的一个键(key)执行 setnx(notic_lock,1) 命令来获取分布式锁。如果该命令执行成功,则表示用户 A 成功获取了分布式锁,可以继续执行下单操作;如果该命令执行失败,则表示用户 A 获取分布式锁失败,需要等待一段时间后再尝试获取分布式锁。
用户 A 在获取到分布式锁后,可以执行需要对商品库存进行操作的命令,例如 set、get、del 等命令。当用户 A 执行完操作后,需要释放分布式锁,可以使用 Redis 命令 del(notic_lock) 来删除 “notic_lock” 这个键值对。
这样,其他用户就可以再次尝试获取分布式锁并对商品的库存进行操作了。 为了避免 Redis 分布式锁出现死锁的情况,可以设置 Redis 的超时时间,让 Redis 在一段时间内没有收到释放分布式锁的命令时自动释放分布式锁。
另外,可以使用 Redis 的事务来保证操作的原子性和顺序性,避免多个用户同时对同一个商品的库存进行操作导致数据错误或死锁的情况。
死锁
通过分布式锁的机制可以实现对数据操作的排他性,但数据使⽤结束后**必须解锁(**谁加锁,谁解 锁),如果数据使⽤ 后忘记解锁或由于意外的发⽣⽆法解锁,就形成了死锁。
在设计分布式锁时不允许出现死锁。 在设置分布式锁时就需要使⽤失效时间进⾏设置,当时间到达后⾃动解锁:
# 设置分布式锁
set key value [ex seconds] [px milliseconds] [nx]
Redis 死锁示例:
假设有两个客户端,分别为 A 和 B,它们同时向 Redis 中的一个哈希表(hash)执行 set 操作。客户端 A 先向哈希表中的一个键(key)设置了一个值,然后客户端 B 也向哈希表中的同一个键设置了一个值。
此时,哈希表中已经有了两个键值对,分别由客户端 A 和客户端 B 持有。 接下来,客户端 A 和客户端 B 分别请求从哈希表中获取(get)同一个键对应的值。
由于 Redis 中的操作是按照客户端请求的顺序执行的,因此客户端 A 先执行了 get 操作,获取了该键对应的值,并将该值返回给客户端 A。此时,哈希表中还剩下一个键值对,由客户端 B 持有。
然而,客户端 B 的请求被阻塞了,因为哈希表中已经没有可用的键值对了。客户端 B 无法继续执行 get 操作,因此发生了死锁。
为了避免 Redis 中的死锁,可以采取一些措施,例如设置 Redis 的超时时间、使用事务来保证操作的原子性和顺序性、禁止客户端在同一时间对同一个 Redis 资源执行多个操作等。
(数据 只能被改变⼀次),此时我们就需要使⽤监控锁,对要修改的数据监控起来,⼀旦数据发⽣改变(已被其他⼈修改),则 ⾃动终⽌事务的执⾏。
对指定 key 添加监控锁,在执⾏事务前如果 key 的值发⽣改变,⾃动终⽌事务的执⾏.
watch key[key1 key2 .....]
取消对所有可以的监控
unwatch key[key1 key2 .....]
注意: watch 监控锁只是监控,并不能像 java 中锁⼀样将数据锁定,只在事务中有作⽤。
假设有一个在线购物车,在处理购物车结算时需要对购物车中的商品数量进行操作。为了保证只有一个用户能够对购物车中的商品数量进行操作,可以使用 Redis 中的 watch 监控锁来实现互斥。
当用户 A 想要结算购物车时,它会向 Redis 中的一个键(key)执行 watch(notic_lock) 命令来监控 “notic_lock” 这个键值对。如果该命令执行成功,则表示用户 A 成功获取了 watch 监控锁,可以继续执行结算操作;如果该命令执行失败,则表示用户 A 获取 watch 监控锁失败,需要等待一段时间后再尝试获取 watch 监控锁。
用户 A 在获取到 watch 监控锁后,可以执行需要对购物车中的商品数量进行操作的命令,例如 set、get、del 等命令。当用户 A 执行完操作后,需要释放 watch 监控锁,可以使用 Redis 命令 unwatch(notic_lock) 来删除 “notic_lock” 这个键值对的 watch 监控。
这样,其他用户就可以再次尝试获取 watch 监控锁并对购物车中的商品数量进行操作了。 为了避免 Redis watch 监控锁出现死锁的情况,可以设置 Redis 的超时时间,让 Redis 在一段时间内没有收到释放 watch 监控锁的命令时自动释放 watch 监控锁。
另外,可以使用 Redis 的事务来保证操作的原子性和顺序性,避免多个用户同时对购物车中的商品数量进行操作导致数据错误或死锁的情况。
分布式锁
当多个线程需要同时操作⼀个数据时,为避免出现数据异常,我们要将数据锁起来,使⽤结束后再将锁打开,此时 其他线程才可以继续访问该数据, Redis 中使⽤分布式锁实现此场景
Redis 中并没有分布式锁的实现,我们可以通过 setnx 来设计⼀个分布式锁
# 添加⼀个key,该key为分布式锁,我们知道setnx在设置数据时如果数据存在则返回0
# 设置该数据为锁,其他客户端要操作数据前先通过该指令的返回值检测如果返回值为0则表示当前数据已被锁定不能
操作,如果返回值为1表示加锁,然后操作
setnx lock-num 1
# 对加锁的数据使⽤后要解锁,通过del lock-num移除数据的⽅式实现解锁过程
del lock-num
分布式锁的示例:
假设有一个电商网站,在处理订单时需要对同一个商品的库存进行操作。如果多个用户同时下单,就需要使用分布式锁来保证只有一个用户能够对该商品的库存进行操作。 为了实现分布式锁,可以使用 Redis 中的 setnx(notic_lock,1) 命令。
当用户 A 需要下单时,它会向 Redis 中的一个键(key)执行 setnx(notic_lock,1) 命令来获取分布式锁。如果该命令执行成功,则表示用户 A 成功获取了分布式锁,可以继续执行下单操作;如果该命令执行失败,则表示用户 A 获取分布式锁失败,需要等待一段时间后再尝试获取分布式锁。
用户 A 在获取到分布式锁后,可以执行需要对商品库存进行操作的命令,例如 set、get、del 等命令。当用户 A 执行完操作后,需要释放分布式锁,可以使用 Redis 命令 del(notic_lock) 来删除 “notic_lock” 这个键值对。
这样,其他用户就可以再次尝试获取分布式锁并对商品的库存进行操作了。 为了避免 Redis 分布式锁出现死锁的情况,可以设置 Redis 的超时时间,让 Redis 在一段时间内没有收到释放分布式锁的命令时自动释放分布式锁。
另外,可以使用 Redis 的事务来保证操作的原子性和顺序性,避免多个用户同时对同一个商品的库存进行操作导致数据错误或死锁的情况。
死锁
通过分布式锁的机制可以实现对数据操作的排他性,但数据使⽤结束后**必须解锁(**谁加锁,谁解 锁),如果数据使⽤ 后忘记解锁或由于意外的发⽣⽆法解锁,就形成了死锁。
在设计分布式锁时不允许出现死锁。 在设置分布式锁时就需要使⽤失效时间进⾏设置,当时间到达后⾃动解锁:
# 设置分布式锁
set key value [ex seconds] [px milliseconds] [nx]
Redis 死锁示例:
假设有两个客户端,分别为 A 和 B,它们同时向 Redis 中的一个哈希表(hash)执行 set 操作。客户端 A 先向哈希表中的一个键(key)设置了一个值,然后客户端 B 也向哈希表中的同一个键设置了一个值。
此时,哈希表中已经有了两个键值对,分别由客户端 A 和客户端 B 持有。 接下来,客户端 A 和客户端 B 分别请求从哈希表中获取(get)同一个键对应的值。
由于 Redis 中的操作是按照客户端请求的顺序执行的,因此客户端 A 先执行了 get 操作,获取了该键对应的值,并将该值返回给客户端 A。此时,哈希表中还剩下一个键值对,由客户端 B 持有。
然而,客户端 B 的请求被阻塞了,因为哈希表中已经没有可用的键值对了。客户端 B 无法继续执行 get 操作,因此发生了死锁。
为了避免 Redis 中的死锁,可以采取一些措施,例如设置 Redis 的超时时间、使用事务来保证操作的原子性和顺序性、禁止客户端在同一时间对同一个 Redis 资源执行多个操作等。
















 9052
9052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









